







 本文详细解读Kaggle《SIIM-ACR肺部气胸分割》竞赛第一名方案,涵盖数据增强、滑动采样、模型选择、损失函数、学习率调度及后处理技巧。重点介绍了Albunet、SENet和ResNet50网络在医疗图像分割领域的应用。
本文详细解读Kaggle《SIIM-ACR肺部气胸分割》竞赛第一名方案,涵盖数据增强、滑动采样、模型选择、损失函数、学习率调度及后处理技巧。重点介绍了Albunet、SENet和ResNet50网络在医疗图像分割领域的应用。
当初刷微博无意中看到这个比赛,内容和自己所在团队的工作内容很契合,就花了点时间学习了下第一名的方案。在这里把自己学习的成果记录下来,也希望和大家一起讨论学习。
文章同步发在我的个人博客,欢迎大佬们指教。kaggle《SIIM-ACR Pneumothorax Segmentation》第一名方案详解
1 Introduction
引用一段比赛页面对这个比赛的介绍:
“Pneumothorax can be caused by a blunt chest injury, damage from underlying lung disease, or most horrifying—it may occur for no obvious reason at all. On some occasions, a collapsed lung can be a life-threatening event.
Pneumothorax is usually diagnosed by a radiologist on a chest x-ray, and can sometimes be very difficult to confirm. An accurate AI algorithm to detect pneumothorax would be useful in a lot of clinical scenarios. AI could be used to triage chest radiographs for priority interpretation, or to provide a more confident diagnosis for non-radiologists.”
比赛地址:SIIM-ACR Pneumothorax Segmentation
Data:
-
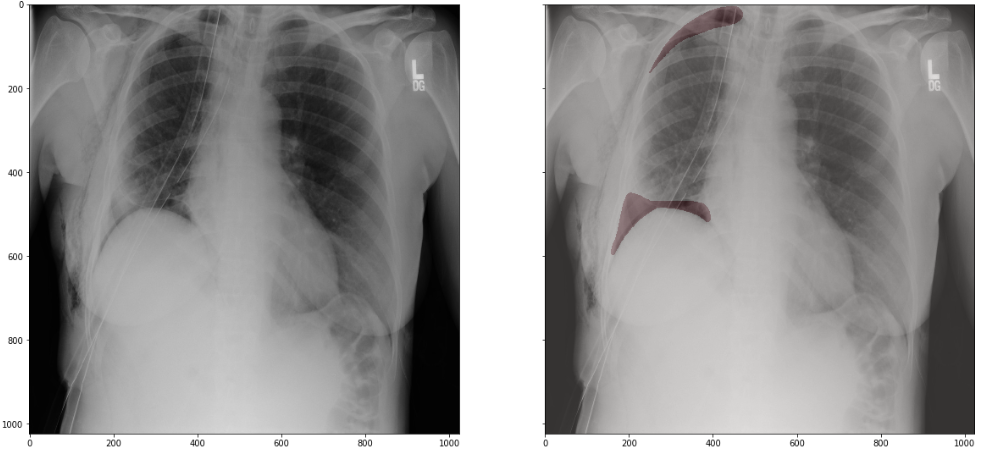
10679份dicom文件(站立位胸片),有气胸:无气胸 = 2379:8300
-
有气胸的胸片皆有mask, run-length-encoded (RLE)格式
-
一个胸片如果有多处气胸,会有多个单独的mask
Evaluation: Dice coefficient:
