<think>好的,我现在需要帮助用户解决在ArcGIS 10.8和Python 2.7环境下,根据选择字段的字段值分割SHP文件的问题。首先,我需要确认用户的需求:他们想通过编写Python脚本,使用特定字段的值来分割SHP文件。这可能涉及到遍历每个要素,根据字段值将要素分类到不同的输出文件中。
首先,我应该考虑ArcGIS 10.8的环境,因为ArcGIS 10.8使用的是Python 2.7,这一点用户已经明确。不过需要注意的是,Python 2.7已经停止支持,可能存在兼容性问题,但用户可能因为ArcGIS版本的限制必须使用。接下来,用户需要根据字段值分割SHP,可能需要用到arcpy模块,这是ArcGIS的Python库。
接下来,我需要回忆arcpy中处理Shapefile的相关函数。分割操作通常涉及读取输入文件,遍历每个要素,获取指定字段的值,然后根据该值将要素写入不同的输出文件。可能需要使用搜索游标(SearchCursor)来遍历要素,同时对于每个唯一的字段值,创建对应的输出Shapefile,并使用插入游标(InsertCursor)将要素写入。
不过,直接为每个字段值创建单独的SHP文件可能效率不高,特别是当字段值很多时。或者,是否存在更高效的方法,比如使用工具Split By Attributes?但用户可能希望用脚本实现,以便自定义或集成到其他流程中。
需要检查arcpy是否有现成的工具可以实现这个功能,比如分析工具中的“分割”工具(Split)。如果有的话,可能只需调用arcpy.Split_analysis()函数,但需要确认该工具在ArcGIS 10.8中是否存在。假设存在,那么代码会相对简单。否则,需要手动处理。
假设用户需要手动编写代码,流程大致如下:
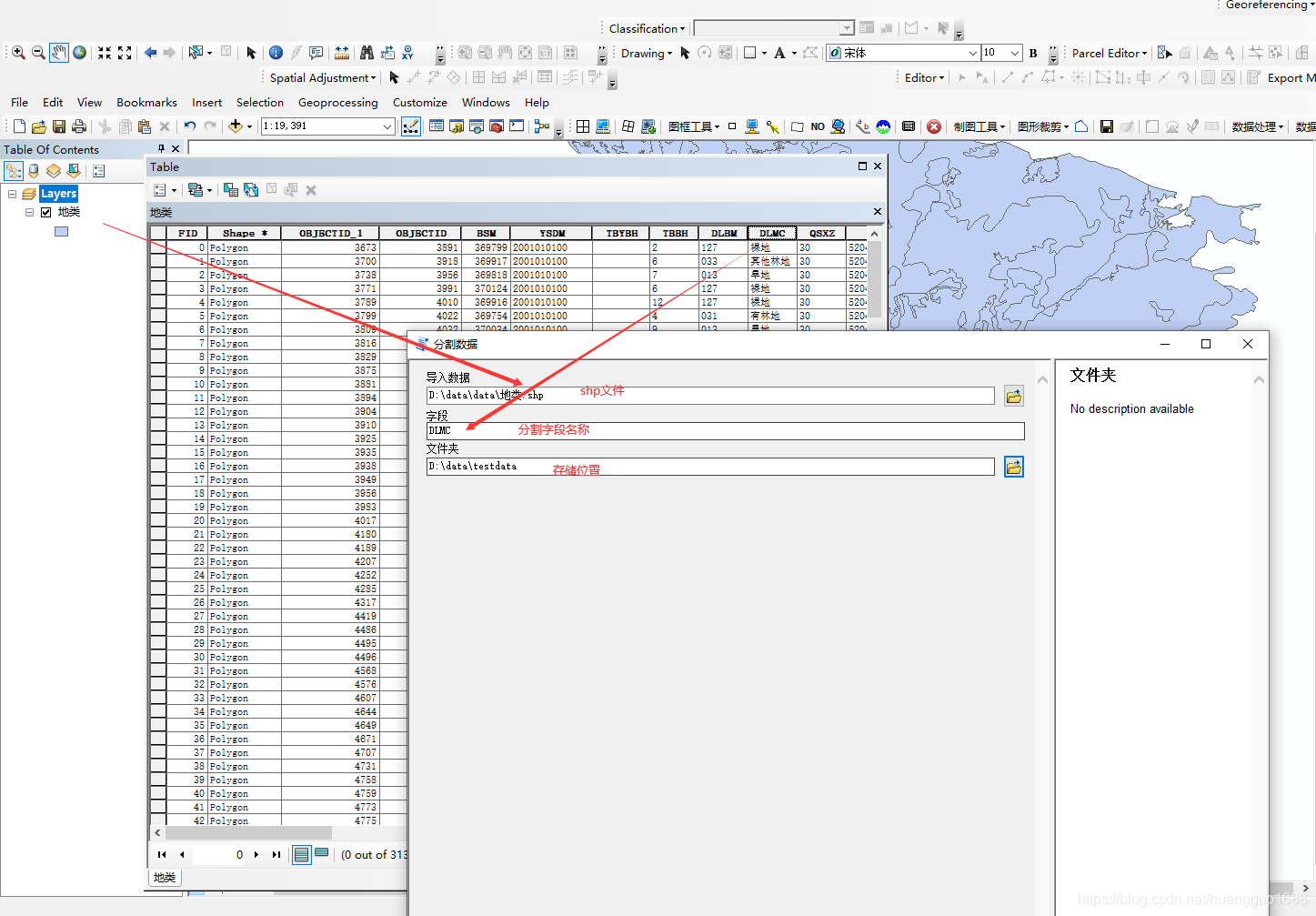
1. 输入参数:输入SHP路径,分割字段名,输出文件夹。
2. 使用SearchCursor遍历输入SHP的每个要素。
3. 对于每个要素,获取分割字段的值。
4. 根据字段值创建对应的输出SHP(如果不存在),并复制要素进去。
5. 处理几何和属性表的复制。
