 Redis字典dict实现与Hash数据结构解析
Redis字典dict实现与Hash数据结构解析





 本文详细介绍了Redis中Hash数据结构的底层实现,主要为字典dict,包括其哈希表结构、负载因子、扩容机制以及如何处理键冲突。同时提到了在数据量较小时,Redis会使用ziplist作为Hash的底层实现。
本文详细介绍了Redis中Hash数据结构的底层实现,主要为字典dict,包括其哈希表结构、负载因子、扩容机制以及如何处理键冲突。同时提到了在数据量较小时,Redis会使用ziplist作为Hash的底层实现。
Hash底层数据结构
Hash 数据结构底层实现为一个字典( dict )哈希表,也是RedisBb用来存储K-V的数据结构,Redis内存数据库,最底层是一个redisDb;字典中的每一项,使用dictEntry ,代表KV键值;类似于HashMap中的键值对Entry。dict是一种用于维护key和value映射关系的数据结构,与很多编程语言中的Map类似。
关于Redis存储模型结构可以参考我的这篇博客:Redis第七讲 Redis存储模型详解
Dict的效率高表现在哪里?
因为dict/map实现了key和value的映射,通过key查询value是效率非常高的操作,时间复杂度是O(c),C是常数,在没有冲突/碰撞的情况下,可以达到O(1)。
dict本质上是为了解决算法中的查找问题(Searching),一般查找问题的解法分为两个大类:一个是基于各种平衡树,一个是基于哈希表。
- 平衡树,如二叉搜索树、红黑树,使用的是“二分思想”;如果需要实现排序,则可使用平衡树,如:用大顶堆实现TreeMap;
- 哈希表,如Java中的Map,Python中的字典dict,使用的是“映射思想”;
我们平常使用的各种Map或dict,大都是基于哈希表实现的。在不要求数据有序存储,且能保持较低的哈希值冲突概率的前提下,基于哈希表的查找性能能做到非常高效,接近O(1),而且容易实现。
字典dict的主要用途有以下两个:
- 实现数据库键空间(key space);
- 用作 hash 键的底层实现之一;
Redis数据库键空间(key space)
Redis 是一个键值对数据库服务器,服务器中每个数据库都由 redisDB 结构表示(默认16个库)。其中,redisDB 结构的 dict 字典保存了数据库中所有的键值对,这个字典被称为键空间(key space)。
可以认为,Redis默认16个库,这16个库在各自的键空间(key space)中;其实就通过键空间(key space)实现了隔离。而键空间(key space)底层是dict实现的。
-
键空间(key space)除了实现了16个库的隔离,还能基于键空间通知(Keyspace Notifications) 实现某些事件的订阅通知,如某个key过期的时间,某个key的value变更事件。
-
键空间通知(Keyspace Notifications),是因为键空间(key space)实现了16个库的隔离,而我们执行Redis命令最终都是落在其中一个库上,当有事件发生在某个库上时,该库对应的键空间(key space)就能基于pub/sub发布订阅,实现事件“广播”。
Redis字典dict如何实现的?
Redis字典dict,也是采用哈希表,本质就是数组+链表。也是众多编程语言实现Map的首选方式,如Java中的HashMap。
Redis字典dict 的底层实现,其实和Java中的ConcurrentHashMap思想非常相似。
就是用数组+链表实现了分布式哈希表。当不同的关键字、散列到数组相同的位置,就拉链,用链表维护冲突的记录。当冲突记录越来越多、链表越来越长,遍历列表的效率就会降低,此时需要考虑将链表的长度变短。