2 ∗ ∣ X ⋂ Y ∣ ∣ X ∣ + ∣ Y ∣ \frac {2*|X \bigcap Y|}{|X|+|Y|} ∣X∣+∣Y∣2∗∣X⋂Y∣
2 OverView
用一张图来表示作者的思路:
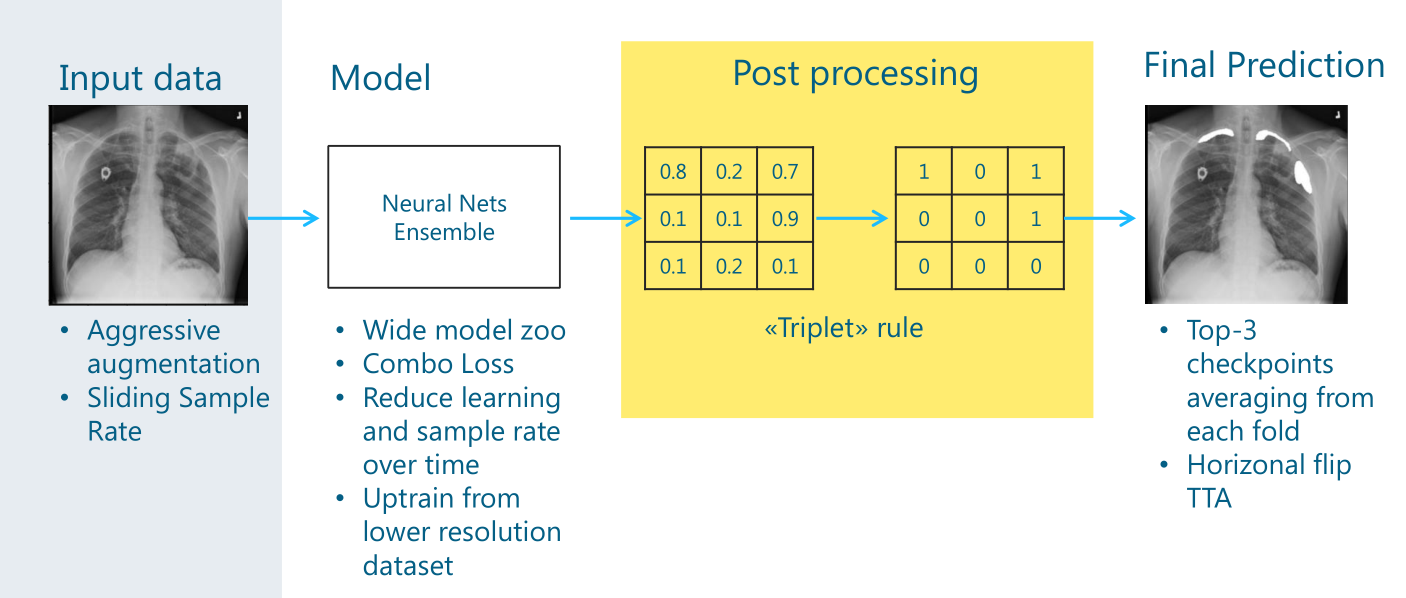
作者在训练模型时,采用5折交叉验证,并将模型训练分成了4个阶段(下文中分别表示成part0,part1,part2,part3),每个阶段都是上图中这样一个完整的过程,后一阶段直接在前一阶段的最优模型上fine-tuning.每一个阶段有不同的数据构成和模型参数。
3 Input Data
3.1 Data Augmentation
这里模型的输入是1024X1024X3的胸片和1024X1024X1的mask。作者直接使用了图像增强库 albumentations 对数据进行增强,作者使用了一个较为复杂的方案:以固定顺序对图像进行不同的变换,并且给予每种方法一定的概率,使增强方法的运用随机化。具体如下:
- HorizontalFlip:0.5
- OneOf:0.3
- RandomContrast:0.5
- RandomGamma:0.5
- RandomBrightness:0.5
- OneOf:0.3
- ElasticTransform:0.5
- GridDistortion:0.5
