




1. 引言:高可用性的业务价值
在当今数字化时代,数据库高可用性不再是"锦上添花",而是业务连续性的"生命线"。对于Java开发者而言,理解MySQL高可用架构意味着:
- 业务连续性:保证7×24小时服务不中断
- 数据安全:防止单点故障导致数据丢失
- 性能扩展:支撑业务快速增长的数据访问需求
- 故障恢复:快速从各类故障中恢复服务
// 高可用缺失的代价 - 电商平台场景
@Service
public class OrderService {
public void createOrder(OrderDTO order) {
try {
// 数据库宕机时,整个交易链路中断
orderDAO.insert(order);
inventoryDAO.deduct(order.getItems());
paymentService.process(order);
} catch (DatabaseConnectionException e) {
// 直接影响营收和用户体验
throw new BusinessException("系统繁忙,请稍后重试");
}
}
}
2. 高可用基础概念
2.1 可用性指标与SLA
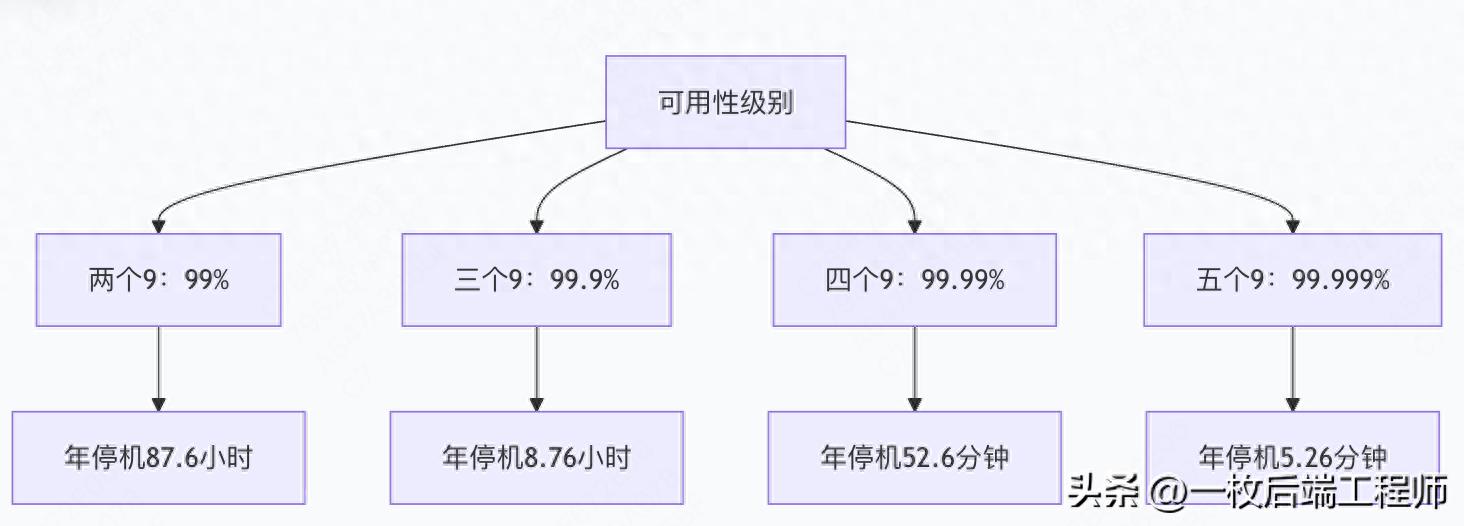
2.2 高可用核心要素
- 冗余性:消除单点故障
- 监控性:实时检测组件状态
- 故障转移:自动切换备用系统
- 数据一致性:保证主从数据同步
- 可恢复性:快速从故障中恢复
3. 基于复制的高可用架构
3.1 主从复制架构
3.1.1 基础架构设计
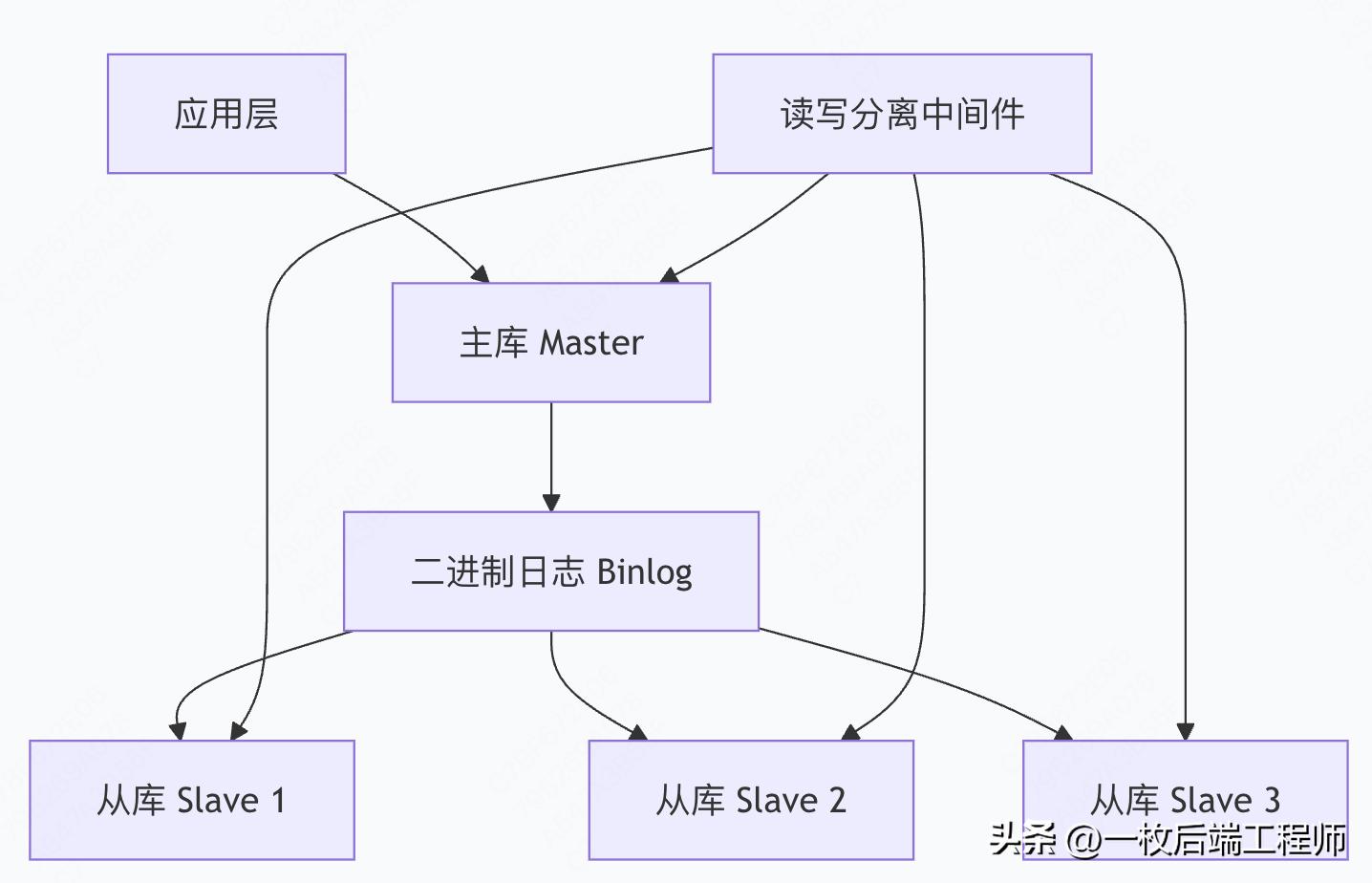
3.1.2 复制模式深度解析
public class ReplicationModeAnalysis {
/**
* 异步复制 - 性能优先
*/
public void asyncReplication() {
// 主库提交事务后立即返回,不等待从库确认
// 优点:性能最佳
// 缺点:可能丢失数据(主库宕机时)
}
/**
* 半同步复制 - 平衡选择
*/
public void semiSyncReplication() {
// 主库提交事务时,至少等待一个从库确认
// 优点:保证数据至少有一个副本
// 缺点:性能略有下降
}
/**
* 全同步复制 - 数据安全优先
*/
public void fullSyncReplication() {
// 主库提交事务时,等待所有从库确认
// 优点:数据最安全
// 缺点:性能影响较大
}
}
// 半同步复制配置示例
@Configuration
public class SemiSyncConfig {
@Bean
public CommandLineRunner setupSemiSync(DataSource dataSource) {
return args -> {
JdbcTemplate jdbc = new JdbcTemplate(dataSource);
// 主库配置
jdbc.execute("INSTALL PLUGIN rpl_semi_sync_master SONAME 'semisync_master.so'");
jdbc.execute("SET GLOBAL rpl_semi_sync_master_enabled = 1");
jdbc.execute("SET GLOBAL rpl_semi_sync_master_timeout = 1000"); // 1秒超时
// 从库配置
jdbc.execute("INSTALL PLUGIN rpl_semi_sync_slave SONAME 'semisync_slave.so'");
jdbc.execute("SET GLOBAL rpl_semi_sync_slave_enabled = 1");
};
}
}
3.2 主主复制架构
3.2.1 双主模式设计
