






SD 的安装和介绍
万事开头难,安装确实是难中难(T ▽ T)。对于一个没有计算机基础的同学来说上手还是有一点点难度的,在此提供以下几种方式供不同行业的同学选择。
安装 Stable Diffusion
目前主要有三种形式可以把 SD 环境跑起来:
-
1. 整合包:包括秋叶整合包,星空整合包。
-
2. 云环境:腾讯云,青椒云等等都支持低成本地部署 SD。
-
3. 手动下载 SD webUI 源码,搭建开发环境,从 0 开始部署本地环境。
整合包:对于无计算机基础的同学来说最合适不过,对于有计算机相关经验的同学来说也是相当不错的,已经在整合包里面集成了相关开发环境的搭建,拿来即用。
云环境:如果你本地的机器配置达不到要求,或者你有更高的需求要跑高质量的图那么你可以选择云环境。在云环境下你可以选择合适的显卡,只要钱到位一切都不是问题!
本地运行:首先,一定要机器资源到位!如果你拿着 1080Ti 这种曾经的卡皇幻想着是否能支持的话,倒也不是不行,可能你会被死机,运行迟钝整崩溃。建议上 8G
显存及其以上,上不封顶。
这份完整版的AI绘画(SD、comfyui、AI视频)整合包已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】
 #### 秋叶整合包
#### 秋叶整合包
详细安装说明见秋叶的 B 站介绍:https://www.bilibili.com/video/BV1iM4y1y7oA/。目前秋叶的整合包已经更新到
v4.5 版本,支持了最新的 SDXL 模型。相对来说还是更新较快的。
秋叶整合包里面整合了一些常用的大模型和 Lora 模型,基本相当于把 SD 放到你的手上,就怕你学会了。
如果你的电脑是第一次安装,需要先下载启动器运行依赖,安装依赖后,再解压 sd-webui-aki-v4 文件夹。
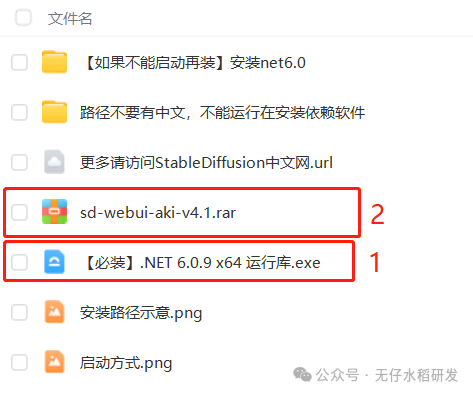
安装路径
解压 sd-webui-aki-v4 文件夹后,双击打开A 启动器 程序即可。
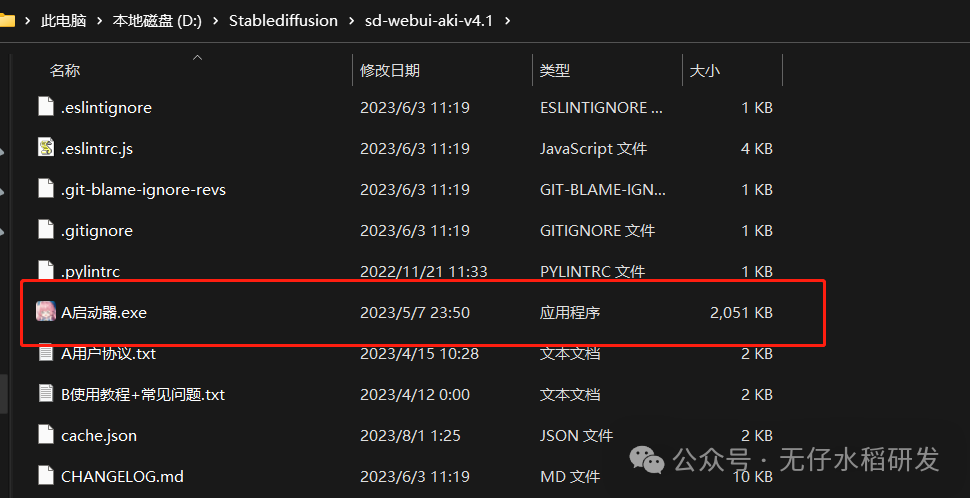
安装路径
点击启动,启动界面是这样的:
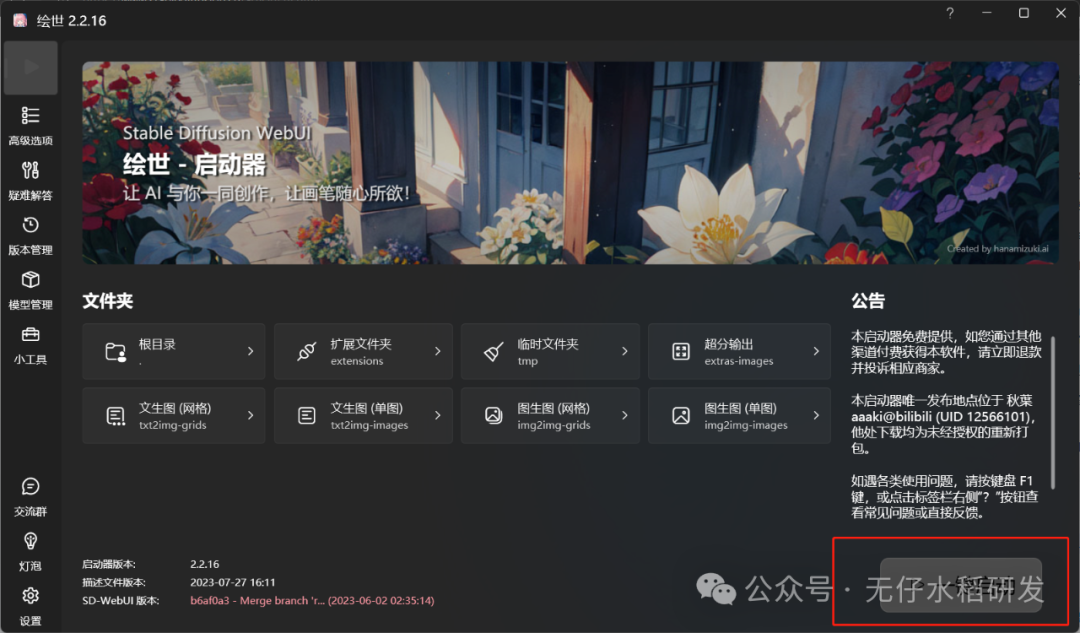
启动界面
本地手动安装
安装前首先需要这些准备:
一台中高端显卡的电脑。
电脑可以流畅且迅速地访问 Github。_这一点非常重要,后续大模型和插件都需要这种能力。
安装 Git。
安装 Python。
Python 需要安装 3.10.6 版本,因为 SD WebUI 是基于这个版本进行开发的。
https://www.python.org/downloads/release/python-3106/
