







1. 初识EM、VI与VAE
1.1. EM算法
- EM是一种从频率角度解决优化问题(常见的频率角度模型有:回归模型、SVM等)。
- EM常与MLE进行对比。
- MLE(极大似然估计)

- EM算法

- MLE(极大似然估计)
1.2 VI算法
- 变分推断(Variational Inference)解决的是贝叶斯角度的积分问题,是贝叶斯推断的确定性近似推断。
- 利用EM的思路,把 log p ( x ) \log p(x) logp(x)堪称 E L B O ELBO ELBO和 K L KL KL散度的结合。再把 E L B O ELBO ELBO看成泛函,利用平均场理论进行求解。
1.3 VAE
- VAE可以看成是从
变
分
和
贝
叶
斯
的
角
度
来
解
决
A
u
t
o
E
n
c
o
d
e
r
问
题
\color{red}变分和贝叶斯的角度来解决AutoEncoder问题
变分和贝叶斯的角度来解决AutoEncoder问题。
因为用到了变分,所以常常是先看VI,再看VAE。
- VAE本质上就是:
- 常规的自编码器的基础上,对encoder的结果(在VAE中对应着计算均值的网络)加上了 “ 高 斯 噪 声 ” \color{red}“高斯噪声” “高斯噪声”,使得结果decoder能够对噪声有鲁棒性;
- 而那个额外的KL loss( 目 的 是 让 均 值 为 0 , 方 差 为 1 \color{red}目的是让均值为0,方差为1 目的是让均值为0,方差为1),事实上就是相当于对encoder的一个正则项,希望encoder出来的东西均有零均值。
2. EM与VI的异同
2.1 相同点
2.1.1 都是处理具有隐变量的问题
都 是 对 M L E 无 法 处 理 的 情 况 进 行 处 理 \color{red}都是对MLE无法处理的情况进行处理 都是对MLE无法处理的情况进行处理。明确参数的意义:
- X X X:Observed data, X = ( x 1 , x 2 , ⋯ , x N ) X = (x_1, x_2, \cdots, x_N) X=(x1,x2,⋯,xN)。
- ( X , Z ) (X,Z) (X,Z):Complete data, ( X , Z ) = { ( x 1 , z 1 ) , ( x 2 , z 2 ) , ⋯ , ( x N , z N ) } (X,Z) = \{ (x_1,z_1),(x_2,z_2),\cdots,(x_N,z_N) \} (X,Z)={(x1,z1),(x2,z2),⋯,(xN,zN)}。
- θ \theta θ:parameter, θ = { P 1 , ⋯ , P k , μ 1 , ⋯ , μ k , Σ 1 , ⋯ , Σ k } \theta=\{ P_1, \cdots, P_k, \mu_1, \cdots, \mu_k,\Sigma_1,\cdots,\Sigma_k \} θ={P1,⋯,Pk,μ1,⋯,μk,Σ1,⋯,Σk}。
- Maximum Likelihood Estimation求解参数
-
P ( x ) P(x) P(x)可以表示为:
p ( x ) = ∑ Z p ( x , Z ) = ∑ k = 1 K p ( x , z = C k ) = ∑ k = 1 K p ( z = C k ) ⋅ p ( x ∣ z = C k ) = ∑ k = 1 K p k ⋅ N ( x ∣ μ k , Σ k ) (2.1) \begin{aligned}p(x)&= \sum_Z p(x,Z) \\ & = \sum_{k=1}^K p(x,z = C_k) \\ & = \sum_{k=1}^K p(z = C_k)\cdot p(x|z=C_k) \\ & = \sum_{k=1}^K p_k \cdot \mathcal{N}(x|\mu_k,\Sigma_k)\end{aligned}\tag{2.1} p(x)=Z∑p(x,Z)=k=1∑Kp(x,z=Ck)=k=1∑Kp(z=Ck)⋅p(x∣z=Ck)=k=1∑Kpk⋅N(x∣μk,Σk)(2.1)
