 NVIDIA DOCA产品测试体验
NVIDIA DOCA产品测试体验





平台设备
优快云和丽台科技为我们提供了一台测试服务器,安装了一块双端口的Bulefiled 3 DPU
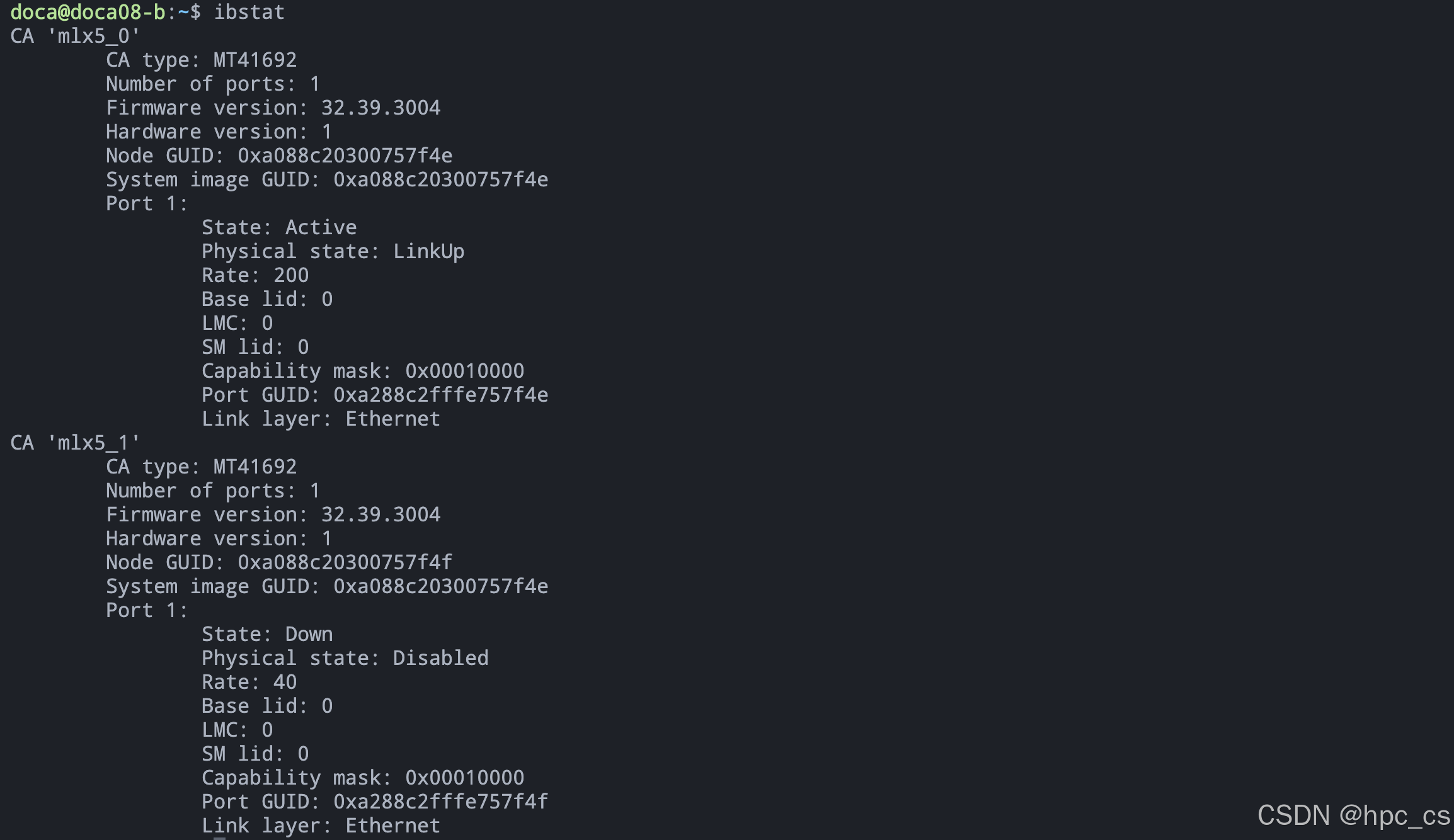
ibstat
mst status -v

mlxconfig -d /dev/mst/mt41692_pciconf0 -e q
设备具体型号是 NVIDIA BlueField-3 B3220 P-Series FHHL DPU,双端口 QSFP112 接口,支持 200GbE(默认模式)或 NDR200 IB。具有16个 Arm 核心处理器和32GB 板载 DDR 内存,PCIe接口为 Gen5.0 x16。

