Hive数据仓库——UDF、UDTF
UDF:一进一出
案例一
创建Maven项目,并加入依赖
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>1.2.1</version>
</dependency>
编写代码,继承org.apache.hadoop.hive.ql.exec.UDF,实现evaluate方法,在evaluate方法中实现自己的逻辑
package com.liangzai.UDF;
import org.apache.hadoop.hive.ql.exec.UDF;
public class MyUDF extends UDF {
public String evaluate(String gender) {
String resStr = "";
resStr = gender.replace("男","boy");
resStr = resStr.replace("女","girl");
return resStr;
}
}
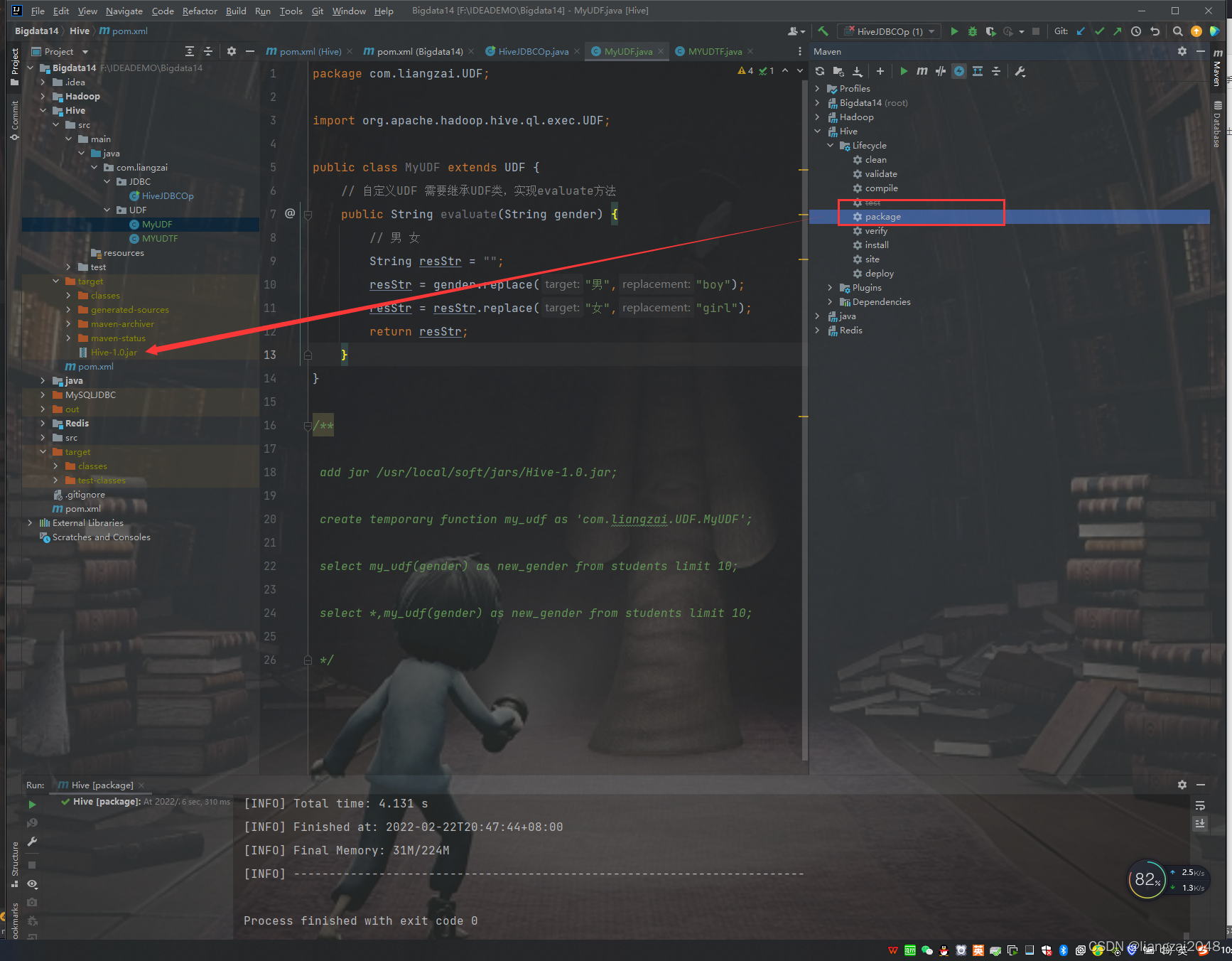
打成jar包并上传至Linux虚拟机
在hive shell中,使用 add jar 路径将jar包作为资源添加到hive环境中
add jar /usr/local/soft/jars/Hive-1.0.jar;
使用jar包资源注册一个临时函数,fxxx1是你的函数名,'MyUDF’是主类名
