







 Fast R-CNN是R-CNN和SPP-Net的改进版,通过单个卷积网络同时进行目标分类和位置修正,显著提升了训练和测试速度。它使用ROI池化层,解决了多阶段训练问题,允许所有层的参数更新,并通过多任务损失进行联合训练。Fast R-CNN在VOC2012数据集上实现了66%的mAP,相比R-CNN和SPP-Net有更高的精度和更快的速度。
Fast R-CNN是R-CNN和SPP-Net的改进版,通过单个卷积网络同时进行目标分类和位置修正,显著提升了训练和测试速度。它使用ROI池化层,解决了多阶段训练问题,允许所有层的参数更新,并通过多任务损失进行联合训练。Fast R-CNN在VOC2012数据集上实现了66%的mAP,相比R-CNN和SPP-Net有更高的精度和更快的速度。
详细内容来源于:https://blog.youkuaiyun.com/cdknight_happy/article/details/87925098
论文:https://arxiv.org/abs/1504.08083
caffe实现:https://github.com/rbgirshick/fast-rcnn
包括理解!
Fast R-CNN:Fast Regions with CNN features
摘要
本文在R-CNN的基础上提出了Fast R-CNN,使用CNN实现了更快更准的目标检测。
相比于R-CNN,使用VGG16骨干网络,训练提速了9倍,测试提速了231倍,在PASCAL VOC 2012数据集上取得了更高的mAP;相比于SPP Net,使用VGG16骨干网络,训练提速了3倍,测试提速了10倍,并且更加准确。
1 引言
最近,深度ConvNets显著地改进了图像分类和物体检测的准确率。与图像分类相比,目标检测是一项更具挑战性的任务,需要更复杂的方法来解决。由于这种复杂性,当前的算法多采用多级方法训练模型(例如R-CNN),这些模型是速度慢且不优雅。
目标检测的复杂源于需要对目标进行精确定位,有两个主要的挑战:
必须处理大量的候选位置(通常称为“proposal”),计算量大;
这些proposal只是目标的粗略定位,必须对其修正以提升检测精度。
解决上面两个问题往往会影响算法的整体处理速度、准确性和简洁性。
在本文中,我们简化了最先进的基于ConvNet的目标检测器的训练过程。使用单个卷积网络完成proposal的分类和目标位置修正,由此产生的方法以VGG16为骨干网络时,训练速度比R-CNN快9倍,比SPPnet快3倍。在测试时,单幅图像的目标检测过程需要0.3s(不包括提取proposal的时间)。同时在PASCAL VOC 2012上实现了最高的mAP,66%(R-CNN为62%)。
1.1 R-CNN和SPP
R-CNN通过使用深度ConvNet对proposal进行分类,实现了良好的目标检测。然而,R-CNN有明显的缺点:
训练过程太过繁琐:R-CNN首先使用proposal的log损失对ConvNet进行微调;然后,对ConvNet提取的特征训练SVM分类器,这些SVM分类器替代微调过程中的softmax分类器实现目标类别判定;最后,训练bounding-box回归器以对目标位置进行修正;
训练过程空间占用和耗时很大:训练SVM分类器和BB回归网络时,需要提取各图像全部proposal的特征并保存。对于非常深的网络,例如VGG16,特征提取过程耗时很长,磁盘空间占用也很大;