MPI all_to_all 测试
# 使用mpich的MPI实现
# dpkg –l | grep mpich
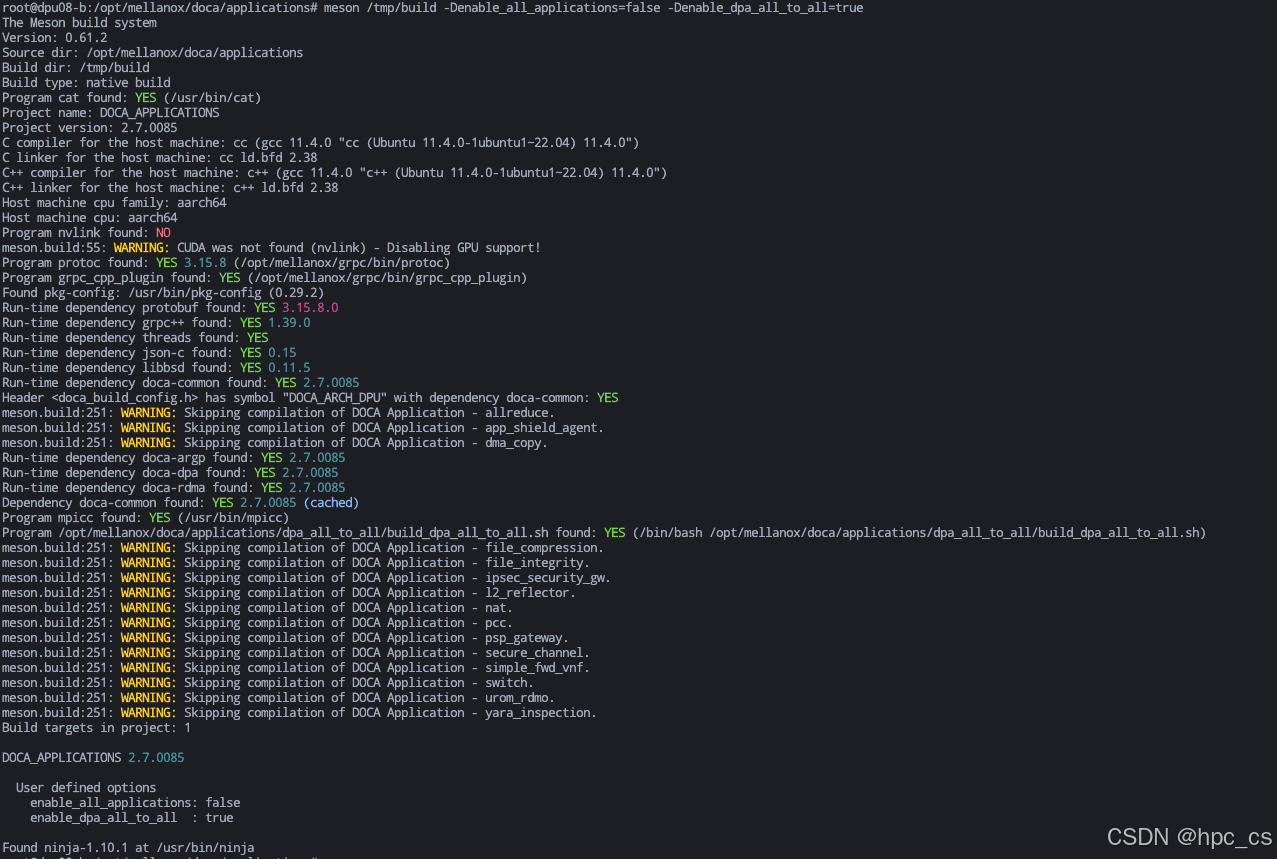
cd /opt/mellanox/doca/applications
meson /tmp/build -Denable_all_applications=false -Denable_dpa_all_to_all=true
ninja -C /tmp/build
运行测试
mpirun -np 4 /tmp/build/dpa_all_to_all/doca_dpa_all_to_all -m 32 -d "mlx5_0"

可以看到上面的结果,每个rank收发数据都正常
PyTorch训练测试
思路
需要在DPU上利用DOCA编写程序后,在HOST上集成使用
- 纯宿主机
- 使用DPU网络卸载(利用DPU加速数据传输和预处理)
# 1. 宿主机环境准备
pip install torch torchvision tensorboard psutil
# 2. DPU环境准备
ssh root@dpu
apt-get update
apt-get install python3-pip
pip3 install torch torchvision tensorboard
纯宿主机
我们直接在宿主机上进行测试
1. 环境准备
首先安装需要的软件包
sudo apt-get install python3-pip
pip install torch torchvision tensorboard psutil
2. 测试代码
编写测试代码main.py
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision
import torchvision.transforms as transforms
import time
import psutil
import os
from torch.utils.tensorboard import SummaryWriter
class SimpleCNN(nn.Module):
def __init__(self):
super(SimpleCNN, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 16 * 5 * 5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
def get_system_usage():
cpu_usage = psutil.cpu_percent()
memory = psutil.virtual_memory()
return cpu_usage, memory.percent
def train():
# 设置设备
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"Using device: {
device}")
# 设置TensorBoard
writer = SummaryWriter('runs/cifar_experiment')
# 数据预处理
transform_train = transforms.Compose([
transforms.RandomCrop(32, padding 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 766
766

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









