




 博客围绕Go语言展开,对比了Go数组与C数组在内存使用上的差异,指出Go数组赋值和传参是值复制,消耗内存大,而切片可节约内存并处理好共享内存问题。还介绍了切片的拷贝、扩容策略、并发写入缺陷及另类初始化等特性。
博客围绕Go语言展开,对比了Go数组与C数组在内存使用上的差异,指出Go数组赋值和传参是值复制,消耗内存大,而切片可节约内存并处理好共享内存问题。还介绍了切片的拷贝、扩容策略、并发写入缺陷及另类初始化等特性。
在 Go 中,与 C 数组变量隐式作为指针使用不同,Go 数组是值类型,赋值和函数传参操作都会复制整个数组数据。
package main
import (
"fmt"
)
func main() {
arrayA := [2]int{100, 200}
var arrayB [2]int
arrayB = arrayA
fmt.Printf("arrayA : %p , %v\n", &arrayA, arrayA)
fmt.Printf("arrayB : %p , %v\n", &arrayB, arrayB)
testArray(arrayA)
}
func testArray(x [2]int) {
fmt.Printf("func Array : %p , %v\n", &x, x)
}
打印结果:
arrayA : 0xc00000a0a0 , [100 200]
arrayB : 0xc00000a0b0 , [100 200]
func Array : 0xc00000a100 , [100 200]
可以看到,三个内存地址都不同,这也就验证了 Go 中数组赋值和函数传参都是值复制的。那这会导致什么问题呢?
假想每次传参都用数组,那么每次数组都要被复制一遍。如果数组大小有 100万,在64位机器上就需要花费大约 800W 字节,即 8MB 内存。这样会消耗掉大量的内存。于是乎有人想到,函数传参用数组的指针。
func main() {
arrayA := [2]int{100, 200}
testArrayPoint(&arrayA) // 1.传数组指针
arrayB := arrayA[:]
testArrayPointSlice(&arrayB) // 2.传切片
fmt.Printf("arrayA : %p , %v\n", &arrayA, arrayA)
}
func testArrayPoint(x *[2]int) {
fmt.Printf("func Array : %p , %v\n", x, *x)
(*x)[1] += 100
}
func testArrayPointSlice(x *[]int) {
fmt.Printf("change Array : %p , %v\n", x, *x)
(*x)[1] += 100
}
打印结果:
func Array : 0xc00000a0a0 , [100 200]
change Array : 0xc000004078 , [100 300]
arrayA : 0xc00000a0a0 , [100 400]
这也就证明了数组指针确实到达了我们想要的效果。现在就算是传入10亿的数组,也只需要再栈上分配一个8个字节的内存给指针就可以了。这样更加高效的利用内存,性能也比之前的好。不过传指针会有一个弊端,从打印结果可以看到,万一原数组的指针指向更改了,那么函数里面的指针指向都会跟着更改。切片的优势也就表现出来了。用切片传数组参数,既可以达到节约内存的目的,也可以达到合理处理好共享内存的问题。打印结果第二行就是切片,切片的指针和原来数组的指针是不同的。
func main() {
var a = []int{2, 3, 5, 7, 11}
fmt.Printf("slice a : %v , len(a) : %v, cap(a) : %v\n", a, len(a), cap(a))
b := a[1:3]
fmt.Printf("slice b : %v , len(b) : %v, cap(b) : %v\n", b, len(b), cap(b))
c := b[0:3]
fmt.Printf("slice c : %v , len(c) : %v, cap(c) : %v\n", c, len(c), cap(c))
}
输出结果:
slice a : [2 3 5 7 11] , len(a) : 5, cap(a) : 5
slice b : [3 5] , len(b) : 2, cap(b) : 4
slice c : [3 5 7] , len(c) : 3, cap(c) : 4
数组和切片的内存布局
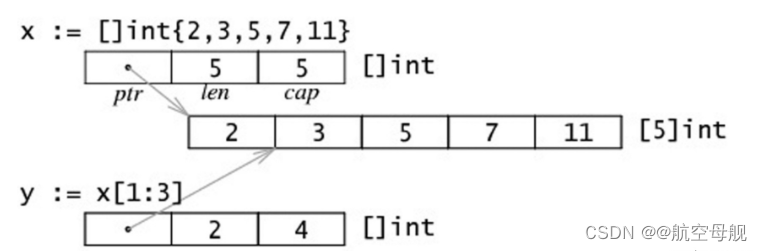
数组
func main() {
var a = [5]int{1, 2, 3, 4, 5}
var r [5]int
for i, v := range a {
if i == 0 {
a[1] = 12
a[2] = 13
}
r[i] = v
}
fmt.Println("r = ", r)
fmt.Println("a = ", a)
}
参考答案及解析:
r = [1 2 3 4 5]
a = [1 12 13 4 5]
切片
func main() {
var a = []int{1, 2, 3, 4, 5}
var r [5]int
for i, v := range a {
if i == 0 {
a[1] = 12
a[2] = 13
}
r[i] = v
}
fmt.Println("r = ", r)
fmt.Println("a = ", a)
}
参考答案及解析:
r = [1 12 13 4 5]
a = [1 12 13 4 5]
切片在 go 的内部结构有一个指向底层数组的指针,当 range 表达式发生复制时,副本的指针依旧指向原底层数组,所以对切片的修改都会反应到底层数组上,所以通过 v 可以获得修改后的数组元素。
func main() {
a := [3]int{0, 1, 2}
s := a[1:2]
fmt.Println(s, len(s), cap(s)) //[1] 1 2
