




 本文深入探讨PromQL的运算符,包括算术、关系、向量匹配和逻辑运算符,详细解析运算规则及应用场景,帮助读者掌握Prometheus监控数据处理技巧。
本文深入探讨PromQL的运算符,包括算术、关系、向量匹配和逻辑运算符,详细解析运算规则及应用场景,帮助读者掌握Prometheus监控数据处理技巧。
目录
4.2 many-to-one (多对一)and one-to-many(一对多)
上篇讲了 PromQL的聚合,本篇继续,讲PromSQL运算符。
一、PromQL运算符 说明
当用户需要使用不同的监控指标进行更多操作时,PromQL聚合操作会出现无法满足使用的情况。这时Prometheus提供了多种运算符。这些运算符不仅允许对即时向量进行简单的算术运算,还可以将运算符应用于两个基于标签分组的即时向量。下面我们对Prometheus查询语言提供的算术运算符、关系运算符、向量匹配模式和逻辑运算符进行介绍。
二、算术运算符
Prometheus提供的所有算术运算的工作原理都是类似的,有编程基础的读者可以看到其语义与其他编程语言的语义也相同。Prometheus的6种算术运算符如下:
| 运行符 | 描述 |
|---|---|
| + | 加 |
| - | 减 |
| * | 乘 |
| / | 除 |
| % | 求余 |
| ^ | 幂运算 |
运算操作符支持三类操作:scalar/scalar(标量/标量)之间的操作;vector/scalar(即时向量/标量)之间的操作;vector/vector(即时向量/即时向量)之间的操作。
下面我们分别对表达式进行调试,通过Prometheus Web UI上直观的输出信息观察三类操作。
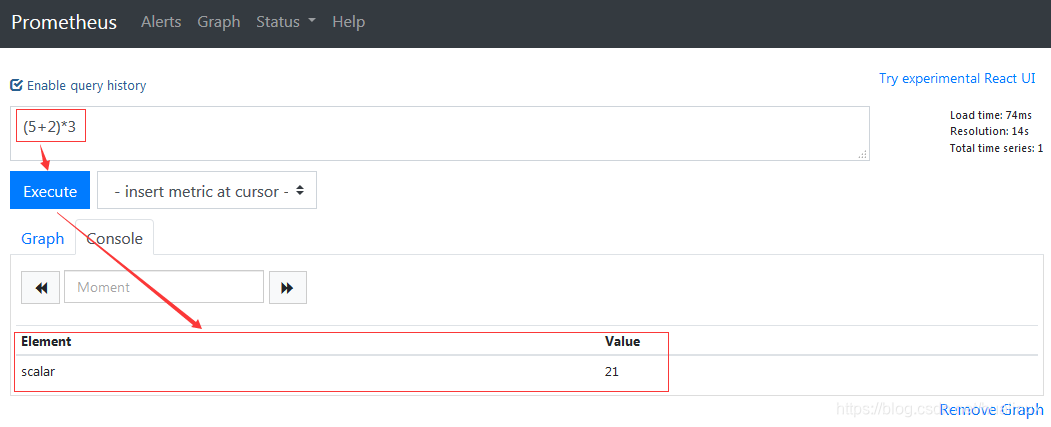