对比公式(11.1.1)可见几何角度的结果中的 α k \alpha_k αk就是混合模型中的 p k p_k pk,权重即概率。 -
尝试使用MLE求解GMM参数
尝试使用MLE求解GMM参数的解析解。实际上GMM一般使用EM算法求解, 因 为 使 用 M L E 求 导 后 , 无 法 求 出 具 体 解 析 解 \color{blue}因为使用MLE求导后,无法求出具体解析解 因为使用MLE求导后,无法求出具体解析解。所以接下来我们来看看为什么MLE无法求出解析解。
θ ^ M L E = a r g m a x θ l o g p ( X ) = a r g m a x θ l o g ∏ i = 1 N p ( x i ) = a r g m a x θ ∑ i = 1 N l o g p ( x i ) = a r g m a x θ ∑ i = 1 N l o g ∑ k = 1 K p k ⋅ N ( x i ∣ μ k , Σ k ) (2.2) \begin{aligned}\hat{\theta }_{MLE}&=\underset{\theta }{argmax}\; log\; p(X)\\ &=\underset{\theta }{argmax}\; log\prod_{i=1}^{N}p(x_{i})\\ &=\underset{\theta }{argmax}\sum_{i=1}^{N}log\; p(x_{i})\\ &=\underset{\theta }{argmax}\sum_{i=1}^{N}{\color{Red}{log\sum _{k=1}^{K}}}p_{k}\cdot N(x_{i}|\mu _{k},\Sigma _{k})\end{aligned}\tag{2.2} θ^MLE=θargmaxlogp(X)=θargmaxlogi=1∏Np(xi)=θargmaxi=1∑Nlogp(xi)=θargmaxi=1∑Nlogk=1∑Kpk⋅N(xi∣μk,Σk)(2.2)
想要求的 θ \theta θ包括, θ = { p 1 , ⋯ , p K , μ 1 , ⋯ , μ K , Σ 1 , ⋯ , Σ K } \color{blue}\theta=\{ p_1, \cdots, p_K, \mu_1, \cdots, \mu_K,\Sigma_1,\cdots,\Sigma_K \} θ={p1,⋯,pK,μ1,⋯,μK,Σ1,⋯,ΣK}。
-
- MLE的问题
按照之前的思路,是对每个参数进行求偏导来计算最终的结果。但 log \log log函数里是一个求和的形式,而不是求积的形式。这意味着计算非常的困难。甚至根本就求不出解析解。如果是单一的Gaussian Distribution:
log p ( x i ) = log 1 2 π σ exp { − ( x i − μ ) 2 2 σ } . (2.3) \log p(x_i) = \log \frac{1}{\sqrt{2 \pi} \sigma} \exp\left\{ -\frac{(x_i - \mu)^2}{2\sigma} \right\}.\tag{2.3} logp(xi)=log2πσ1exp{−2σ(xi−μ)2}.(2.3)
根据 log \log log函数优秀的性质,这个问题是可以解的。但是,很不幸 公 式 ( 2.2 ) 后 面 是 一 个 求 和 的 形 式 \color{red}公式(2.2)后面是一个求和的形式 公式(2.2)后面是一个求和的形式。所以,直接使用MLE求解GMM,无法得到解析解。对于含有隐变量的模型来说使用EM算法是更为合适的。
2.2.2 都是把 log p ( x ) \log p(x) logp(x)化简为ELBO+KL散度
有以下数据:
- X : o b s e r v e d v a r i a b l e → X : { x i } i = 1 N X:observed\;variable\rightarrow X:\left \{x_{i}\right \}_{i=1}^{N} X:observedvariable→X:{xi}i=1N