需要注意的是,每次创建新的SHP文件时,需要定义其字段结构,与原始文件一致。可以使用arcpy.CreateFeatureclass_management函数,并复制字段。或者,使用Select_analysis工具,每次选择特定字段值的要素并导出。这可能更高效,因为Select_analysis可以处理查询,直接生成新的SHP,而不需要逐条记录处理。
例如,可以先获取所有唯一的字段值,然后循环每个唯一值,构造SQL查询语句,使用Select_analysis导出到对应的SHP文件。这种方法可能更简单,且效率更高,因为利用了现有的工具。
所以,步骤可能调整为:
1. 获取输入SHP的路径、分割字段名、输出文件夹。
2. 使用arcpy.da.SearchCursor获取所有唯一的字段值。
3. 对于每个唯一值,构造Where子句,例如“FieldName = 'Value'”或者“FieldName = 123”。
4. 使用arcpy.Select_analysis工具,将符合该条件的要素导出到新的SHP文件,保存在输出文件夹中。
这种方法避免了手动创建要素类和插入要素,代码更简洁,且效率更高。同时,Select_analysis会处理字段结构的复制,不需要手动创建字段。
接下来,考虑字段类型,如果是文本类型,值需要加引号,如果是数字则不需要。因此,在构造Where子句时,需要判断字段类型,以正确添加引号。例如,使用arcpy.ListFields函数获取字段类型,然后根据类型决定是否添加引号。
不过,在ArcGIS的SQL表达式中,字符串值需要用单引号括起来,而数值不需要。例如,如果字段类型是字符串,那么查询应该是"Field = 'Value'",而如果是数字,则是"Field = 123"。
因此,代码需要:
- 确定分割字段的数据类型。
- 根据类型构造正确的Where子句。
此外,处理唯一值时,需要考虑特殊字符,比如字段值中含有单引号,这时需要进行转义,但这种情况可能较少,用户需要注意。
总结步骤:
1. 导入arcpy模块,设置环境。
2. 定义输入参数:输入shp路径,分割字段名,输出文件夹。
3. 获取分割字段的数据类型。
4. 使用SearchCursor获取所有唯一的分割字段值。
5. 对于每个唯一值:
a. 根据字段类型构造Where子句。
b. 使用Select_analysis导出满足条件的要素到输出路径,文件名可以基于字段值命名(需处理无效字符)。
6. 处理可能的错误,如无效的字段名,输出路径不存在等。
