






 本文深入探讨了浏览器中的EventLoop机制,详细阐述了浏览器渲染进程中的JS引擎线程、GUI渲染线程、事件触发线程、定时触发器线程和异步请求线程的工作原理。解释了同步任务与异步任务的执行流程,以及宏任务和微任务在事件循环中的角色。同时,通过实例分析了代码执行顺序,帮助理解JS的执行模型。
本文深入探讨了浏览器中的EventLoop机制,详细阐述了浏览器渲染进程中的JS引擎线程、GUI渲染线程、事件触发线程、定时触发器线程和异步请求线程的工作原理。解释了同步任务与异步任务的执行流程,以及宏任务和微任务在事件循环中的角色。同时,通过实例分析了代码执行顺序,帮助理解JS的执行模型。
前言
EventLoop就是事件循环,在前端概念中通常用来指浏览器或者Node环境中,用于解决JavaScript单线程运行时不会阻塞的一种机制。这篇文章我们主要来了解一下浏览器中JS的EventLoop是怎么运行的。
在进入EventLoop的概念前,我们不妨先大致梳理一下两个概念,即:
浏览器在这中间到底做了什么事情 以及 JS是单线程运行的。
进程/线程
身为web前端工程师,我们使用的JS多运行在浏览器上。每当我们打开一个浏览器的时候,实际上我们就是在我们新打开了一个浏览器进程,在浏览器进程中我们才运行的JS线程
进程就是一个工厂 ---> 工厂间也是互相独立的
线程就是每个工厂的工人 ---> 工人 相互协作在工厂中完成任务
在我们任务管理器中打开,第一个tab就是进程列表
实际上进程就是cpu资源分配的一个单位
线程就是cpu能调度的一个单位
一般通用的叫法:单线程与多线程,都是指在一个进程内的单线程和多线程
同时我们的浏览器也是多进程的,比如我开了17个谷歌的tab页。浏览器帮我+1了
简单点理解,每打开一个Tab页,就相当于创建了一个独立的浏览器进程。
(如果浏览器是单进程,那么某个Tab页崩溃了,直接整个浏览器全G了)
所以我们得出了个结论:在浏览器中打开一个网页相当于新起了一个进程
浏览器渲染进程
JS执行,页面渲染,事件循环都是在我们浏览器渲染的这个进程中执行0的。
1.GUI渲染进程
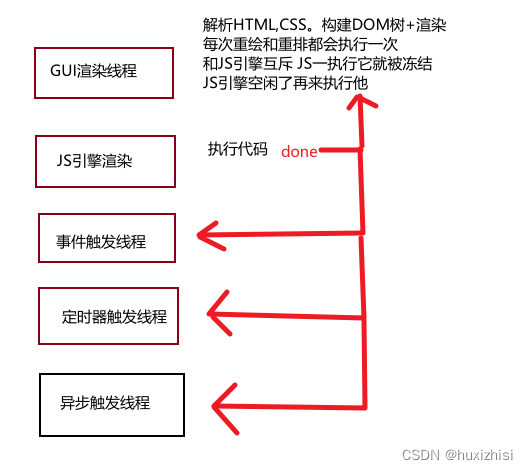
负责渲染浏览器界面,解析HTML,CSS,构建DOM树和RenderObject树,布局和绘制等
当界面需要重绘(Repaint)或由于某种操作引发回流(reflow)时,该线程就会执行
注意,GUI渲染线程与JS引擎线程是互斥的,当JS引擎执行时GUI线程会被挂起(相当于被冻结了),
GUI更新会被保存在一个队列中等到JS引擎空闲时立即被执行。
2.JS引擎线程
也称为JS内核,负责处理Javascript脚本程序。(例如V8引擎)
JS引擎线程负责解析Javascript脚本,运行代码。
JS引擎一直等待着任务队列中任务的到来,然后加以处理。
一个Tab页(renderer进程)中无论什么时候都只有一个JS线程在运行JS程序。
同样注意,GUI渲染线程与JS引擎线程是互斥的,所以如果JS执行的时间过长,就会导致页面渲染加载阻塞。
3.事件触发线程
归属于浏览器而不是JS引擎,用来控制事件循环(JS引擎自己都忙不过来,需要浏览器另开线程协助)
当JS引擎执行代码块如setTimeOut时(也可来自浏览器内核的其他线程,如鼠标点击、AJAX异步请求等),会将对应任务添加到事件线程中
当对应的事件符合触发条件被触发时,该线程会把事件添加到待处理队列的队尾,等待JS引擎的处理
注意,由于JS的单线程关系,所以这些待处理队列中的事件都得排队等待JS引擎处理(当JS引擎空闲时才会去执行)
4.定时触发器线程
setInterval与setTimeout所在线程
浏览器定时计数器并不是由JavaScript引擎计数的
(因为JavaScript引擎是单线程的, 如果处于阻塞线程状态就会影响记计时的准确)
因此通过单独线程来计时并触发定时
(计时完毕后,添加到事件队列中,等待JS引擎空闲后执行)
注意,W3C在HTML标准中规定,规定要求setTimeout中低于4ms的时间间隔算为4ms。
5.异步请求线程
XHR在连接后是通过浏览器新开一个线程请求
将检测到状态变更时,如果设置有回调函数,异步线程就产生状态变更事件,将这个回调再放入事件队列中。再由JavaScript引擎执行。
小问题: css加载是否会阻塞dom树渲染?
css是由单独的下载线程异步下载的
css加载不会阻塞DOM树解析(异步加载时DOM照常构建)
但会阻塞render树渲染(渲染时需等css加载完毕,因为render树需要css信息)
JS的EventLoop
到此时,已经是属于浏览器页面初次渲染完毕后的事情,JS引擎的一些运行机制分析。
这里主要是结合Event Loop来谈JS代码是如何执行的,不做多的引申。
