







背景
随着大型语言模型参数量的不断增加,针对其进行预训练的难度越来越大,全量微调的方式也越来越不可行,如何将大模型部署在消费级显卡上进行训练成为一个热门的研究方向。
LoRA论文中假设大模型在训练过程中权重的变化具有较低的“内在秩”,允许我们通过优化适应期间密集层变化的秩分解矩阵来 间接训练神经网络中的一些密集层,同时保持预训练权重冻结。简单的说,LoRA冻结了预训练的模型权重,并将可训练的秩分解矩阵注入到Transformer 架构的每一层,极大地减少了下游任务的可训练参数的数量。
且不会像adapter一样,在网络中插入几层,训练这几层就可以,但是这样会加大网络的深度,加大模型的推理时间。
核心点
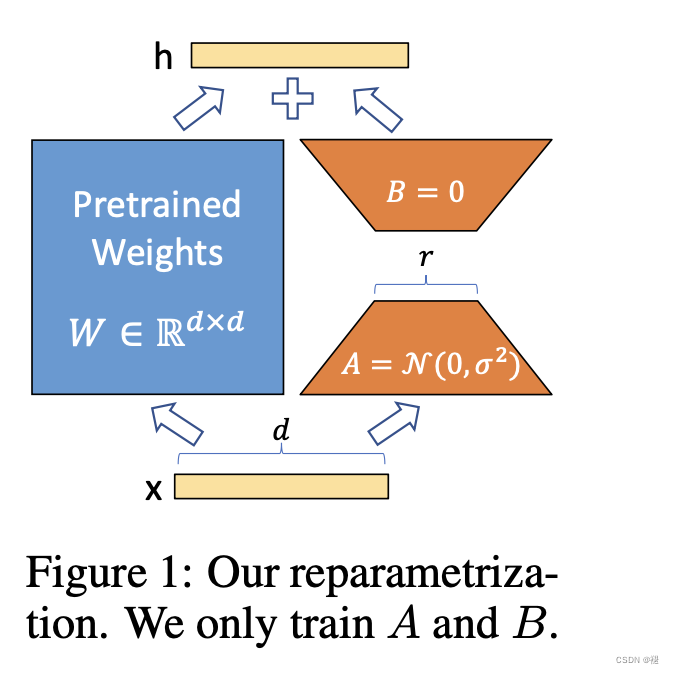
之前模型:
即现在的权重为
,
,
,其中
所以训练的参数量会大大降低。将
中一些特征进行了放大,在下游任务微调时,就会放大下游任务中相关的特征,这也是为什么用低秩微调有时候比全量微调效果还好(去掉了一些无用的噪声)
A、B一般一个初始化为0,一个采用kaiming_uniform(随机
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 510
510

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