接下来,编写代码的大纲:
import arcpy
import os
input_shp = r"输入文件的路径"
split_field = "字段名"
output_folder = r"输出文件夹路径"
# 确保输出文件夹存在
if not os.path.exists(output_folder):
os.makedirs(output_folder)
# 获取字段类型
field_type = None
fields = arcpy.ListFields(input_shp)
for field in fields:
if field.name == split_field:
field_type = field.type
break
# 获取唯一值
unique_values = set()
with arcpy.da.SearchCursor(input_shp, [split_field]) as cursor:
for row in cursor:
unique_values.add(row[0])
# 遍历每个唯一值
for value in unique_values:
# 处理文件名中的特殊字符,替换为下划线等
safe_value = str(value).replace(" ", "_").replace("'", "").replace('"', '')
output_shp = os.path.join(output_folder, f"{safe_value}.shp")
# 构造Where子句
if field_type in ['String', 'Text']:
where_clause = f"{arcpy.AddFieldDelimiters(input_shp, split_field)} = '{value}'"
else:
where_clause = f"{arcpy.AddFieldDelimiters(input_shp, split_field)} = {value}"
# 执行Select分析
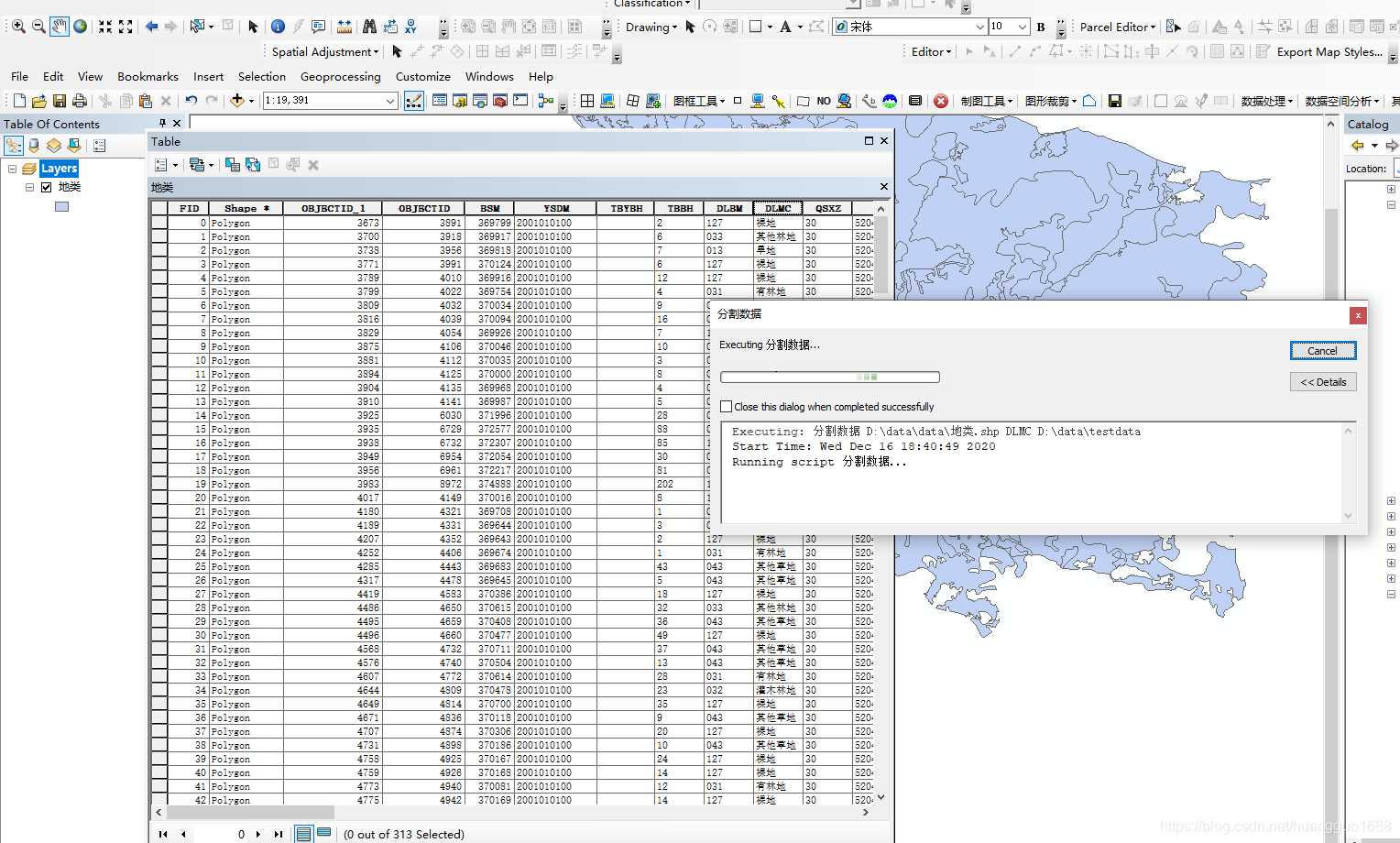
arcpy.Select_analysis(input_shp, output_shp, where_clause)
print("处理完成!")
