




 本文介绍了在不同CentOS版本上编译Doris遇到的问题及解决方案,包括使用clang和gcc的编译调试,静态库和动态库的链接问题,以及CMake的使用。作者强调clang编译的程序可用gdb调试,而解决glibc版本不兼容的关键在于第三方库的匹配。此外,文章还涉及了ABI、调试信息和Maven在构建过程中的应用。
本文介绍了在不同CentOS版本上编译Doris遇到的问题及解决方案,包括使用clang和gcc的编译调试,静态库和动态库的链接问题,以及CMake的使用。作者强调clang编译的程序可用gdb调试,而解决glibc版本不兼容的关键在于第三方库的匹配。此外,文章还涉及了ABI、调试信息和Maven在构建过程中的应用。
目录
概述
尝试编译 doris,其过程异常坎坷,不过也学到了很多东西。
首先,按照doris官网上的编译指导,下载ldb_toolchain_gen.sh,安装编译工具链,doris默认是用clang编译的,但是我尝试debug的时候,出现core dump,也许是因为我的Linux版本太旧了,我一开始用的是CentOS7,内核版本是3.10,glibc库也是libc-2.17.so,而且执行ldb_toolchain_gen所带的gdb时也会报错:
gdb: error while loading shared libraries: libsource-highlight.so.4: cannot open shared object file: No such file or directory
其实clang编译的c/c++可执行文件,也可以用gdb调试的,不过要保证它们的兼容性。不过我一开始不懂,以为clang编译的程序必须用lldb,而gdb只能调试gcc编译的程序,但是当尝试用lldb调试clang编译的程序时,出现core dump。
于是又尝试用gcc编译(修改env.sh),但是最后又遇到glibc太旧的问题。可能是预编译的第三方库调用了新版本的glibc。
关于第三方库,一开始是下载源码编译的,但是我嫌这个过程太长,就按照官网直接下载预编译的第三方库二进制文件。
最后尝试在更高版本的CentOS上编译:安装了CentOS-Stream-9虚拟机。它自带了gcc 11,glibc也是更新版本的,可以直接安装clang,对于CentOS-Stream-9,dnf代替了yum,但是命令行选项的含义都是一样的,只是开头的命令从yum换成了dnf。
在CentOS-Stream-9上,使用gcc而不是clang,doris分支为master,只要对源码工程做小小的改动,就可以编译成功了(这里是指编译be),这种方式编译出来的be也可以用自带的gdb调试。
同时尝试了CentOS-Stream-9上,编译doris的tag:1.2.4.3,它不用修改,编译工程会选择使用gcc。这个过程感到master上的代码由很多问题,最好不要用它编译,应该用tag版本的代码。截止本文,doris最新发布版为1.2.5。
关于glibc的信息,参考:NewAppsOnOldGlibc (lightofdawn.org)
在这个过程中学到的几个知识点:
1、关于clang
没有深入研究,只当它是gcc/g++的代替,使用方法,命令行选项的含义大多与 gcc/g++ 相同,且编译出的可执行程序也可以用gdb调试的(测试过),也可以用lldb调试(没测试过),动态库,静态库的链接和使用也和gcc/g++相同。

通过阅读网上文章,感觉clang的跨平台性更好一些,macOS,windows用clang编译器。
clang和llvm是配合使用的,只有clang是不能生成机器代码的,从源码编译llvm时会自动编译clang。
BE也可以用gcc编译,注意不要直接改env.sh,而是设置环境变量:
USE_AVX2=0 BUILD_TYPE=Debug DORIS_TOOLCHAIN=gcc ./build.sh --be
2、关于 链接静态库