- Z : l a t e n t v a r i a b l e + p a r a m e t e r → Z : { z i } i = 1 N Z:latent\;variable + parameter\rightarrow Z:\left \{z_{i}\right \}_{i=1}^{N} Z:latentvariable+parameter→Z:{zi}i=1N
- ( X , Z ) : c o m p l e t e d a t a (X,Z):complete\;data (X,Z):completedata
记 z z z为隐变量和参数的集合。接着变换概率 p ( x ) p(x) p(x)的形式然后引入分布 q ( z ) q(z) q(z):
l
o
g
p
(
x
)
=
l
o
g
p
(
x
,
z
)
−
l
o
g
p
(
z
∣
x
)
=
l
o
g
p
(
x
,
z
)
q
(
z
)
−
l
o
g
p
(
z
∣
x
)
q
(
z
)
(2.4)
\color{blue}log\; p(x)=log\; p(x,z)-log\; p(z|x)=log\; \frac{p(x,z)}{q(z)}-log\; \frac{p(z|x)}{q(z)}\tag{2.4}
logp(x)=logp(x,z)−logp(z∣x)=logq(z)p(x,z)−logq(z)p(z∣x)(2.4)
3. 公式简化
对公式(12.2.1)进行简化,式子两边同时对
q
(
z
)
q(z)
q(z)求积分(期望):
左
边
=
∫
z
q
(
z
)
⋅
l
o
g
p
(
x
∣
θ
)
d
z
=
l
o
g
p
(
x
∣
θ
)
∫
z
q
(
z
)
d
z
=
l
o
g
p
(
x
∣
θ
)
(2.5)
左边=\int _{z}q(z)\cdot log\; p(x |\theta )\mathrm{d}z=log\; p(x|\theta )\int _{z}q(z )\mathrm{d}z=log\; p(x|\theta )\tag{2.5}
左边=∫zq(z)⋅logp(x∣θ)dz=logp(x∣θ)∫zq(z)dz=logp(x∣θ)(2.5)
右
边
=
∫
z
q
(
z
)
l
o
g
p
(
x
,
z
∣
θ
)
q
(
z
)
d
z
⏟
E
L
B
O
(
e
v
i
d
e
n
c
e
l
o
w
e
r
b
o
u
n
d
)
−
∫
z
q
(
z
)
l
o
g
p
(
z
∣
x
,
θ
)
q
(
z
)
d
z
⏟
K
L
(
q
(
z
)
∣
∣
p
(
z
∣
x
,
θ
)
)
=
L
(
q
)
⏟
变
分
+
K
L
(
q
∣
∣
p
)
⏟
≥
0
(2.6)
右边=\underset{ELBO(evidence\; lower\; bound)}{\underbrace{\int _{z}q(z)log\; \frac{p(x,z|\theta )}{q(z)}\mathrm{d}z}}\underset{KL(q(z)||p(z|x,\theta ))}{\underbrace{-\int _{z}q(z)log\; \frac{p(z|x,\theta )}{q(z)}\mathrm{d}z}}=\underset{变分}{\underbrace{L(q)}} + \underset{\geq 0}{\underbrace{KL(q||p)}}\tag{2.6}
右边=ELBO(evidencelowerbound)
∫zq(z)logq(z)p(x,z∣θ)dzKL(q(z)∣∣p(z∣x,θ))
−∫zq(z)logq(z)p(z∣x,θ)dz=变分
L(q)+≥0
KL(q∣∣p)(2.6)
Evidence Lower Bound (ELBO)是变分,
L
(
q
)
L(q)
L(q)和
K
L
(
q
∣
∣
p
)
KL(q||p)
KL(q∣∣p)被记为:
{
L
(
q
)
=
∫
z
q
(
z
)
log
p
(
x
,
z
∣
θ
)
q
(
z
)
d
z
K
L
(
q
∣
∣
p
)
=
−
∫
z
q
(
z
)
log
p
(
z
∣
x
)
q
(
z
)
d
z