如果你安装别的版本可能会有一些莫名其妙的问题。建议还是以这个版本为主。
安装好 Git 和 Python 之后我们就进入正式环节:安装 SD。
首先去 GitHub 上面下载下来源代码:
git clone [https://github.com/AUTOMATIC1111/stable-diffusion- webui.git](https://github.com/AUTOMATIC1111/stable-diffusion-webui.git)
放在你喜欢的任意目录下即可。进入当前文件夹,滑动到最下面:
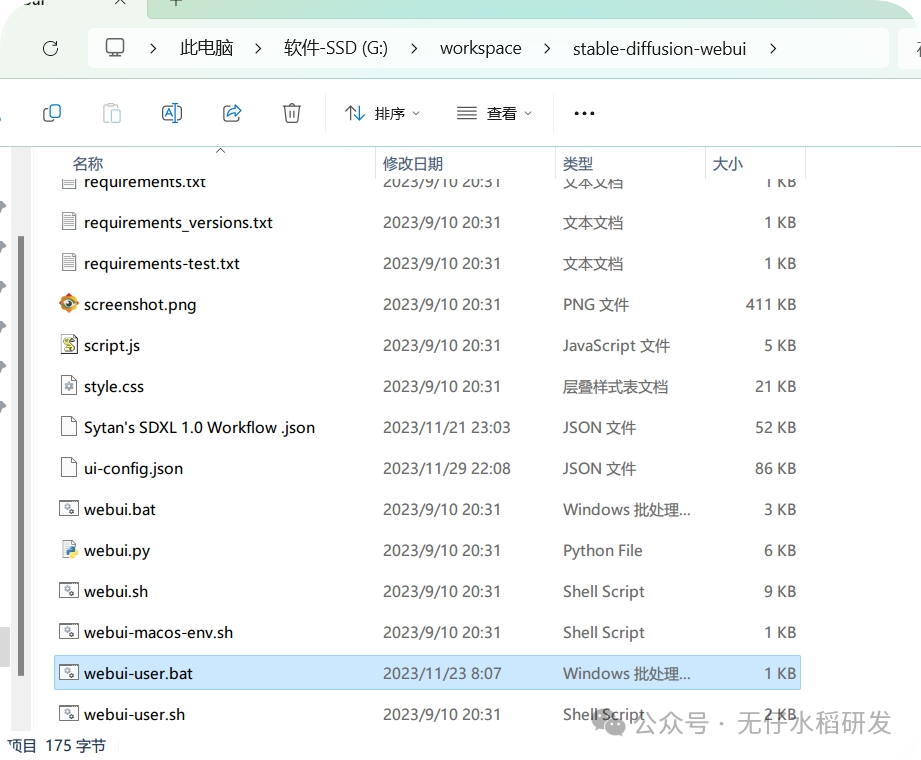
webUI
注意看这里有两个同名的文件,选择后缀为”.bat”的文件双击执行,双击之后就会出现一个黑色的命令行窗口,这里会自动去安装当前项目所需要的各种依赖文件。一般情况下如果不出错,十几分钟差不多能结束依赖安装的过程;如果出错的情况下,首先看看网络环境,其次检查
Python 版本,最后如果还搞不定就得看看具体报错信息具体分析。
安装完依赖包之后,最后会去自动下载一个基础版本的官方大模型包,下载完毕能正常启动的情况下会自动跳转到浏览器打开一个启动界面:
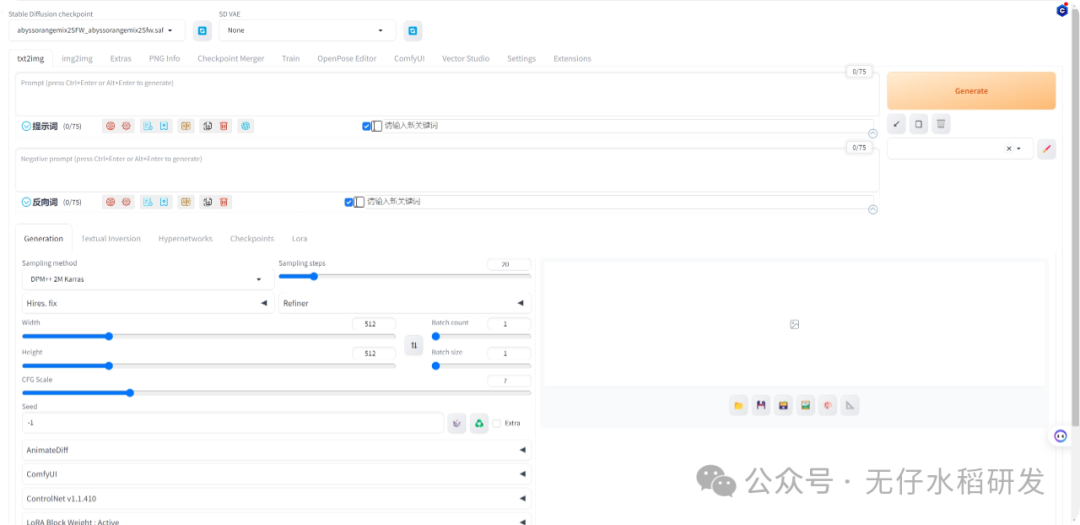
启动界面
这就表示你安装成功了,可以正常使用。
接着你可以在下图的红色框 1 中试着输入一些关键词然后点击 2 运行,可以在 3 处得到一些反馈:
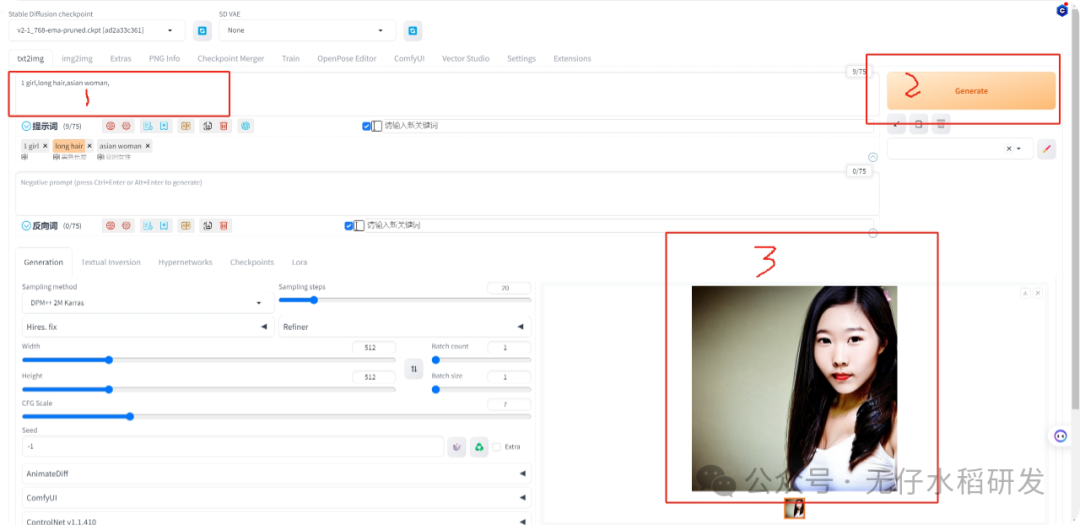
1-11.png
可以看到此刻你第一次用基于 AI
的方式生成了一张虚拟人物照片。看起来似乎细节方面不是很好,人物有一些缺陷,没关系,你可以试着去完善关键词看看是否能获得一些提升。
另外如果大家英文看起来不习惯的话,还可以安装汉化插件:
https://gitcode.net/overbill1683/stable-diffusion-webui-localization-zh_Hans
大家可以自行看这个文档的介绍,文档上安装说明很详细这里就不多介绍。
SD-WebUI 基础功能
如上图所示,SD WebUI 的操作界面主要分为:模型区域、功能区域、参数区域、出图区域。
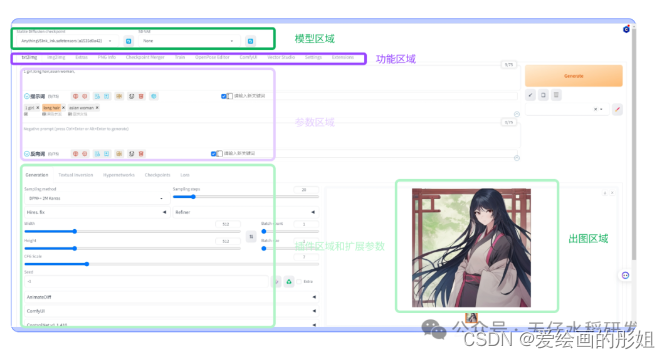
功能说明
txt2img 功能介绍

txtimg介绍
还有几个功能单独说一下:

功能
**Refiner:**了解 SDXL 的同学可能已经知道,SDXL 采用了一种两步走的生图方式,先用 1
个基础模型生成一张看起来差不多的图片,然后再使用一个精修模型把它打磨的更漂亮,那么在 SD 1.5 版本的非 XL
模型同样也能做这个事情,只是需要你手动加载,Refiner 提供了这样的功能。