2.1 两个标量之间
在两个标量之间进行算术运算,得到的结果还是标量
2.2 时向量与标量之间
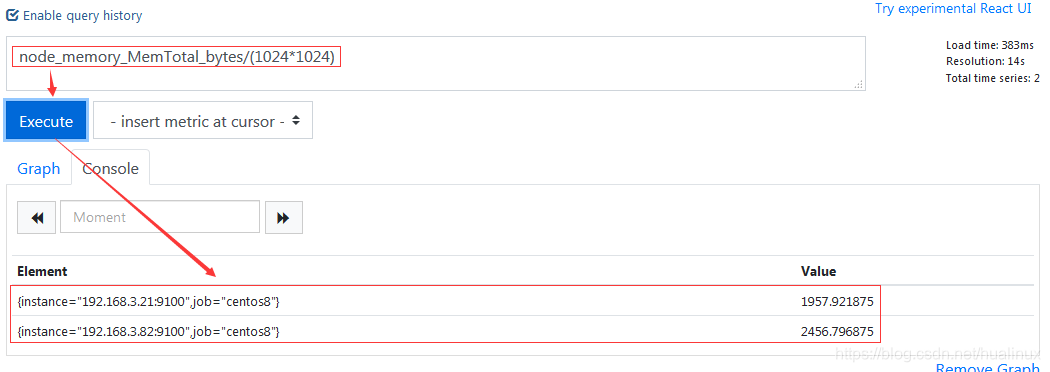
当即时向量与标量之间进行算术运算时,算术运算符会依次作用于即时向量中的每一个样本值,从而得到一组新的时间序列。
例如,我们可以通过监控指标node_memory_MemTotal_bytes获取主机内存总空间的大小,其样本单位为byte。现在把样本单位换算为MB时,表达式为node_memory_MemTotal_bytes/(1024*1024),如下图:
2.3 即时向量与即时向量之间
即时向量与即时向量进行算术运算的过程相对复杂一些。
例如,node_disk_read_bytes_total和node_disk_written_bytes_total获取磁盘读写时间总量,使用表达式:
node_disk_read_bytes_total+node_disk_written_bytes_total,如下图所示:
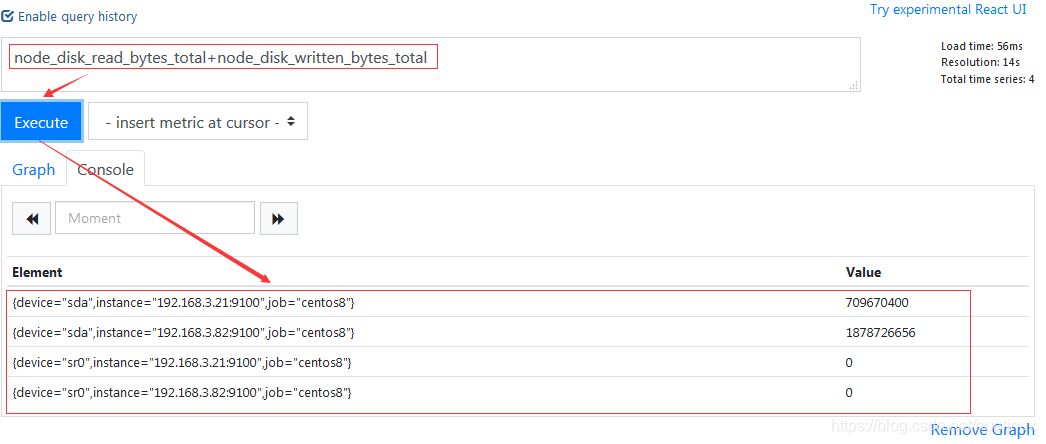
该表达式工作过程是依次找到与左边向量元素匹配(标签完全一致)的右边向量元素进行运算,如果没找到匹配元素,则直接丢弃,同时,新的时间序列将不会包含指标名称。
三、关系运算符
Prometheus同样提供了关系运算符,也称为比较运算符,其语义很容易理解。Prometheus的6种关系运算符如下所示:
关系运算符同样被应用于scalar/scalar(标量/标量)、vector/scalar(即时向量/标量),和vector/vector(即时向量/即时向量)之间。默认情况下,运算符用于对时序数据进行过滤。但是在有些情况下,可以通过在运算符之后使用bool修饰符,从而不对时间序列进行过滤,直接返回0(false)或者1(true)。下面我们使用Prometheus Web UI分别对表达式进行调试后,通过直观的输出信息观察三类操作。