\color{blue}\{ \begin{array}{ll}L(q)&=\int_z q(z)\log\ \frac{p(x,z|\theta)}{q(z)}dz\\ KL(q||p)&= - \int_z q(z)\log\ \frac{p(z|x)}{q(z)}dz \end{array}
{L(q)KL(q∣∣p)=∫zq(z)log q(z)p(x,z∣θ)dz=−∫zq(z)log q(z)p(z∣x)dz
2.2 不同点
2.2.1 EM算法
在把
log
p
(
x
)
\log p(x)
logp(x)转换为公式(2.7)后,
l
o
g
p
(
x
∣
θ
)
=
E
L
B
O
+
K
L
(
q
(
z
)
∣
∣
p
(
z
∣
x
,
θ
)
)
(2.7)
\color{red}log\; p(x|\theta )=ELBO+KL(q(z)||p(z|x,\theta ))\tag{2.7}
logp(x∣θ)=ELBO+KL(q(z)∣∣p(z∣x,θ))(2.7)
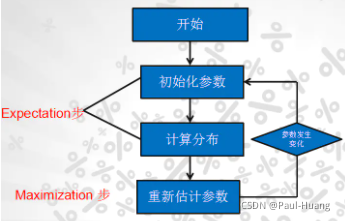
EM算法是(EM算法实例):
- 第一步是E:求出期望;
固定 θ ( t ) \theta^{(t)} θ(t),改变 q ( z ) q(z) q(z),使得 K L ( q ( z ) ∣ ∣ p ( z ∣ x , θ ) ) = − ∫ z q ( z ) l o g p ( z ∣ x , θ ) q ( z ) d z = 0 {KL(q(z)||p(z|x,\theta ))}={-\int _{z}q(z)log\; \frac{p(z|x,\theta )}{q(z)}\mathrm{d}z}=0 KL(q(z)∣∣p(z∣x,θ))=−∫zq(z)logq(z)p(z∣x,θ)dz=0,求期望。即:
log p ( x ∣ θ ( t ) ) = ∫ z q ( z ) l o g p ( x , z ∣ θ ) q ( z ) d z = E L B O . (2.8) \color{red}\log\; p(x|\theta ^{(t)})={\int _{z}q(z)log\; \frac{p(x,z|\theta )}{q(z)}\mathrm{d}z}=ELBO.\tag{2.8} logp(x∣θ(t))=∫zq(z)logq(z)p(x,z∣θ)dz=ELBO.(2.8) - 第二步是M:将期望最大化。
固定 q ( z ) q(z) q(z),将期望最大化.极大化:
θ ( t + 1 ) = arg max θ E z ∼ P ( z ∣ x , θ ( t ) ) [ log P ( x , z ∣ θ ) ] (2.9) \color{red}\theta^{(t+1)} = \arg\underset{\theta}{\max} \mathbb{E}_{z\sim P(z|x,\theta^{(t)})}\left[ \log P(x,z|\theta) \right]\tag{2.9} θ(t+1)=argθmaxEz∼P(z∣x,θ(t))[logP(x,z∣θ)](2.9)
2.2.2 VI算法
在把
log
p
(
x
)
\log p(x)
logp(x)转换为公式(2.7)后,
l
o
g
p
(
x
∣
θ
)
=
E
L
B
O
+
K
L
(
q
(
z
)
∣
∣
p
(
z
∣
x
,
θ
)
)
(2.7)
\color{red}log\; p(x|\theta )=ELBO+KL(q(z)||p(z|x,\theta ))\tag{2.7}
logp(x∣θ)=ELBO+KL(q(z)∣∣p(z∣x,θ))(2.7)
VI算法使用平均场理论,再进一步分布求解。
平均场理论:把多维变量的不同维度分为 M M M组,组与组之间是相互独立的:
q ( z ) = ∏ i = 1 M q i ( z i ) (2.10) \color{red}q(z)=\prod_{i=1}^{M}q_{i}(z_{i})\tag{2.10} q(z)=i=1∏Mqi(zi)(2.10)
3. VI与VAE异同
- VAE利用了VI中的 K L ( p ( x ) ∣ ∣ q ( x ) ) KL(p(x)||q(x)) KL(p(x)∣∣q(x))的性质,其实质是在AutoEncoder中引入贝叶斯模型。
