






- 有时我们希望保存训练的模型以在将来的各种环境中使用
- 当运行一个耗时较长的训练过程时,最佳的做法是定期保存中间结果,以防止服务器电源被不小心断掉而导致浪费掉前面的训练
1. 加载和保存张量
- 对于单个张量,我们可以直接调用
load和save分别读写它们 - 两个函数都要求我们提供一个名称,其中
save要求将保存的变量作为输入
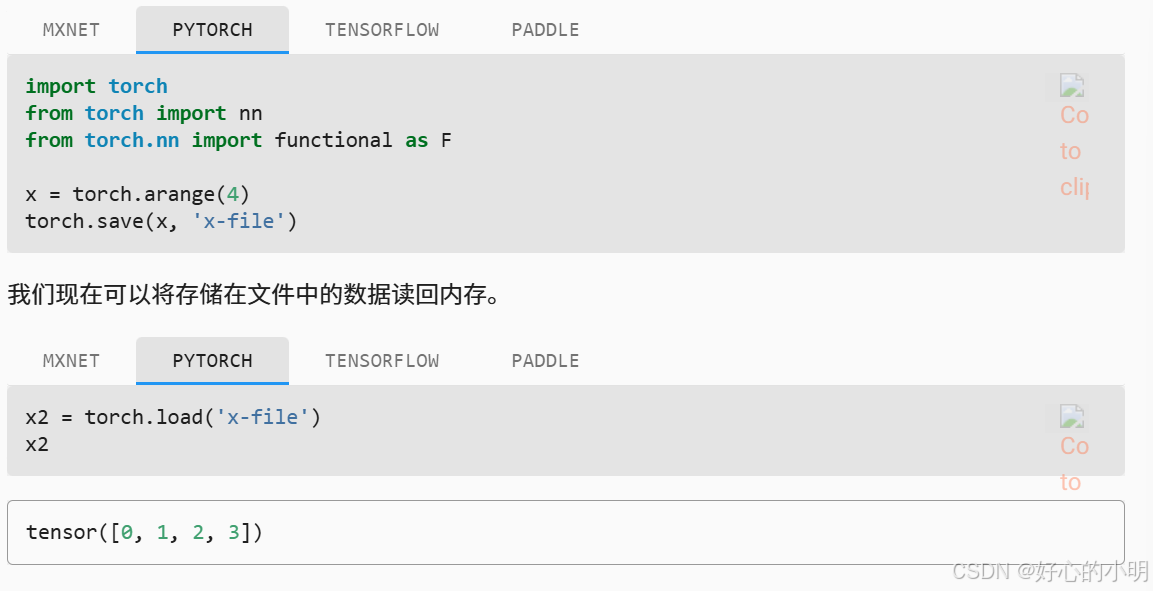
- 可以存储一个张量列表,然后将它们读回内存

