




 本文介绍了两种集成学习方法Adaboosting与GradientBoosting的基本原理与使用方法。Adaboosting通过调整样本权重逐步减少错误率,而GradientBoosting则通过连续训练多个模型来修正前一个模型的错误。
本文介绍了两种集成学习方法Adaboosting与GradientBoosting的基本原理与使用方法。Adaboosting通过调整样本权重逐步减少错误率,而GradientBoosting则通过连续训练多个模型来修正前一个模型的错误。

一、Adaboosting
1、Adaboosting的大致思路,第一个模型跑完之后,根据这个模型和实际数据的误差调整样本点的权值,不断进行下去
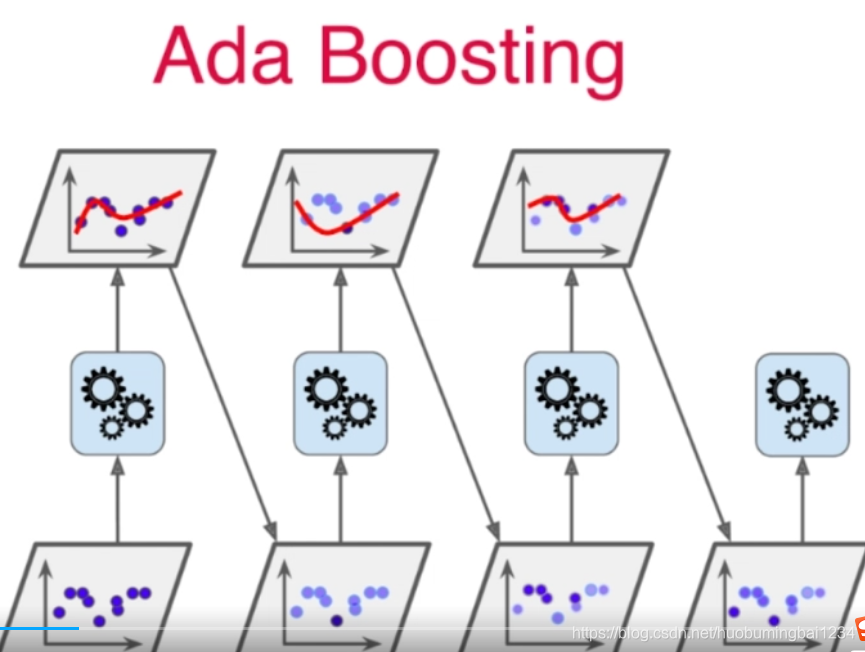
2、Adaboosting的公式推导(补)
3、Adaboosting的具体使用
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
X, y = datasets.make_moons(n_samples=500, noise=0.3, random_state=42)
plt.scatter(X[y==0,0],X[y==0,1])
plt.scatter(X[y==1,0],X[y==1,1])
from sklearn.ensemble import AdaBoostClassifier
from sklearn.tree import DecisionTreeClassifier
# DecisionTreeClassifier这个是基学习器,一般是用决策树
# n_estimators=500 相当于提升迭代了500次
ada_clf = AdaBoostClassifier(DecisionTreeClassifier(max_depth=2),n_estimators=500)
ada_clf.fit(X_train,y_train)
ada_clf.score(X_test, y_test)
二、Gradient Boosting
1、大致思想: 训练一个模型m1,产生错误e1
针对e1训练第二个模型m2,产生错误e2
针对e2训练第三个模型m3,产生错误e3...
最终预测结果是:m1 + m2 + m3
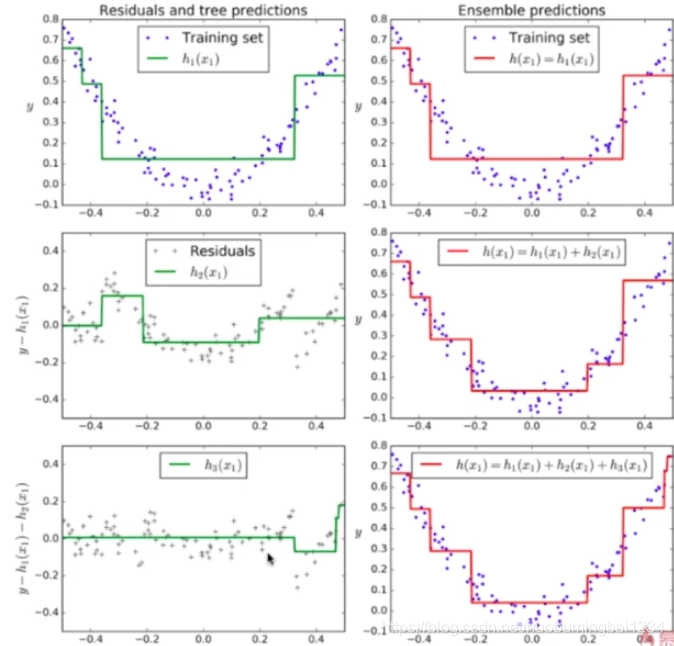
大致拟合过程,首先我们根据这个抛物线得出模型h1(x1),根据模型和实际的误差得到h2(x1),h2(x1)预测值和实际值的误差拟合出h3(x1),最后模型预测结果为h(x1) = h1(x1) + h2(x1) + h3(x1)
2、Gradient Boosting数学证明(补)
3、Gradient Boosting具体使用
# 数据集仍然使用上面的
from sklearn.ensemble import GradientBoostingClassifier
# 这里基学习器就是决策树
gb_clf = GradientBoostingClassifier(max_depth=2, n_estimators=30)
gb_clf.fit(X_train,y_train)
gb_clf.score(X_test,y_test)

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