第一个参数 checkpoint 就是你要精修的大模型, switch at 表示精修开始的步数百分比。(sampling steps * switch
at) 的结果表示精修模型开始参与的步数的开始。
**Textual Inversion/hypernetworks:**Textual Inversion 表示一种模型的训练方式,生成的模型类型为
embedding 模型。这种模型一般只有几十 k 大小,通常 3,5 张照片就能训练一个 embedding 类型的模型,主要用于固定画质,提升画风。
Hypernetworks 与 textual inversion
差不多都是一种小模型的训练方式,它们都不会改变原模型,会定义一些新的关键字实现特定的样式。它们的区别是在生成过程中作用的地方不同。实验表明
embedding 的效果比 Hypernetworks 要稍好一些。
**Checkpoints:**当前你添加的大模型都在这里。
**LoRA:**Lora 模型和 Hypernetworks 比较相似,都是通过作用于 UNet 的 cross-attention
模块,改变生成图像的风格。区别在于 LoRA 改变的是 cross-attention 的权重,而 Hypernetworks 插入了其他的模块。LoRA
的结果通常比 Hypernetworks 更好,而且模型结构都很小,基本都低于 200m。
img2img 功能介绍
img2img 功能可以生成与原图相似构图色彩的画像,或者指定一部分内容进行变换。可以重点使用 Inpaint 图像修补这个功能。
Resize mode
决定要对上传的图片做何种操作。
上传的图片最好与生图设置一致。
-
• Just resize:调整图片为生图设置的宽高。若上传图片的宽高与生成设置的宽高不一致,则该图片会被压扁
-
• Crop and resize:裁切图片以符合生图的宽高
-
• Resize and fill:裁切并调整图片宽高,若上传图片的宽高与生成设置的宽高不一致,则多出来的区域会自动填满。
-
• Just resize (latent upscale):调整图片大小为生图设置的宽高,并使用潜在空间放大。
Resize to
依照填入的宽高来生图。
Resize by
依照填入的缩放系数来生图,然后缩放图片。
Denoising strength 降噪强度
数值越小,生成的图与原图越相似,可用来微调图片。
在生成按钮的左边还有两个按钮:
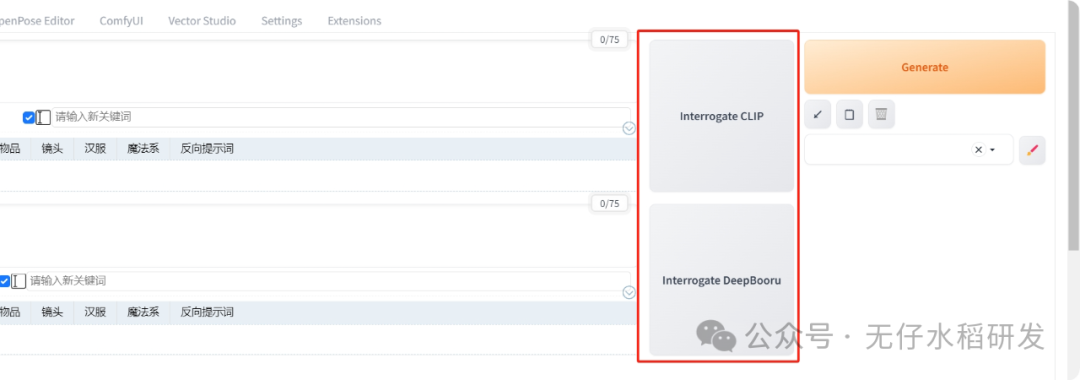
反推相关
这两个按钮的作用是反推提示词。算是一个附加功能,结果并不准确,只是给我们一个参考。如果是第一次使用,需要联网下载模型包。
CLIP 反推:侧重于对图像的描述,生成句子;
DeepBooru 反推:侧重于对图像内容的识别,生成 tag。
