




 本文介绍了基于语义检索的召回模型LSTM-DSSM,作为对传统BM25算法的补充。DSSM模型通过深度网络将query和doc映射到语义空间,LSTM-DSSM则引入LSTM解决文本顺序和上下文信息丢失问题,提升召回效果。此外,还探讨了Bert预训练模型在生成词向量中的作用,以及如何结合品牌和类目信息优化模型。
本文介绍了基于语义检索的召回模型LSTM-DSSM,作为对传统BM25算法的补充。DSSM模型通过深度网络将query和doc映射到语义空间,LSTM-DSSM则引入LSTM解决文本顺序和上下文信息丢失问题,提升召回效果。此外,还探讨了Bert预训练模型在生成词向量中的作用,以及如何结合品牌和类目信息优化模型。
众所周知,BM25算法是Elasticsearch全文检索引擎默认相似度算法,但此种算法仅考虑了文本Term之间的匹配关系,并未考虑文本语义之间的信息,所以导致很多场景下,语义相关的内容无法召回。随着深度学习在NLP的广泛应用,在IR和QA(问答系统)中出现了很多深度模型将query和doc通过神经网络embedding,映射到一个稠密空间的向量表示,然后再计算其是否相关,并取得很好的效果,而本文就来介绍一种基于语义检索的召回模型LSTM-DSSM。
【DSSM】
DSSM是Deep Structured Semantic Model的缩写,基于深度网络的语义模型,由微软研究院在2013年发表,其其核心思想是基于搜索引擎的曝光点击行为数据,利用多层DNN网络把query及文档Doc Embeding成同一纬度的语义空间中,通过最大化约束query和doc两个语义向量的余弦举例,从而训练学习得到隐层相似度语义模型,从而实现了检索召回。
下图是DSSM模型的网络结构图
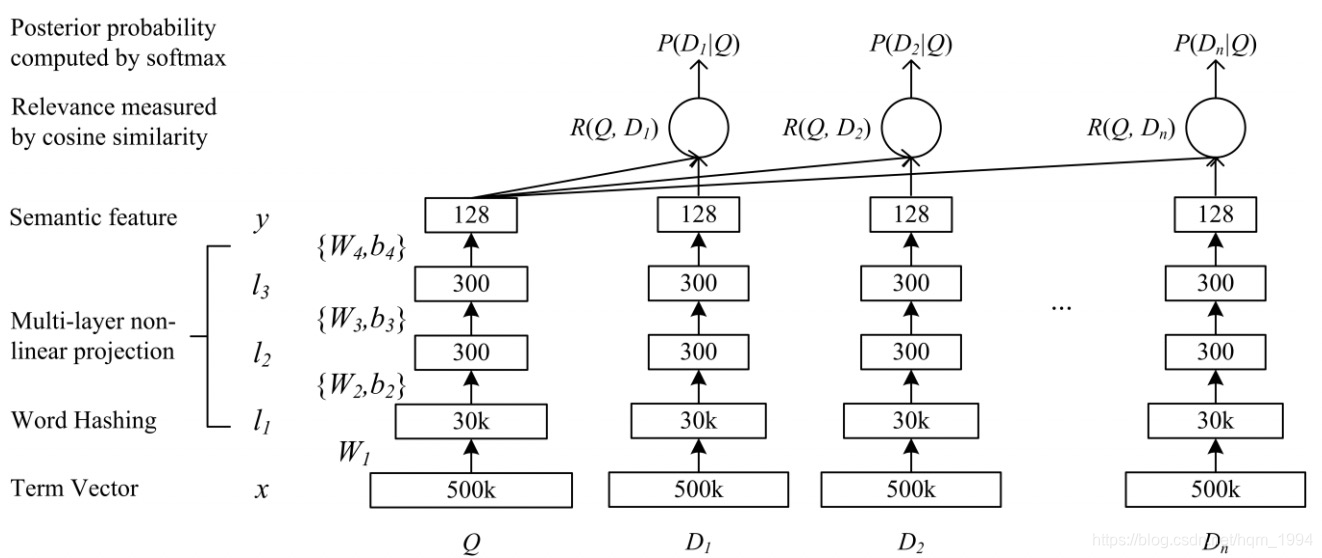
DSSM 从下往上可以分为三层结构:输入层、表示层、匹配层。
输入层:将所有query以及候选集doc映射到统一空间并作为输入,放进DNN中进行训练,但在DSSM中,中英文的处理方式有所不同。英文一般直接使用word hashing,3个字母为一组,#表示开始和结束符。为啥使用3个字母?3个字母的表达往往能代表英文中的前缀和后缀,并且实验证明,3个字母的单词冲突仅为22个,比2个字母的单词冲突数减小近100倍。而中文依赖于分词,中文分词本身就比较难,中文语义性太强,同样的词语在不同的句子中表达的意思完全不同,中文词语有近百万个,在网络中维度太高不利于训练,所以DSSM中文输入层
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3210
3210

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









