






 本文介绍了Hive分桶的概念及其作用,通过开启分桶开关并创建分桶表来实现数据的均匀分布,以解决MapReduce的数据倾斜问题。在实际操作中,通过CLUSTERED BY指定字段和BUCKETS数量创建分桶表,并使用INSERT INTO语句确保数据正确分布到各个桶中。分桶技术有助于提高查询效率和MapJoin操作。
本文介绍了Hive分桶的概念及其作用,通过开启分桶开关并创建分桶表来实现数据的均匀分布,以解决MapReduce的数据倾斜问题。在实际操作中,通过CLUSTERED BY指定字段和BUCKETS数量创建分桶表,并使用INSERT INTO语句确保数据正确分布到各个桶中。分桶技术有助于提高查询效率和MapJoin操作。
Hive分桶
分桶实际上是对文件(数据)的进一步切分,Hive默认关闭分桶。
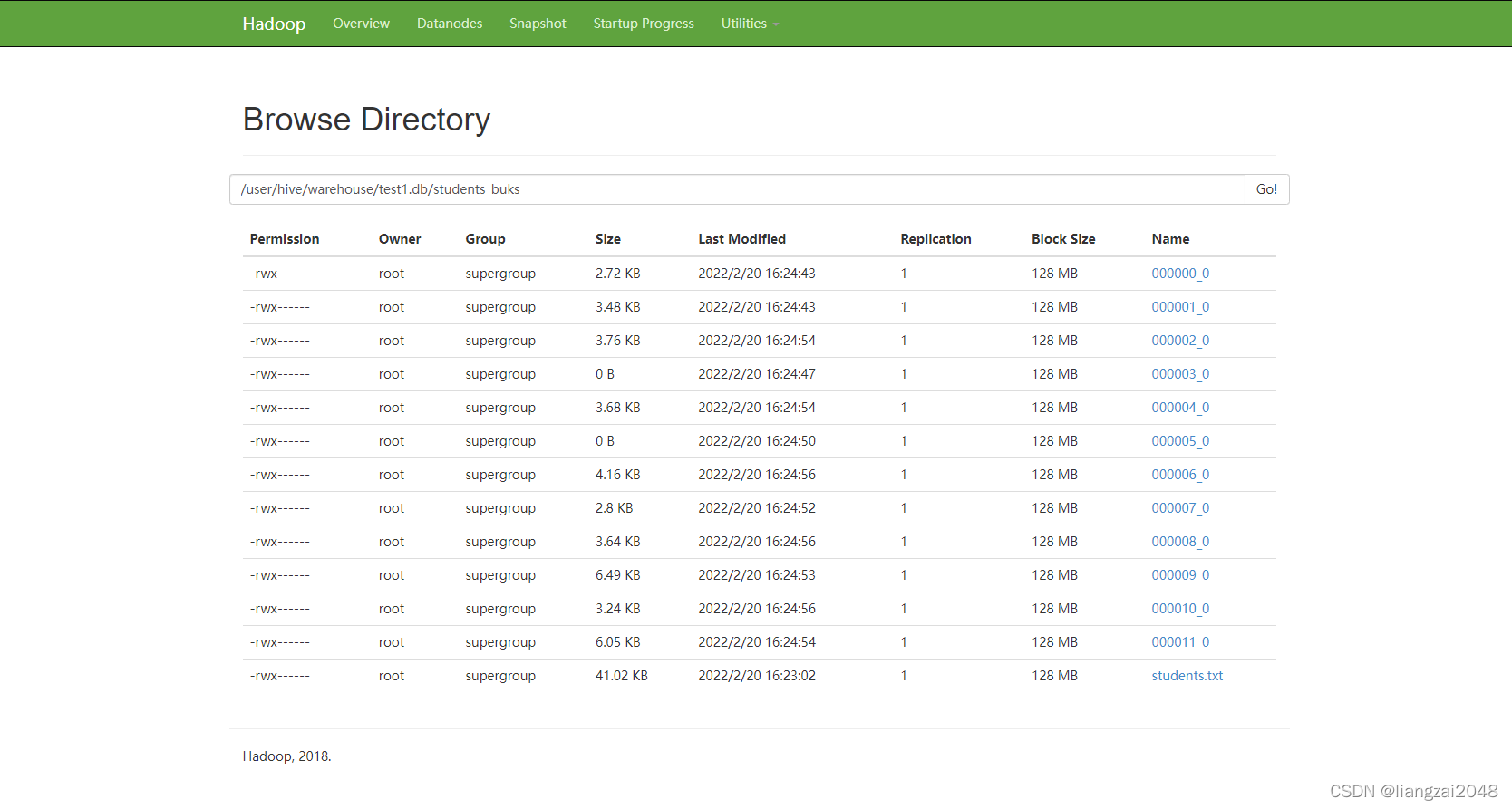
作用:在往分桶表中插入数据的时候,会根据 clustered by 指定的字段 进行hash分区 对指定的buckets个数 进行取余,进而可以将数据分割成buckets个数个文件,以达到数据均匀分布,可以解决Map端的“数据倾斜”问题,方便我们取抽样数据,提高Map join效率。
分桶字段 需要根据业务进行设定。
开启分桶开关
set hive.enforce.bucketing=true;