-- 节点A配置 (server-id=1) [mysqld] server-id = 1 log-bin = mysql-bin auto_increment_increment = 2 auto_increment_offset = 1 replicate-do-db = business_db -- 节点B配置 (server-id=2) [mysqld] server-id = 2 log-bin = mysql-bin auto_increment_increment = 2 auto_increment_offset = 2 replicate-do-db = business_db
3.2.2 数据冲突解决策略
@Service
public class DualMasterConflictResolver {
/**
* 自增ID冲突避免 - 奇偶分配
*/
public class IdGenerator {
private final long nodeId; // 1 或 2
public Long generateId() {
// 节点1生成奇数ID:1, 3, 5, 7...
// 节点2生成偶数ID:2, 4, 6, 8...
String sql = "SELECT business_seq.nextval * 2 - ? FROM dual";
return jdbcTemplate.queryForObject(sql, Long.class, nodeId);
}
}
/**
* 数据冲突检测与处理
*/
@Transactional
public void handleDataConflict(String businessKey, Object newData) {
// 1. 检查最后更新时间
Timestamp lastUpdate = getLastUpdateTime(businessKey);
// 2. 基于时间戳的冲突解决
if (isNewerData(lastUpdate, newData.getUpdateTime())) {
updateData(businessKey, newData);
} else {
log.warn("数据冲突,忽略旧数据更新: {}", businessKey);
// 可选的冲突解决策略:
// - 记录冲突日志
// - 通知管理员
// - 业务特定解决逻辑
}
}
}
4. MySQL Group Replication
4.1 组复制原理架构
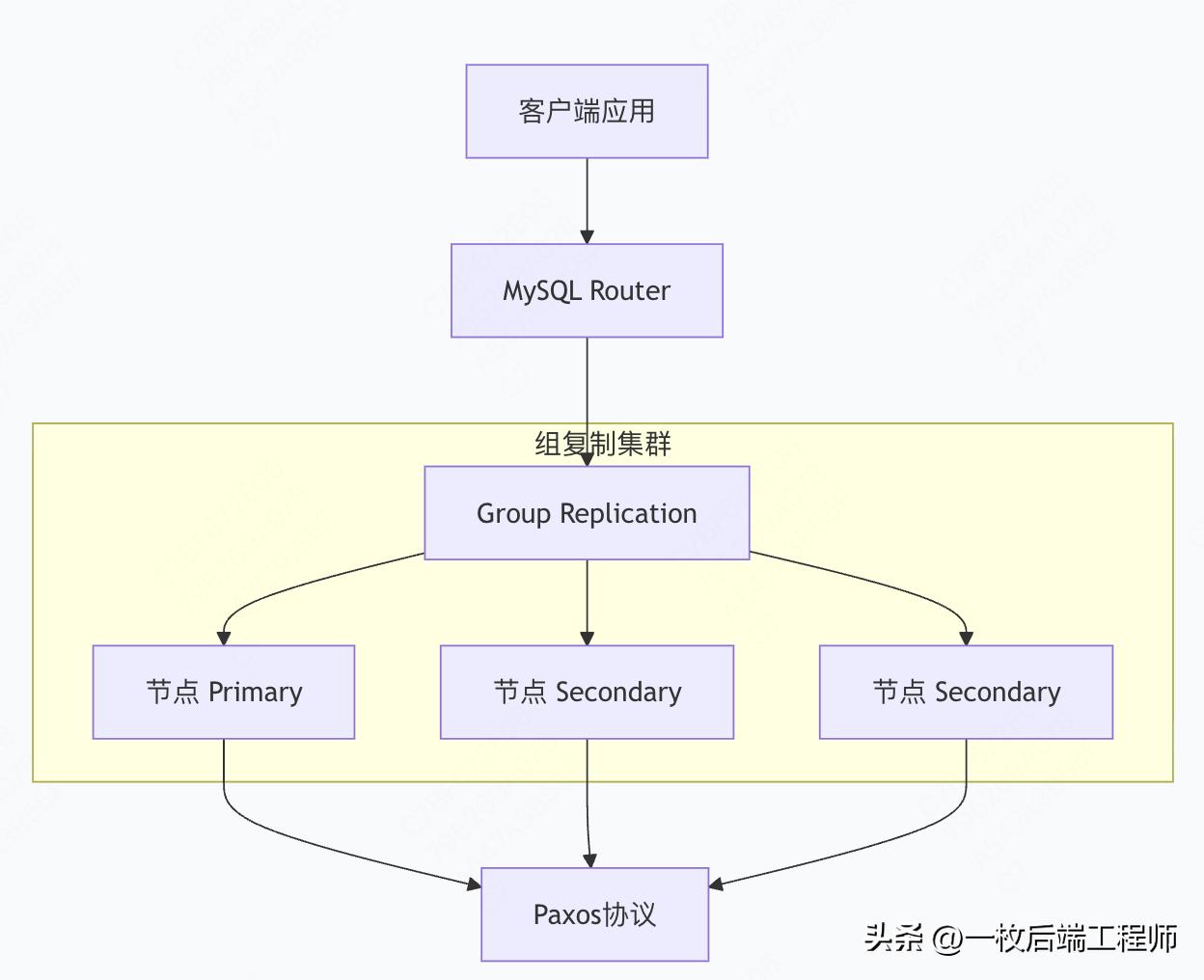
4.2 组复制配置实战
4.2.1 集群初始化
# 节点1 - 引导节点 mysqld --defaults-file=node1.cnf --initialize-insecure mysqld --defaults-file=node1.cnf & mysql -h 127.0.0.1 -P 3306 -u root -p # MySQL中执行: SET SQL_LOG_BIN=0; CREATE USER replication@'%' IDENTIFIED BY 'password'; GRANT REPLICATION SLAVE ON *.* TO replication@'%'; FLUSH PRIVILEGES; SET SQL_LOG_BIN=1; INSTALL PLUGIN group_replication SONAME 'group_replication.so'; SET GLOBAL group_replication_bootstrap_group=ON; START GROUP_REPLICATION; SET GLOBAL group_replication_bootstrap_group=OFF;
4.2.2 节点加入集群
-- 节点2加入集群 INSTALL PLUGIN group_replication SONAME 'group_replication.so'; SET GLOBAL group_replication_group_seeds = "node1:33061,node2:33061,node3:33061"; START GROUP_REPLICATION USER='replication', PASSWORD='password'; -- 验证集群状态 SELECT * FROM performance_schema.replication_group_members;
4.2.3 Java应用集成
@Configuration