如果链接的是动态库,或链接时全都是.o,那没有问题,但是如果有.a文件,这些静态库就有个顺序问题,简单地说,就是.a文件(或.o文件)里面也会依赖其它库定义的符号,被依赖的库文件必须出现在依赖它的库文件后面,才不会出现undefined reference错误,这个问题的解决,除了人工调整.a文件的顺序外,还可以使用连接选项-Wl,--start-group和-Wl,--end-group,把一些.a文件放在这两个选项之间,链接器寻找符号时会多次扫描这两个选项之间的.a文件,无论它们顺序如何,或者它们之间有怎样复杂的循环依赖都可以处理,也可以没有-Wl,--end-group,只有-Wl,--start-group,表示-Wl,--start-group的后面的都在影响范围内。
但是对于动态链接,有一个链接器选项:-Wl,--as-needed,也要求so文件在目标文件后面,估计是避免不必要的链接,就是不会把命令行里所有so链接到可执行文件。
还遇到一个问题,libkrb5.a 要依赖 libresolv.a,但是我的/usr/lib64里只有libresolv.so,没有静态版本,链接时指定了 -lresolv,还是会报错:
undefined reference to '__res_nsearch'
解决办法就是链接doris_be的时候,给出libresolv.a的绝对路径,幸好在ldb_toolchain里有libresolv.a。
至于 -L -lname的链接选项,我暂时理解这是给动态库用的。
关于静态库和动态库的编译选项:
1、动态连接库中用到的object文件必须是用 "-shared -fPIC"选项编译产生的,否则连接时要么报错,要么被忽略。
2、静态库中的object文件最好也用"-shared -fPIC"选项编译,这样静态库就可以同时被连接到.so 或者可执行性文件中。
参考:
(40条消息) C/C++ 静态链接的顺序问题_howard_shooter的博客-优快云博客
Static and Dynamic Linkage in C++ - jdhao's digital space
这个静态库问题,是我使用gcc编译doris的be时遇到的,当修改了env.sh,使用gcc编译时,最后连接时报如下错误:
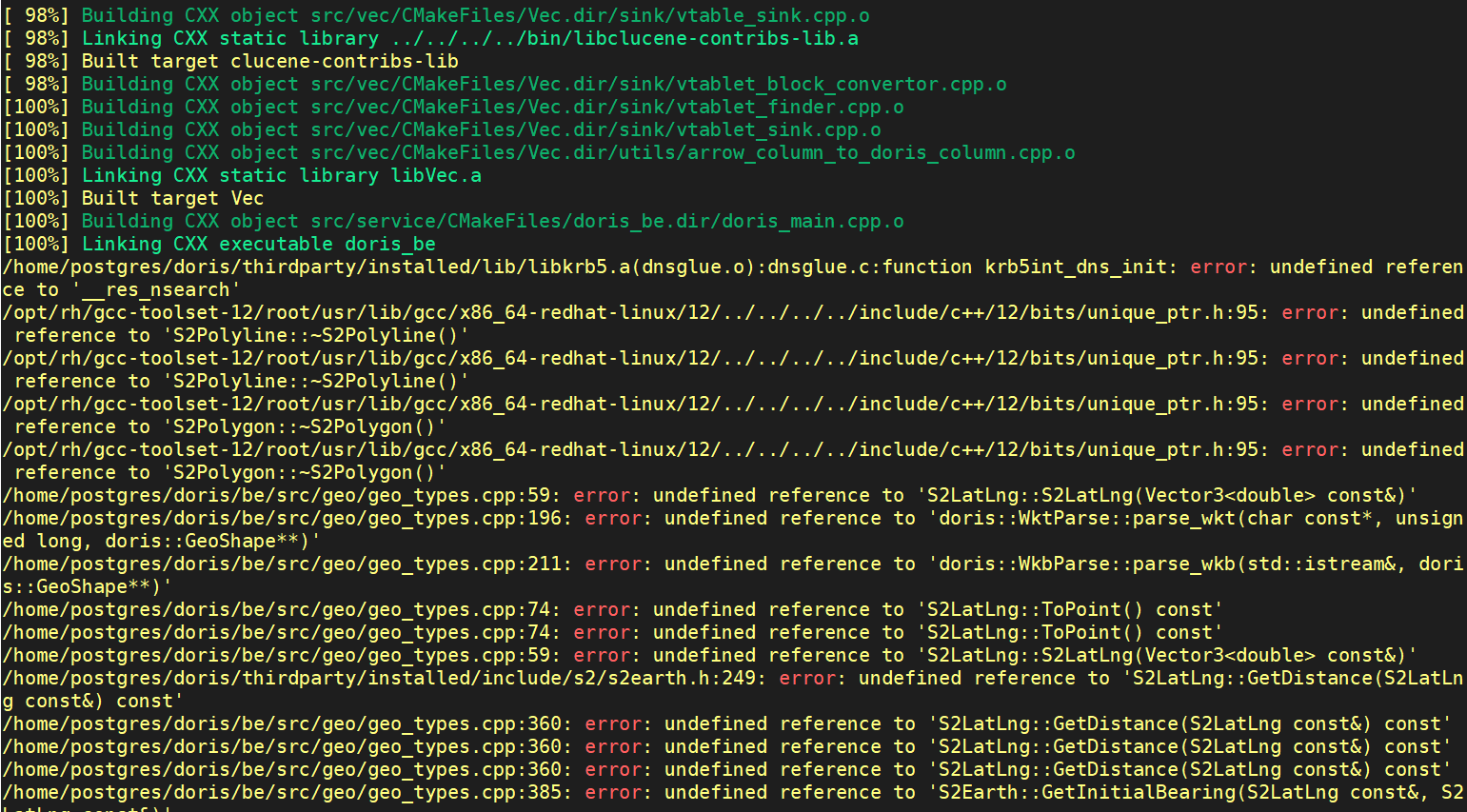 经过研究,是静态库链接顺序导致的问题,但具体的修改方式是,把geo_types.cpp和geo的其它文件一起编译进libGeo.a,修改be/src/geo/CMakeLists.txt:
经过研究,是静态库链接顺序导致的问题,但具体的修改方式是,把geo_types.cpp和geo的其它文件一起编译进libGeo.a,修改be/src/geo/CMakeLists.txt:

但是我发现,如果用master分支,不做任何修改,即使用clang编译,这里不修改也能编译,按照网友的提示,clang编译的程序也可以用gdb调试,所以不必为了用gdb调试而专门用gcc编译,gdb调试的机制应该和编译工具不相关。
3、 关于cmake
cmake类似于configure,可以生成Makefile或其它IDE的编译工程,既然它在Makefile或IDE上面加了一层,那它应该比它们更易用才行,不过我感到cmake也没有多么易用,只是业界都在使用,我也只好学着用。
用户创建cmake工程,最关键的是编写CMakeLists.txt,在cmake工程中只有它不是自动生成的,需要人工编写,要编译哪些源文件,要用到哪些编译选项,宏定义,动态连接还是静态链接,生成的是可执行程序还是库,都在CMakeLists.txt指定,所以当想修改工程的编译选项,宏定义,或是编译时出什么问题,都应该在CMakeLists.txt里寻找线索。
CMakeLists.txt是目录嵌套的,就是说,对于一个有许多层目录的cmake工程,根目录有一个CMakeLists.txt,子目录下可能也有CMakeLists.txt,父目录的CMakeLists.txt中用add_subdirectory将子目录下的CMakeLists.txt联系起来。
CMakeLists.txt和*.cmake文件是cmake脚本,里面按照cmake语法编写,有许多cmake的功能函数,例如:
set(BUILD_STATIC_LIBRARIES ON) -- 用于设置cmake变量
add_library(Geo STATIC
geo_common.cpp
wkt_parse.cpp
wkb_parse.cpp
${GENSRC_DIR}/geo/wkt_lex.l.cpp
${GENSRC_DIR}/geo/wkt_yacc.y.cpp
geo_tobinary.cpp
ByteOrderValues.cpp
machine.h
geo_types.cpp
)
-- 编译生成库文件add_executable(doris_be doris_main.cpp) -- 编译生成可执行文件
target_link_libraries(doris_be
${DORIS_LINK_LIBS}
)-- 连接可执行文件
add_executable是指生成可执行文件doris_be需将哪些源文件包含进来。
target_link_libraries是指生成可执行文件doris_be除了上面的源文件,还要链接哪些库文件。
两者不冲突,如果只有add_executable,没有target_link_libraries,那就把源文件直接编译生成可执行文件。
include_directories: 增加头文件搜索路径
link_directories: 增加库文件搜索路径
cmake生成的Makefile工程,执行make时默认不显示编译gcc命令,要想像configure&make显示每个文件的编译命令,有三种方法:
方法1:
执行命令cmake时追加:-DCMAKE_VERBOSE_MAKEFILE=ON
方法2:
在CMakeLists.txt中添加:set(CMAKE_VERBOSE_MAKEFILEON ON)
方法3:
make时追加: VERBOSE=1
4、关于nm
我用来查看可执行文件或者库文件的符号表,对于C++符号名会被mangle,可读性差,可以nm时demangle,用-C选项,例如:
nm myprogram -C
显示出的符号中前面的字母含义,这里列出常用的几个:
U :本文件中未定义的
T:本文件中定义的
W/w:这是个弱符号,就是说如果其它文件定义了这个符号且不是弱符号就用其它文件的,否则用本文件的
参考:
(38条消息) linux——nm命令:查看符号表_nm查看符号表_The Goat的博客-优快云博客
这里有个概念:弱符号
参考:
(40条消息) __attribute__((weak)) 简介及作用___attribute__((weak)) mt_disp_show_charging(int in_侵蚀昨天的博客-优快云博客
注意:这个weak属性可以用于C语言程序的,这就让C语言程序具备了类似C++的虚函数中的override功能。
5、关于 ABI
ABI是Application Binary Interface的简称。
C/C++发展的过程中,二进制兼容一直是个问题。不同编译器厂商编译的二进制代码之间兼容性不好,甚至同一个编译器的不同版本之间兼容性也不好。
之后,C拥有了统一的ABI,而C++由于其特性的复杂性以及ABI标准推进不力,一直没有自己的ABI。
这就涉及到标识符的mangle问题。比如,C++源码中的同一个函数名,不同的编译器或不同的编译器版本,编译后的名称可能会有不同。
参考:
mangle和demangle - BloodAndBone - 博客园 (cnblogs.com)
C++ standard library ABI compatibility | MaskRay
6、关于debug info
-g和-O2或-O3可以一起使用,优化代码的同时,保存调试信息,之后可以把调试信息单独提取出来,每个可执行文件或库都有对应的.debug文件,里面记录了其中的函数在哪个源文件的那一行,它们总称为debug info。例如,生成产系统上出现段错误,一线运维发挥调用栈或core dump文件,结合debug info,可以指定详细的crash信息。
参考:
(40条消息) 深入理解debuginfo_Chinainvent的博客-优快云博客
7、关于maven
在公司可以连外网的机器上试过,maven源设为国内的,可以编译通过FE,使用国内源,编译时间会短一些。