建立分桶表
create table students_buks
(
id bigint,
name string,
age int,
gender string,
clazz string
)
CLUSTERED BY (clazz) into 12 BUCKETS
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
往分桶表中插入数据
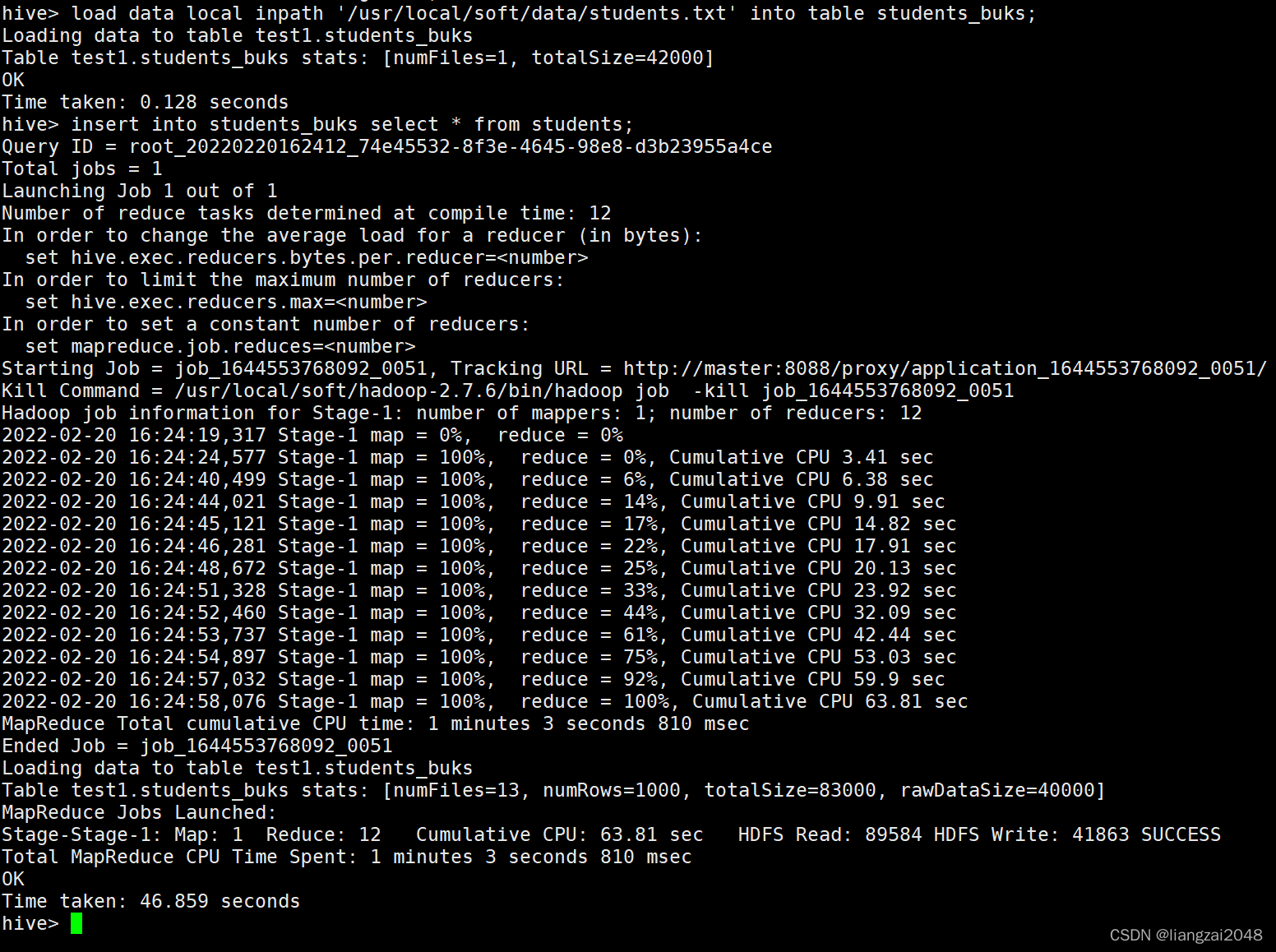
直接使用load data 并不能将数据打散
// 直接使用load data 并不能将数据打散
load data local inpath '/usr/local/soft/data/students.txt' into table students_buks;
需要使用下面这种方式插入数据,才能使分桶表真正发挥作用
// 需要使用下面这种方式插入数据,才能使分桶表真正发挥作用
insert into students_buks select * from students;
到底啦!关注靓仔学习更多的大数据知识。( •̀ ω •́ )✧


















 2034
2034

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