- OpticalDistortion:0.5
- ShiftScaleRotate:0.5
上面小数表示此增强方法运用的概率,OneOf表示在其子方法中选择一个。
需要注意的是,这里有2个OneOf,第一个OneOf下面的增强方法主要对图像的亮度、对比度等进行调整,而第二个OneOf下面的增强方法主要对图像的形状进行调整。可以看几个例子。
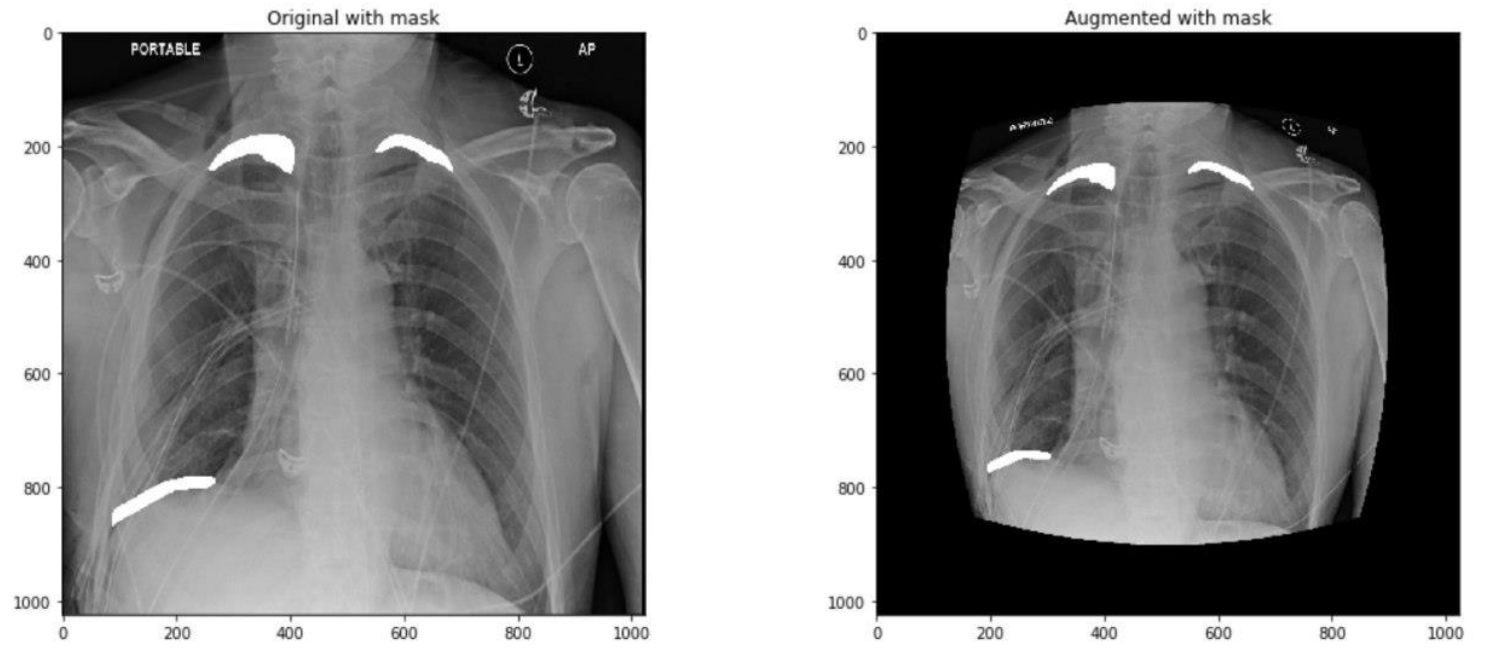
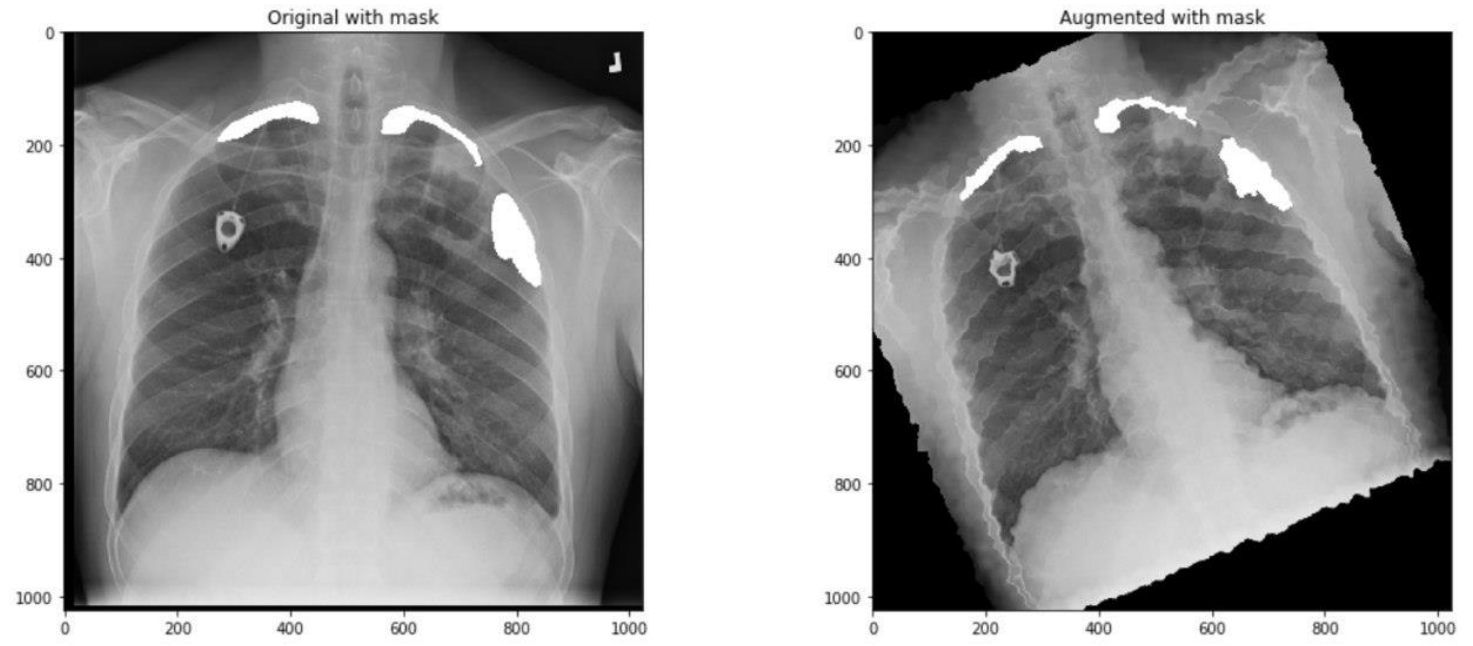
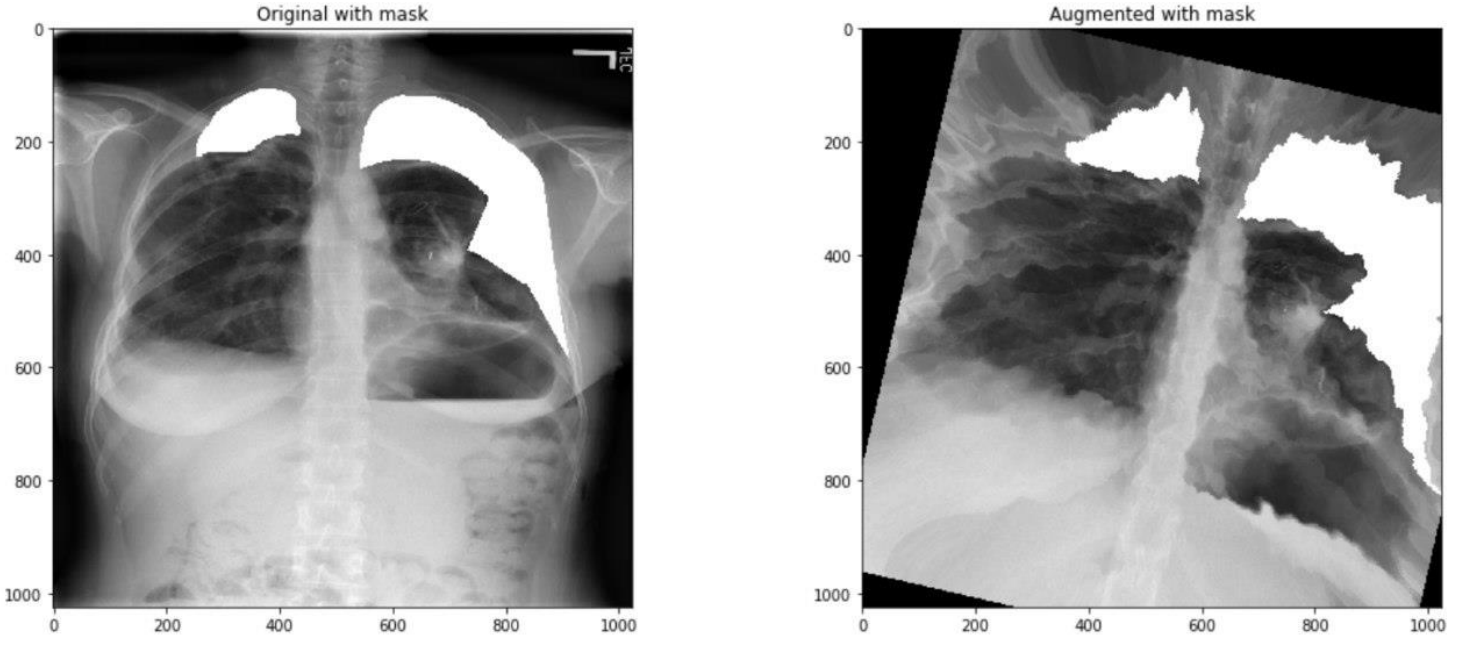
因为训练模型分成四个阶段,每个阶段使用的数据是一样的,使用一定概率给图像做增强,实际上保证了每个阶段实际参加训练的数据都不完全一样。
3.2 Sliding Sample
对无气胸的样本随机下采样,使有气胸的样本占0.8(part0),0.6(part1),0.4(part2),0.5(part3)
4 Model
4.1 Model Zoo
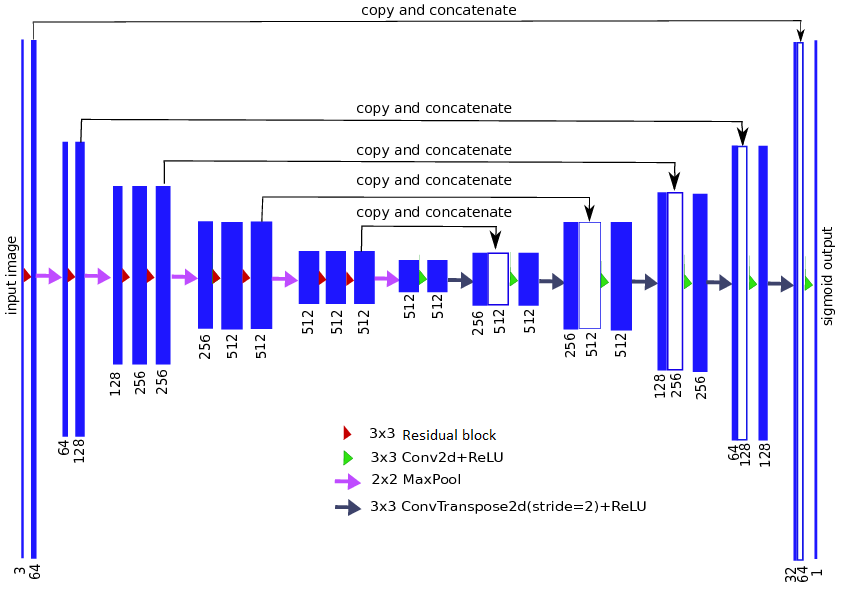
UNet简直是图像分割的神器,特别是在医疗图像分割的上,目前其各种变体网络仍是各种比赛的主力。Unet主要有2个特点:1.U型结构;2.skip connection.