public class GroupReplicationConfig {
@Bean
@Primary
public DataSource groupReplicationDataSource() {
MysqlDataSource dataSource = new MysqlDataSource();
// 配置多节点连接
dataSource.setUrl("jdbc:mysql:replication://" +
"node1:3306,node2:3306,node3:3306/business_db?" +
"loadBalanceStrategy=random&" +
"autoReconnect=true&" +
"failOverReadOnly=false");
dataSource.setUser("app_user");
dataSource.setPassword("secure_password");
return dataSource;
}
@Bean
public GroupReplicationHealthCheck healthCheck() {
return new GroupReplicationHealthCheck();
}
}
@Component
public class GroupReplicationHealthCheck {
@Autowired
private DataSource dataSource;
public Health checkHealth() {
try {
JdbcTemplate jdbc = new JdbcTemplate(dataSource);
// 检查集群成员状态
List<Map<String, Object>> members = jdbc.queryForList(
"SELECT member_id, member_host, member_state " +
"FROM performance_schema.replication_group_members"
);
long healthyMembers = members.stream()
.filter(m -> "ONLINE".equals(m.get("member_state")))
.count();
if (healthyMembers >= 2) {
return Health.up()
.withDetail("activeMembers", healthyMembers)
.build();
} else {
return Health.down()
.withDetail("activeMembers", healthyMembers)
.build();
}
} catch (Exception e) {
return Health.down(e).build();
}
}
}
5. InnoDB Cluster全面解析
5.1 架构组件详解
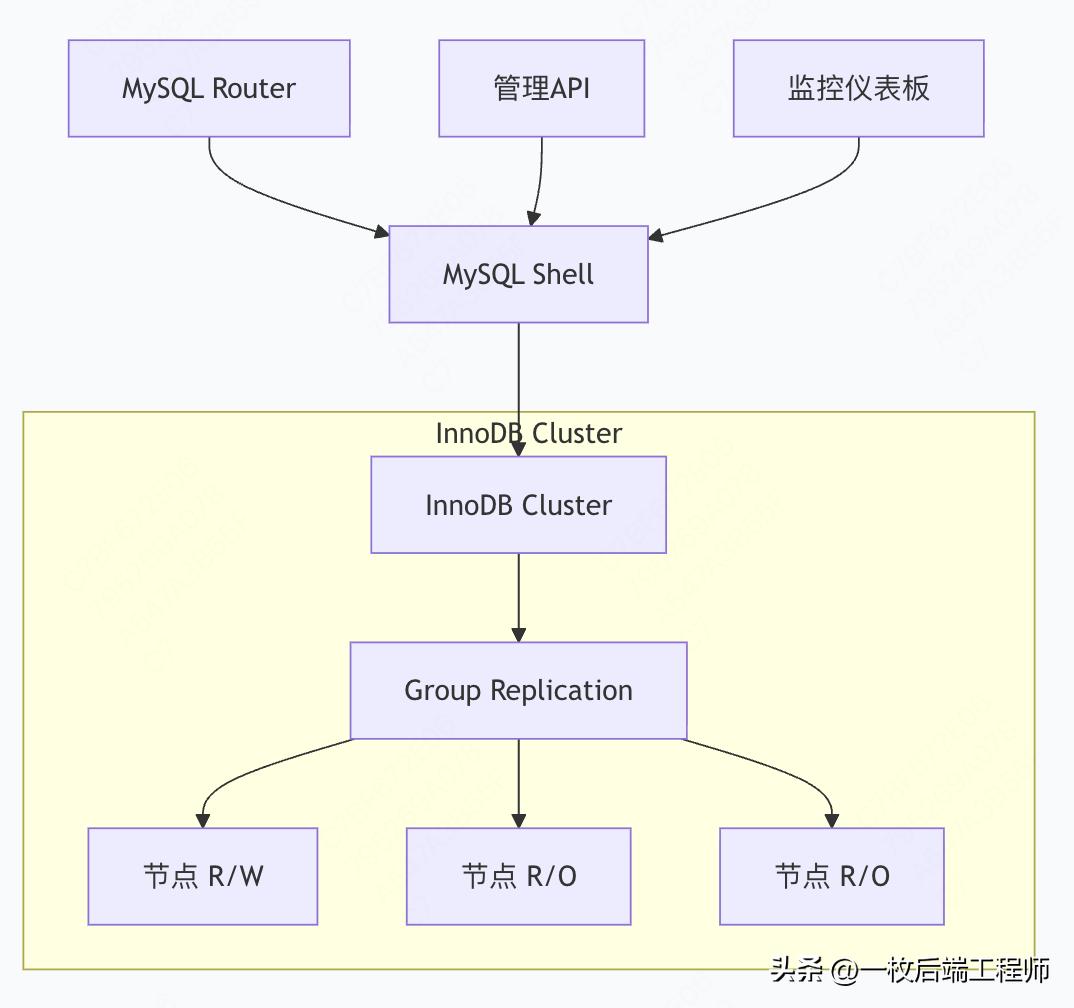
5.2 集群部署与管理
5.2.1 使用MySQL Shell部署
// 使用MySQL Shell配置InnoDB Cluster
// 连接到种子节点
\connect root@node1:3306
// 创建集群
var cluster = dba.createCluster('production_cluster')
// 添加实例
cluster.addInstance('root@node2:3306', {password: 'password'})
cluster.addInstance('root@node3:3306', {password: 'password'})
// 检查集群状态
cluster.status()
// 配置MySQL Router
// 在应用服务器安装并配置Router
mysqlrouter --bootstrap root@node1:3306 --directory /opt/mysqlrouter --user=mysqlrouter
5.2.2 集群运维命令
-- 查看集群状态
SELECT * FROM performance_schema.replication_group_members;
-- 检查集群健康度
