




 本文详细介绍了决策树模型,包括ID3、C4.5和CART算法。主要内容涵盖特征选择的熵、信息增益和增益率,以及决策树的生成和剪枝过程。CART算法中,回归树和分类树的生成分别基于平方误差最小化和基尼指数最小化。此外,还讨论了CART剪枝策略,通过损失函数和交叉验证选择最优子树。
本文详细介绍了决策树模型,包括ID3、C4.5和CART算法。主要内容涵盖特征选择的熵、信息增益和增益率,以及决策树的生成和剪枝过程。CART算法中,回归树和分类树的生成分别基于平方误差最小化和基尼指数最小化。此外,还讨论了CART剪枝策略,通过损失函数和交叉验证选择最优子树。
文章目录
1. 决策树模型概述
分类决策树模型是一种描述对实例进行分类的树形结构。决策树由结点和有向边组成。结点有两种类型:内部结点和叶结点。内部结点表示一个特征或属性,叶结点表示一个类。
决策树学习通常包括3 个步骤:特征选择、决策树的生成和决策树的修剪。决策树学习常用的算法有ID3 、C4.5 与CART。
2. 特征选择
决策树在一个分支时会从众多属性中选择一个属性进行划分,一般是选择最优的属性进行划分,对最优的评判需要依靠一些指标来进行。我们希望决策树的分支结点所包含的样本尽可能属于同一类别,即结点“纯度”越来越高。
2.1 信息熵
在这之前,我们先定义信息熵的概念,假设样本集合 D D D 中第 k k k 类样本所占的比例为 p k ( k = 1 , 2 , . . . , N ) p_k(k=1,2,...,N) pk(k=1,2,...,N) ,则 D D D 的信息熵定义为
E n t ( D ) = − ∑ k = 1 N p k l o g 2 p k Ent(D)=-\sum_{k=1}^{N}p_klog_2p_k Ent(D)=−k=1∑Npklog2pk E n t ( D ) Ent(D) Ent(D) 的值越小,则 D D D 的不确定性越高。
2.2 信息增益
假设离散属性 a a a 有 V V V 个可能的取值,若采用 a a a 进行划分时,会产生 V V V 个分支,每个分支包含了取值的所有样本,记其中一个分支为 D v D^v Dv,可算出其信息熵,再考虑到每一个分支结点中的样本数不同,对其进行权重赋予 ∣ D v ∣ / ∣ D ∣ \lvert D^v \rvert /\lvert D \rvert ∣Dv∣/∣D∣,样本越多影响越大,所以属性 a a a 对样本集 D D D 划分的“信息增益”定义为
G a i n ( D , a ) = E n t ( D ) − ∑ v = 1 V ∣ D v ∣ ∣ D ∣ E n t ( D v ) Gain(D,a)=Ent(D)-\sum_{v=1}^{V}\frac {\lvert D^v \rvert} {\lvert D \rvert}Ent(D^v) Gain(D,a)=Ent(D)−v=1∑V∣D∣∣Dv∣Ent(Dv)信息增益越大,则使用属性 a a a 来进行划分所得的“纯度提升”越大,其中 D D D 是要进行本次划分计算的集合。
2.3 增益率
信息增益对可取值数目较多的属性有一定的偏好,为了减少这种影响,可使用增益率来作为指标,增益率如下所示
G a i n _ r a t i o ( D , a ) = G a i n ( D , a ) I V ( a ) Gain\_ratio(D,a)=\frac{Gain(D,a)}{IV(a)} Gain_ratio(D,a)=IV(a)Gain(D,a)其中
I V ( a ) = − ∑ v = 1 V ∣ D v ∣ ∣ D ∣ l o g 2 ∣ D v ∣ ∣ D ∣ IV(a)=-\sum_{v=1}^V\frac {\lvert D^v \rvert} {\lvert D \rvert}log_2\frac {\lvert D^v \rvert} {\lvert D \rvert} IV(a)=−v=1∑V∣D∣∣Dv∣log2∣D∣∣Dv∣称为属性 a a a 的固有值。
增益率对属性可能取值少的属性比较有偏好,所以一般是先从候选属性中找出信息增益高于平均水平的属性,再从中选择增益率高的。
3. 决策树生成
3.1 ID3算法
ID3 算法的核心是在决策树各个结点上应用信息增益准则选择特征,递归地构建决策树。具体方法是:从根结点开始,对结点计算所有可能的特征的信息增益, 选择信息增益最大的特征作为结点的特征,由该特征的不同取值建立子结点;再对子结点递归地调用以上方法,构建决策树;直到所有特征的信息增益均很小或没有特征可以选择为止。最后得到一棵决策树。
ID3 算法只有树的生成,所以该算法生成的树容易产生过拟合。
具体例子在这里截取李航老师的《统计学习方法》来做理解:
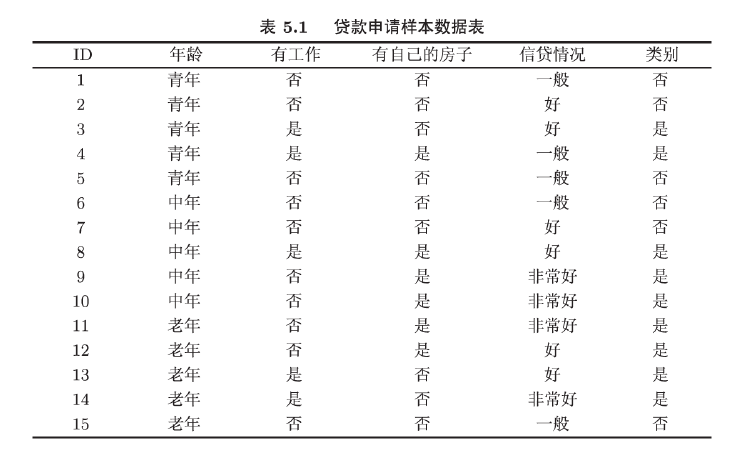
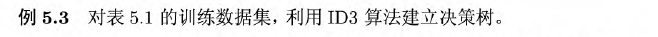

