



什么是xxl-job
xxl-job 项目是分布式调度开源系统,具有开发迅速、学习简单、轻量级、易扩展等核心设计目标。
安装xxl-job
获取源码
git clone git@github.com:xuxueli/xxl-job.git构建工程
进入工程目录,使用mvn命令构建工程:
cd xxl-job
mvn package构建过程中,会下载所需要的jar包。
修改配置文件
在IDEA中打开工程,需要修改logback.xml和properties中的日志路径。具体修改方法可以参考XXL-JOB的官方文档。
初始化数据库
运行以下命令初始化数据库
source /xxl-job/doc/db/tables_xxl_job.sql同时,需要修改application.properties中的数据库用户密码。具体修改方法可以参考XXL-JOB的官方文档。
运行web工程
在IDEA中运行web工程,访问地址为:http://localhost:8080/xxl-job-adm。
以上是XXL-JOB的安装和配置过程。在实际应用中,还需要根据具体需求进行进一步的配置和优化。同时,建议参考XXL-JOB的官方文档和社区资源,以便更好地了解和使用XXL-JOB平台。
其他项目引入XXL-JOB
导入依赖,配置执行器
<dependency>
<groupId>com.xuxueli</groupId>
<artifactId>xxl-job-core</artifactId>
</dependency>配置文件配置
xxl:
job:
admin:
addresses: http://localhost:8080/xxl-job-admin
executor:
appname: bill #执行器名字(很重要,在调度中心要用到)
address:
ip:
port: 9999 #执行器端口号
logpath: /data/applogs/xxl-job/jobhandler
logretentiondays: 30
accessToken: default_token主要就是xxl.job.admin.addresses 和 xxl.job.executor.appname 这俩,第一个必须指向正确的调度中心地址。修改xxl-job-admin配置文件application.properties中xxl.job.accessToken的token值,默认值为default_token
后台配置执行器

配置xxl-job的配置类
package com.hworld.custom.config;
import com.xxl.job.core.executor.impl.XxlJobSpringExecutor;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.boot.autoconfigure.condition.ConditionalOnProperty;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.Profile;
/**
* <p>
* xxl-job 配置类 通过配置 xxl.job.enabled 控制是否启用XXL-JOB功能
* </p>
*
* @author : hudy
* @date : 2023/11/20
*/
@Configuration
@Slf4j
@ConditionalOnProperty(name = "xxl.job.enabled", havingValue = "true", matchIfMissing = false)
public class XxlJobConfig {
@Value("${xxl.job.admin.addresses}")
private String adminAddresses;
@Value("${xxl.job.executor.appname}")
private String appName;
@Value("${xxl.job.executor.port}")
private int port;
@Value("${xxl.job.accessToken}")
private String accessToken;
@Value("${xxl.job.executor.logpath}")
private String logPath;
@Value("${xxl.job.executor.logretentiondays}")
private int logRetentionDays;
@Bean
@Profile({"local", "prod"})
