




文章目录
1. 实战概述
- 本次实战围绕 PySpark 的本地与远程开发环境搭建及词频统计应用展开。通过在虚拟机中配置 IPython 并结合 findspark 与 pyspark 库,分别使用 RDD 和 Spark SQL 实现了对本地及 HDFS 文件的词频统计;同时,在宿主机 PyCharm 中远程连接虚拟机,完成相同功能的脚本开发与运行,验证了 PySpark 在不同开发模式下的灵活性与一致性。
2. 实战步骤
2.1 在虚拟机的IPython里玩PySpark
2.1.1 更换pip3源为阿里源
-
执行命令:
mkdir ~/.pip
-
执行命令:
vim ~/.pip/pip.conf
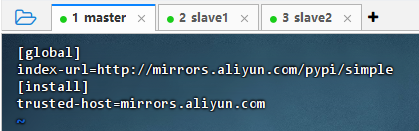
[global] index-url=http://mirrors.aliyun.com/pypi/simple [install] trusted-host=mirrors.aliyun.com
2.1.2 安装IPython库
- 执行命令:
pip3 install ipython
2.1.3 安装findspark库
- 执行命令:
pip3 install findspark
2.1.4 安装pyspark库
- 执行命令:
pip3 install pyspark
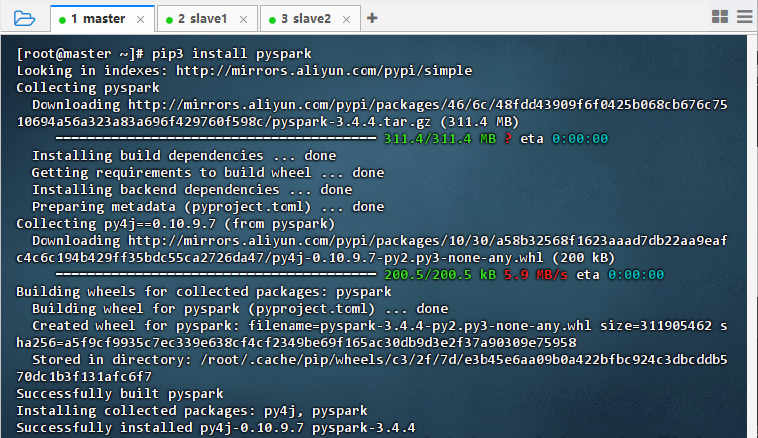
2.1.5 在IPython里玩Spark
-
启动ipython,导入findspark库,初始化,导入pyspark库,定义sc变量
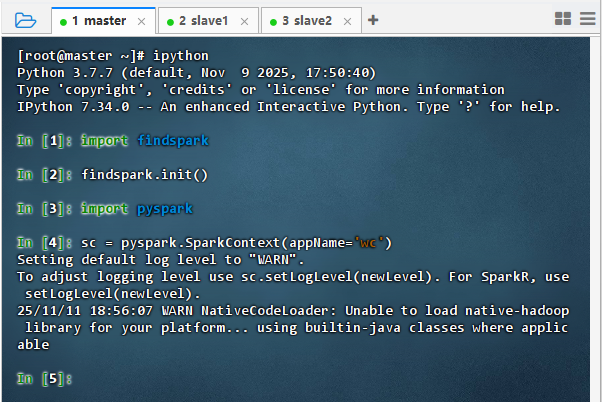
-
使用PySpark基于Spark RDD实现词频统计
-
数据源为本地文件:
/root/words.txtfor wc in sc.textFile("/root/words.txt") \ .flatMap(lambda line: line.split(' ')) \ .map(lambda word: (word, 1)) \ .reduceByKey(lambda a, b: a + b) \ .sortBy(lambda wc: wc[1], False) \ .collect(): print(wc)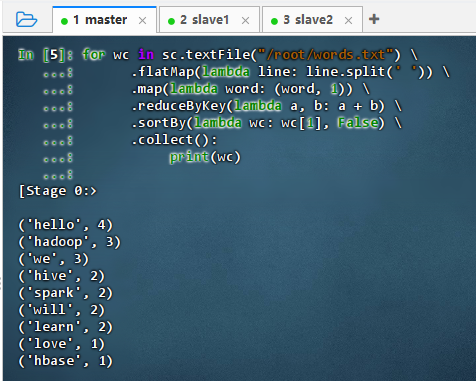
-
数据源为HDFS文件:
hdfs://master:9000/wordcount/input/test.txtfor wc in sc.textFile("hdfs://master:9000/wordcount/input/test.txt") \ .flatMap(lambda line: line.split(' ')) \ .map(lambda word: (word, 1)) \ .reduceByKey(lambda a, b: a + b) \ .sortBy(lambda wc: wc[1], False) \ .collect(): print(wc)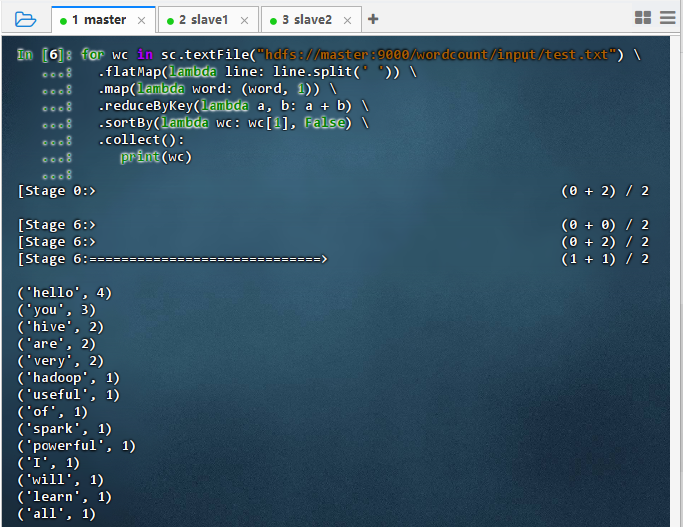