SELECT * FROM mysql_innodb_cluster_metadata.instances;
-- 手动故障转移
-- 在MySQL Shell中执行:
cluster.setPrimaryInstance('node2:3306')
-- 移除故障节点
cluster.removeInstance('node3:3306')
5.3 Java应用适配
@Configuration
@EnableConfigurationProperties(ClusterProperties.class)
public class InnoDBClusterConfig {
@Bean
@Primary
public DataSource innodbClusterDataSource(ClusterProperties properties) {
MysqlDataSource dataSource = new MysqlDataSource();
// 使用MySQL Router作为接入点
dataSource.setUrl("jdbc:mysql://router-host:6446/business_db?" +
"loadBalanceAutoCommitStatementThreshold=5&" +
"retriesAllDown=10&" +
"secondsBeforeRetryMaster=30&" +
"initialTimeout=2");
dataSource.setUser(properties.getUsername());
dataSource.setPassword(properties.getPassword());
return new LazyConnectionDataSourceProxy(dataSource);
}
@Bean
public ClusterAwareTransactionManager transactionManager(DataSource dataSource) {
return new ClusterAwareTransactionManager(dataSource);
}
}
@Component
public class ClusterAwareTransactionManager extends DataSourceTransactionManager {
public ClusterAwareTransactionManager(DataSource dataSource) {
super(dataSource);
}
@Override
protected void doBegin(Object transaction, TransactionDefinition definition) {
try {
super.doBegin(transaction, definition);
} catch (CannotGetJdbcConnectionException e) {
// 处理集群节点故障
handleClusterFailure(e);
throw e;
}
}
private void handleClusterFailure(CannotGetJdbcConnectionException e) {
// 记录故障、告警、尝试重连等
log.error("数据库集群连接失败", e);
alertService.sendClusterAlert(e.getMessage());
}
}
6. 高可用架构模式对比
6.1 架构选型矩阵
|
架构模式 |
数据一致性 |
自动故障转移 |
性能影响 |
复杂度 |
适用场景 |
|
主从复制 |
最终一致 |
需要外部工具 |
低 |
低 |
读扩展、备份 |
|
主主复制 |
冲突风险 |
需要外部工具 |
中 |
中 |
写扩展、跨地域 |
|
MHA |
强一致 |
自动 |
中 |
中 |
传统业务系统 |
|
Group Replication |
强一致 |
自动 |
中高 |
高 |
金融、交易系统 |
|
InnoDB Cluster |
强一致 |
自动 |
中高 |
高 |
云原生、容器化 |
6.2 性能基准测试
@SpringBootTest