public XxlJobSpringExecutor xxlJobExecutor() {
log.info(">>>>>>>>>>> xxl-job config init.");
XxlJobSpringExecutor xxlJobSpringExecutor = new XxlJobSpringExecutor();
xxlJobSpringExecutor.setAdminAddresses(adminAddresses);
xxlJobSpringExecutor.setAppname(appName);
xxlJobSpringExecutor.setPort(port);
xxlJobSpringExecutor.setAccessToken(accessToken);
xxlJobSpringExecutor.setLogPath(logPath);
xxlJobSpringExecutor.setLogRetentionDays(logRetentionDays);
return xxlJobSpringExecutor;
}
}项目配置正确,服务自动注册会将项目地址自动注册到Online机器地址。并且其他项目服务日志有

这样就是直接使用@XxlJob注解了
关于XXL-JOB
一、基本组成
XXL-JOB主要由调度中心和执行器两部分组成:
- 调度中心:统一管理任务调度平台上的调度任务,负责触发调度执行,并且提供任务管理平台。它主要负责管理调度信息,按照调度配置发出调度请求,但自身不承担业务代码。
- 执行器:接收调度中心的调度并且执行,可以直接执行也可以集成到项目中。它负责接收调度请求并执行任务逻辑,包括执行请求、终止请求和日志请求等。
二、特点与优势
- 简单易用:XXL-JOB提供了友好的Web界面,支持通过Web界面进行任务的增删改查,同时也支持通过API接口进行任务管理。用户可以通过简单的操作完成任务的调度和管理。
- 动态管理:支持动态修改任务状态、启动/停止任务以及终止运行中任务,所有操作都会实时生效。
- 高可用性:调度中心和执行器都支持集群部署,可保证调度和执行的高可用性。即使某个节点出现故障,也能自动切换到其他节点继续执行任务。
- 弹性扩容缩容:一旦有新执行器机器上线或者下线,下次调度时将会重新分配任务,实现弹性扩容缩容。
- 丰富的路由策略:执行器集群部署时提供多种路由策略,包括第一个、最后一个、轮询、随机、一致性HASH等,以满足不同场景下的需求。
- 故障转移:如果执行器集群中某一台机器故障,将会自动Failover切换到一台正常的执行器发送调度请求,确保任务能够正常执行。
- 执行失败查看日志:对于执行失败的任务,可以查看详细的日志信息,方便用户进行问题排查和修复。
- 支持邮件报警:当任务执行失败时,XXL-JOB支持发送邮件通知相关人员,以便及时处理异常情况。
三、应用场景
XXL-JOB适用于各种需要定时执行任务或实时处理任务的场景,如:
- 定时发送邮件:通过XXL-JOB可以定时发送邮件通知相关人员。
- 定时生成报表:可以定时生成各类业务报表,供相关人员进行分析和决策。
- 定时清理数据:可以定时清理过期或无效的数据,确保数据库的整洁和高效运行。
- 实时数据采集:可以实时采集各类业务数据,并进行处理和分析。
- 实时消息推送:可以实时推送各类业务消息给用户或第三方系统。
四、与其他任务调度框架的比较
与Quartz等传统的任务调度框架相比,XXL-JOB具有以下优势:
- 学习成本低:XXL-JOB提供了可视化的Web界面和丰富的文档支持,降低了学习成本。
- 操作简便:通过Web界面可以方便地进行任务的创建、编辑、删除和查询等操作。
- 负载均衡:XXL-JOB通过执行器实现协同分配式运行任务,充分发挥集群优势,实现了负载均衡。
xxl-job如何获取参数:
通过任务参数字段
在XXL-JOB的任务管理界面,每个任务都有一个“任务参数”字段。你可以在这个字段中填写需要传递给执行器的参数。这些参数通常以JSON、键值对或其他格式编写,具体取决于你的执行器如何解析这些参数。JobHandler任务方法名填写@XxlJob注解中的名称
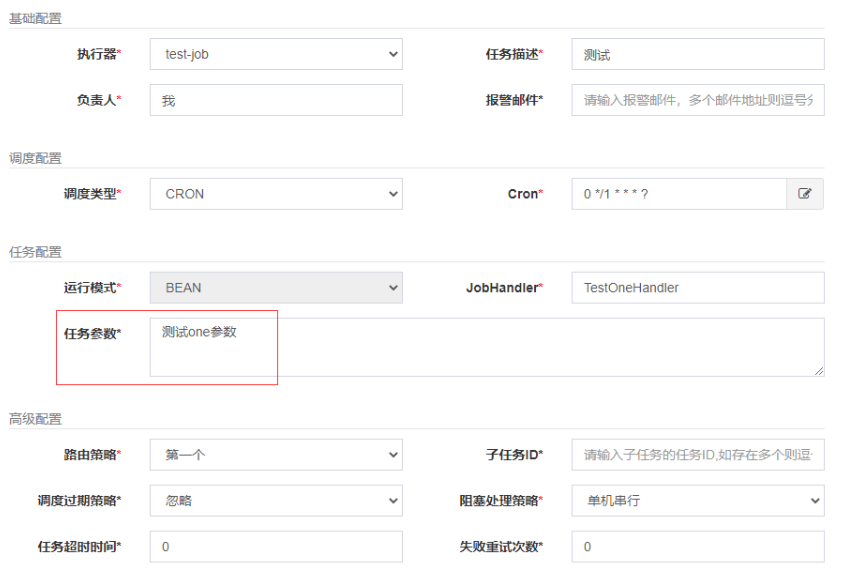
XxlJobHelper主要API说明
- XxlJobHelper.getJobParam(): 获取任务参数
- XxlJobHelper.getShardIndex(): 获取当前分片序号
- XxlJobHelper.getShardTotal(): 获取总分片数
- XxlJobHelper.handleSuccess(): 标记任务执行成功
- XxlJobHelper.handleFail(): 标记任务执行失败