– U型结构encoder的下采样和decoder的上采样的次数相同,这就保证了模型的输出恢复到原图片的分辨率,实现端到端的预测。
– skip connection的结构使模型结合不同level的feature map上进行学习,相比于FCN分割边缘更清晰。
同时Albunet的网络的encoder使用的是ResNet,其由何凯明大佬于2015年提出(Unet也是这一年提出,回过头看,这一年真的是丰收的一年),同样风靡至今。从理论上讲,越高级的特征,应该有越强的表征能力,而VGG网络证明,网络的深度对特征的表达能力至关重要。
理想情况下,当我们直接对网络进行简单的堆叠到特别长,网络内部的特征在其中某一层已经达到了最佳的情况,这时候剩下层应该不对改特征做任何改变,自动学成恒等映射的形式。也就是说,对一个特别深的深度网络而言,该网络的浅层形式的解空间应该是这个深度网络解空间的子集,但实际上,如果使用简单是网络堆叠,由于网络性能衰减,网络的效果反而越差。为了深度网络后面的层至少实现恒等映射的作用,作者提出了residual模块。
除了Albunet,作者还尝试了如下2种网络进行实验:
-
Resnet50: GitHub链接
-
SCSEUnet:也就是SENet((论文:squeeze-and-excitation network))
4.2 Loss Function
作者使用BCE,Dice和Focal loss加权的方式作为最终的损失函数:
L o s s = W 1 ∗ S t a b l e B C E L o s s + W 2 ∗ D i c e L o s s + W 3 ∗ F o c a l L o s s 2 d ( ) Loss = W_1 * StableBCELoss + W_2 * DiceLoss + W_3 * FocalLoss2d() Loss=W1∗StableBCELoss+W2∗DiceLoss+W3∗FocalLoss2d()
这里需要注意的是,损失函数StableBCELoss的输入是没有进行sigmoid计算的模型输出,而其他2个损失函数的输入是经过sigmoid计算的模型输出。作者使用这三个损失函数,是想从三个维度驱动网络学习。
– Focal loss主要解决正负样本失衡的问题,在医学图像分割的这种像素级分类的任务中,往往都是正样本较少,负样本较多,气胸的分割同样不例外。其公式如下:
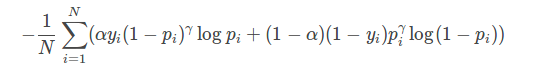
从如上公式上可以看到,某个样本输出的概率越高,其产生的loss越小,实际上达到了促使网络学习困难样本的目的(在分割任务中,目标像素就是困难样本,因为其数量较少)。
– Dice loss在很多关于医学图像分割的竞赛、论文和项目中出现的频率很高,此比赛的评价指标也是它。从前文它的公式可以看到,其表示的是预测的轮廓与真实的mask的相似程度。其公式如下:
D i c e L o s s = 1 − 2 ∗ ∣ X ⋂ Y ∣ ∣ X ∣ + ∣ Y ∣ DiceLoss = 1 - \frac {2*|X \bigcap Y|}{|X|+|Y|} DiceLoss=1−∣X∣+∣Y∣2∗∣X⋂Y∣
– StableBCELoss, 这里非常奇怪的是,其输入是没有进行sigmoid计算的模型输出,至今没想通(to do:等搞明白了补上)。这里附上pytorch文档中其公式:
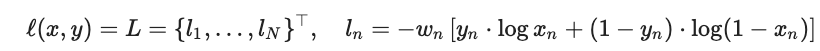
最终作者寻优,得到各个损失函数的权重如下:
-
(3,1,4) for albunet_valid and seunet;
-
(1,1,1) for albunet_public;
-
(2,1,2) for resnet50.
4.3 Learn Rate Scheduler
作者在不同的训练阶段,采用了不同的学习率调整策略,具体如下:
| Phase | Start Lr | Scheduler |
|---|---|---|
| part0 | 1e-4 | ReduceLROnPlateau |
| part1 | 1e-5 | ReduceLROnPlateau or CosineAnnealingWarmRestarts |
| part2 | 1e-5 | ReduceLROnPlateau or CosineAnnealingWarmRestarts |
| part3 | 1e-6 | ReduceLROnPlateauor CosineAnnealingWarmRestarts |
4.3.1 torch.optim.lr_scheduler.ReduceLROnPlateau
其基本思想是:当参考的评价指标停止变优时,降低学习率,挺实用的方法。
Code Example:
optimizer = torch.optim.SGD(model.parameters(), lr=0.1, momentum=0.9)
scheduler = ReduceLROnPlateau(optimizer, 'min')
for epoch in range(10):
train(...)
val_loss = validate(...)