-
-
使用PySpark基于Spark SQL实现词频统计
-
导入Spark会话,执行命令:
from pyspark.sql import SparkSession
-
创建Spark会话对象,执行命令:
spark = SparkSession.builder.appName('wc').getOrCreate()
-
读取HDFS文件生成数据帧,执行命令:
lines_df = spark.read.text("hdfs://master:9000/wordcount/input/test.txt")

-
基于数据帧创建临时视图,执行命令:
lines_df.createOrReplaceTempView("lines")
-
使用Spark SQL编写词频统计查询
result = spark.sql(""" SELECT word, COUNT(*) AS count FROM ( SELECT explode(split(value, ' ')) AS word FROM lines ) t WHERE word != '' AND word IS NOT NULL GROUP BY word ORDER BY count DESC """)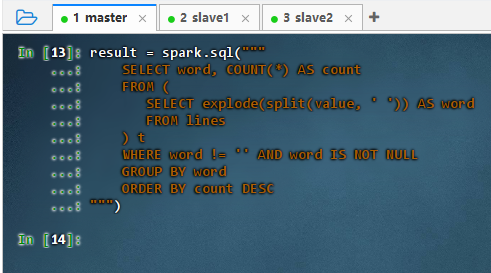
-
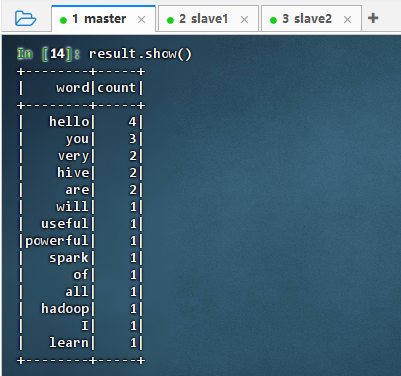
执行命令:
result.show()
-
收集并逐行打印结果
for row in result.collect(): print(f"('{row[0]}', {row[1]})")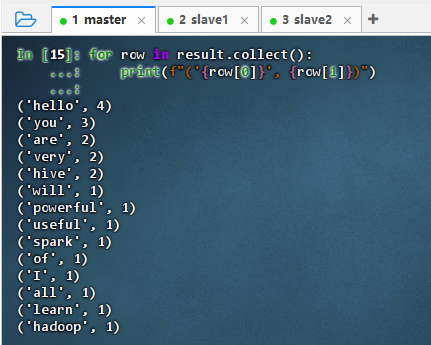
-
2.2 在宿主机的PyCharm里玩PySpark
2.2.1 更换pip3源为阿里源
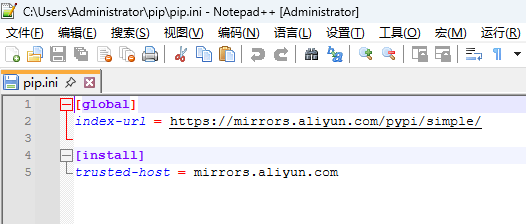
- pip初始化文件:
C:\Users\Administrator\pip\pip.ini
2.2.2 安装IPython库
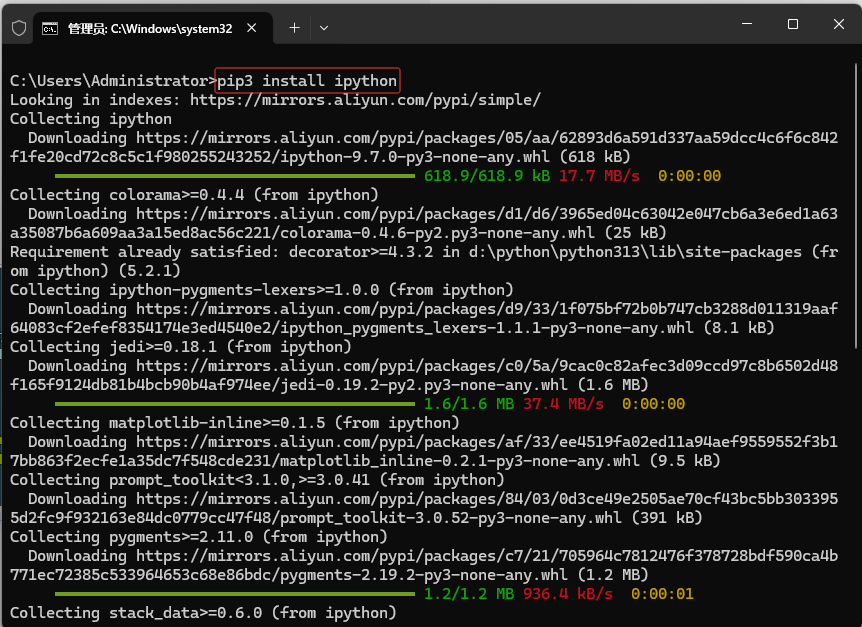
- 执行命令:
pip3 install ipython
2.2.3 安装findspark库
- 执行命令:
pip3 install findspark
2.2.4 安装pyspark库
- 执行命令:
pip3 install pyspark
2.2.5 在PyCharm里玩Spark
-
使用Spark RDD实现词频统计
-
创建
Spark RDD词频统计.py文件