需要注意的几点:
- 使用arcpy.AddFieldDelimiters来处理字段名,特别是当字段名含有空格或特殊字符时,会自动添加正确的分隔符,如双引号或方括号。
- 处理输出文件名时,需要确保value中没有非法字符(如空格、斜杠等),否则会导致文件创建失败。这里用替换空格为下划线,移除引号等简单处理,可能需要更全面的清理,比如使用正则表达式替换所有非字母数字字符。
- 错误处理:例如,字段不存在,或无权限写入输出文件夹等,可以添加try-except块。
- 性能问题:如果唯一值很多,可能会生成大量SHP文件,需要注意磁盘空间和性能。
此外,用户可能需要考虑是否覆盖现有文件,可以使用arcpy.env.overwriteOutput = True来允许覆盖。
综上,这段代码应该可以满足用户的需求,使用arcpy的Select_analysis工具根据字段值分割SHP文件。需要注意的是,由于ArcGIS 10.8使用的是Python 2.7,字符串格式化可能需要调整,例如使用.format()而不是f-strings(因为f-strings在Python 3.6+引入)。所以,在Python 2.7中,output_shp应该写成os.path.join(output_folder, "{0}.shp".format(safe_value))。
因此,修正代码中的字符串格式化部分:
output_shp = os.path.join(output_folder, "{0}.shp".format(safe_value))
另外,处理字段类型时,需要确认ListFields返回的type属性对应的字符串。例如,字符串类型可能是'String',而整数可能是'Integer',双精度浮点数是'Double'等。确保在构造Where子句时正确判断是否为文本类型。
最后,测试代码,确保生成的各个SHP文件只包含对应字段值的要素。</think>在ArcGIS 10.8和Python 2.7环境下,可通过以下脚本根据字段值分割Shapefile文件。该方法利用`arcpy.Select_analysis`工具实现高效分割:
```python
# -*- coding: utf-8 -*-
import arcpy
import os
# 设置覆盖输出
arcpy.env.overwriteOutput = True
# 输入参数设置
input_shp = r"C:\data\input.shp" # 输入Shapefile路径
split_field = "TYPE" # 分割依据字段名
output_folder = r"C:\output" # 输出文件夹路径