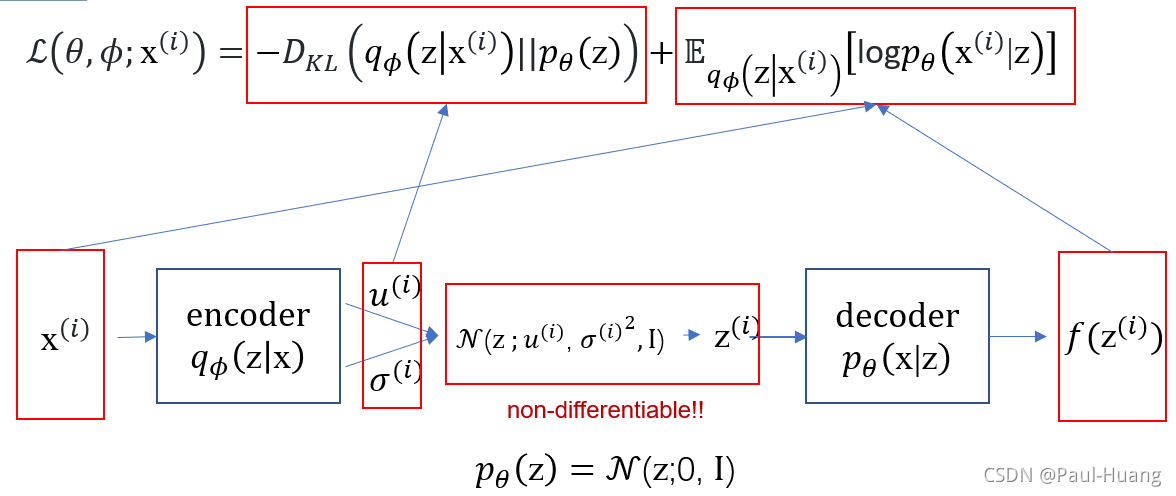
- VAE 利用了EM算法和VI算法对 E L B O ELBO ELBO的化简:
L ( θ , ϕ ; x ( i ) ) = ∑ z q ϕ ( z ∣ x ( i ) ) log ( p θ ( x , z ) q ϕ ( z ∣ x ( i ) ) ) = ∑ z q ϕ ( z ∣ x ( i ) ) log ( p θ ( x ( i ) ∣ z ) p θ ( z ) q ϕ ( z ∣ x ( i ) ) ) = ∑ z q ϕ ( z ∣ x ( i ) ) [ log ( p θ ( x ( i ) ∣ z ) ) + log ( p θ ( z ) q ϕ ( z ∣ x ( i ) ) ) ] = − D K L ( q ϕ ( z ∣ x ( i ) ) ∣ ∣ p θ ( z ) ) + E q ϕ ( z ∣ x ( i ) ) [ log p θ ( x ( i ) ∣ z ) ] (3.1) \begin{aligned}\color{red}\mathcal{L}(\theta,\phi;\mathtt{x}^{(i)}) &=\sum_{\mathbf{z}} q_{\phi}(\mathtt{z}|\mathtt{x}^{(i)}) \log \left(\frac{p_{\theta}(\mathbf{x}, \mathbf{z})}{q_{\phi}(\mathtt{z}|\mathtt{x}^{(i)})}\right)=\sum_{\mathtt{z}} q_{\phi}(\mathtt{z}|\mathtt{x}^{(i)}) \log \left(\frac{p_{\theta}(\mathtt{x}^{(i)}| \mathtt{z}) p_{\theta}(\mathtt{z})}{q_{\phi}(\mathtt{z}|\mathtt{x}^{(i)})}\right) \\ &=\sum_{\mathbf{z}} q_{\phi}(\mathtt{z}|\mathtt{x}^{(i)})\left[\log \left(p_{\theta }(\mathtt{x}^{(i)}|\mathtt{z})\right)+\log \left(\frac{p_{\theta}(\mathbf{z})}{q_{\phi}(\mathtt{z}|\mathtt{x}^{(i)})}\right)\right] \\ &\color{red}= -D_{KL}(q_{\phi}(\mathtt{z}|\mathtt{x}^{(i)})||p_{\theta}(\mathtt{z}))+ \mathbb{E}_{q_{\phi}(\mathtt{z}|\mathtt{x}^{(i)})}[\log p_{\theta }(\mathtt{x}^{(i)}|\mathtt{z})]\end{aligned}\tag{3.1} L(θ,ϕ;x(i))=z∑qϕ(z∣x(i))log(qϕ(z∣x(i))pθ(x,z))=z∑qϕ(z∣x(i))log(qϕ(z∣x(i))pθ(x(i)∣z)pθ(z))=z∑qϕ(z∣x(i))[log(pθ(x(i)∣z))+log(qϕ(z∣x(i))pθ(z))]=−DKL(qϕ(z∣x(i))∣∣pθ(z))+Eqϕ(z∣x(i))[logpθ(x(i)∣z)](3.1)
先 验 分 布 p θ ∗ ( z ) 生 成 一 个 z ( i ) \color{red}先验分布p_{\theta^*}(\mathtt{z})生成一个\mathtt{z}^{(i)} 先验分布pθ∗(z)生成一个z(i);
条 件 分 布 p θ ∗ ( x ∣ z ) 生 成 一 个 x ( i ) \color{red}条件分布p_{\theta^*}(\mathtt{x|z})生成一个\mathtt{x}^{(i)} 条件分布pθ∗(x∣z)生成一个x(i)。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









