 使用requests库进行网页爬取
使用requests库进行网页爬取





 该博客介绍了requests库在Python中的应用,用于爬取网页信息。通过设置请求头和超时时间,能够实现对指定URL的HTTP请求,并获取HTML文本内容。示例中展示了如何处理可能出现的异常情况。
该博客介绍了requests库在Python中的应用,用于爬取网页信息。通过设置请求头和超时时间,能够实现对指定URL的HTTP请求,并获取HTML文本内容。示例中展示了如何处理可能出现的异常情况。
爬虫的基础库requests库
requests库
功能强大的爬取网页信息的第三方库,可以进行自动爬取HTML页面及自动网络请求提交的操作。
requests库的主要方法:
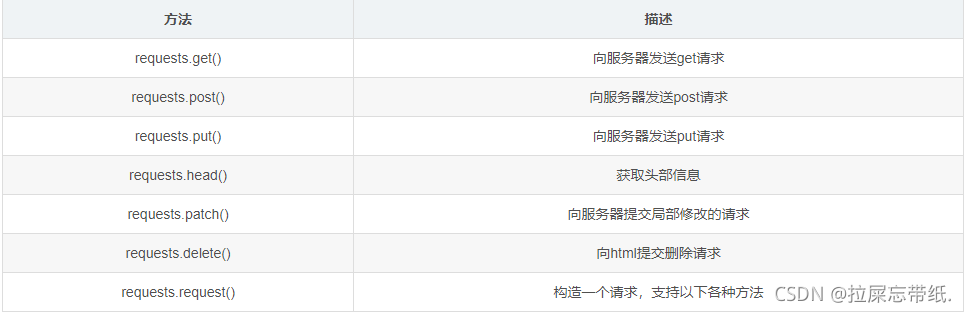
requests对象:
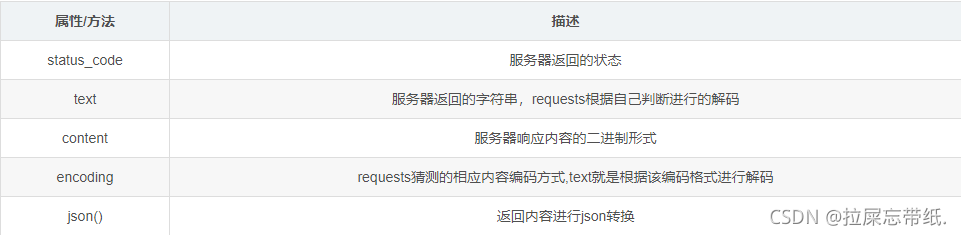
爬取实例:

#导入Requests
import requests
#爬取url
url =https://www.douban.com/
#定义获取Text内容
def getHTMLText(url:
try:
#设置请求头(豆瓣设有反爬机制)
headers ={
User-Agent: 'Moilla/5.0 (X11; Linux x86 64) AppleWebKt/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36'
}
response = requests.get(url, headers=headers, timeout=200); #设置超时
response.raise for status0
response.encoding = utf-8'
return response.text
except
return 产生异常”
#name是当前模块名,当模块被直接运行时模块名为_main_
#这句话的意思就是,当模块被直接运行时,以下代码块将被运行,当模块
#是被导入时,代码块不被运行
#相当于入口
ifname == main_:
print(getHTMLText(urll)

















 3175
3175

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