s[0] = 11
s = append(s, 12) //slice指向真实地址,数组容量已满
s = append(s, 13)
s[0] = 21
fmt.Println(a) //{0, 11, 12}
fmt.Println(s) //21 12 13
}
切片拷贝
- slice的浅拷贝就是指slice变量的赋值操作
- slice的深拷贝就是指使用内置的copy函数来拷贝两个slice
下面代码输出什么
func main() {
var src, dst []int
src = []int{1, 2, 3}
copy(dst, src)
fmt.Println(dst)
}
参考答案及解析:输出 []。知识点:拷贝切片。copy(dst, src) 函数返回 len(dst)、len(src) 之间的最小值。如果想要将 src 完全拷贝至 dst,必须给 dst 分配足够的内存空间。
修复代码:
func main() {
var src, dst []int
src = []int{1, 2, 3}
dst = make([]int, len(src))
n := copy(dst, src)
fmt.Println(n,dst)
}
拷贝大切片一定比小切片代价大吗
拷贝大切片跟小切片的代价应该是一样的
SliceHeader是切片在go的底层结构。type SliceHeader struct { Data uintptr Len int Cap int }
- 大切片跟小切片的区别无非就是
Len和Cap的值比小切片的这两个值大一些,如果发生拷贝,本质上就是拷贝上面的三个字段。
切片扩容
切片容量达到最大时,再使用append会发生扩容。一旦切片扩容了,切片指向的地址已经发生了改变,不再指向原来的数组,而是指向了一个新的数组了
func addNum(sli []int) {
sli = append(sli, 4)
fmt.Printf("%p\n", sli) //0xc00000c360
}
func main() {
arr := []int{1, 2, 3}
fmt.Printf("%s, %p\n", cap(arr), arr) //0xc000014150
addNum(arr)
fmt.Printf("%p\n", arr) //0xc000014150
}
func change(s ...int) { s = append(s, 3) }
func main() {
slice := make([]int, 5, 5)
slice[0] = 1
slice[1] = 2
change(slice...)
fmt.Println(slice)
change(slice[0:2]...)
fmt.Println(slice)
}
参考答案及解析:[1 2 0 0 0] [1 2 3 0 0] 切片底层数组 第一次调用 change() 时,append() 操作使切片底层数组发生了扩容,原 slice 的底层数组不会改变; 第二次调用change() 函数时,使用了操作符[i,j]获得一个新的切片,假定为 slice1, 它的底层数组和原切片底层数组是重合的,不过 slice1 的长度、容量分别是 2、5,所以在 change() 函数中对 slice1 底层数组的修改会影响到原切片。
扩容策略
在golang1.18版本更新之前网上大多数的文章都是这样描述slice的扩容策略的:
当原 slice 容量小于 1024 的时候,新 slice 容量变成原来的 2 倍;原 slice 容量超过 1024,新 slice 容量变成原来的1.25倍。
在1.18版本更新之后,slice的扩容策略变为了:
当原slice容量(oldcap)小于256的时候,新slice(newcap)容量为原来的2倍;原slice容量超过256,新slice容量newcap = oldcap+(oldcap+3*256)/4
为了说明上面的规律,我写了一小段玩具代码:
func main() {
s := make([]int, 0)
oldCap := cap(s)
for i := 0; i < 2048; i++ {
s = append(s, i)
newCap := cap(s)
if newCap != oldCap {
fmt.Printf("[%d -> %4d] cap = %-4d | after append %-4d cap = %-4d\n", 0, i-1, oldCap, i, newCap)
oldCap = newCap
}
}
}
运行结果(1.18版本之前):
[0 -> -1] cap = 0 | after append 0 cap = 1
[0 -> 0] cap = 1 | after append 1 cap = 2
[0 -> 1] cap = 2 | after append 2 cap = 4
[0 -> 3] cap = 4 | after append 4 cap = 8
[0 -> 7] cap = 8 | after append 8 cap = 16
[0 -> 15] cap = 16 | after append 16 cap = 32
[0 -> 31] cap = 32 | after append 32 cap = 64
[0 -> 63] cap = 64 | after append 64 cap = 128
[0 -> 127] cap = 128 | after append 128 cap = 256
[0 -> 255] cap = 256 | after append 256 cap = 512
[0 -> 511] cap = 512 | after append 512 cap = 1024
[0 -> 1023] cap = 1024 | after append 1024 cap = 1280
[0 -> 1279] cap = 1280 | after append 1280 cap = 1696
[0 -> 1695] cap = 1696 | after append 1696 cap = 2304