# 创建输出文件夹
if not os.path.exists(output_folder):
os.makedirs(output_folder)
# 获取字段类型字典
field_type_dict = {
"Integer": "LONG",
"String": "TEXT",
"Double": "DOUBLE",
"Date": "DATE"
}
# 验证字段存在性
field_names = [f.name for f in arcpy.ListFields(input_shp)]
if split_field not in field_names:
raise ValueError("字段 {} 不存在于输入文件中".format(split_field))
# 获取字段类型
field_type = [f.type for f in arcpy.ListFields(input_shp) if f.name == split_field][0]
# 获取唯一字段值
unique_values = set()
with arcpy.da.SearchCursor(input_shp, [split_field]) as cursor:
for row in cursor:
if row[0] is not None: # 过滤空值
unique_values.add(row[0])
# 分割处理
for value in unique_values:
try:
# 创建安全文件名(替换特殊字符)
safe_name = "".join([c if c.isalnum() else "_" for c in str(value)])
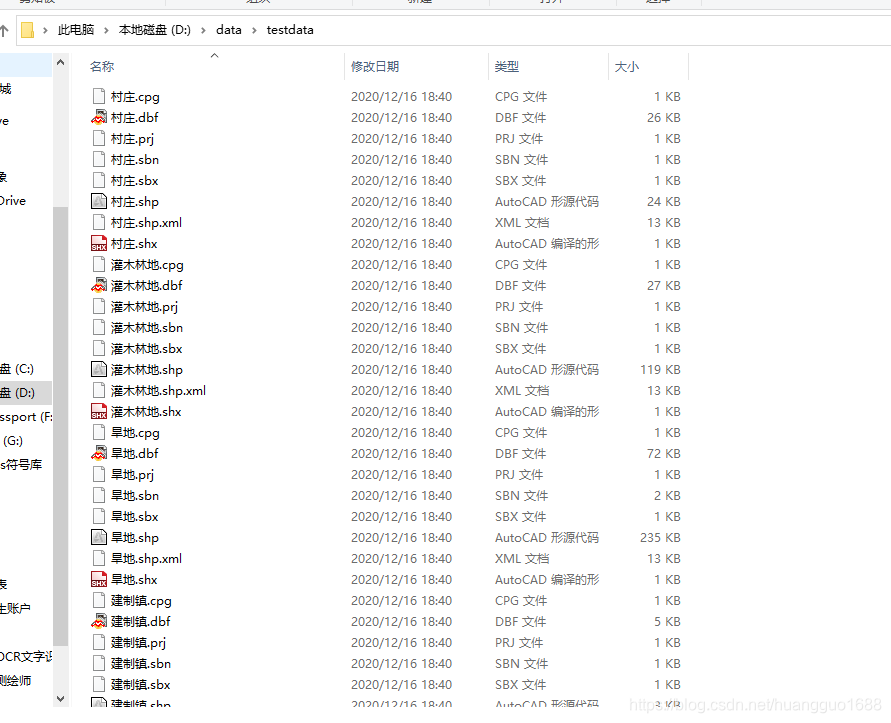
output_path = os.path.join(output_folder, safe_name + ".shp")
# 构造查询条件
if field_type in ["String", "Date"]:
where_clause = "{} = '{}'".format(
arcpy.AddFieldDelimiters(input_shp, split_field),
value
)
else:
where_clause = "{} = {}".format(
arcpy.AddFieldDelimiters(input_shp, split_field),
value
)
# 执行要素选择
arcpy.Select_analysis(
in_features=input_shp,
out_feature_class=output_path,
