







相关性模型
- 现在搜索引擎普遍使用BERT模型计算 q 和 d 的相关性
- 交叉BERT模型(单塔)准确率好,但是推理代价大,通常用于链路下游(精排,粗排)
- 双塔BERT模型不够准确,但是推理代价小,常用于链路上游(粗排,召回海选)
- 训练相关性BERT的 4 个步骤:预训练,后预训练,微调,蒸馏
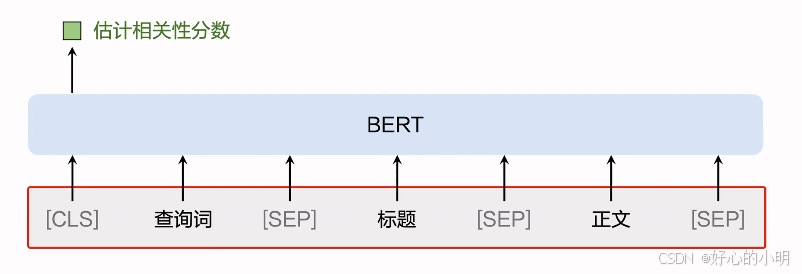
交叉BERT模型
- 交叉的意思是自注意力层对查询词和文档进行了交叉

字粒度 vs 字词混合粒度
- 字粒度:将每个汉字/字符作为一个token
- 词表较小(几千),只包含汉字,字母,常用字符
- 优点:实现简单,无需做分词,可以作为好的baseline
- 字词混合粒度:做分词,将分词结果作为 tokens
- 词表较大(几万,几十万),包含汉字,字母,常用符号,常用中文短语,常用英文单词
- 与字粒度相比,字词混合粒度得到的序列长度更短
- 序列更短有什么好处?
- BERT的计算量是token数量的超线性函数
- 为了控制推理成本,会限定token数量,例如128或256
- 如果文档超出token数量上限,会被阶段,或者做抽取式摘要
- 使用字词混合粒度,token数量更少,推理成本降低(字粒度需要256 token,字词混合粒度只需要128 token)
交叉BERT模型的推理降本
- 对每个 (q,d) 二元组计算相关性分数score,代价很大
- 用Redis这样的KV数据库缓存 (q,d,score)
- (q,d) 作为 key,相关性分数作为value
- 如果缓存命中,则避免计算
- 如果超出内存上限,那么用LRU清理缓存
- 模型量化技术,例如将float32转化成int8
- 训练后量化(PTQ, post-training quantization)
- 训练中量化(QAT, quantization-aware training)
- 使用文
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1024
1024

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