public class HighAvailabilityBenchmark {
@Autowired
private DataSource dataSource;
@Test
public void benchmarkWritePerformance() {
JdbcTemplate jdbc = new JdbcTemplate(dataSource);
// 测试不同复制模式下的写性能
long startTime = System.currentTimeMillis();
for (int i = 0; i < 1000; i++) {
jdbc.update("INSERT INTO test_table VALUES (?, ?)", i, "test_data");
}
long duration = System.currentTimeMillis() - startTime;
System.out.println("写入1000条记录耗时: " + duration + "ms");
}
@Test
public void testFailoverTime() throws InterruptedException {
// 模拟主节点故障,测量故障转移时间
failPrimaryNode();
long startTime = System.currentTimeMillis();
boolean recovered = waitForRecovery(30); // 30秒超时
long failoverTime = System.currentTimeMillis() - startTime;
assertThat(recovered).isTrue();
System.out.println("故障转移时间: " + failoverTime + "ms");
}
}
7. 故障转移与恢复策略
7.1 自动故障转移设计
@Component
public class AutomaticFailoverManager {
@Autowired
private HealthCheckService healthCheck;
@Autowired
private ClusterConfigManager configManager;
@Scheduled(fixedRate = 5000) // 每5秒检查一次
public void monitorClusterHealth() {
ClusterHealth health = healthCheck.checkClusterHealth();
if (health.getStatus() == HealthStatus.DEGRADED) {
handleDegradedCluster(health);
} else if (health.getStatus() == HealthStatus.DOWN) {
initiateFailover(health);
}
}
private void initiateFailover(ClusterHealth health) {
log.warn("检测到集群故障,开始故障转移");
try {
// 1. 停止应用写入
trafficManager.blockWrites();
// 2. 选举新的主节点
String newPrimary = electNewPrimary(health);
// 3. 重新配置集群
configManager.promoteToPrimary(newPrimary);
// 4. 更新应用配置
configManager.updateDataSourceConfig(newPrimary);
// 5. 恢复应用写入
trafficManager.resumeWrites();
log.info("故障转移完成,新主节点: {}", newPrimary);
} catch (Exception e) {
log.error("故障转移失败", e);
alertService.sendCriticalAlert("自动故障转移失败,需要手动干预");
}
}
private String electNewPrimary(ClusterHealth health) {
// 基于GTID位置、机器配置、负载等选举新主节点
