






最近 AI 绘画火出圈了!无论是生成二次元头像、科幻场景,还是艺术创作,Stable Diffusion(SD)都能轻松搞定。今天,我们就来一篇超详细的教程,手把手教你从零开始部署 Stable Diffusion,让你也能成为 AI 绘画高手!
一、什么是 Stable Diffusion?
Stable Diffusion 是一款开源的文本生成图像模型,它可以根据你输入的文字描述(Prompt)生成高质量的图像。无论是风景、人物、还是抽象艺术,它都能轻松驾驭。更重要的是,它支持本地部署,完全免费,让你可以自由定制和优化!
二、部署前的准备工作
在开始之前,确保你的电脑满足以下条件:
1. 硬件要求
-
操作系统:Windows 10/11 或 Linux(推荐 Ubuntu 20.04)。
-
显卡:推荐 NVIDIA GPU,显存至少 4GB(8GB 以上效果更佳)。
-
内存:至少 16GB。
-
硬盘空间:至少 10GB 空闲空间。
2. 软件要求
-
Python 3.8+:Stable Diffusion 依赖 Python 环境。
-
CUDA 和 cuDNN:如果你使用 NVIDIA GPU,需要安装与显卡匹配的 CUDA 和 cuDNN 版本。
这份完整版的SD整合包已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

三、详细部署步骤
--------
### 步骤 1:安装 Python 和 Git
-
- 下载 Python:
-
访问 Python 官网,下载并安装 Python 3.8 或更高版本。
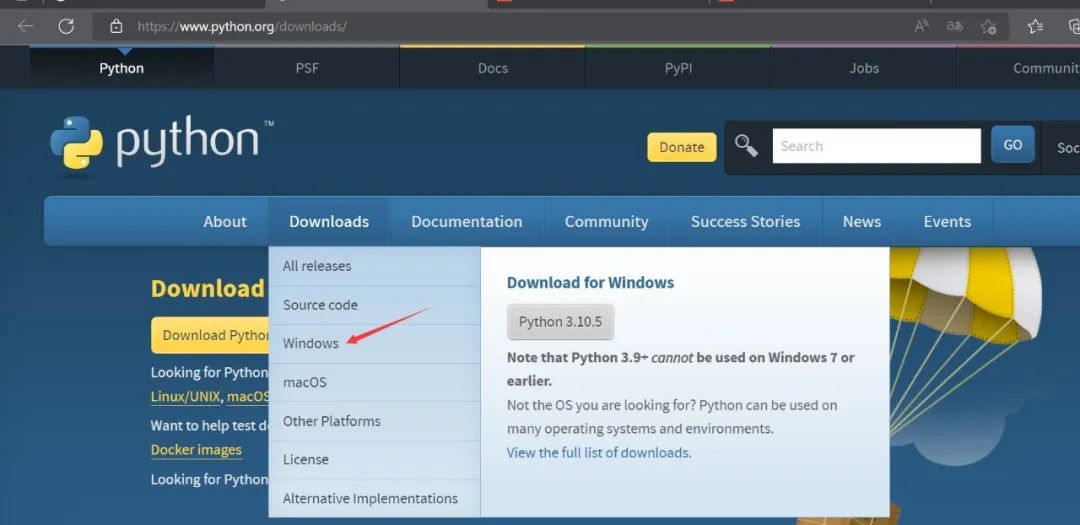 安装时记得勾选 **“Add Python to PATH”**,这样可以在命令行中直接使用 Python。-
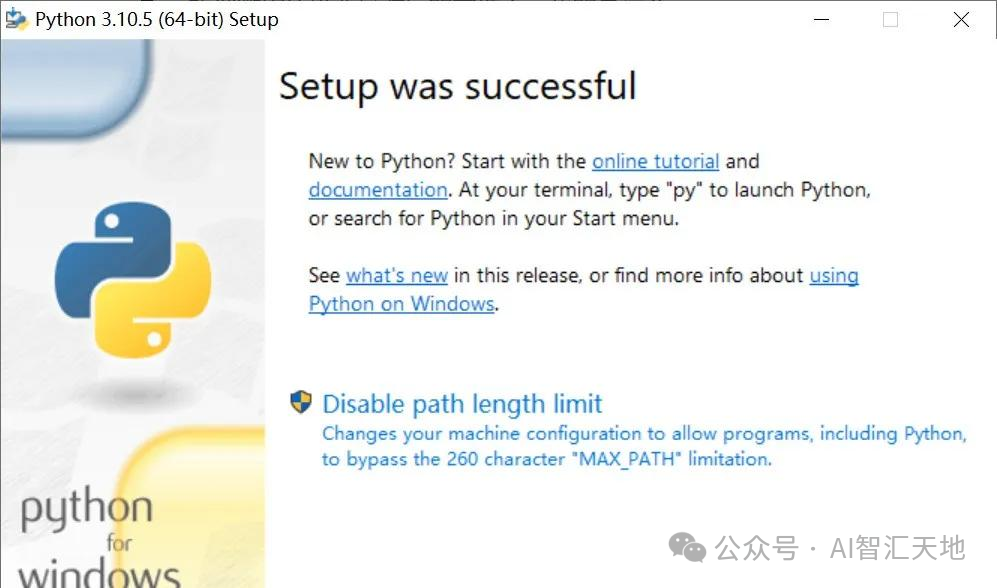
-
安装 Git:
-
访问 Git 官网,下载并安装 Git。
-
安装完成后,打开命令行(Windows 按
Win + R,输入cmd;Mac/Linux 打开终端),输入以下命令检查是否安装成功: -