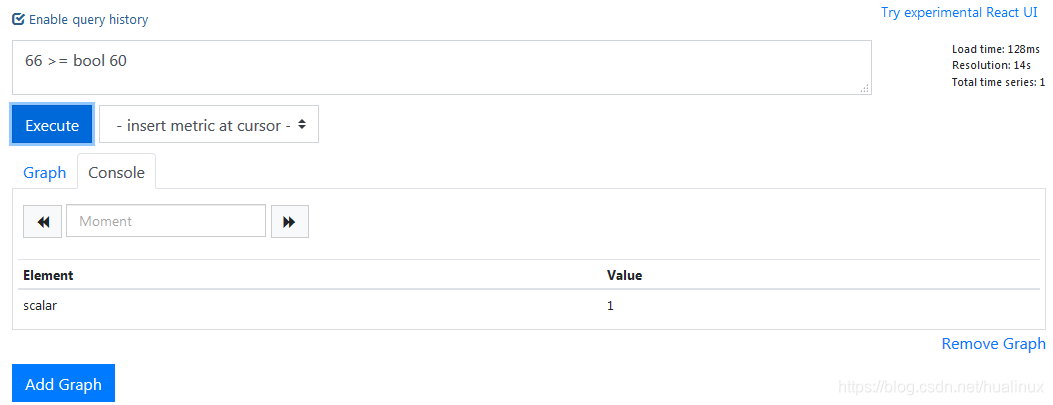
3.1 两个标量之间
在两个标量之间进行关系运算,必须使用bool修饰符,并且这些运算符会产生另一个标量,即0(false)或者1(true),如图
3.2 即时向量与标量之间
当即时向量与标量之间进行关系运算时,这个运算符会应用到某个当前时刻的每个时间序列数据上,如果一个时间序列数据值与这个标量的比较结果是false,则这个时间序列数据被丢弃,如果是true,则这个时间序列数据被保留在结果中。
例如,通过监控指标node_netstat_Tcp_CurrEstab获取主机网络状态为ESTABLISHED,数量大于30的表达式为:node_netstat_Tcp_CurrEstab≥30
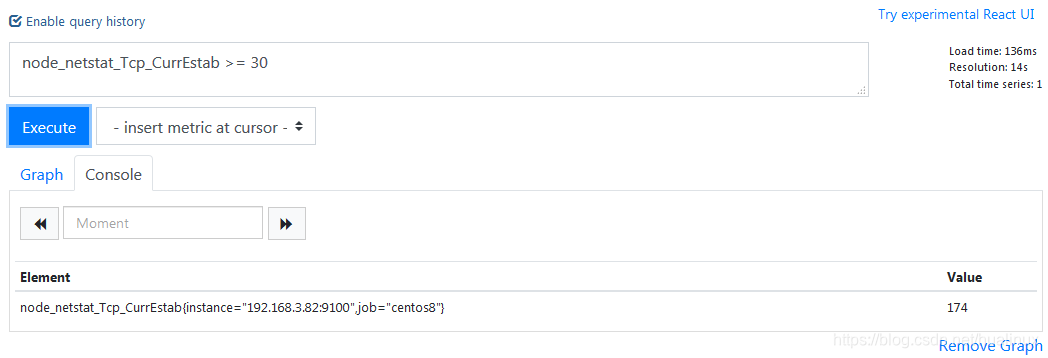 还有我们经常使用的被监控主机告警表达式,例如,up{job="node_exporter"}==0。
还有我们经常使用的被监控主机告警表达式,例如,up{job="node_exporter"}==0。
3.3 即时向量与即时向量之间
在即时向量与即时向量之间进行关系运算时,运算符默认情况下是过滤的,用于匹配条目。表达式不是true或在表达式的另一侧找不到匹配项的向量元素将被从结果中删除,不在结果中显示;否则将保留左侧的度量指标和标签的样本数据写入即时向量。如果提供了bool修饰符,则删除的向量元素的值为0,而保留的向量元素的值为1,左侧标签值为1。
四、向量匹配Vector matching
