




 本文深入解析DenseNet结构,包括DenseBlock、DenseNet-B、Transitionlayer等关键组件,以及与ResNet的比较,揭示其在特征传递、模型紧凑性和隐性深度监督方面的优势。
本文深入解析DenseNet结构,包括DenseBlock、DenseNet-B、Transitionlayer等关键组件,以及与ResNet的比较,揭示其在特征传递、模型紧凑性和隐性深度监督方面的优势。
深度学习论文精读(2):DenseNet
论文地址:Densely Connected Convolutional Networks
译文地址:https://blog.youkuaiyun.com/tumi678/article/details/78667966
作者github地址:https://github.com/liuzhuang13/DenseNet
参考博客1:https://blog.youkuaiyun.com/u011974639/article/details/78290448
参考博客2:https://blog.youkuaiyun.com/u014380165/article/details/75142664
文章目录
1.总体介绍
- ResNet的研究表明,更深的网络和输入输出间存在快捷通道(shortcut connection)能够有效的提升正确率。
- 作者接收并拓展了这个观点,利用快捷通道(shortcut connection)的结构,设计了DenseNet的结构。
- 即使每一层的输入是之前全部层feature-maps,每一层输出的feature-maps是之后所有层的输入。
- 起到的效果有:
- 减轻了梯度消失问题(vanishing-gradient)
- 加强了特征的传递
- 强调特征复用,更有效的利用了特征
- 一定程度上减少了参数的数量
2.DenseNet结构
2.1Dense Block结构
-
DenseNet的思想为,将所有size相同的层直接相连。(connect all layers (with matching feature-map sizes) directly with each other)
-
Dense Block由若干单元组成,每个单元的结构为(BN-Relu-Conv)。
-
在同一个Dense Block中,每个单元的输入,包含了之前所有单元的输出(是之前所有输出的concat结构)。
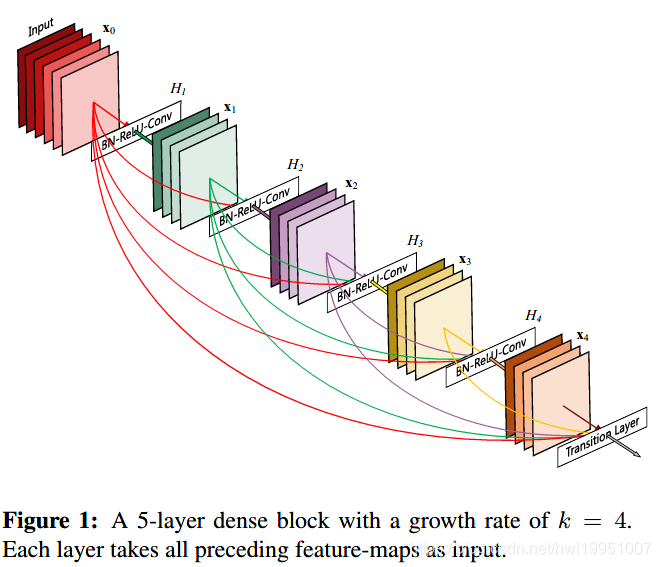
-
原文中提到:Each layer has direct access to the gradients from the loss function and the original input signal, leading to an implicit deep supervision。直接解释了为什么这个网络的效果会很好。
- 梯度消失问题在网络深度越深的时候越容易出现,原因是输入信息和梯度信息在很多层之间传递导致的,而现在这种DenseNet中,相当于每一层都直接连接input和loss,因此就可以减轻梯度消失现象。
-
ResNet与DenseNet的区别:
- 在ResNet中,每一层的输出为 x l = H l ( x l − 1 + x l − 1 ) x_l = H_l(x_{l-1} + x_{l-1}) xl=Hl(xl−1+xl−1)。
- 在DenseNet中,每一层的输出为 x l = H l ( [ x 0 , x 1 , … , x l − 1 ] ) x_l = H_l([x_0,x_1,…,x_{l-1}]) xl=Hl([x0,x1,…,xl−1])。
- H l ( ) H_l() Hl()指在 l l l层的复合操作函数, x l x_l xl指 l l l层的输出。
-
Growth Rate:Dense Block中,每增加一个基本单元(BN-Relu-Conv)后增加多少filter。
-
- 假设某个Dense Block的输入是 k 0 k_0 k0维数据,则该Dense Block中,第 l l l个基本单元(Bn-Relu-Conv)的输入为 k 0 + k ∗ ( l − 1 ) k_0+k*(l-1) k0+k∗(l−1)维数据,其中 k k k就是growth rate。
2.2 DenseNet-B
-
尽管每层只产生 k k k个feature-maps,但依然太多了。作者发现在DenseNet上使用bottleneck layer(1x1 conv) 很有效,因此设计了DenseNet-B结构:
BN →Relu→bottleneck layer(1x1 conv) →BN →Relu→Conv(3x3)
在实验中,bottleneck layer获得的新通道数为 4 k {4}k 4k,即4倍的Growth rate。
2.3 Transition layer
- 结构:BN →bottleneck layer(1x1 conv) + average pooling(2x2)
- 作用:降维,减少feature maps的(H、W、C)长、宽、通道数。
- compression factor θ \theta θ 用作降维,减少feature-maps的个数。将 θ < 1 \theta<1 θ<1的结构称为DenseNet-C结构。在实验中,设置的 θ = 0.5 \theta=0.5 θ=0.5。
- θ < 0.5 \theta<0.5 θ<0.5并且在Dense block内使用了bottleneck layer的结构称为DenseNet-BC。
2.4 总体结构
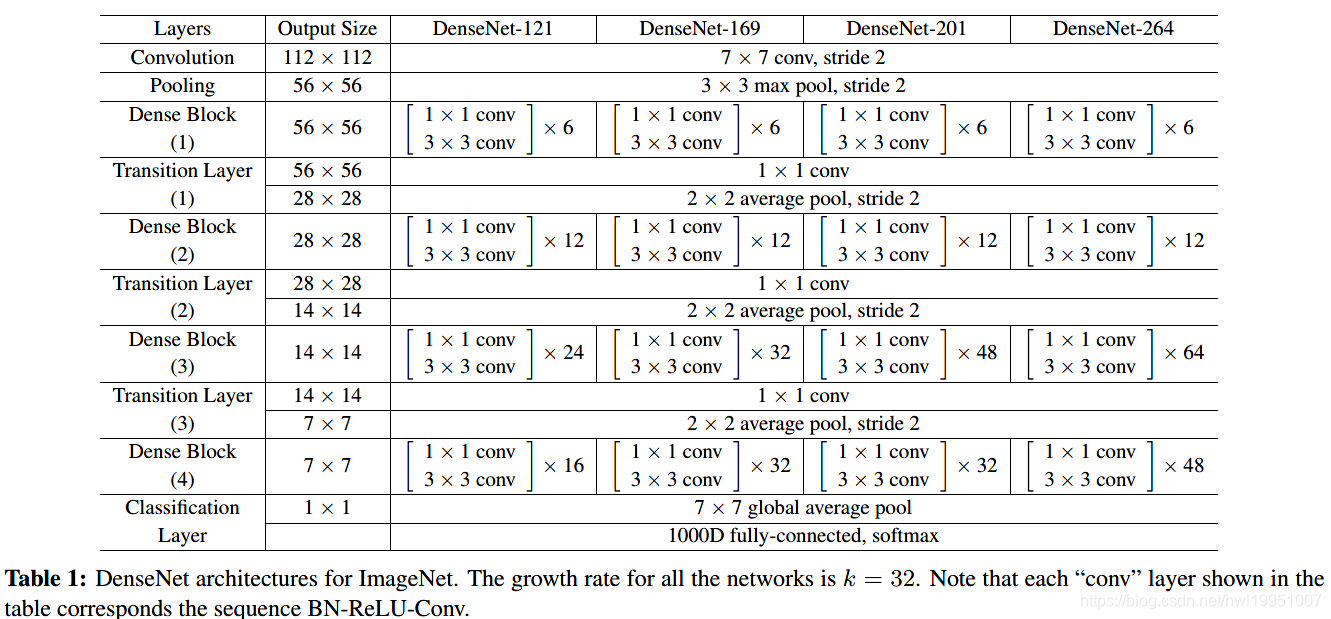
- 由于卷积网络必须有下采样(通常为pooling层)来减小特征维度,DenseNet的连接方式也无法满足不同的特征维度。因此将网络分成多个DenseBlock。中间利用Transition layer进行降维。如下图。

