




PG到目前为止使用的事务ID仍然是32位的,在内存计算时虽然已经使用64位事务ID,但是存储在页中tuple仍然使用32位事务ID,这就是说,事务ID回卷仍然是必须处理的问题。
所谓PG事务ID回卷,简单地说,就是在数据库频繁运行中,事务ID不断增加,32位的事务ID不够用了,怎么办?PG的处理方法,简单的说,就是在事务ID还没用完以前,把数据库中所有的tuple处理一遍,将以前的事务(不活跃的事务)修改的(包括插入)tuple中的事务ID改为2(或设置infomask),表示这个tuple对于以后的事务(不管是多少的事务ID)都是可见的,即freeze。
这样,当前事务达到2^32后,再从3开始(0、1、2保留做特殊事务ID),就不会有什么问题了,即就不会导致很旧的事务修改过的tuple不可见了。
这里有个隐含背景知识,就是PG内部读写tuple时,tuple中的事务ID,在当前事务ID之前 ,这个tuple对于当前事务才是可见的。
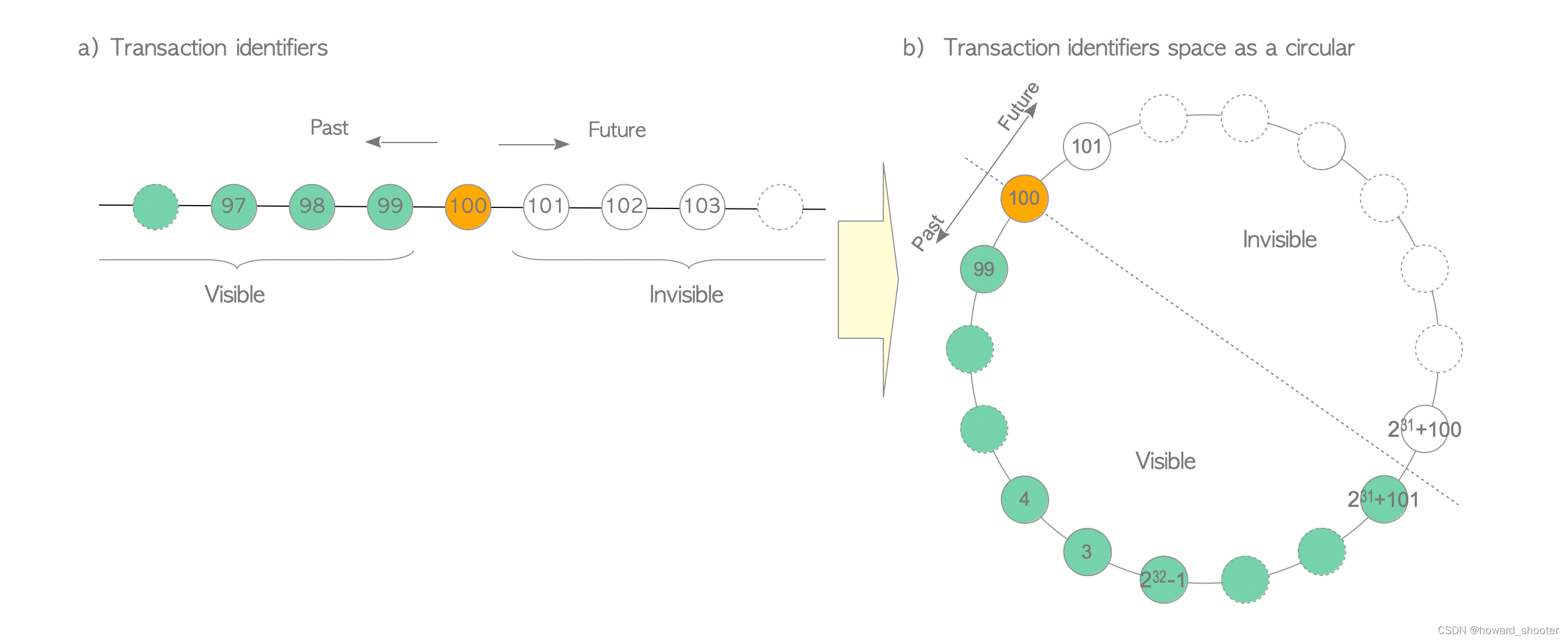
网上有一张图片,来说明“之前”、“之后”和回卷的概念,但是我觉得都没说明白,我来尝试理解一下,我觉得问题的关键是PG源码中比较事务ID的函数:
TransactionIdPrecedes() 和 TransactionIdFollows()