在标量和即时向量之间使用运算符可以满足很多需求,但是在两个即时向量之间使用运算符时,哪些样本应该适用于哪些其他样本?这种即时向量的匹配称为向量匹配。Prometheus提供了两种基本的向量匹配模式:
one-to-one向量匹配和many-to-one(one-to-many)向量匹配
4.1 one-to-one(一对一)
即一对一向量匹配模式,它从运算符的两侧表达式中获取即时向量,依次比较并找到一对唯一条目进行匹配,如果两个条目具有完全相同的标签和对应的值,则它们匹配。一般默认表达式格式为vector1<运算符>vector2
如:
process_open_fds{instance="192.168.3.21:9100",job="centos8"}
/
process_max_fds{instance="192.168.3.21:9100",job="centos8"}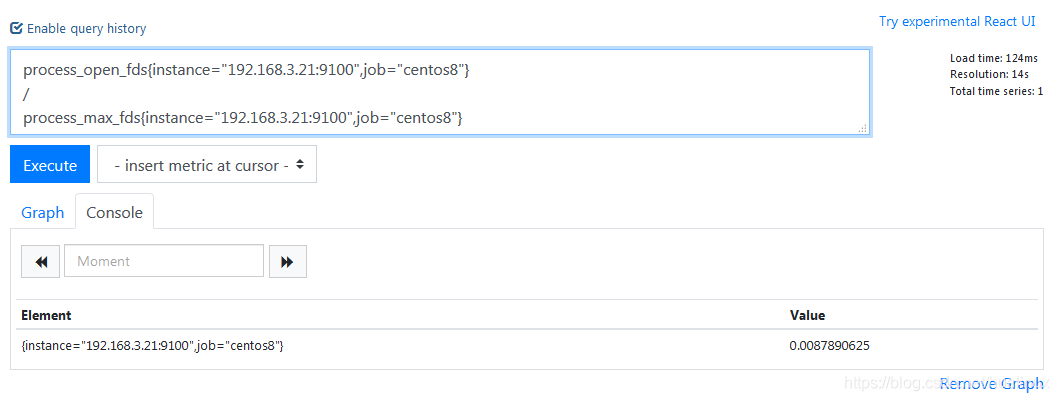
从上图看到,除了标签_name__中的指标名称之外,具有完全相同标签的样本被匹配在一起。也就是说,该示例中都有标签{instance="192.168.3.21:9100",job="centos8"}的将匹配在一起。
如果运算符两侧表达式标签不一致,可以使用关键字on或ignoring修改标签间的匹配行为。其中,on用于在指定标签上进行匹配,ignoring可以忽略指定标签进行匹配。表达格式分别为:
<vector expr> <bin-op> ignoring(<label list>) <vector expr>
<vector expr> <bin-op> on(<label list>) <vector expr>这里我们列举一个表达式:
#表达式中使用到了rate()函数,即计算某个时间序列范围内的平均增长率