""" 功能:采用Spark RDD实现词频统计 作者:华卫 日期:2025年11月11日 """ import findspark findspark.init() from pyspark import SparkContext # ============================== # 1. 初始化 SparkContext # ============================== # 创建 Spark 上下文,指定应用名称为 "WordCount" # 注意:在本地测试时,若未配置 HDFS,可改用本地文件路径 sc = SparkContext(appName="WordCount") try: # ============================== # 2. 读取输入文件(HDFS 路径) # ============================== # 从 HDFS 读取文本文件,返回一个 RDD,每个元素是一行字符串 lines_rdd = sc.textFile("hdfs://master:9000/wordcount/input/test.txt") # ============================== # 3. 拆分每行为单词(扁平化) # ============================== # 对每一行使用 split(' ') 切分为单词列表, # flatMap 将所有列表“拍平”成一个单词的 RDD words_rdd = lines_rdd.flatMap(lambda line: line.split(' ')) # ============================== # 4. 映射为 (word, 1) 键值对 # ============================== # 将每个单词转换为元组 (word, 1),用于后续计数 word_pairs_rdd = words_rdd.map(lambda word: (word, 1)) # ============================== # 5. 按键聚合,统计词频 # ============================== # 对相同的 key(即单词)进行 reduce,累加其 value(即出现次数) word_counts_rdd = word_pairs_rdd.reduceByKey(lambda a, b: a + b) # ============================== # 6. 按词频降序排序 # ============================== # sortBy 接收一个函数,提取每个元素的排序依据(这里是词频 wc[1]) # ascending=False 表示降序(从高到低) sorted_word_counts_rdd = word_counts_rdd.sortBy(lambda wc: wc[1], ascending=False) # ============================== # 7. 