






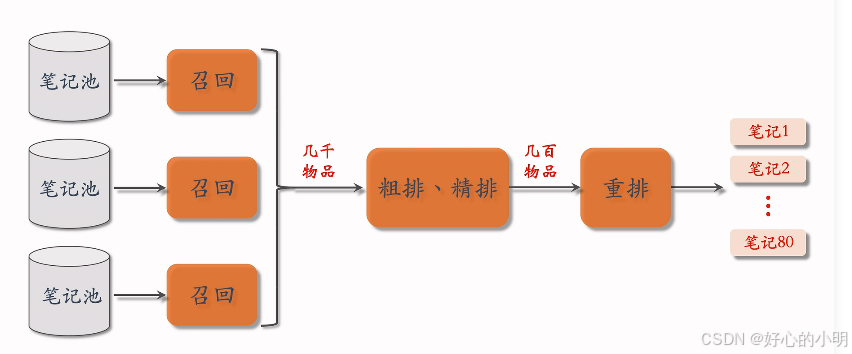
推荐系统的链路
用户——笔记的交互
- 对于每篇笔记,系统记录:曝光次数,点击次数,点赞次数,收藏次数,转发次数
- 可以用消费指标衡量受欢迎程度
- 排序模型预估点击率,点赞率,收藏率,转发率等多种分数
- 融合这些预估分数(比如加权和)
- 根据融合的分数做排序和阶段
多目标模型
- 排序模型的输入是各种各样的特征
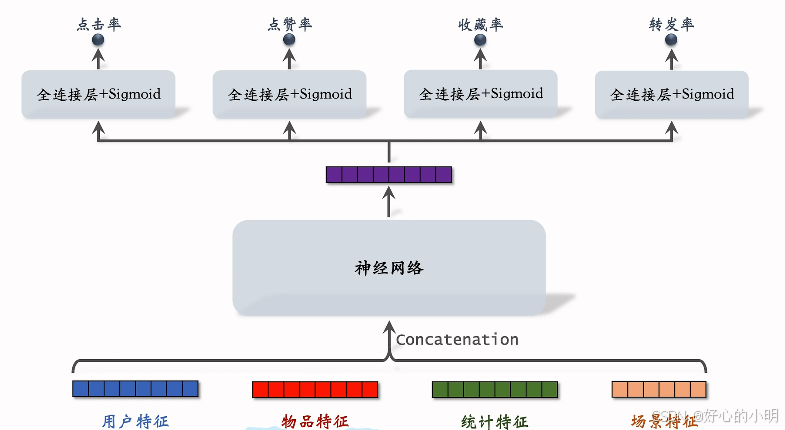
- 用真实的信息来训练模型

- 训练的困难:类别不平衡。没100次点击,约有10次点击,90次无点击。没100次点击,约有10次收藏,90次无收藏。太多的负样本没啥用,白白浪费资源
- 解决方案:负样本降采样。保留一小部分负样本,让正负样本数量平衡,节约计算
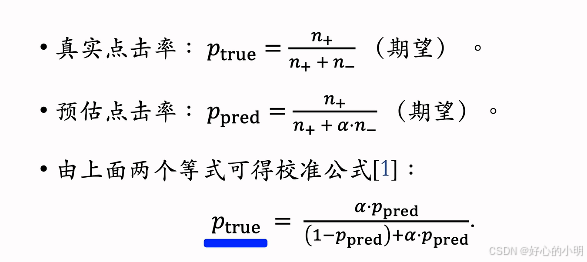
预估值校准
- 负样本一般会远大于正样本
- 对负样本做降采样,抛弃一部分负样本
- 使用 α·n- 个负样本,其中 α 是采样率
- 由于负样本变少,预估点击率大于真实点击率

















 889
889

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