sum by(instance, job)(rate(node_cpu_seconds_total{mode="idle"}[5m]))
/ on(instance, job)
sum by(instance, job)(rate(node_cpu_seconds_total[5m]))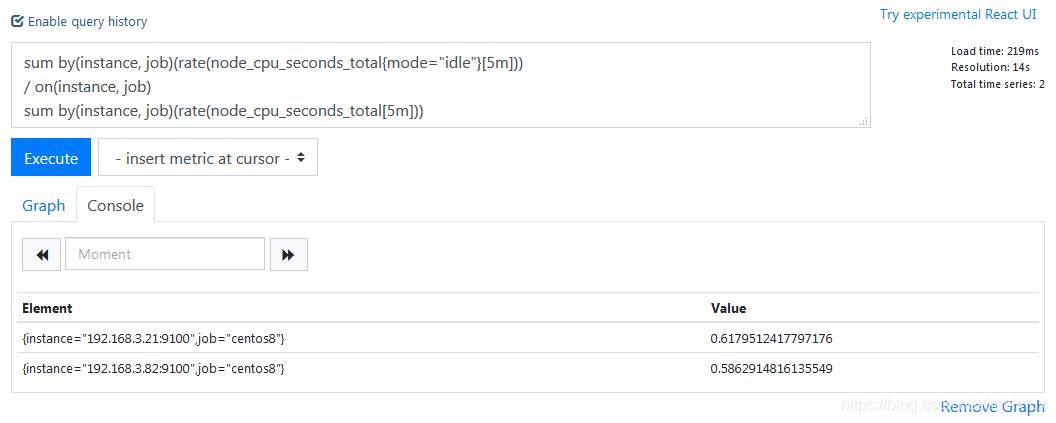
算术运算符返回的值是计算的结果,若使用两个即时向量进行比较运算符时,结果是返回左侧表达式的值。感兴趣的读者可以测试一下,
例如,表达式process_max_fds>process_open_fds和表达式process_open_fds<process_max_fds均是返回左侧表达式的值。
4.2 many-to-one (多对一)and one-to-many(一对多)
多对一和一对多的匹配模式,可以理解为向量元素中的一个样本数据匹配到了多个样本数据标签。在使用该匹配模式时,需要使用group_left或group_right修饰符明确指定哪一个向量具有更高的基数,也就是说左或者右决定了哪边的向量具有较高的子集。此表达格式为:
<vector expr> <bin-op> ignoring(<label list>) group_left(<label list>) <vector expr>
<vector expr> <bin-op> ignoring(<label list>) group_right(<label list>) <vector expr>
<vector expr> <bin-op> on(<label list>) group_left(<label list>) <vector expr>