- 安装 cuDNN:
-
访问 NVIDIA cuDNN 下载页面,下载与 CUDA 版本匹配的 cuDNN。
-
解压下载的文件,将其中的
bin、include和lib文件夹复制到 CUDA 安装目录下(默认路径为C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.8)。
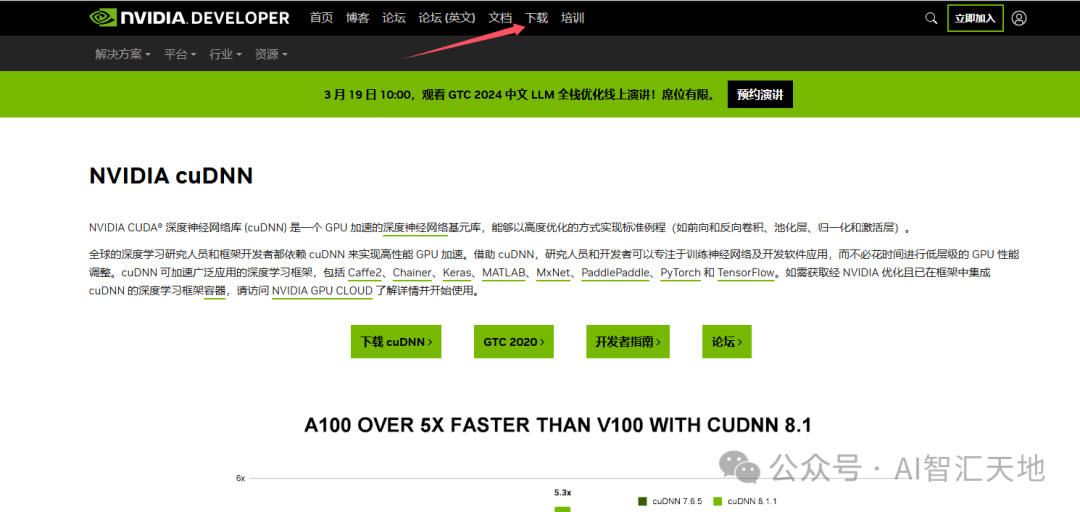
步骤 3:创建虚拟环境
为了避免依赖冲突,建议创建一个独立的 Python 虚拟环境
打开命令行,输入以下命令安装虚拟环境工具:

-
-
创建一个新的虚拟环境:
-

激活虚拟环境:
- Windows:

Mac/Linux

步骤 4:安装 PyTorch 和依赖
- 安装 PyTorch 和 CUDA 支持:

安装其他依赖

四、启动 Stable Diffusion Web UI
步骤 1:下载 Web UI 代码
-
打开命令行,克隆 Web UI 仓库
-

步骤 2:安装依赖
- 运行安装脚本:
-
Windows:双击
webui-user.bat。 -
Mac/Linux:运行以下命令:
-

步骤 3:启动 Web UI
-
安装完成后,打开浏览器,访问
http://127.0.0.1:7860,即可使用 Web UI 生成图像。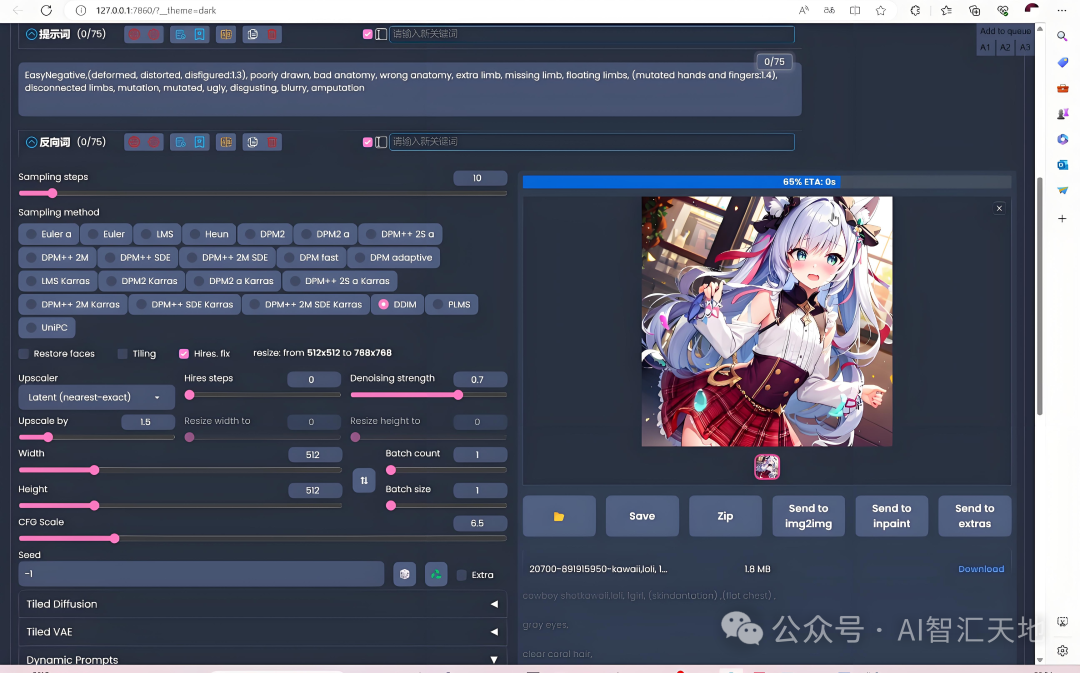
-
五、使用技巧
-
1. 优化 Prompt
-
具体描述:越详细的描述,生成的图像越符合预期。
-
风格关键词:例如
trending on artstation,oil painting,cyberpunk style。 -
负面 Prompt:指定不希望出现的元素,例如
low quality, blurry, distorted。
2. 调整参数
-
采样步数(Steps):推荐 20-50 步。
-
CFG Scale:推荐 7-12。
-
随机种子(Seed):固定种子可以生成相同的图像。
3. 批量生成
使用循环批量生成图像:

六、常见问题
1. 显存不足怎么办?
-
降低图像分辨率。
-
使用
torch.cuda.empty_cache()清理显存。 -
尝试 CPU 模式(速度较慢)。
2. 生成的图像不符合预期?
-
-
这份完整版的SD整合包已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【
保证100%免费】

















 4122
4122

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