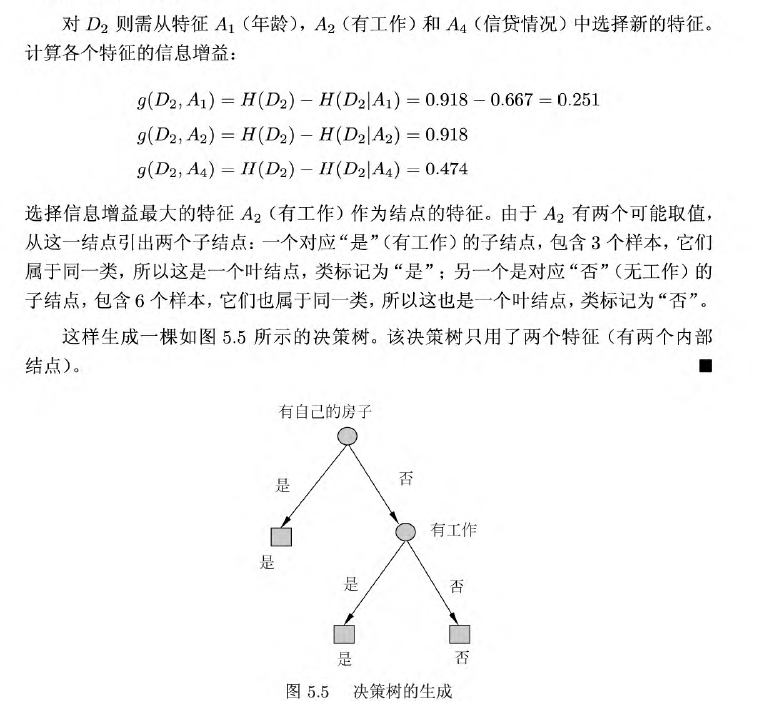
3.2 C4.5生成算法
C4.5 算法与ID3 算法相似, C4.5 算法对ID3 算法进行了改进。C4.5 在生成的过程中,用信息增益比来选择特征,除此之外没有不同
4. 决策树剪枝
决策树生成算法递归地产生决策树,直到不能继续下去为止。这样产生的树往往对训练数据的分类很准确,但对未知的测试数据的分类却没有那么准确,即出现过拟合现象。解决这个问题的办法是考虑决策树的复杂度,对已生成的决策树进行简化。
剪枝时可以按照类似正则化的方法对决策树进行剪枝。
设决策树 T T T 的叶节点个数是 ∣ T ∣ \vert T \vert ∣T∣ ,该叶节点有 N t N_t Nt 个样本点,其中 k k k 的样本点有 N t k N_{tk} Ntk 个, k = 1 , 2 , ⋯ , K k=1,2,\cdots,K k=1,2,⋯,K , H t ( T ) H_t(T) Ht(T) 为叶节点 t t t 上的熵, α ≥ 0 \alpha \geq 0 α≥0 为参数,则决策树的损失函数定义如下:
C α ( T ) = ∑ t = 1 ∣ T ∣ N t H t ( T ) + α ∣ T ∣ C_{\alpha}(T)=\sum_{t=1}^{\vert T \vert}N_tH_t(T)+ \alpha \vert T \vert Cα(T)=t=1∑∣T∣NtHt(T)+α∣T∣其中熵为
H t ( T ) = − ∑ k N t k N t log N t k N t H_t(T)=-\sum_k \frac{N_{tk}}{N_t} \log \frac{N_{tk}}{N_t} Ht(T)=−k∑NtN
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1739
1739

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