<vector expr> <bin-op> on(<label list>) group_right(<label list>) <vector expr>这里我们使用group_left指定左侧操作数组中可以有多个匹配样本。表达式示例如下:
sum without(cpu)(rate(node_cpu_seconds_total[5m]))
/ ignoring(mode) group_left
sum without(mode, cpu)(rate(node_cpu_seconds_total[5m]))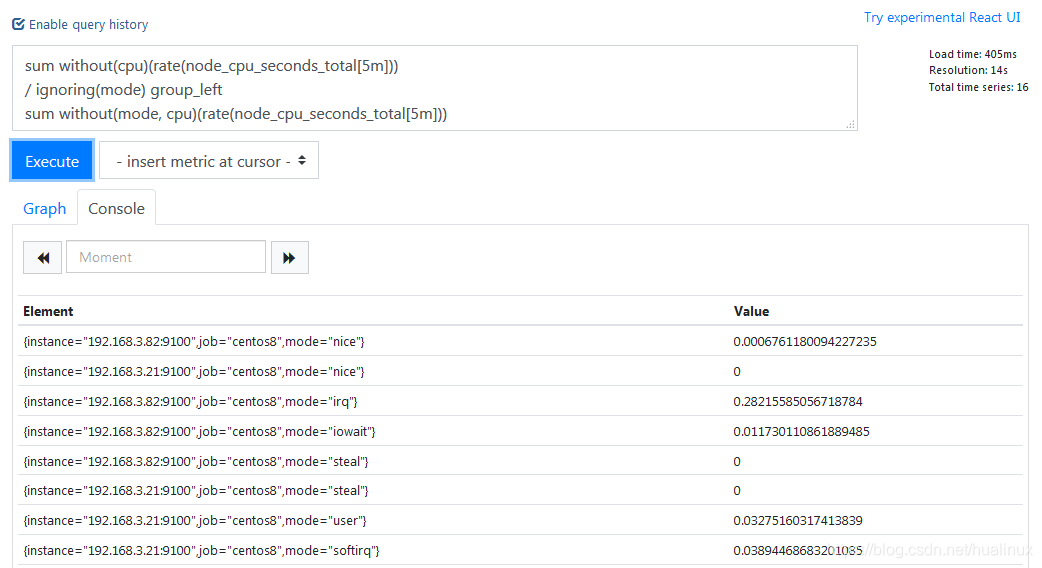
从以上输出信息可以看到,为左侧每组中的每个不同模式标签生成了一个输出样本。我们可以使用这种方法来确定指标中每个标签值代表的比例。
Prometheus官方文档operators中也提供了示例。
通常情况下不需要这些操作,在大多数情况下,一对一的匹配可以基本满足大家的需求。
五、逻辑运算符
Prometheus提供了三种逻辑运算符:and、or和unless。逻辑运算符仅用于向量与向量之间。所有逻辑运算符都以多对多的方式工作,它们是唯一能工作于多对多方式的运算符。不同于算术运算符和比较运算符,因为没有执行任何数学计算,所以重点是描述一个组是否包含样本。下面我们根据官方提供的内容分别对三种逻辑运算进行介绍。
5.1 vector1 and vector2
and逻辑运算会产生一个由vector1的元素组成的新的向量。该向量包含vector1中完全匹配vector2中的元素。表达式示例如下:
node_cpu_seconds_total{job="centos8"}
and
node_cpu_seconds_total{mode="idle"}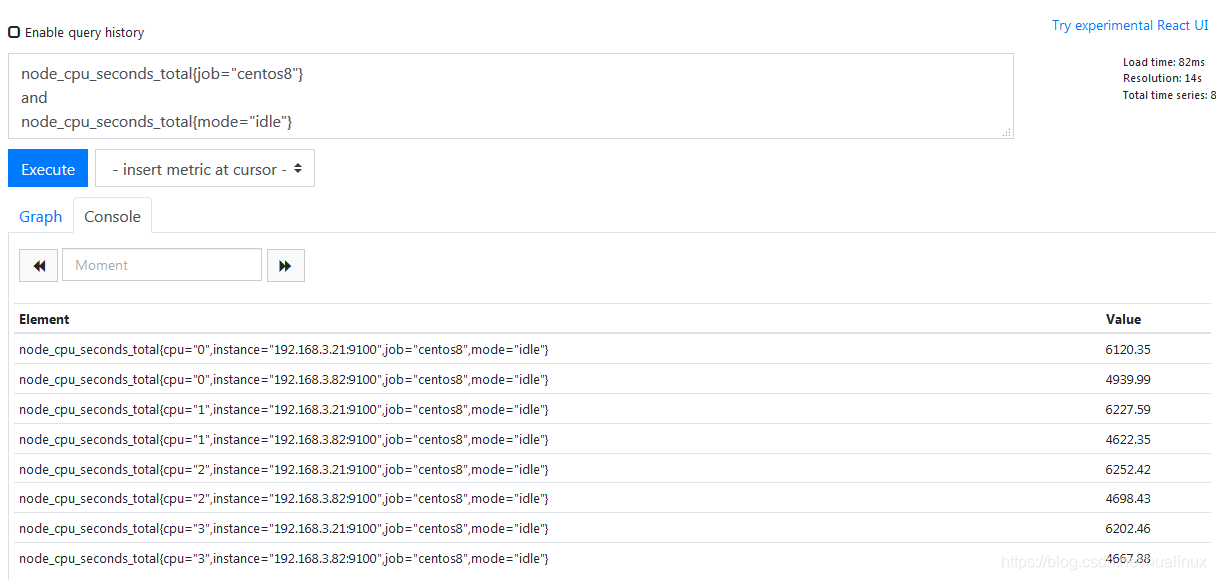