反推
左边是原始图片,右边分别是使用 CLIP 和 deepbooru 反推生成的图片描述和
tag。可以看到对于简单的图基本能描述一些大概,生成的标签也非常的详细,但是你如果用它来重新生成图片的话,效果如下:
反推
可以看到跟原图出入还是挺大的哈。
Sketch(绘图 ):适合有美术基础的用户,可以给一张现有的图加东西,或者画出你想要的东西,然后再输入提示词完善。
inpaint(局部绘制 )
很多时候我们对生成的图片 99% 都非常满意,就唯独那 1%
不满意,尤其是四肢混乱关节错位的问题尤为常见。这个时候我们只能忍痛重绘一张了吗?但是重绘又有可能大幅度改变图片的内容,应该怎么办呢?SD
的「局部重绘」的功能就是专门为了解决这个问题而存在的。它就像我们写作业时使用的涂改液一样,可以针对一张大图里的某一个区域覆盖重画,既能修正错误、又不至于撕掉重画一遍。
比如还是以上面的动漫图为例,首先我先基于这张图进行提示词反推:
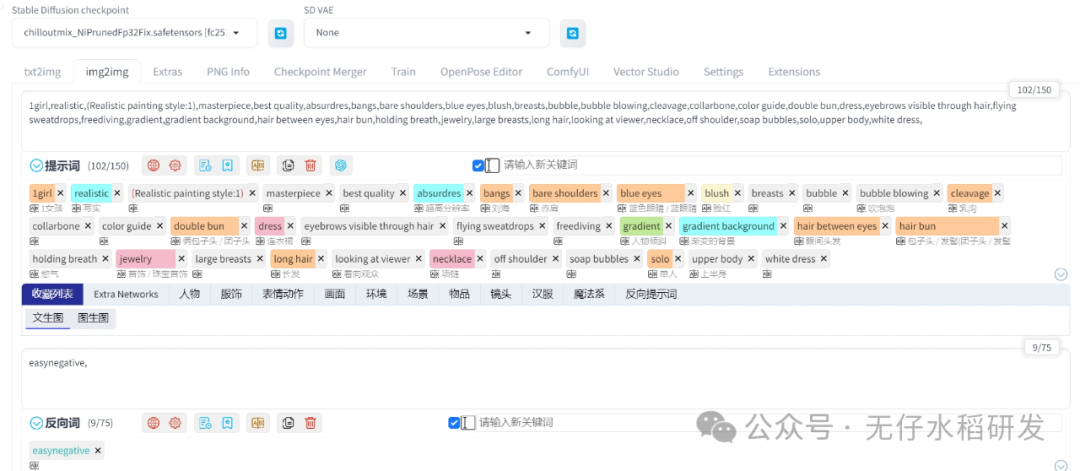
反推提示词
生成的提示词肯定有一些是不相关或者有误的,需要手动删除。现在是一张动漫人物,如果我们想基于这个动漫人物的相关特性生成一个真人图片要怎么做呢?很简单首先我们要找一个真人的模型,然后在提示词中去掉动漫相关的强场景词,然后加入写实风相关的强提示,比如:realistic。
风格转变
生成的图片如上,该有的都有哈!但是可以看到人物的左手臂有一点变形,对于这张图来说,这么美,我们不能因为手臂的问题就放弃了对吧,我们把这张图拖入放到
impaint 框:
修复
比如我们这张图的人物正面左边手臂明显看起来有点形变,手臂肌肉不够饱满。这里使用右上角的笔刷工具将我们想要修复的部位进行涂抹,被涂抹的部位表示是我们想修复的部位。涂抹完毕后需在正向关键词中添加你想修复的提示,比如:饱满修长的手臂。
然后可以再次点击生成:
修复
如果修复效果不如意,你可以多点击生成几次,总会有一次符合效果的。
impaint 模式下有几个参数需要注意:
Mask blur(蒙版模糊)
:图片上的笔刷毛边柔和程度。遮色片的模糊,用于控制遮罩图像的模糊程度,具体来说,遮罩模糊度越大,遮罩图像的边缘就越模糊,相邻像素之间的颜色差异就越小,从而导致修复图像的效果更加平滑和自然。相反,如果遮罩模糊度较小,则遮罩图像的边缘更加锐利,修复图像的效果可能会更加清晰和精细。需要注意的是,较大的遮罩模糊度可能会导致修复图像的细节丢失,因此需要权衡模糊度和修复图像的细节之间的平衡。
Mask mode (蒙版模式)
| 蒙版类型 | 描述 |
|---|---|
| Inpaint masked(重绘蒙版内容) | 帮我们重绘我们加遮色片的区域。 |