按照上面代码的算法,对于任何事物ID,例如100,如果另一个事务ID比它大,但是没有超过这个事务ID后的半圆,例如2^31+100,就认为是在它的后面,那么事务100的tuple,对事务2^31+100就是可见的。
按照上面代码的算法,对于任何事物ID,例如100,如果另一个事务ID比它大,还超过了事务ID后的半圆,例如2^31+101,就认为是在它前面,那么事务100的数据,对事务2^31+101就是不可见的。
这导致对任何事务ID,它只能看到它之前的 2^31 个事务的数据,而不是 2^32 个事务的数据,而且不同事务的可见事务集合也是不同的。
这种算法叫做 “模算数” (modulo-2^32 arithmetic)

这个和freeze有什么关系呢?
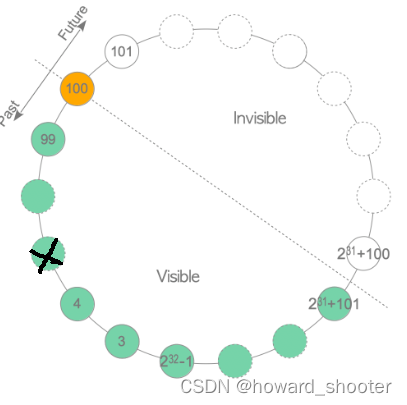
想象事务ID一直在增加,穿过圆心的线顺时针转动,每转动一个事务ID,就有一个事务ID变的不可见,要想不丢失这个事务ID的数据,就要对它的tuples做freeze,这一岂不是freeze太频繁了吗?
实际上,PG对于past部分的tuple,早就做了freeze了,例如下图,一般X之前的tuple已经freeze过了,而当前事务ID不断增加,每隔一段时间做一次freeze,将与当前事务ID有一定差值(5千万)的past tuple,做freeze。
并不是在穿过圆心的直线另一端,快到达某个事物ID时(未做freeze的tuple事务ID与当前事务ID差值已经非常大了),才对这个事物ID做freeze。
总结一下vacuum,最近看pgvector索引代码时,对vacuum有了新的理解,pgvector有个接口:hnswbulkdelete,是删除了表的一些记录后,做vacuum时,删除索引中对应条目用的。
PG删除记录时,不是真的删除,而是在tuple上标记删除,此时也不会删除对应的索引项,真的删除是vacuum时做的。
vacuum是以表为单位进行的,就是说最小可以只对一个表进行vacuum,它主要有两个工作:
1、删除 dead tuple
2、将记录设置frozen xid
这两个工作都有,lazy和eager两种模式,它们的触发条件不同,对系统的影响也不同。
1、lazy模式,删除dead tuple,跳过没有dead tuple的page(参考vm),对于有dead tuple的page,物理删除dead tuple和对应索引项,页内碎片整理。
2、eager模式,删除dead tuple,不会参考vm,直接重建一份表数据,从旧的表数据的page中逐个tuple拷贝,重建索引,表内碎片整理。它的触发条件就是用FULL VACUUM命令。
3、lazy模式,freeze,跳过没有dead tuple和所有tuple都已经freeze的page(参考vm),对其他page中的tuple设置frozen txid,但是又不是每个tuple都设置,只有xmin小于特定值的tuple才设置。
4、eager模式,freeze,跳过所有tuple都已经freeze的page(参考vm),对其他page中的tuple设置frozen txid,但是又不是每个tuple都设置,只有xmin小于特定值的tuple才设置。这里面还有个特殊情况,就是vacuum时有FREEZE选项,则用eager模式,但是并不是只有xmin小于特定值的tuple才设置frozen,而是所有小于当前事务ID的tuple都设置frozen。
触发条件:粗糙的说,当前事务ID与数据库中最小的(未freeze的)事务ID,的差达到一定值后,就会触发。这个“当前事务ID”是指OldestXmin ,“数据库中最小的事务ID”是指pg_database.datfrozenxid,差值是Vacuum_freeze_table_age。
5、autovacuum触发条件,既可以是事务ID的改变,也可以是dead tuple的比例的改变,也可以是新插入的tuple的比例达到一定阈值。
参考:
6.3. Freeze Processing :: Hironobu SUZUKI @ InterDB
postgresql - About "Transaction ID Wraparound" - Database Administrators Stack Exchange

















 2396
2396

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