create temporary function my_udf as 'com.liangzai.UDF.MyUDF';
使用函数名处理数据
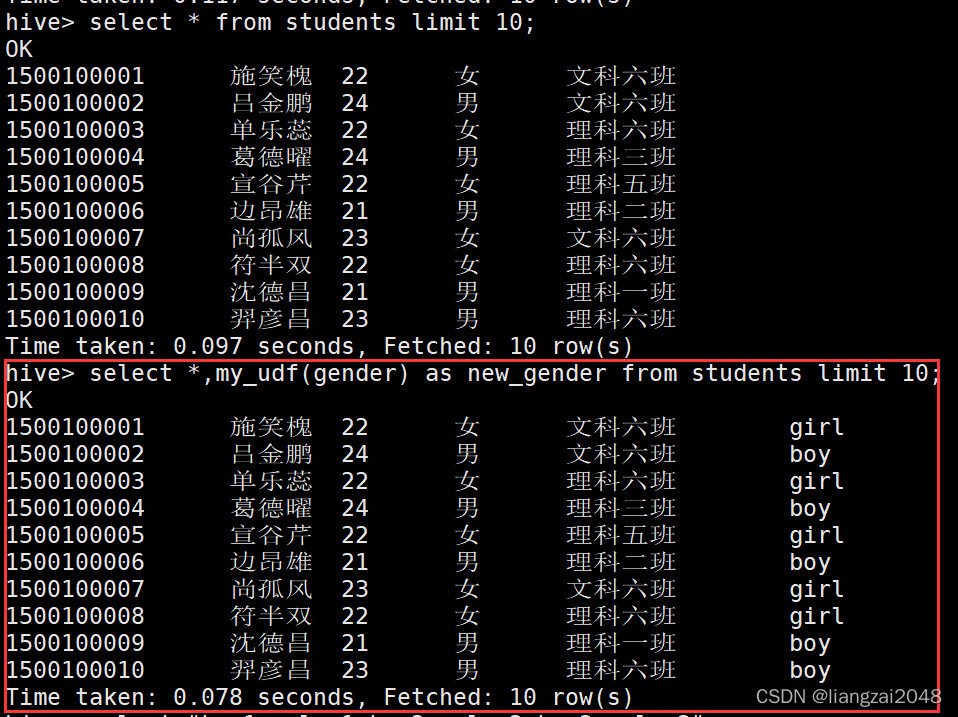
select my_udf(gender) as new_gender from students limit 10;
select *,my_udf(gender) as new_gender from students limit 10;
案例二
编写代码,继承org.apache.hadoop.hive.ql.exec.UDF,实现evaluate方法,在evaluate方法中实现自己的逻辑
package com.liangzai.UDF;
import org.apache.hadoop.hive.ql.exec.UDF;
public class MyUDF1 extends UDF {
public String evaluate(String clazz) {
String resStr = "";
resStr = clazz.replace("一","1");
resStr = resStr.replace("二","2");
resStr = resStr.replace("三",






 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1201
1201

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