return health.getAvailableNodes().stream()
.max(Comparator.comparing(Node::getReplicationLag)
.thenComparing(Node::getPerformanceScore))
.orElseThrow(() -> new IllegalStateException("无可用节点"))
.getHost();
}
}
7.2 数据一致性保障
@Service
public class DataConsistencyService {
/**
* 在故障转移前后保证数据一致性
*/
@Transactional
public void processWithConsistencyGuarantee(BusinessOperation operation) {
// 1. 记录操作开始
String operationId = recordOperationStart(operation);
try {
// 2. 执行业务操作
executeBusinessOperation(operation);
// 3. 确认操作完成
markOperationCompleted(operationId);
} catch (Exception e) {
// 4. 记录操作失败
markOperationFailed(operationId, e.getMessage());
throw e;
}
}
/**
* 故障恢复后的一致性检查
*/
public void verifyDataConsistencyAfterFailover() {
List<String> pendingOperations = findPendingOperations();
for (String opId : pendingOperations) {
try {
// 重新执行或补偿未完成的操作
compensateOperation(opId);
} catch (Exception e) {
log.error("操作补偿失败: {}", opId, e);
// 记录人工干预需要的异常
}
}
}
}
8. 监控与告警体系
8.1 全方位监控指标
# Prometheus监控配置
scrape_configs:
- job_name: 'mysql_cluster'
static_configs:
- targets: ['node1:9104', 'node2:9104', 'node3:9104']
metrics_path: /metrics
params:
collect[]:
- group_replication
- innodb
- replication
- engine_innodb_status
# 关键告警规则
groups:
- name: mysql_cluster_alerts
rules:
- alert: MySQLClusterMemberDown
expr: mysql_group_replication_member_status != 1
for: 1m
labels:
severity: critical
annotations:
summary: "MySQL集群节点异常"
- alert: MySQLReplicationLagHigh
expr: mysql_replication_slave_lag_seconds > 30
for: 2m
labels:
severity: warning
8.2 Java应用监控集成
@Component
public class ClusterMetricsExporter {
@Autowired
private DataSource dataSource;
@Autowired
private MeterRegistry meterRegistry;
private final Gauge replicationLag;
private final Counter failoverCount;
public ClusterMetricsExporter() {
// 注册自定义指标
this.replicationLag = Gauge.builder("mysql.replication.lag.seconds")