5.2 vector1 or vector2
or逻辑运算会产生一个新的向量,该向量包含vector1的所有原始元素(标签集+值)的向量,以及vector2中没有与vector1匹配标签集的所有元素。假设判断node_test_metric指标是否存在,如果指标不存在则返回0。在这种情况下,我们可以使用与每个目标关联的up指标进行表达式操作:
node_test_metric
or
(up{job="centos8"} == 1) * 0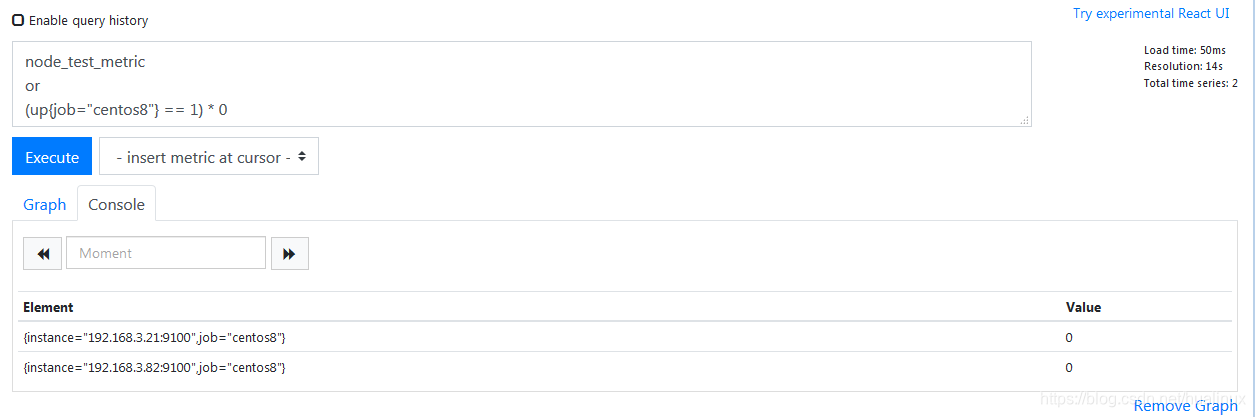
5.3 vector1 unless vector2
unless逻辑运算会产生一个由vector1的元素组成的向量,而这些元素在vector2中没有与标签集完全匹配的元素,两个向量中的所有匹配元素都被删除。表达式示例如下:
node_cpu_seconds_total{job="centos8"}
and
node_cpu_seconds_total{mode="idle"}
#把master节点去掉
unless
node_cpu_seconds_total{instance="192.168.3.82:9100"}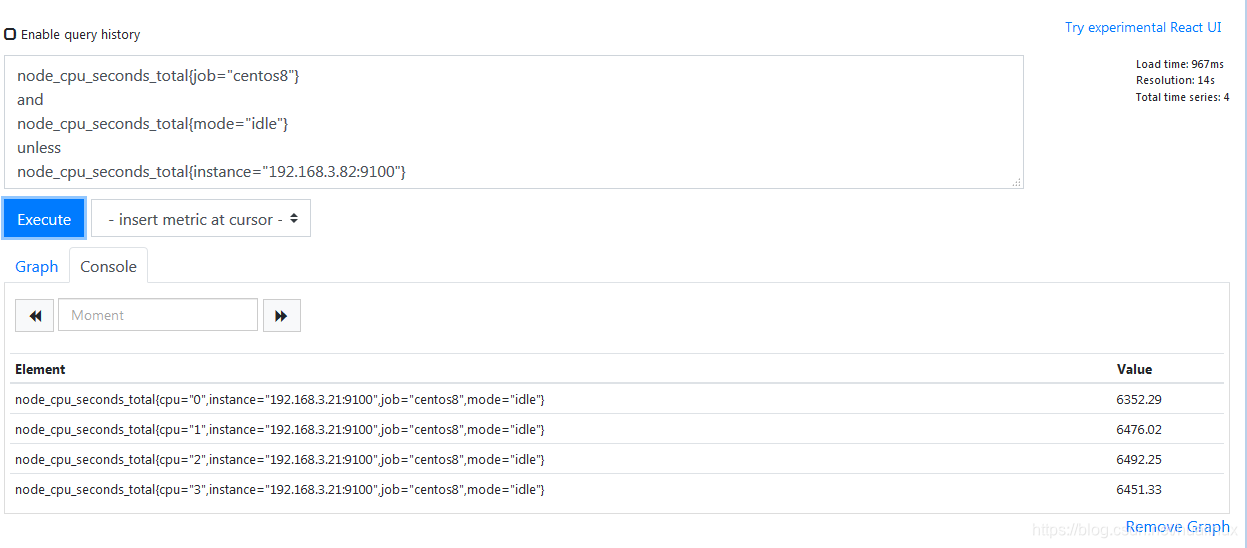
六、运算符优先级
| 编号 | 运算符 |
|---|---|
| 1 | ^ |
| 2 | *,/,% |
| 3 | +,- |
| 4 | ==,!=,<=,<,>=,> |
| 5 | and,unless |
| 6 | or |

















 821
821

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