| Inpaint not masked(重绘非蒙版内容) | 会保留我们涂抹的遮色片区域并重新绘制图片的其他内容生成 一张新的图 |
Masked content(填充的内容类型) :要填充的内容类型。
| Masked content | 描述 |
|---|---|
| fill | 让 AI 参考涂黑附近的颜色填满区域。 |
| original | 在填满区域的时候参考原图底下的内容。 |
| latent noise | 使用潜在空间填满,可能会生出跟原图完全不相关的内容。 |
| latent nothing | 使用潜在空间填满,不加入噪声。 |
inpaint area(重绘区域) :
| Masked content | 描述 |
|---|---|
| Whole picture | 重绘整个图像区域 |
| Only masked | 只在蒙版区域内重绘 |
**Only masked padding, pixels:**个人理解为蒙版区域向外围扩展的像素数量,相当于对模板区域进行了一定程度放大。
Denoising strength(重绘幅度) :重绘幅度,取值范围是 0-1,默认设置 0.75。取值越大,说明图片变化越大,0
表示图片几乎不变,1 表示可能严重偏离原图。一般将该参数设置在 0.6~0.8 范围。
Inpaint Sketch
Sketch 是结合输入完整图像进行重绘,而 Inpaint Sketch 主要是基于蒙版区域内的图像进行重绘。
Inpaint upload
这里仍然是 Inpaint 模式,蒙版不再是通过鼠标绘制,而是可上传一张蒙版图片。Crop to fit 则相当于前面的 Crop and resize。
img2img 菜单我们就说这么多,基本的功能都覆盖了。
Extras 菜单
Extras 主要是对图片大小进行调整,比如进行等比例高清放大。有两个可切换的菜单选项:
| 菜单 | 描述 |
|---|---|
| Scale by | 图片放大倍数,默认为 4。放大倍数越大,分辨率尺寸越大,图片越清晰,所需时间也会相应有所增加 |
| Scale to | 将图片尺寸调整为指定宽高,类似于前文的 Resize mode |
**Upscaler 1:**采样模型。默认为 None,其中 LDSR 耗时长,ScuNET PSNR 适用于动漫效果,SwinIR_4x 效果较好。
**Upscaler 2:**采样模型,默认为 None,模型选项与 Upscaler 1
的一致。相当于可同时有两种模型来共同进行上采样,第二个模型的权重由 Upscaler 2 visibility 决定。
同样地,采样模型还可以加入 GFPGAN 和 CodeFormer,并可以设置其相应权重。Batch Process 和 Batch from
Directory 是用于多张图片的批量操作。
