




文章目录
Hive 1.2.1

大数据体系概述
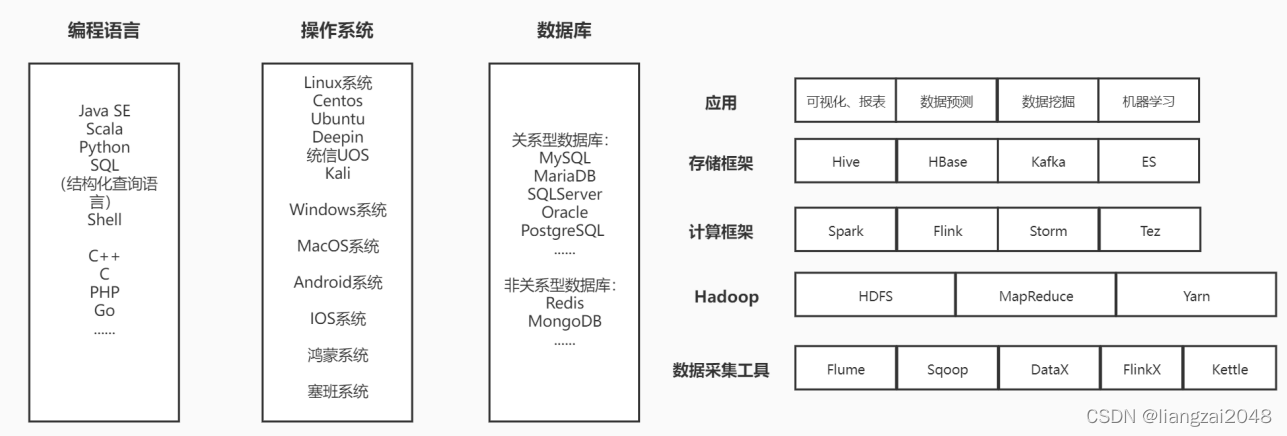
Hive架构
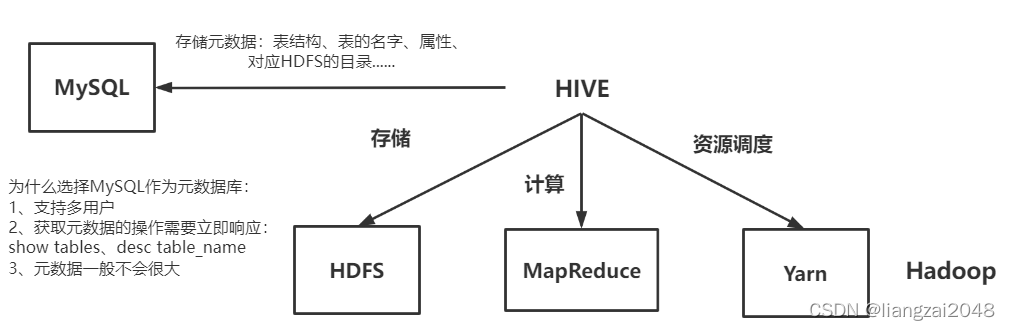
数据仓库
很久很久以前,我们的世界分为:人族、矮人族、精灵、兽族…本来世界很和平。
突然有一天,有一个人,有一个想法,这个想法很可怕,打破了这样的平静,他想统治整个世界,怎么做呢?
他想了一个主意,他会魔法,他用他的魔法,打造出魔戒,然后他把这个魔戒分别送个各个种族的首领,方便各个首领更好的统治;
然后他又偷偷的制造了一个至尊魔戒,这个至尊魔戒可以统治普通的魔戒,以此实现他的统一世界的梦想。。。。。。
如果把世界上每一个生物当作一条记录,那么魔戒就好比数据库,而我们的至尊魔戒就是数据仓库。
数据仓库(Data WareHouse) 实际上是为了公司能够统一各种业务数据,将各个不同数据源中的数据融合,这些数据通常可以做数据分析、数据挖掘、报表,帮助公司做决策。
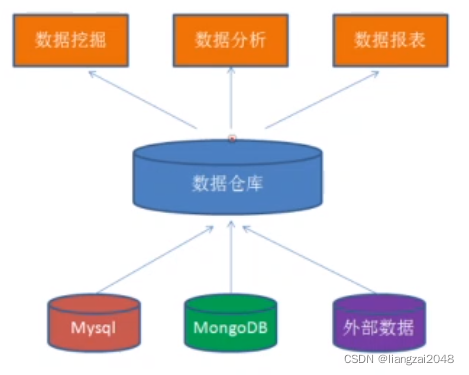
Hive 是什么
Hive是建立在Hadoop上的数据仓库基础架构。它提供了一系列的工具,可以用来进行数据提取转化加载( ETL ),这是一种可以存储、查询和分析存储在 Hadoop 中的大规模数据的机制。Hive 定义了简单的类 SQL 查询语言,称为 HQL ,它允许熟悉 SQL 的用户查询数据。同时,这个语言也允许熟悉 MapReduce 开发者的开发自定义的 mapper 和 reducer 来处理内建的 mapper 和 reducer 无法完成的复杂的分析工作。
数据仓库,英文名称为Data Warehouse,可简写为DW或DWH。数据仓库,是为企业所有级别的决策制定过程,提供所有类型数据支持的战略集合。它出于分析性报告和决策支持目的而创建。为需要业务智能的企业,提供指导业务流程改进、监视时间、成本、质量以及控制。
Hive是SQL解析引擎,它将SQL语句转译成M/R Job然后在Hadoop执行。
Hive的表其实就是HDFS的目录,按表名把文件夹分开。如果是分区表,则分区值是子文件夹,可以直接在M/R Job里使用这些数据。
Hive相当于hadoop的客户端工具,部署时不一定放在集群管理节点中,可以放在某个节点上。
Hive的安装
Hive的详细安装过程请点击下方靓仔原创博客链接:

版本介绍
- Hive数据仓库——环境搭建及简单使用
- 1.2.1和1.2.2 稳定版本,为Hive2版本(主流版本)
- 1.2.1的程序只能连接hive1.2.1 的hiveserver2
学习Hive
- java 1.8.0_171
- hadoop 2.7.6
- hive 1.2.1
- mysql:5.7
自己使用的过程中一定严格按照这个版本去使用(版本兼容)
安装主要流程
- 安装MySQL服务
- 安装hive包,解压
- 修改配置文件,连接mysql,连接hadoop
- 启动
Hive的详细安装过程请点击下方靓仔原创博客链接:
Hive与传统数据库比较
| 查询语言 | HiveQL | SQL |
|---|---|---|
| 数据存储位置 | HDFS | Raw Device or 本地 FS |
| 数据格式 | 用户定义 | 系统决定 |
| 数据更新 | 不支持(1.x以后版本支持) | 支持 |
| 索引 | 新版本有,但弱 | 有 |
| 执行 | MapReduce | Executor |
| 执行延迟 | 高 | 低 |
| 可扩展性 | 高 | 低 |
| 数据规模 | 大 | 小 |
- 查询语言,类 SQL 的查询语言 HQL。熟悉 SQL 开发的开发者可以很方便的使用 Hive 进行开发。
- 数据存储位置,所有 Hive 的数据都是存储在 HDFS 中的。而数据库则可以将数据保存在块设备或者本地文件系统中。
- 数据格式,Hive 中没有定义专门的数据格式。而在数据库中,所有数据都会按照一定的组织存储,因此,数据库加载数据的过程会比较耗时。
- 数据更新,Hive 对数据的改写和添加比较弱化,0.14版本之后支持,需要启动配置项。而数据库中的数据通常是需要经常进行修改的。
- 索引,Hive 在加载数据的过程中不会对数据进行任何处理。因此访问延迟较高。数据库可以有很高的效率,较低的延迟。由于数据的访问延迟较高,决定了 Hive 不适合在线数据查询。
- 执行计算,Hive 中执行是通过 MapReduce 来实现的而数据库
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 2295
2295

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