运行结果(1.18版本):
[0 -> -1] cap = 0 | after append 0 cap = 1
[0 -> 0] cap = 1 | after append 1 cap = 2
[0 -> 1] cap = 2 | after append 2 cap = 4
[0 -> 3] cap = 4 | after append 4 cap = 8
[0 -> 7] cap = 8 | after append 8 cap = 16
[0 -> 15] cap = 16 | after append 16 cap = 32
[0 -> 31] cap = 32 | after append 32 cap = 64
[0 -> 63] cap = 64 | after append 64 cap = 128
[0 -> 127] cap = 128 | after append 128 cap = 256
[0 -> 255] cap = 256 | after append 256 cap = 512
[0 -> 511] cap = 512 | after append 512 cap = 848
[0 -> 847] cap = 848 | after append 848 cap = 1280
[0 -> 1279] cap = 1280 | after append 1280 cap = 1792
[0 -> 1791] cap = 1792 | after append 1792 cap = 2560
向 slice 追加元素的时候,若容量不够,会调用 growslice 函数,所以我们直接看它的代码。
// go 1.9.5 src/runtime/slice.go:82
func growslice(et *_type, old slice, cap int) slice {
// ……
newcap := old.cap
doublecap := newcap + newcap
if cap > doublecap {
newcap = cap
} else {
if old.len < 1024 {
newcap = doublecap
} else {
for newcap < cap {
newcap += newcap / 4
}
}
}
// ……
capmem = roundupsize(uintptr(newcap) * ptrSize)
newcap = int(capmem / ptrSize)
}
golang版本1.18
// go 1.18 src/runtime/slice.go:178
func growslice(et *_type, old slice, cap int) slice {
// ……
newcap := old.cap
doublecap := newcap + newcap
if cap > doublecap {
newcap = cap
} else {
const threshold = 256
if old.cap < threshold {
newcap = doublecap
} else {
for 0 < newcap && newcap < cap {
// Transition from growing 2x for small slices
// to growing 1.25x for large slices. This formula
// gives a smooth-ish transition between the two.
newcap += (newcap + 3*threshold) / 4
}
if newcap <= 0 {
newcap = cap
}
}
}
// ……
capmem = roundupsize(uintptr(newcap) * ptrSize)
newcap = int(capmem / ptrSize)
}
并发写入缺陷
func main() {
var slice []string
for i := 0; i < 9999; i++ {
go func() {
slice = append(slice, "demo")
}()
}
fmt.Println("slice len", len(slice))
}
实际追加的数据不是我们预期的结果。多协程写入下,是一个并发式写入过程。我们无法保证每一次的写都是有序的,存在第一个协程向某个索引位
写入数据之后,后执行的协程同样的往这个索引位写入数据,就导致前面的协程写入数据被后面的协程给覆盖掉。如下图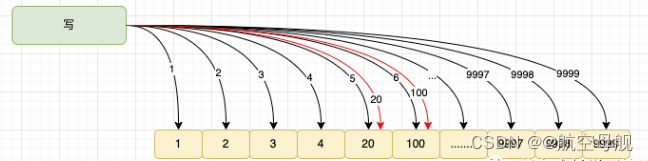
func main() {
var slice []string
mutex := sync.RWMutex{}
for i := 0; i < 9999; i++ {
mutex.Lock()
go func() {
slice = append(slice, "demo")
mutex.Unlock()
}()
}
fmt.Println("slice len", len(slice))
}
切片的另类初始化
func main() {
var x = []int{4: 44, 55, 66, 1: 77, 88}
println(len(x), x[2])
}
指定了第 5 个元素(对应索引是 4),值是 44。根据上面规则的第三点,55、66 都没有指定索引,因此它们的索引是前一个元素的索引加一,即:
5: 55, 6: 66
下一个元素是 1: 77,为其指定了索引 1,因此它的下一元素 88 的索引就是 2 了,因此这个定义相当于如下的定义:
var x = []int{4: 44, 5: 55, 6: 66, 1: 77, 2: 88}
同样,因为数组/切片的特性,缺少的元素(索引 0 和 3)值是 0,而整个切片的长度是最大索引加一,即 7。

















 2046
2046

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