目标检测速度慢:在测试时,需要对测试图像的各proposal提取特征,使用GPU进行目标检测的速度依然为47s/幅。
R-CNN速度很慢,因为它不共享计算过程,而是对每个proposal都需要执行一次ConvNet前向运算。
SPP Net通过共享计算来加速R-CNN,SPPnet计算整个输入图像的卷积特征图,然后从总的特征图上提取各proposal对应的特征实现其类别判定,由于各proposal大小不同,对应的特征大小也不同,SPP中通过应用池化核大小可变的最大池化得到固定大小的输出特征(例如,6×6),连接多个尺度的输出特征,SPP可以实现多个尺度的快速目标检测。SPP的检测速度比R-CNN快10到100倍。由于proposal的特征提取速度加快,模型的训练时间也减少了3倍。
SPPnet也有明显的缺点,与R-CNN一样,其训练过程包含多个阶段,涉及到了提取特征、微调具有log损失的网络、训练SVM和拟合bounding-box回归器,特征也需要存储到硬盘上。但与R-CNN不同,SPP-Net中微调时无法更新空间金字塔池化层(SPP层)之前的卷积层,该缺陷(固定卷积层的参数)限制了最终的检测精度。
1.2 创新点
我们提出了一种新的训练算法,它可以解决R-CNN和SPPnet的缺点,同时提高它们的速度和准确性。我们称这种方法为Fast R-CNN,因为它训练和测试的速度相对较快。 Fast R-CNN方法有几个优点:
比R-CNN、SPPnet具有更高的mAP;
使用多任务损失进行单阶段训练;
训练过程可以更新网络的所有层;
不需要任何的硬盘空间进行特征缓存。
2 Fast R-CNN结构和训练
Fast R-CNN的架构如下:
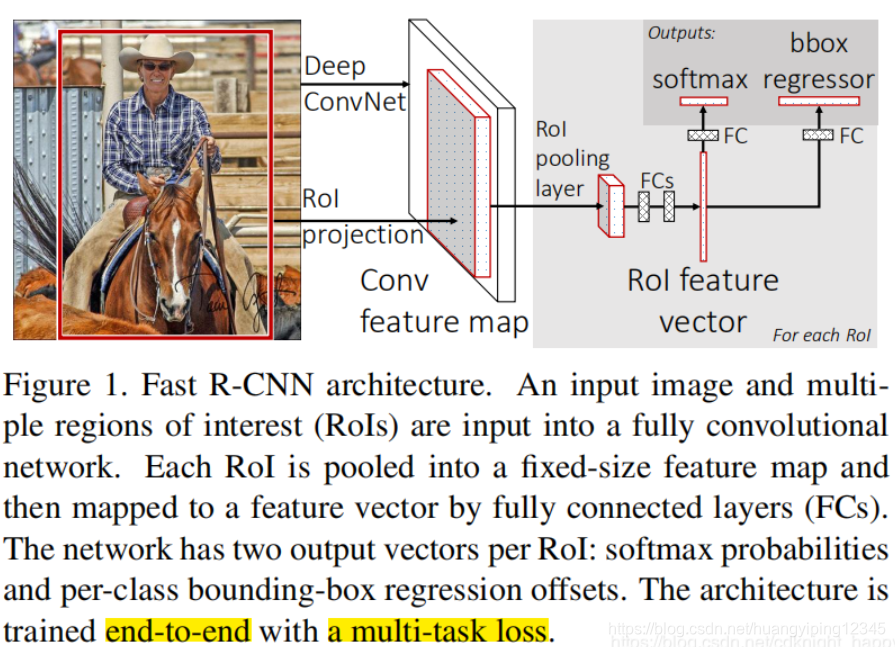
Fast R-CNN的输入是整个图像和一组proposal(2000个),首先对输入图像应用卷积和最大池化操作产生卷积特征图,然后,对于每个proposal,通过ROI Pooling层从全图的特征图中提取和该proposal对应的固定长度的特征向量,提取的特征向量送入多个全连接层,最终分成两个输出层:一个产生proposal的类别信息(通过softmax函数得到的K+1个概率值),另一个输出大小为K∗4的实数值,表示该proposal对于各类别bounding box坐标的修正值。
2.1 ROI池化层
RoI池化层使用最大池化将任何尺寸的感兴趣区域的特征转换为大小固定为H×W(如,7×7)的特征值。其中H和W是超参数,与任何特定的RoI无关。在本文中,RoI是卷积特征映射上的某个矩形窗口,每个RoI由四元组 ( r , c , h , w ) (r,c,h,w) (r,c,h,w)定义,指定其左上角位置 ( r , c ) (r,c) (r,c)和高度宽度 ( h , w ) (h,w) (h,w)。(注:FPN+Fast RCNN代码中实现是左上角、右下角坐标)
RoI 最大池化层通过将大小为 h × w h×w h×w的RoI窗口划分为大约 H × W H×W H×W个大小为 h / H × w / W h/H×w/W h/H×w/W的子窗口,然后将每个子窗口中的值应用最大池化得到输出值。和标准最大池化一样,ROI池化操作独立应用于特征图的每个通道。RoI层只是SPPnets中使用的SPP层的特例,因为这里只有一个尺度。