# Note that step should be called after validate()
scheduler.step(val_loss)
4.3.2 torch.optim.lr_scheduler.CosineAnnealingLR
可以翻译为余弦退火调整学习率:根据论文SGDR: Stochastic Gradient Descent with Warm Restarts而来,只包含论文里余弦退火部分,并不包含restart部分。
当使用SGD时,模型的Loss应越来约接近全局最小值。当它逐渐接近这个最小值时,学习率应该变得更小来使得模型尽可能接近这一点。
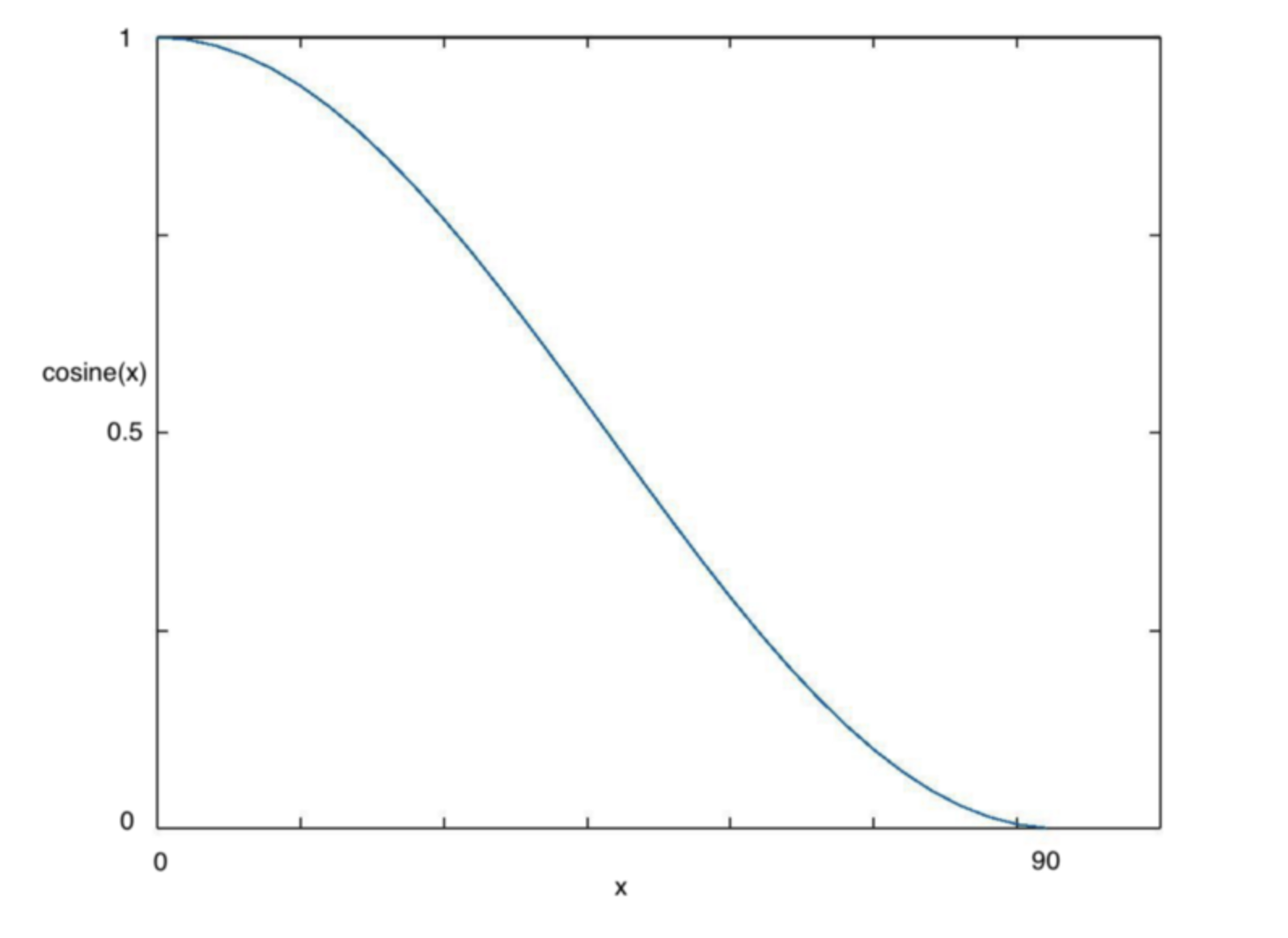
从上图可以看出,随着x的增加,余弦值首先缓慢下降,然后加速下降,再次缓慢下降。这种下降模式能和学习率配合,比较有效的训练模型。
4.3.3 torch.optim.lr_scheduler.CosineAnnealingWarmRestarts
SGDR:这个方法就是论文SGDR: Stochastic Gradient Descent with Warm Restarts的完整实现。
在训练时,梯度下降算法可能陷入局部最小值,而不是全局最小值。做随机梯度下降时可以通过突然提高学习率,来“跳出”局部最小值并找到通向全局最小值的路径。具体可以看下图:
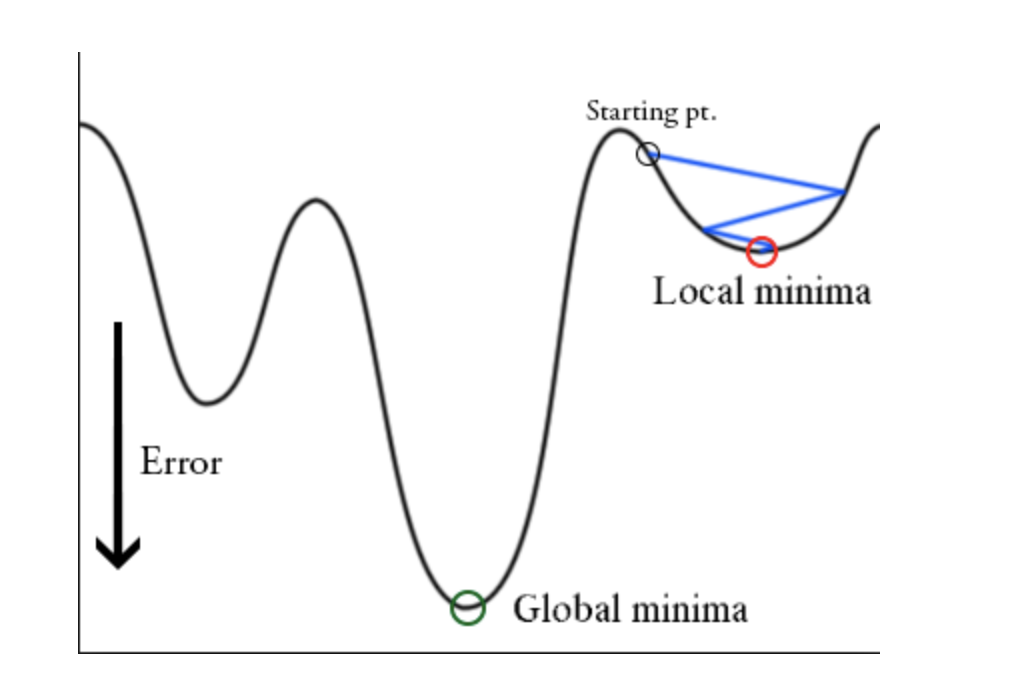
5 Post Proprecess
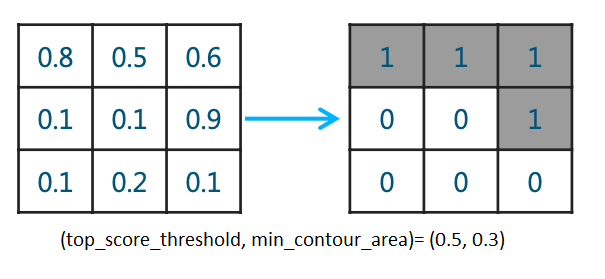