PNGinfo 配置
用于查看 SD 所生成的图片的图像信息,包括提示词、反向提示词、步骤数、采样器、种子等参数。
Checkpoint Merger
Checkpoint Merger
是指模型合并不同的模型,生成新的模型。我们可能会根据基础模型微调得到不同生成风格的新模型。合并不同的微调模型可能能够同时获得两种模型的生成特点。合并完成之后,新的模型也会保存在
models/Stable Diffusion 文件目录下,并且可以在网页页面直接选择调用。
| 功能 | 说明 |
|---|---|
| Primary model (A) Secondary model (B) Tertiary model © | |
| 用于选择将要合并的模型。需要注意,这些模型最好来自于同一类基础模型,具有相同的结构参数。如果模型结构不同,那么会出现参数不匹配的错误。 | |
| Custom Name (Optional) | 自定义合并后的模型名称 |
| Multiplier (M) - set to 0 to get model A | 模型合并时,A 模型所占权重比例 |
| Interpolation Method | 三种模型合并方法: |
| 1.No interpolation:不进行模型合并,仅对模型 A 进行转换。它可实现模型类型格式转换(ckpt/safetensors)或者增加 | |
| VAE(人脸修复等特定功能的编码优化算法)。 | |
| 2.Weighted sum:模型 A 和模型 B 合并,合并方式为 A _ (1 - M) + B _ M。 | |
| 3.Add difference:模型 A 与模型 B、C 之间的偏差进行合并,即 A + (B - C) * M。 | |
| Checkpoint format | 模型保存格式。Ckpt 是以字典格式保存,可以存储额外的脚本信息。Safetensors 则是纯粹保存 |
| tensors,不含额外的信息。因此,safetensors 格式更加安全 | |
| Save sa float16 | 保存为 float16(FP16)精度的模型,可以降低模型显存占用 |
| Copy config from | 复制模型的配置文件 |
| Bake in VAE | 增加 VAE(人脸修复等特定功能的编码优化算法) |
| Discard weights with matching name | 设置不参与合并的参数权重 |
Train
Train 用于自己训练或微调 Stable Diffusion,以在某些特定领域达到更好的结果。这里不进行介绍,下一节将单独详细介绍 Stable
Diffusion 的训练模式。
setting
主要是一些设置选项,作为新手的你此刻还用不上这里的功能,后面会慢慢接触到。