2.2 使用预训练网络初始化
我们尝试了三个预训练的ImageNet 网络,每个网络都有五个最大池化层,但卷积层有五到十三个(有关网络详细信息,请参见第5.1节)。
使用预训练的分类网络初始化Fast R-CNN网络时,需要进行三项调整:
*最后一个最大池化层替换为RoI池化层,ROI池化层的参数H和W依据该层后接的第一个全连接层来配置(例如,对于VGG16,H = W = 7),目的就是保证ROI池化层的输出和后面的全连接层的输入的尺寸一致;
*网络的最后一个全连接层和softmax层(用于1000类ImageNet分类训练)被前面描述的两个输出层替换(K+1类的全连接层后接softmax;及各类的bounding-box回归器,全连接层实现);
*网络被修改为采用两个数据输入:图像和各图像的RoI集合。
2.3 针对目标检测进行微调
*能够通过反向传播训练所有层的参数是Fast R-CNN的重要创新点。
首先,解释下为什么SPPnet无法更新空间金字塔池化层之前的网络层的权重。
根本原因是,R-CNN和SPPnet网络的训练时,每个训练样本(即,ROI)来自于不同的图像,通过SPP层反向传播时非常低效。这是因为每个RoI可能具有非常大的感受野,通常几乎覆盖了整个输入图像。由于前向传播必须处理整个感受野,因此训练输入很大(通常是整个图像),造成反向传播时的计算量很大。(理解:RCNN是每个batch从所有图像中取128个ROI,然后每个ROI都要过卷积层求特征,卷积特征参数不共享)
*Fast R-CNN在训练期间通过特征共享实现了更高效的训练。Fast R-CNN训练过程中,mini-batch的随机梯度下降(SGD)按层次采样,首先选择N个图像,然后从每个图像中采样R / N个RoI。重要的是,来自相同图像的各RoI在前向和反向传播中共享计算和存储(理解:一张图像只卷积一次,共享卷积计算),这样使得计算量减少了N倍。例如,当N = 2,R = 128时,该训练方案比从128个不同图像中各采样一个RoI(即,R-CNN和SPPnet的策略)大约快64倍。
对这种策略的一个担忧是它可能导致训练收敛速度慢,因为来自同一图像的RoI具有一定的相关性。但实验结果可以打消我们的疑虑,通过使用比R-CNN更少的SGD迭代,使用N = 2和R = 128的Fast R-CNN获得了良好的检测结果。
*Fast R-CNN还使用简化的训练和微调过程,同时优化softmax分类器和边界框回归器,而不是像R-CNN那样分别训练softmax分类器,SVM和回归器。具体的训练细节(损失函数,小批量抽样策略,通过RoI池化层的反向传播和SGD超参数)描述如下:
多任务损失
Fast R-CNN网络具有两个输出层,第一个输出每个RoI的K + 1个类别的离散概率分布 p = ( p 0 , … , p k ) p=(p_0,…,p_k) p=(p0,…,pk), p p p是通过对一个具有K+1个神经元的全连接层应用softmax函数得到。第二个输出为输入的proposal对于各类目标ground-truth box的位置及宽高偏移, t k = ( t x k , t y k , t w k , t h k ) t^k=(t^k_x,t^k_y,t^k_w,t^k_h) tk=(tx
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