我们训练的分割模型输出每个像素的0-1概率,然后卡一下阈值,我们可以称这样的mask为basic sigmoid mask, 实际上医学图像中我们的分割目标也许并不存在,所以常用双重阈值(top_score_threshold, min_contour_area)的方法计算出mask并同时判断是否有分割目标(在本次比赛中我们分割目标是气胸),这种方法且称为doublet。其具体逻辑为:当大于概率阈值top_score_threshold的pixel数少于
min_contour_area,就将mask像素值全部置0,也就是认为此胸片没有气胸。简单画个示意图如下:
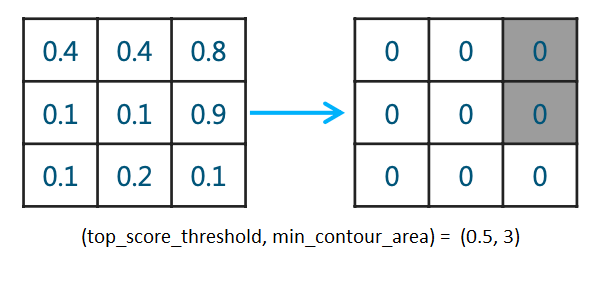
而作者在此基础上作了改进,使用了三重阈值(top_score_threshold, min_contour_area, bottom_score_threshold)的方法来达到相同的目标,且称改进后的方法为Triplet.其具体逻辑为:当大于概率阈值top_score_threshold的pixel数少于
min_contour_area,就将此mask pixel值全部置0,也就是认为此胸片没有气胸,然后再使用阈值bottom_score_threshold产生真正的mask。简单画个示意图如下:
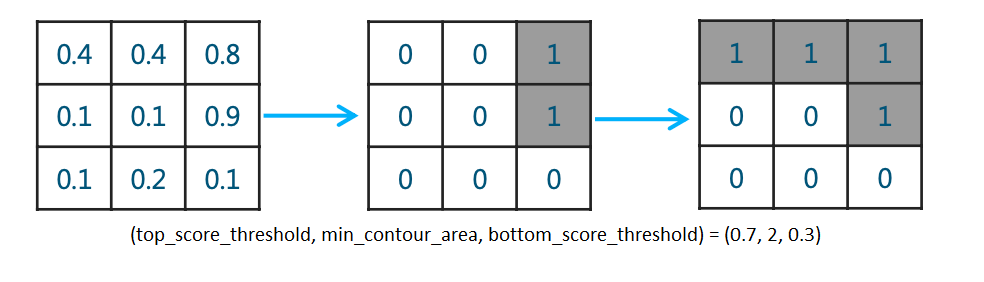
最终作者通过搜索,分别获得了在validation和在Public Leaderboard上的最优参数:
- Best triplet on validation: (0.75, 2000, 0.3).