.description("复制延迟秒数")
.register(meterRegistry);
this.failoverCount = Counter.builder("mysql.failover.count")
.description("故障转移次数")
.register(meterRegistry);
}
@Scheduled(fixedRate = 10000)
public void updateMetrics() {
try {
JdbcTemplate jdbc = new JdbcTemplate(dataSource);
// 监控复制延迟
Long lag = jdbc.queryForObject(
"SELECT seconds_behind_master FROM information_schema.slave_status",
Long.class);
replicationLag.set(lag != null ? lag : 0);
// 监控集群状态
Integer memberCount = jdbc.queryForObject(
"SELECT COUNT(*) FROM performance_schema.replication_group_members WHERE member_state = 'ONLINE'",
Integer.class);
Gauge.builder("mysql.cluster.online.members")
.description("在线集群成员数")
.register(meterRegistry)
.set(memberCount);
} catch (Exception e) {
log.warn("集群指标收集失败", e);
}
}
}
9. 生产环境最佳实践
9.1 容量规划与性能优化
# 高可用环境优化配置 [mysqld] # 组复制优化 group_replication_flow_control_mode = "QUOTA" group_replication_member_expel_timeout = 5 # InnoDB优化 innodb_buffer_pool_size = 16G innodb_log_file_size = 2G innodb_flush_log_at_trx_commit = 2 # 复制优化 slave_parallel_workers = 8 slave_parallel_type = LOGICAL_CLOCK # 连接管理 max_connections = 1000 thread_cache_size = 100
9.2 备份与灾难恢复
@Service
public class DisasterRecoveryService {
/**
* 跨地域灾备策略
*/
public void setupCrossRegionDR() {
// 1. 主集群:上海
// 2. 同城灾备:上海另一个可用区
// 3. 异地灾备:北京
}
/**
* 定期灾备演练
*/
@Scheduled(cron = "0 0 2 * * SUN") // 每周日凌晨2点
public void performDisasterRecoveryDrill() {
log.info("开始灾备演练");
try {
// 1. 切换到灾备站点
switchToDRSite();
// 2. 验证应用功能
verifyApplicationFunctionality();
// 3. 切换回主站点
switchBackToPrimary();
log.info("灾备演练完成");
} catch (Exception e) {
log.error("灾备演练失败", e);
alertService.sendDRDrillAlert(e.getMessage());
}
}
/**
* 数据备份验证
*/
public boolean verifyBackupIntegrity(String backupId) {
// 验证备份文件的完整性和可恢复性
return backupVerifier.verifyBackup(backupId);
}
}
10. 云原生高可用架构
