






 本文分享了一个初学者在解决数组去重问题时的心得体会,并对比分析了自己的实现与优秀解决方案之间的差距,强调了理解题意的重要性。
本文分享了一个初学者在解决数组去重问题时的心得体会,并对比分析了自己的实现与优秀解决方案之间的差距,强调了理解题意的重要性。
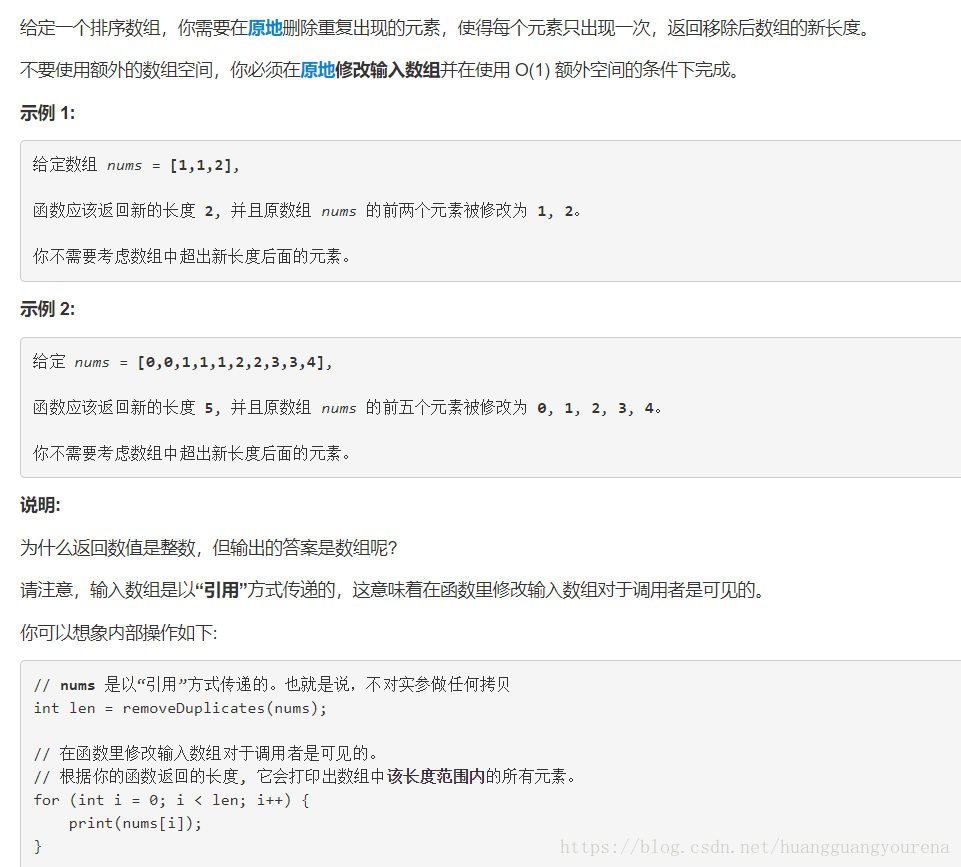
通过不断的修改,终于把自己写的代码正确的跑起来了,不过执行的时间是1304ms,跪了。才开始几天,我就已经怀疑自己是否适合编程了。下面贴上自己的代码。
class Solution:
def removeDuplicates(self, nums):
k = 0
for i in range(len(nums)):
i = k
if i+1 < len(nums):
if nums[i] == nums[i + 1]:
nums.remove(nums[i])
else:
k += 1
return len(nums)看了别人的代码后,觉得自己写的方法很笨,而且考虑到每一次remove都要对数据内的元素进行移动,就会非常的耗时。
不过还是简单的说一下自己的思路。
先不看k,这个循环就不用说了,然后判断i+1是否越界,如果不越界的话就判断相邻的两个元素是否相等,相等说明重复,这个时候删掉nums[i]即可。但是如果不相等的话,而且没有这个k的话,就会出现问题。
因为假设一开始有6个元素,那么len(nums)就是6,所以range(6)是固定好的了,但是我们在对nums进行remove操作的时候,数组的长度是会改变的,需要注意的是,数组的长度改变了,但是i却不会变回从0开始,因此我们需要一个变量k来控制。
所以k的作用就是在remove的时候,让i仍然从0开始,在相邻元素不相等的时候k自增,这样在下次进行比较的就是第二和第三个元素进行比较。
下面是高手的代码我也贴上来了,作为对比激励自己。
class Solution:
def removeDuplicates(self, nums):
if len(nums) < 2:
return len(nums)
# nums >= 2
index = 1
pre = nums[0]
for i in range(len(nums)):
if pre != nums[i]:
pre = nums[i]
nums[index] = pre
index += 1
return index这个代码的运行速度是我的1/20,真的是自愧不如,我反思了一下并重新看了一下题目,题目里面有这样一句话
"你不需要考虑数组中超出新长度后面的元素。"
也就是说我其实没有必要去通过remove操作来删除元素,而且这样做还会增加我们的执行时间,非常的不划算。
然后看这位老哥的代码,他通过设置了pre这个中间变量,然后通过扫描数组,寻找与其不相等的值,然后pre等于这个不相等的值,最后Index+=1,需要注意的就是index是从1开始的。
这个代码的执行速度并不是最快的,但是我觉得是个很好的思路,因此我复制下来作为学习的范例了。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