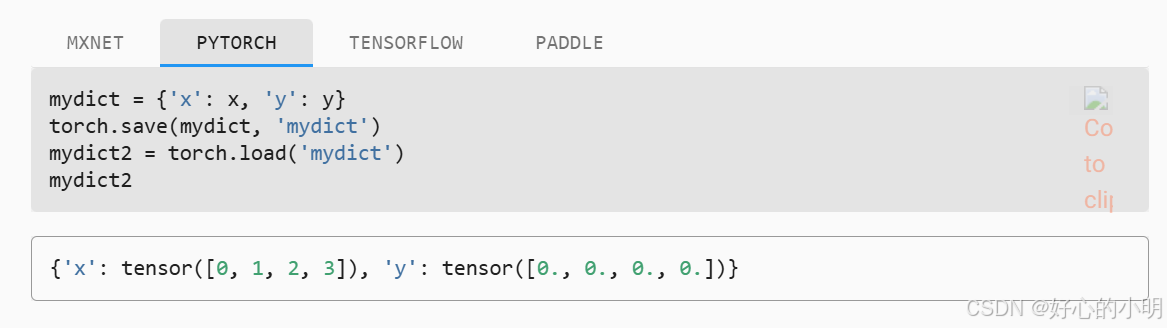
- 还可以写入或者读取字符串映射到张量的字典,这在我们要读取和写入模型中的所有权重时很方便
2. 加载和保存模型参数
- 如果我们想保存一整个模型的参数,像上面那样一个个保存张量会很麻烦
- 不过深度学习框架提供了内置函数来加载和保存整个模型。不过保存的是模型的参数而不是整个模型。
- 由于模型本身可以包含任意代码,所以模型本身是难以序列化的。所以为了恢复模型,我们需要用代码生成架构后再加载保存好的参数,下面我们从MLP开始尝试
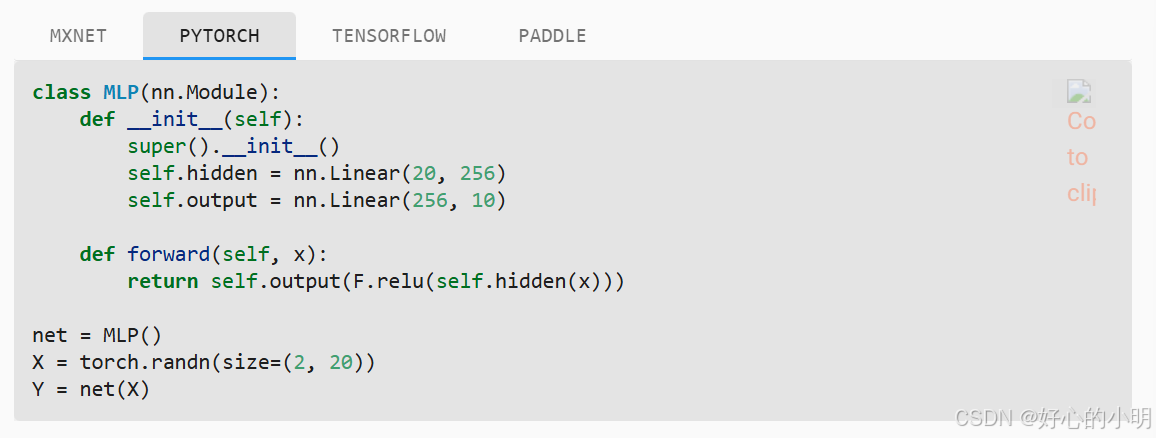
- 我们用
save进行保存,注意这里保存的是net.state_dict()

- 下面我们实例化一个MLP,但是不随机初始化模型参数,而是直接读取文件中的参数
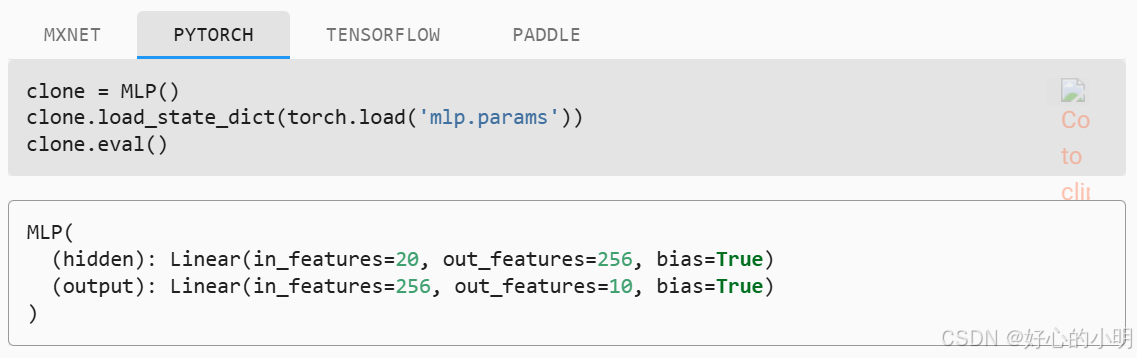
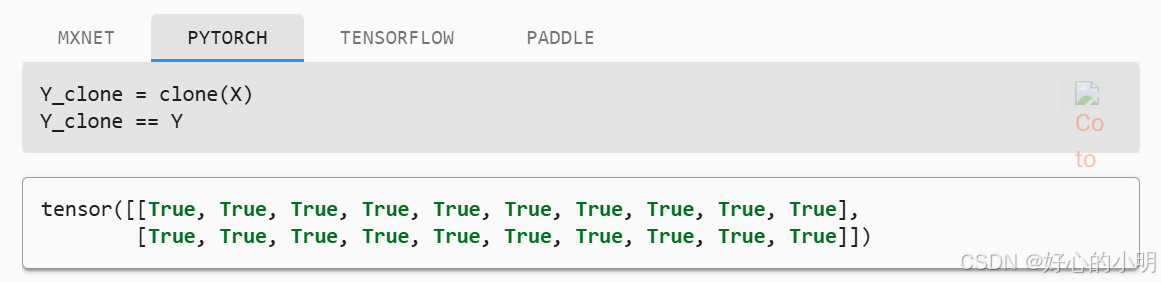
- 由于两个实例有相同的参数,所以在输入相同时它们的输出应该是相同的


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