- XxlJobHelper.log(): 记录执行日志
String param = XxlJobHelper.getJobParam();
long jobId = XxlJobHelper.getJobId();
log.info("当前执行的任务ID: {}", jobId);
XxlJobHelper.handleSuccess("任务执行成功");
XxlJobHelper.log("任务执行异常: {}", e.getMessage());
XxlJobHelper.handleFail("任务执行异常: " + e.getMessage());单个参数
@XxlJob("TestOneHandler")
public ReturnT<String> jobDemo(String s) throws Exception {
String param = XxlJobHelper.getJobParam();
System.out.println("TestOneHandler执行参数:" + param);
return SUCCESS;
}
多个参数
在XXL-JOB调度中心的任务配置中,"任务参数"字段可以填写如下JSON格式内容:
{
"hour": "09",
"hotelId": "H1001",
"forceSend": true,
"threshold": 1000
}解析方法
@XxlJob("TestOneHandler")
public ReturnT<String> jobDemo(String jobParam) throws Exception {
//String jobParam = XxlJobHelper.getJobParam();
JSONObject paramJson = null;
if (StringUtils.isNotBlank(jobParam)) {
try {
paramJson = JSON.parseObject(jobParam);
log.info("接收到JSON参数: {}", paramJson.toJSONString());
} catch (Exception e) {
log.error("JSON参数解析失败: {}", jobParam, e);
}
}
}任务策略
路由策略
当您在 XXL-JOB 调度中心创建或编辑任务时,可以设置以下路由策略:
- FIRST(第一个):固定选择注册到执行器的第一个节点执行
- LAST(最后一个):固定选择注册到执行器的最后一个节点执行
- ROUND(轮询):按照顺序轮询选择执行节点
- RANDOM(随机):随机选择执行节点
- CONSISTENT_HASH(一致性HASH):根据任务参数进行一致性HASH选择
- LEAST_FREQUENTLY_USED(最不经常使用):选择历史执行次数最少的节点
- LEAST_RECENTLY_USED(最近最久未使用):选择最近最久未执行的节点
- FAILOVER(故障转移):失败转移,如果某个节点失败则转移到下一个节点
- BUSYOVER(忙碌转移):如果某个节点忙碌则转移到空闲节点
- SHARDING_BROADCAST(分片广播):向所有注册节点广播执行任务
路由策略使用场景
1. FIRST(第一个)
使用场景:
- 主备模式:指定主节点处理关键任务
- 固定执行节点:某些任务需要在特定环境下运行
- 测试环境:指定测试节点执行任务
典型应用:
- 核心数据同步任务
- 系统状态检查任务
- 主节点数据汇总任务
2. LAST(最后一个)
使用场景:
- 备用节点执行:作为备用方案执行任务
- 新节点优先:新加入的节点优先执行任务
典型应用:
- 灰度发布环境下的任务执行
- 新版本执行器测试任务
3. ROUND(轮询)
使用场景:
- 负载均衡:多个执行器平均分配任务
- 无状态任务分发
- 避免单点过载
典型应用:
- 定时数据清理任务
- 日志分析任务
- 批量数据处理任务
4. RANDOM(随机)
使用场景:
- 简单负载均衡
- 容错性要求高但无严格顺序要求的任务
- 分散执行压力
典型应用:
- 数据采样任务
- 健康检查任务
- 缓存预热任务
5. CONSISTENT_HASH(一致性HASH)
使用场景:
- 根据任务参数固定分配执行节点
- 分布式缓存场景
- 需要最小化节点变更影响的场景
典型应用:
- 用户数据处理任务(按用户ID分片)
- 订单处理任务(按订单ID分片)
- 内容分发任务
6. LEAST_FREQUENTLY_USED(最不经常使用)
使用场景:
- 平衡各节点执行次数
- 避免某些节点过载
- 长期运行的任务调度优化
典型应用:
- 长周期统计任务
- 资源监控任务
- 性能分析任务
7. LEAST_RECENTLY_USED(最近最久未使用)
使用场景:
- 平衡各节点执行频率
- 避免热点节点
- 公平调度需求
典型应用:
- 定期维护任务
- 系统优化任务
- 资源回收任务
8. FAILOVER(故障转移)
使用场景:
- 高可用要求场景
- 关键业务任务执行
- 不能容忍任务失败的场景
典型应用:
- 核心数据备份任务
- 业务告警任务
- 交易确认任务
9. BUSYOVER(忙碌转移)
使用场景:
- 动态负载均衡
- 实时性要求较高的任务
- 避免任务在忙碌节点堆积
典型应用:
- 实时数据处理任务
- 紧急告警任务
- 在线数据分析任务
10. SHARDING_BROADCAST(分片广播)
@Component
@Slf4j
public class ShardingExampleTask {
@XxlJob("shardingExampleJob")
public void shardingExample() {
// 获取分片参数
int shardIndex = XxlJobHelper.getShardIndex();
int shardTotal = XxlJobHelper.getShardTotal();
log.info("开始执行分片任务,当前分片序号: {},总分片数: {}", shardIndex, shardTotal);
// 根据分片参数处理不同数据
processShardingData(shardIndex, shardTotal);
log.info("分片任务执行完成");
}
private void processShardingData(int shardIndex, int shardTotal) {
// 示例:处理用户数据,按用户ID分片
List<User> allUsers = userService.getAllUsers();
for (int i = 0; i < allUsers.size(); i++) {
// 分片逻辑:index % total == shardIndex
if (i % shardTotal == shardIndex) {
User user = allUsers.get(i);
processUser(user);
}
}
}
private void processUser(User user) {
// 处理单个用户逻辑
log.info("处理用户: {}", user.getId());
}
}使用场景:
- 大数据量分片处理
- 并行处理需求
- 需要所有节点同时执行任务
典型应用:
- 大规模数据清洗任务
- 全量数据统计任务
- 分布式计算任务
- 系统批量更新任务
阻塞处理策略
XXL-JOB提供了多种阻塞处理策略,用于控制当任务执行时间超过调度周期时的行为,确保任务调度的稳定性和可靠性。
阻塞处理策略类型
在XXL-JOB调度中心的任务配置中,"阻塞处理策略"字段有以下几种选择:
- 单机串行:默认策略,同一任务在同一个执行器上只能有一个实例在运行
- 丢弃后续调度:如果前一个任务未完成,后续调度将被丢弃
- 覆盖之前调度:新调度会覆盖之前的任务执行
- 允许并发:允许多个任务实例同时执行
不同策略的适用场景
- 单机串行:适用于需要保证任务顺序执行的场景,如数据同步、报表生成等
- 丢弃后续调度:适用于对实时性要求不高的任务,避免资源浪费
- 覆盖之前调度:适用于需要最新数据的任务,如缓存更新、状态刷新等
- 允许并发:适用于可以并行处理的任务,如批量数据处理、文件下载等
调度过期策略
XXL-JOB的调度过期策略是指当任务执行时间超过调度周期时,系统如何处理后续调度请求的策略。这直接影响到任务的执行频率和可靠性。
调度过期策略类型
在XXL-JOB调度中心的任务配置中,"调度过期策略"字段有以下几种选择:
- 立即执行:无论前一个任务是否完成,都立即执行新的调度
- 等待执行:等待前一个任务完成后才开始新的调度
- 丢弃执行:如果前一个任务未完成,直接丢弃新的调度请求
- 覆盖执行:新调度会覆盖之前的任务执行
不同策略的适用场景
- 立即执行:适用于对实时性要求极高的任务,如监控告警、实时数据同步等
- 等待执行:适用于需要保证任务完整性的场景,如报表生成、数据备份等
- 丢弃执行:适用于对实时性要求不高的任务,避免资源浪费
- 覆盖执行:适用于需要最新数据的任务,如缓存更新、状态刷新等

















 1057
1057

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