Extensions
Extensions 是一些扩展功能,例如 Lora 或 SwinIR 等模型功能。扩展还可以通过 Available 设置一些额外的展示信息。
AI绘画SD整合包、各种模型插件、GPT人工智能学习资料都已经打包好放在网盘中了,有需要的小伙伴文末扫码自行获取。
| 设置不参与合并的参数权重
Train
Train 用于自己训练或微调 Stable Diffusion,以在某些特定领域达到更好的结果。这里不进行介绍,下一节将单独详细介绍 Stable
Diffusion 的训练模式。
setting
主要是一些设置选项,作为新手的你此刻还用不上这里的功能,后面会慢慢接触到。
Extensions
Extensions 是一些扩展功能,例如 Lora 或 SwinIR 等模型功能。扩展还可以通过 Available 设置一些额外的展示信息。
AI绘画SD整合包、各种模型插件、GPT人工智能学习资料都已经打包好放在网盘中了,有需要的小伙伴文末扫码自行获取。
这是一位SD资深大神整理的,100款Stable Diffusion超实用插件,涵盖目前几乎所有的,主流插件需求。
这份完整版的AI绘画(SD、comfyui、AI视频)整合包已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】
全文超过4000字。
我把它们整理成更适合大家下载安装的【压缩包】,无需梯子,并根据具体的内容,拆解成一二级目录,以方便大家查阅使用。
单单排版就差不多花费1个小时。
希望能让大家在使用Stable Diffusion工具时,可以更好、更快的获得自己想要的答案,以上。
如果感觉有用,帮忙点个支持,谢谢了。
想要原版100款插件整合包的小伙伴,可以来点击下方插件直接免费获取
100款Stable Diffusion插件:
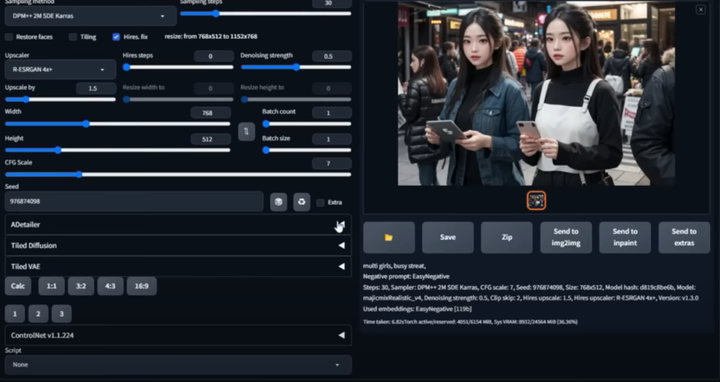
面部&手部修复插件:After Detailer
在我们出图的时候,最头疼的就是出的图哪有满意,就是手部经常崩坏。只要放到 ControlNet 里面再修复。
现在我们只需要在出图的时候启动 Adetailer 就可以很大程度上修复脸部和手部的崩坏问题
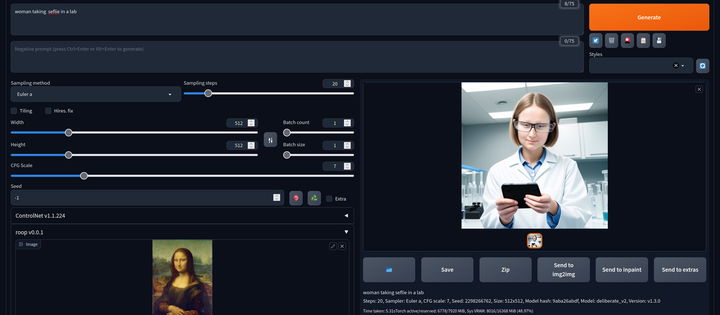
AI换脸插件:sd-webui-roop
换脸插件,只需要提供一张照片,就可以将一张脸替换到另一个人物上,这在娱乐和创作中非常受欢迎。
模型预设管理器:Model Preset Manager
这个插件可以轻松的创建、组织和共享模型预设。有了这个功能,就不再需要记住每个模型的最佳 cfg_scale、实现卡通或现实风格的特定触发词,或者为特定图像类型产生令人印象深刻的结果的设置!