在maven的安装目录下的conf/settings.xml中加入:
<mirror>
<id>nju_mirror</id>
<mirrorOf>central</mirrorOf>
<url>https://repo.nju.edu.cn/repository/maven-public/</url>
</mirror>
8、gcc编译master分支
尝试使用gcc编译master分支,原因是我的环境上ldb_toolchain编译出来的没法调试,而且由于要提交PR,需要用master分支。
编译master分支,要注意的问题:
1、使用最新的第三方预编译库,第三方库我一直使用预编译的二级制版本,没有自己从源码编译,不过要用最新的,而且还要clean,不然大概率会有编译错误。
2、选择gcc编译器,不要改env.sh,而是要设置环境变量。
USE_AVX2=0 BUILD_TYPE=Debug DORIS_TOOLCHAIN=gcc ./build.sh --clean --be
9、编译 doris-3.0.4(BCLinux)
为了完全掌握编译过程,以及在不同cpu和操作系统上制作版本,我重新走了一遍编译过程。
3.0.4 相对于以前版本功能多了存算分离功能,即数据存储放到了FundationDB和对象存储中。
但是这个对构建过程影响不大,而且社区提示,这一特性稳定性和性能还不够好,所以这次我的目的是,重新编译按照之前方式使用版本。
首先编译BE,执行build.sh脚本,BE依赖于第三方库,脚本会下载并编译每一个第三方库,这次我是从源码编译第三方库,保证每个第三方库成功的下载、解压、编译、安装。
BE依赖的第三方库非常多,过程非常漫长,我的机器经常断网,因此必须使用screen。
我使用gcc11.4.0编译,使用clang会有问题,这是我自己编译的,安装也可以,我的环境是x86_64-BCLinux(openeuler),有的库会引用 /usr/lib64/libstdc++.so.6,然后报 GLIBCXX_3.4.29 not found 这是我系统中原有的libstdc++.so.6 太旧了,又没有引用到 gcc11的libstdc++.so.6,解决办法就是修改链接 /usr/lib64/libstdc++.so.6 使他指向 gcc11提供的 /usr/lib64/libstdc++.so.6 ,幸好它不像libc那样是系统极端重要的库,不能轻易替换。
strings /usr/local/lib64/libstdc++.so.6 | grep GLIBCXX_3.4.29 可以查看libstdc++库的版本。
注意,运行时也要使用这个最新的 libstdc++ 库。
build thirdparty漫长的过程,非常有可能因为各种原因中断,这就需要一个能够继续的方法,而不是没次中断都要从头再来,幸好 build-thirdparty.sh 提供了这一功能,就是:
DORIS_TOOLCHAIN=gcc USE_AVX2=0 ./build-thirdparty.sh --continue azure > log 2>&1
--continue azure 表示从azure库开始编译,如果之前的库编译安装成功,就不需要再编译了。
build-thirdparty.sh azure 表示只编译azure这一个库。
build-thirdparty.sh --clean 表示清除之前所有库的编译结果,再重新编译。
注意,在构建第三方库的过程中,仍然会下载一些源码,有可能会下载失败,需要多尝试几次。
最后一个第三方库 hadoop_libs 编译时要注意,mirror 不要选国内镜像,注释掉就行了,还要设置JAVA_HOME,我是这样设置的 export JAVA_HOME=/mnt/disk01/nl/jdk-17.0.2 不需要设置PATH。
目前来说 azure 没能编译成功。

















 711
711

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









