







什么是“对抗样本攻击”
笔者给“对抗样本攻击”下的定义是:通过精心的构造原始数据,使得机器学习模型以较大概率返回和事实相反的结果。
最经典的例子就是对于图像、人脸识别系统的攻击样本了。比如
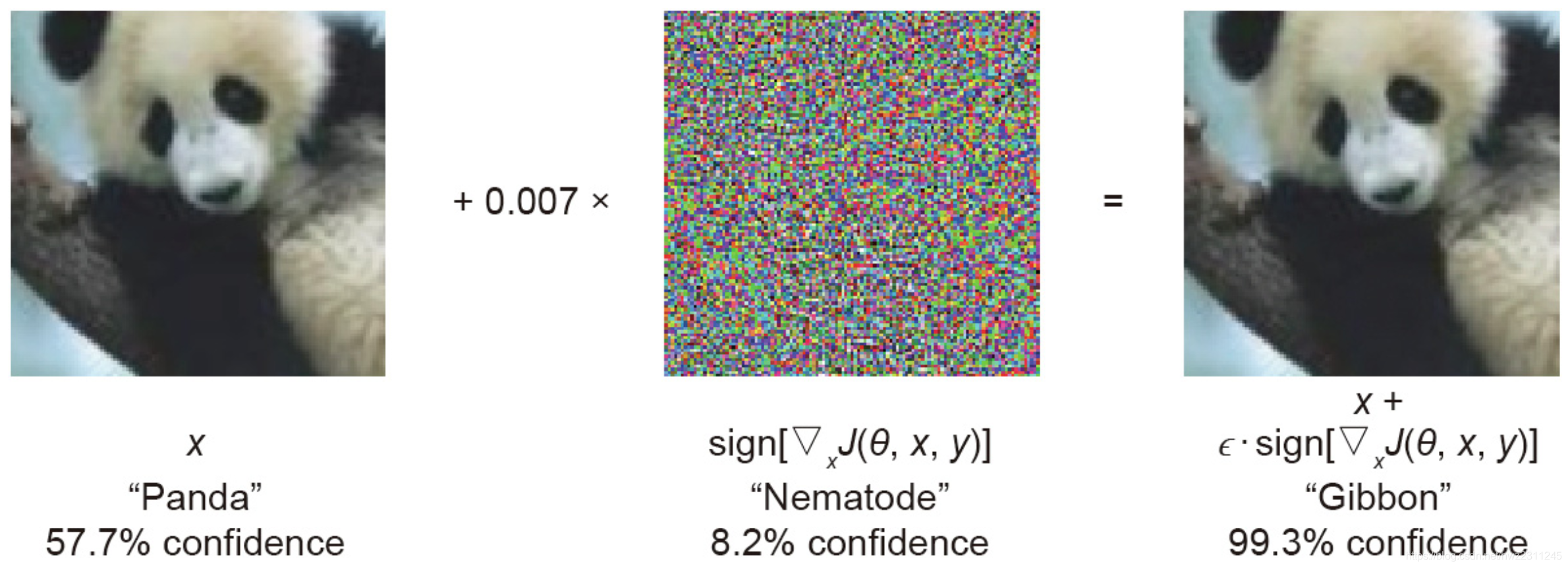
- 加入一些噪点,让GoogleNet把“熊猫”当成“长臂猿”:
- 带上一个眼睛,让人脸识别模型连性别都搞错:

“对抗样本攻击”的现实意义
上面这些例子,简单看起来很恐怖,因为和事实偏差极大。但在此需要强调的是,对抗样本攻击的可怕之处,不仅仅在于它使得模型结果和事实偏差极大,更在于它可以将这种偏差变成必然:上面的例子仅仅是个例,事实上,任何机器学习算法都无法保障100%的准确率,因此,有个别的失误其实并不说明什么。但是,研究表明,通过对抗样本攻击,可以让一个准确率90%的图像识别算法,直接把准确率降到0%。将偶然变成必然,才是对抗样本攻击,真正可怕的地方。
再来打个比方。2015年,全球航班失事的概率是1/200万,每638万坐飞机的就有一个死于空难。这个概率显然非常低,低到让你甘于冒1/638万的风险,仍然去选择飞机的便利性
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 339
339

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