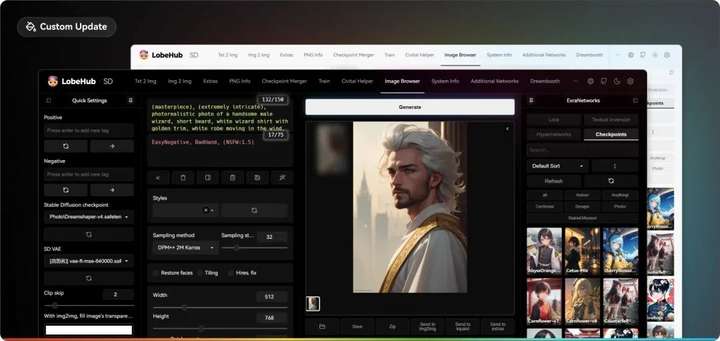
现代主题:Lobe Theme
已经被赞爆的现代化 Web UI 主题。相比传统的 Web UI 体验性大大加强。
提示词自动补齐插件:Tag Complete
使用这个插件可以直接输入中文,调取对应的英文提示词。并且能够根据未写完的英文提示词提供补全选项,在键盘上按↓箭头选择,按 enter 键选中

提示词翻译插件:sd-webui-bilingual-localization
这个插件提供双语翻译功能,使得界面可以支持两种语言,对于双语用户来说是一个很有用的功能。
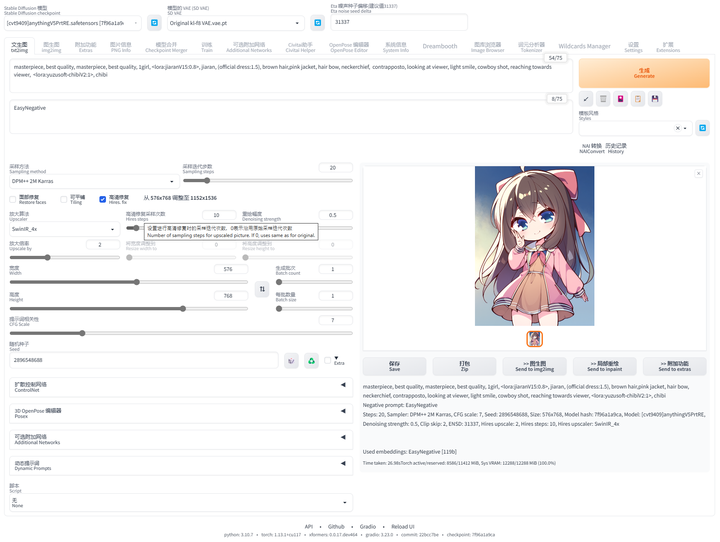
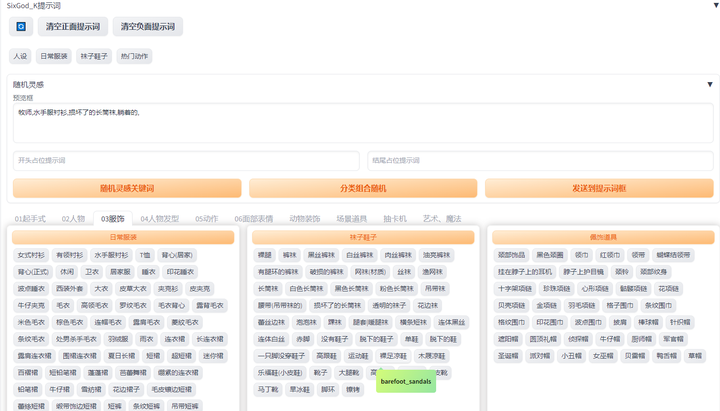
提示词库:sd-webui-oldsix-prompt
提供提示词功能,可能帮助用户更好地指导图像生成的方向。
上千个提示词,无需英文基础快速输入提示词,该词库还在不断更新。
以后再也不担心英文写出不卡住思路了!
这份完整版的AI绘画(SD、comfyui、AI视频)整合包已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

















 7547
7547

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