将链表的长度变短,一个最直接有效的方式就是扩容数组。将数组+链表结构中的数组扩容,数组变长、对应数组下标就增多了;将原数组中所有非空的索引下标、搬运到扩容后的新数组,经过重新散列,自然就把冲突的链表变短了。
Redis dictht的负载因子
我们知道当HashMap中由于Hash冲突(负载因子)超过某个阈值时,出于链表性能的考虑、会进行扩容,Redis dict也是一样。
-
一个dictht 哈希表里,核心就是一个dictEntry数组,同时用size记录了数组大小,用used记录了所有记录数。
-
dictht的负载因子,就是used与size的比值,也称装载因子(load factor)。这个比值越大,哈希值冲突概率越高。当比值[默认]超过5,会强制进行rehash。
dictEntry结构中包含k, v和指向链表下一项的next指针。k是void指针,这意味着它可以指向任何类型。v是个union,当它的值是uint64_t、int64_t或double类型时,就不再需要额外的存储,这有利于减少内存碎片。当然,v也可以是void指针,以便能存储任何类型的数据。
next 指向另一个 dictEntry 结构, 多个 dictEntry 可以通过 next 指针串连成链表, 从这里可以看出, dictht 使用链地址法来处理键碰撞: 当多个不同的键拥有相同的哈希值时,哈希表用一个链表将这些键连接起来。
下图展示了一个由 dictht 和数个 dictEntry 组成的哈希表例子:
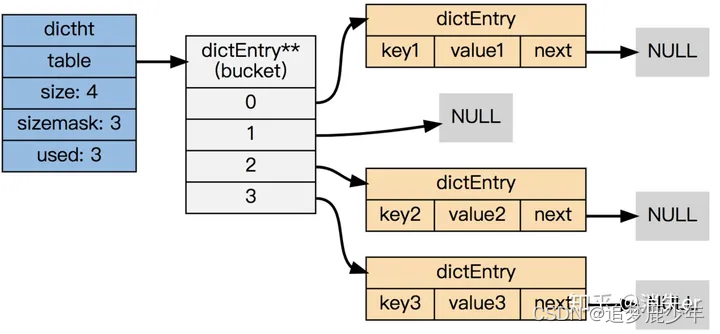
如果再加上之前列出的 dict 类型,那么整个字典结构可以表示如下:
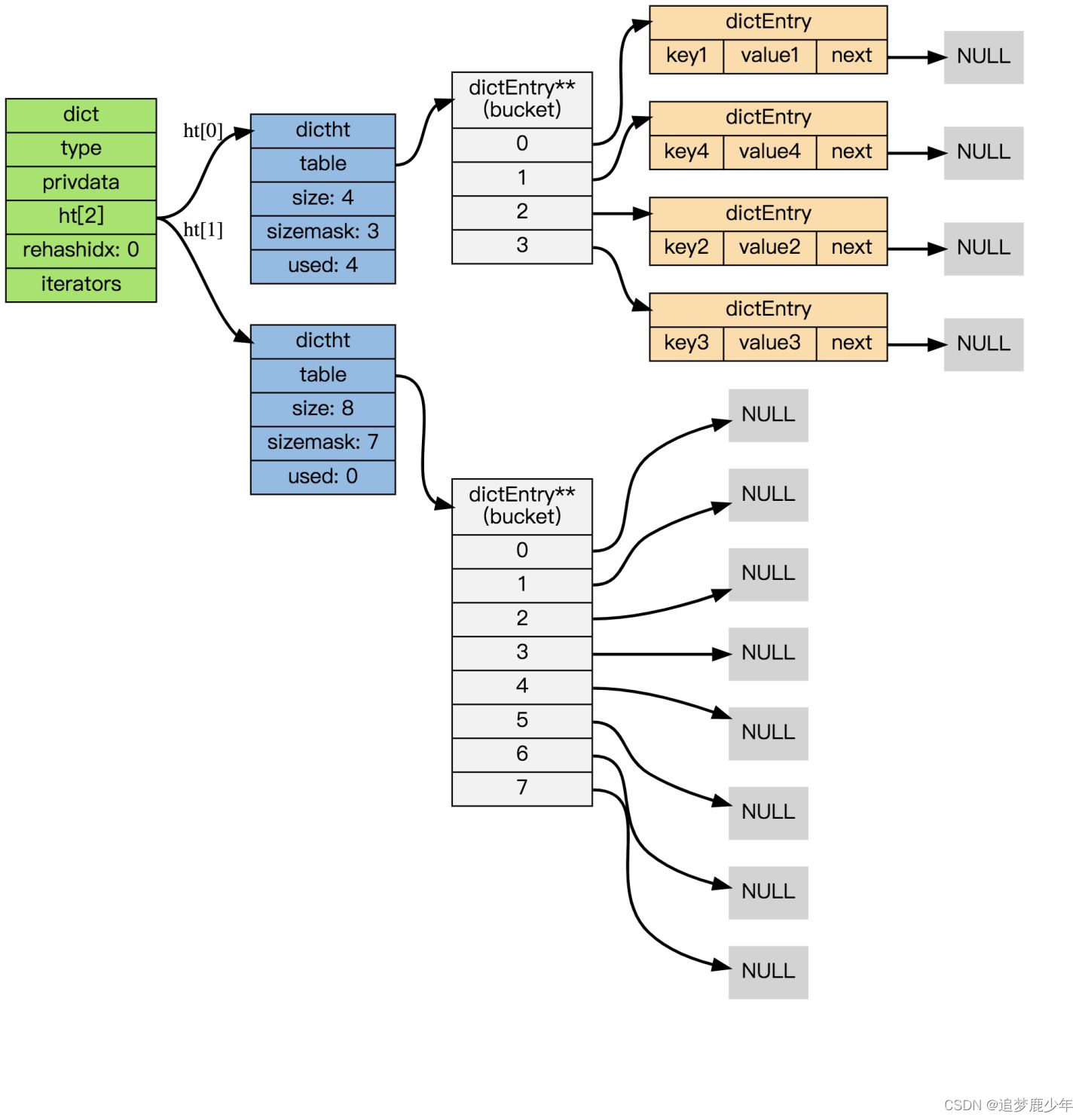
当rehash为1表示扩容,此时ht[1]才会用到,关于rehash后面会介绍到。
关于dict字典数据结构,可以参考我的这篇博客:Redis第七讲 Redis存储模型详解
Ziplist可以作为hash数据结构实现
当数据量比较小,或者单个元素比较小时,底层用ziplist存储,因为压缩列表 比字典更节省内存,所以程序在创建新 Hash 键时,默认使用压缩列表作为底层实现, 当有需要时,才会将底层实现从压缩列表转换到字典。当数据量或者数据个数操作限制时使用hashtable存储,数据大小和元素数量阈值可以通过如下参数设置。
hash-max-ziplist-entries 512 // ziplist 元素个数超过 512 ,将改为hashtable编码
hash-max-ziplist-value 64 // 单个元素大小超过 64 byte时,将改为hashtable编码
首先通过hset写进去数据时,数据写入进去的数据结构是字典,字典是无序的,当hset写进去的数据量比较小的时候 hget的数据和写进去时候的顺序是一样的,因为底层是使用的zipList去存储,当写入的数据比较大的时候,hgett时数据就不是写进去时候的样式
String 和hash类型
String set的时候key的string类型
hashSet的时候 是对key的hashtable编码
hset ha k1 v1 k2 v2 k3 v3
使用 type ha(hash类型数据)
输出 hash
使用 object encoding ha
输出 ziplist
如果set值比较大超过65字节 就会将zipList转换为hashTable编码
关于ziplist数据结构在前面的List底层数据结构实现中已经有讲到,可以参考我的这篇博客:Redis第六讲 Redis之List底层数据结构实现


















 2119
2119

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