where_clause=where_clause
)
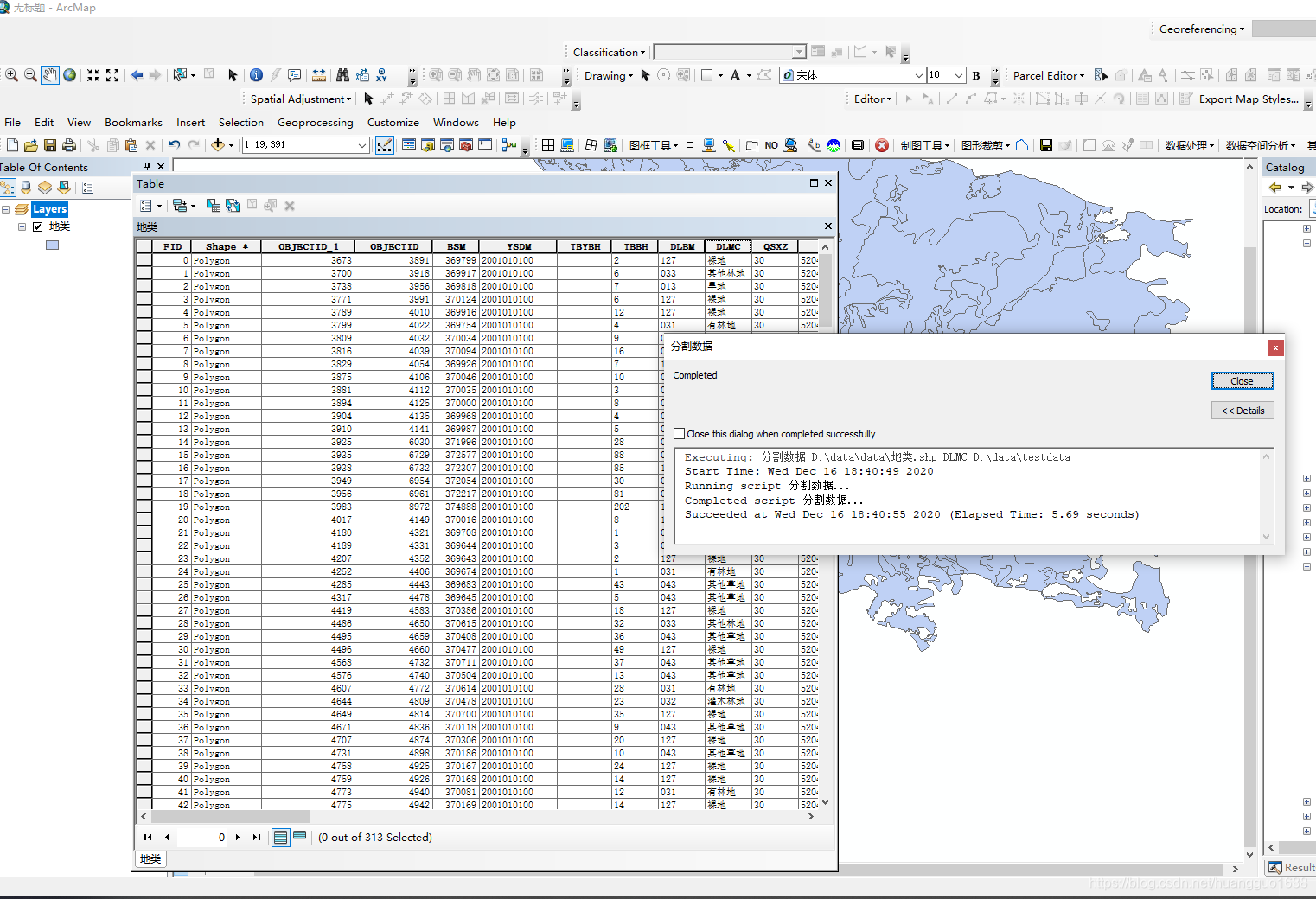
print("已创建: {}".format(output_path))
except Exception as e:
print("错误处理值 {}: {}".format(value, str(e)))
print("处理完成!共生成 {} 个文件".format(len(unique_values)))
```
### 关键要素说明:
1. **环境配置**
- `arcpy.env.overwriteOutput = True` 自动覆盖已存在文件
- 使用`os.makedirs`创建多级输出目录
2. **字段验证**
- 自动检测字段是否存在
- 支持常见字段类型:整型、字符串、浮点型、日期型
3. **安全处理**
- 文件名特殊字符自动替换为下划线
- 使用`arcpy.AddFieldDelimiters`处理带空格字段名
- 过滤空值记录
4. **性能优化**
- 使用集合(`set`)存储唯一值提高查询效率
- 批量处理代替逐要素操作
### 使用注意事项:
1. 确保ArcGIS桌面软件已授权
2. 字段值长度不宜过长(Windows路径限制260字符)
3. 建议提前备份原始数据
4. 处理大型数据集时可能需要增加内存配置
### 扩展改进建议:
```python
# 可添加以下功能扩展
timestamp = datetime.datetime.now().strftime("%Y%m%d_%H%M")
log_file = os.path.join(output_folder, "process_log_{}.txt".format(timestamp))
def write_log(message):
with open(log_file, "a") as f:
f.write("[{}] {}\n".format(
datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S"),
message
))
# 在关键步骤添加日志记录
write_log("开始处理,共发现 {} 个唯一值".format(len(unique_values)))
```
此脚本通过系统工具实现高效分割,相比直接操作要素类,具有更好的稳定性和性能表现。实际使用时应根据数据特征调整异常处理机制。











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言





















 5093
5093