收集结果并打印 # ============================== # collect() 将分布式 RDD 的所有数据拉取到 Driver 端(仅适用于小结果集!) result = sorted_word_counts_rdd.collect() print("==词频统计结果(按频率降序)==") for word, count in result: print(f"{word}: {count}") finally: # ============================== # 8. 关闭 SparkContext(释放资源) # ============================== sc.stop() -
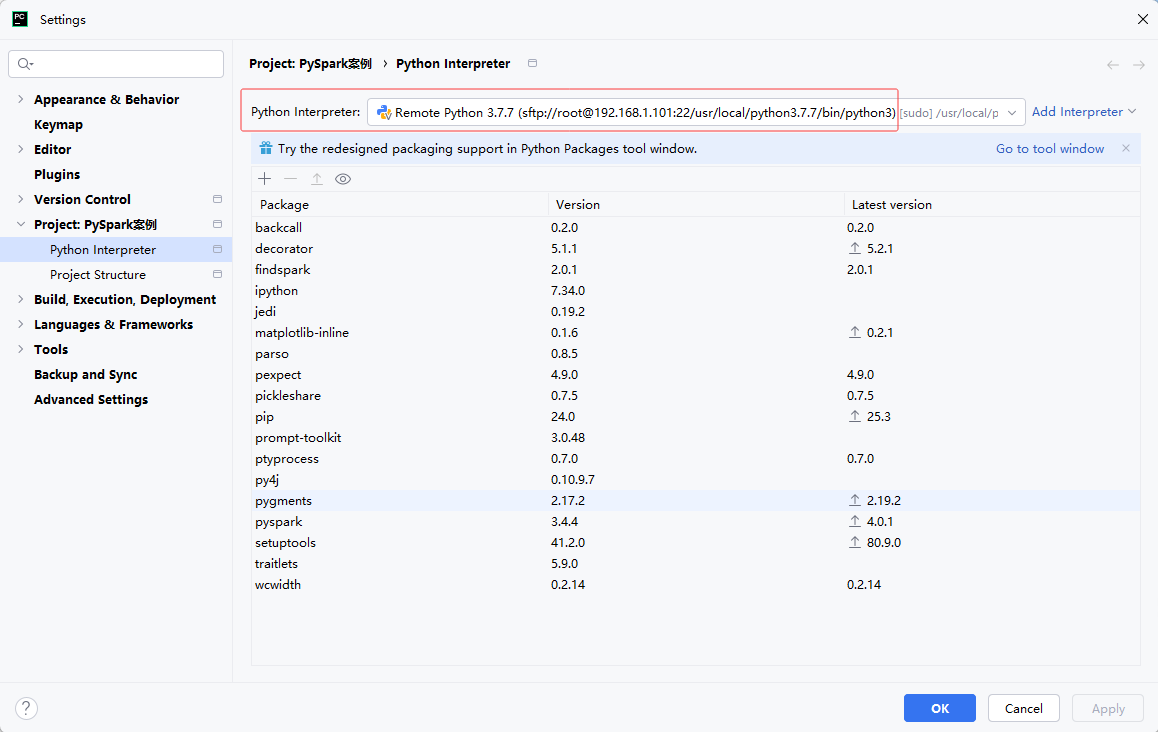
配置Python解释器(远程连接master虚拟机,使用Python3.7.7解释器)
-
运行程序,查看结果
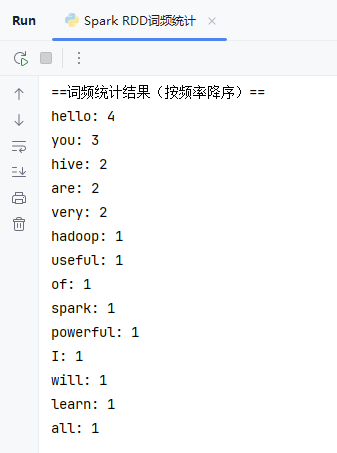
-
-
使用Spark SQL实现词频统计
-
创建
Spark SQL词频统计.py文件
""" 功能:采用 Spark SQL(基于临时视图 + SQL 查询)实现词频统计 作者:华卫 日期:2025年11月11日 """ import findspark findspark.init() from pyspark.sql import SparkSession # ============================== # 初始化 SparkSession # ============================== spark = SparkSession.builder \ .appName("WordCountSQLWithView") \ .getOrCreate() try: # ######################################################### # 1. 读取HDFS文件生成数据帧 # - 每行一个字符串,列名为 "value" # ######################################################### lines_df = spark.read.text("hdfs://master:9000/wordcount/input/test.txt") # 此时 lines_df 包含一列:value(类型为 string) # ######################################################### # 2. 