







 PCA算法在数据压缩中如何选择合适的主成分数量K?本文介绍了基于平均均方误差、数据总变差和经验法则的方法,以及如何通过SVD矩阵高效计算,以保留99%以上的差异性。
PCA算法在数据压缩中如何选择合适的主成分数量K?本文介绍了基于平均均方误差、数据总变差和经验法则的方法,以及如何通过SVD矩阵高效计算,以保留99%以上的差异性。
本文重点
上节课程中我们已经学习了pca算法,已经知道了如何将n维特征变量降到k维,k是PCA算法的一个参数,也被称为主成分的数量。那么现在就产生了一个问题,这个问题就是如何选择K,因为PCA要做的就是要尽量减少投射的平均均方误差,所以K的选择很关键。
平均均方误差
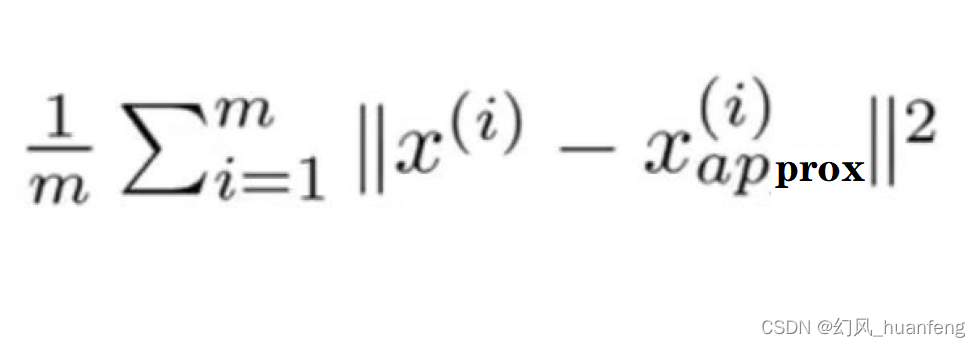
其中x(i)表示原始样本的特征向量,Xapprox(i)表示映射的样本
数据的总变差
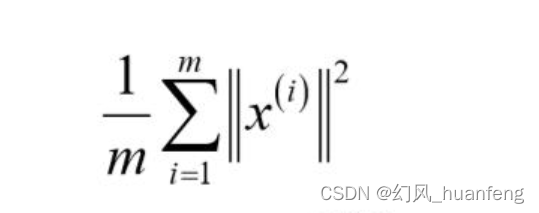
数据的总变差就是数据集中每个训练样本长度的平均值,它表示平均来看我们训练集样本距离0向量有多远。
k值的经验得法则
k值的经验得法则就是,选择能够使得它们之间得比例小于0.01的最小的K值。

这个0.01用PCA语言就是说我们选择的参数K,原本数据

 订阅专栏 解锁全文
订阅专栏 解锁全文


















 2063
2063

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