10.1 Kubernetes中的MySQL高可用
# mysql-cluster-statefulset.yaml
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: mysql-cluster
spec:
serviceName: mysql
replicas: 3
selector:
matchLabels:
app: mysql
template:
metadata:
labels:
app: mysql
spec:
containers:
- name: mysql
image: mysql:8.0
env:
- name: MYSQL_ROOT_PASSWORD
valueFrom:
secretKeyRef:
name: mysql-secret
key: root-password
ports:
- containerPort: 3306
volumeMounts:
- name: mysql-data
mountPath: /var/lib/mysql
- name: mysql-config
mountPath: /etc/mysql/conf.d
livenessProbe:
exec:
command: ["mysqladmin", "ping", "-h", "localhost"]
initialDelaySeconds: 30
periodSeconds: 10
readinessProbe:
exec:
command: ["mysql", "-h", "localhost", "-u", "root", "-p${MYSQL_ROOT_PASSWORD}", "-e", "SELECT 1"]
initialDelaySeconds: 5
periodSeconds: 5
volumeClaimTemplates:
- metadata:
name: mysql-data
spec:
accessModes: [ "ReadWriteOnce" ]
storageClassName: "fast-ssd"
resources:
requests:
storage: 100Gi
10.2 服务网格集成
@Configuration
public class ServiceMeshIntegration {
@Bean
public DataSource meshAwareDataSource() {
// 在服务网格环境中,通过服务发现连接数据库集群
return new MeshAwareDataSource();
}
}
@Component
public class DatabaseCircuitBreaker {
@Autowired
private CircuitBreakerRegistry circuitBreakerRegistry;
public <T> T executeWithCircuitBreaker(Supplier<T> databaseOperation) {
CircuitBreaker circuitBreaker = circuitBreakerRegistry
.circuitBreaker("database");
return circuitBreaker.executeSupplier(databaseOperation);
}
public void handleDatabaseOutage() {
// 数据库不可用时的降级策略
// 1. 返回缓存数据
// 2. 使用只读副本
// 3. 返回默认值并记录补偿操作
}
}
11. 总结
MySQL高可用架构是一个多层次、多维度的系统工程,需要从数据层、应用层到基础设施层的全面考虑:
- 架构选型:根据业务需求选择合适的HA方案
- 数据安全:保证故障场景下的数据一致性
- 自动运维:实现故障自动检测和转移
- 性能保障:在HA基础上保证系统性能
- 监控告警:建立全方位的监控体系
通过系统化的高可用架构设计,可以为业务提供坚实的数据基础保障,支撑企业在数字化时代的快速发展。


















 1214
1214

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