- Growth rate k=32时,ImageNet下,不同的DenseNet构架。
3. ResNet与DenseNet的比较
-
Model compactness(模型效率更高)
使用DenseNet-BC结构的DenseNet能用更少的参数得到比ResNet更好的效果。
-
Implicit Deep Supervision(隐形深度监督)
每一个隐藏层最多通过3个transition layer就可以直接获得loss function的反馈,加强了所有层的学习。
-
Stochastic vs. deterministic connection(随机连接与确定性连接)
对ResNet的layers进行random drop可以获得更好的效果,而这样做的直观目的是连接更多的residual block。而DenseNet则是直接将所有layer连接起来了,因此效果更好。
-
Feature Reuse(特征复用)
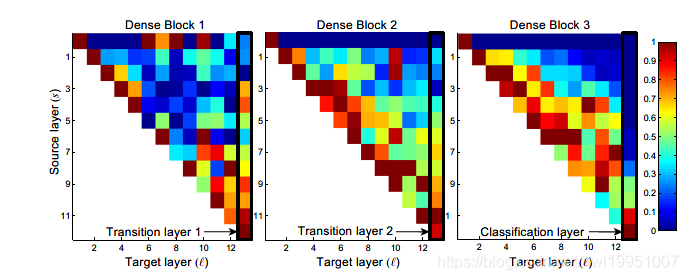
上图为Dense Block内部的Source layer 与 Traget layer 间 weight绝对值。可以看出:
- 早期的Dense Block中,早期特征还是较多得被后面层利用的。
- 后期的Dense Block中,早期特征利用的不做,更主要的还是相邻层之间的特征。这可能与深层特征的抽象性有关。
- 还是有很多的冗余连接。相隔过远的层之间,特征复用率就极低,尤其是经过trainsition layer后的第一层。这也是DenseNet-BC效果好的原因(压缩了transition layer后的feature-maps)。
单词整理:
- compelling
- alleviate
- dominant
- surpass
- parallel
- distill
- explicit
- amplify
- cascade
- bypass
- redundancy
- facilitate
- orthogonal
- impede

















 7004
7004

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