- Best triplet on Public Leaderboard: (0.7, 600, 0.3)
最后再附上作者的代码:
classification_mask = predicted > top_score_threshold
mask = predicted.copy()
mask[classification_mask.sum(axis=(1,2,3)) < min_contour_area, :,:,:] = np.zeros_like(predicted[0])
mask = mask > bot_score_threshold
return mask
6 Train and Inference
6.1 Train
前面就已经提到过,作者将训练过程分为了4个阶段,这里在最前面新加一个预训练阶段。梳理如下:
| Phase | Sample rate | Start lr | Scheduler | Epochs | Note |
|---|---|---|---|---|---|
| part pre | The model be pretrained on our dataset with lower resolution (512x512) | ||||
| part0 | 0.8 | 1e-4 | ReduceLROnPlateau | 10-12 | The goal of this part: quickly get a good enough model with validation score about 0.835 |
| part1 | 0.6 | 1e-5 | ReduceLROnPlateau or CosineAnnealingWarmRestarts | Repeat until best convergence | uptrain the best model from the previous step |
| part2 | 0.4 | 1e-5 | ReduceLROnPlateau or CosineAnnealingWarmRestarts | Repeat until best convergence | uptrain the best model from the previous step |
| part3 | 0.5 | 1e-6 | ReduceLROnPlateauor CosineAnnealingWarmRestarts | Repeat until best convergence | uptrain the best model from the previous step |
6.2 Inference
作者采用五折交叉验证训练模型,并选择每一个fold的top3个模型的结果求平均输出最终的mask。这里的求平均每个像素点的概率求平均。模型的最终效果如下表:
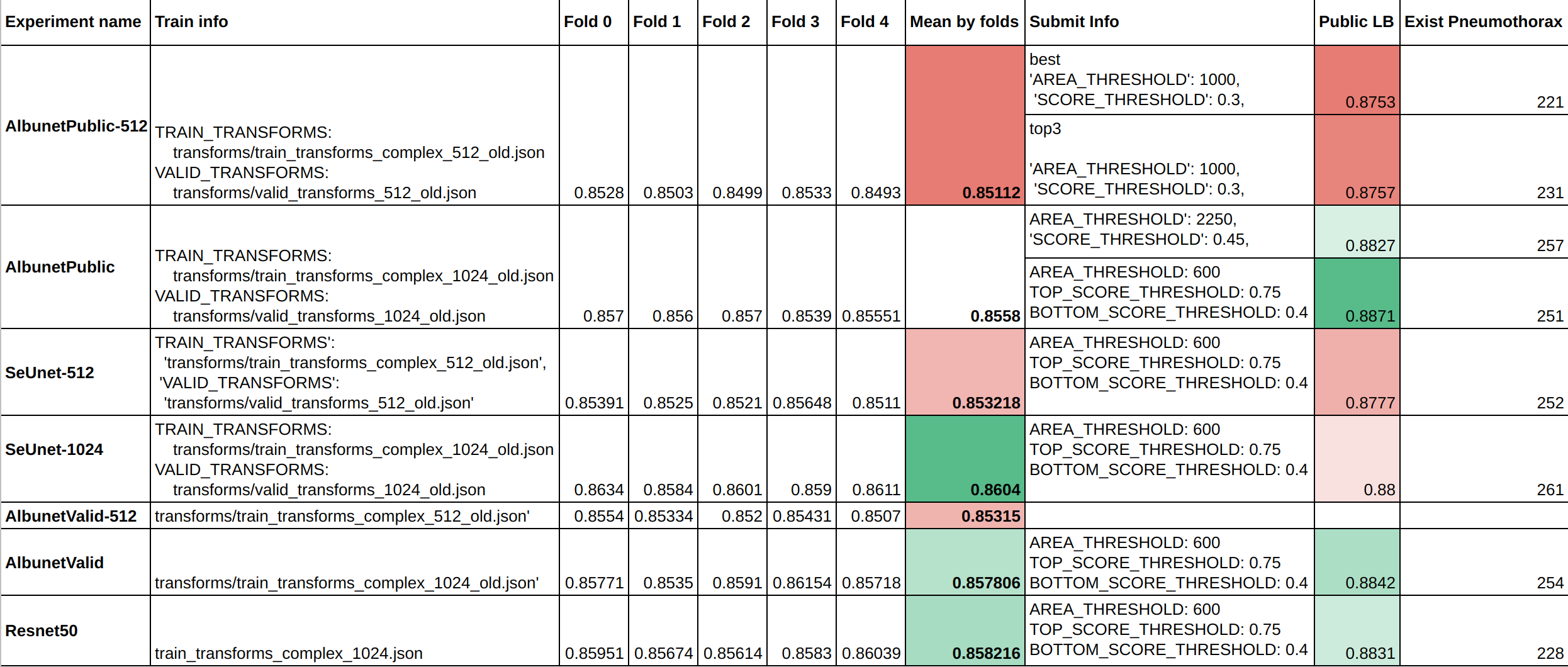
NOTE:
-
albunet_public - best model for Public Leaderboard
-
albunet_valid - best resnet34 model on validation
-
seunet - best seresnext50 model on validation
-
resnet50 - best resnet50 model on validation


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