在这里我们会用到上文的几个概念:
1.JS引擎线程
2.事件触发线程
3.定时触发器线程
JS分为同步任务和异步任务
同步任务都在主线程上执行,形成一个执行栈
主线程之外,事件触发线程管理着一个任务队列,只要异步任务有了运行结果,就在任务队列之中放置一个事件。
一旦执行栈中的所有同步任务执行完毕(此时JS引擎空闲),系统就会读取任务队列,将可运行的异步任务添加到可执行栈中,开始执行。
练习题
阅读以下代码写出打印的执行顺序
console.log(1);
setTimeout(() => {
console.log(2);
}, 1000);
console.log(3);
setTimeout(() => {
console.log(4);
}, 0);
console.log(5);
执行的顺序应该为
1.读取console.log(1) 同步执行 JS引擎线程执行
2.读取到setTimeout,添加到定时触发器线程中,定时器触发器开始计时,1s后推到任务队列里
3.读取到console.log(3),同步执行 JS引擎线程执行
4.读取到setTimeout,添加到定时触发器线程中,定时器触发器开始计时,4ms后推到任务队列里
5.读取到console.log(5),同步执行 JS引擎线程执行
6.读取到JS引擎线程执行完成,系统读取任务队列
所以最终的 打印顺序是15342
在JS的事件循环中,还需要知道宏任务与微任务的概念
宏任务:MacroTask
如:setTimeout、setInterval、script、 I/O 操作等。
微任务:MicroTask
如: Promise,Ajax,async等
宏任务队列可以有多个
微任务队列只能有一个
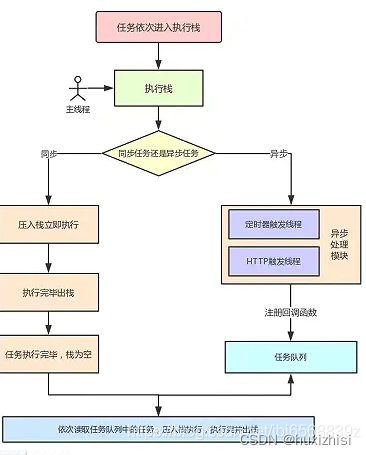
1. 任务会依次进入执行栈,而首先入场的就是——宏任务全局上下文(script);
2. 执行同步任务;
3. js 引擎遇到一个异步任务后并不会一直等待其返回结果:
3.1 遇到异步任务,交给异步处理模块处理,对应的异步处理线程处理异步任务需要的操作,例如定时器的计数和异步请求监听状态的变更;
3.2 当异步事件返回结果后,事件触发线程将回调函数(标记)加入任务队列,等待栈为空时,依次进入栈中执行;
4. 执行栈在执行完同步任务后,查看执行栈是否为空,如果执行栈为空:
4.1 先检查微任务(microTask)队列,如果存在任务,则一次性执行完所有微任务,无任务则跳过
4.2 后检查宏任务(macroTask)队列,如果存在任务,则取出第一个宏任务,执行,
又因为第一次进入执行栈的总是宏任务(Script),而每次宏任务完成后,都会读取微任务队列,所以,大家也会听见另一种表述方式:
每一轮循环中,同步任务执行后会在末尾执行并清空所有的微任务,会在下一轮循环中取第一个宏任务执行,如此循环
再看一下下面这道题
console.log(1)
new Promise(resolve => {
console.log(2)
resolve()
console.log(3)
}).then(() => {
console.log(4)
})
console.log(5)
setTimeout(function() {
console.log(6)
})
//请打印结果
首先我们知道,promise构造函数是同步执行的,then方法本身是同步执行,then方法中的内容加入微任务异步执行
所以这道题的答案就是
再综合一下,我们看一道练习题
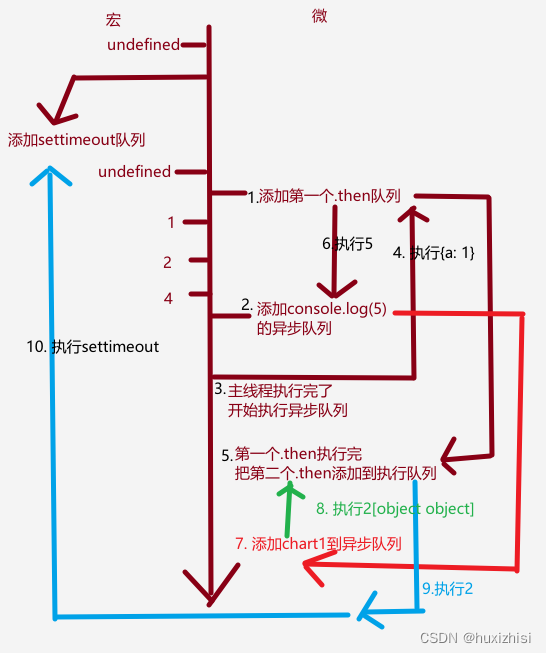
var a
var b
console.log(a)
async function chart1() {
console.log(1)
await chart2()
console.log(2)
}
async function chart2() {
a = 2
console.log(a)
await console.log(4)
console.log(5)
}
setTimeout(function() {
console.log(6)
a = b?.a
console.log(a)
})
new Promise((resolve) => {
console.log(a)
resolve({a : 1})
}).then(val => {
b = val
console.log(b)
}).then(() => {
console.log(a+b)
})
chart1()
// 请打印结果

















 1919
1919

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