基于数据帧创建临时视图,供SQL查询使用 # ######################################################### lines_df.createOrReplaceTempView("lines") # ######################################################### # 3. 使用Spark SQL编写词频统计查询 # - 拆分单词、炸裂数组、过滤空值和NULL、分组计数、降序排序 # ######################################################### result = spark.sql(""" SELECT word, COUNT(*) AS count FROM ( SELECT explode(split(value, ' ')) AS word FROM lines ) t WHERE word != '' AND word IS NOT NULL GROUP BY word ORDER BY count DESC """) result.show() # 表格形式输出结果 # ######################################################### # 4. 收集并逐行打印结果 # - 格式:('word', count) # ######################################################### print("==词频统计结果(按频率降序)==") for row in result.collect(): print(f"('{row[0]}', {row[1]})") finally: # 关闭 SparkSession spark.stop() -
运行程序,查看结果
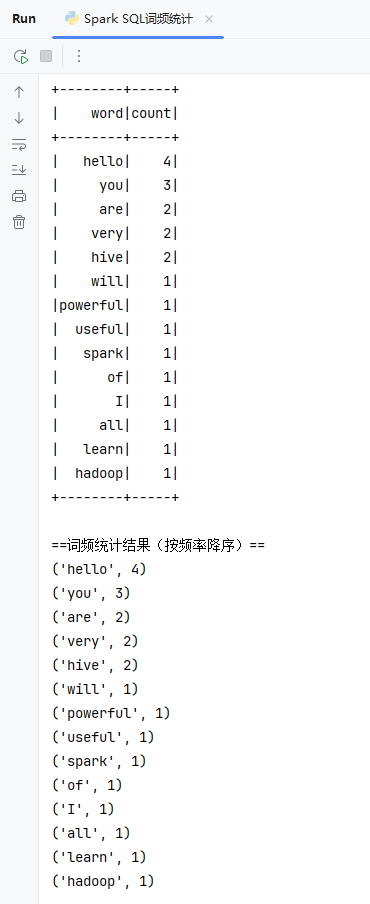
-
3. 实战总结
- 本次实战系统地完成了 PySpark 开发环境的搭建与词频统计任务的实现。首先在虚拟机中配置阿里源,安装 IPython、findspark 和 pyspark,并通过 IPython 交互式环境成功运行基于 RDD 和 Spark SQL 的词频统计代码,验证了对本地文件和 HDFS 文件的处理能力。随后,在宿主机的 PyCharm 中配置远程 Python 解释器,连接虚拟机 Spark 环境,编写结构清晰的脚本分别使用 RDD 和 Spark SQL 实现相同功能,结果一致且运行稳定。整个过程不仅掌握了 PySpark 的核心 API 使用方法,也熟悉了本地开发与远程集群协同的工作模式,为后续大数据应用开发奠定了坚实基础。



















 2702
2702

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











