




1. ZooKeeper简介:分布式系统的"协调员"
1.1 什么是ZooKeeper?
ZooKeeper是一个分布式的、开放源码的分布式应用程序协调服务,它提供了一组简单的原语,分布式应用程序可以基于这些原语实现更高级的服务,如同步、配置维护、分组和命名等。
// ZooKeeper的核心理念:提供分布式环境下的协调服务
public class ZooKeeperEssence {
// 类似于现实世界中的"协调员"
public class CoordinatorAnalogy {
// 会议协调员:管理会议时间、地点、参与者
// ZooKeeper:管理分布式系统的状态、配置、锁
}
// 设计目标:简单、可靠、有序、快速
public enum DesignGoals {
SIMPLICITY, // 简单的数据模型和API
RELIABILITY, // 高可用性,容错能力强
ORDERING, // 全局有序的操作序列
SPEED // 读操作高性能,写操作强一致
}
}
1.2 ZooKeeper的数据模型:层次化命名空间
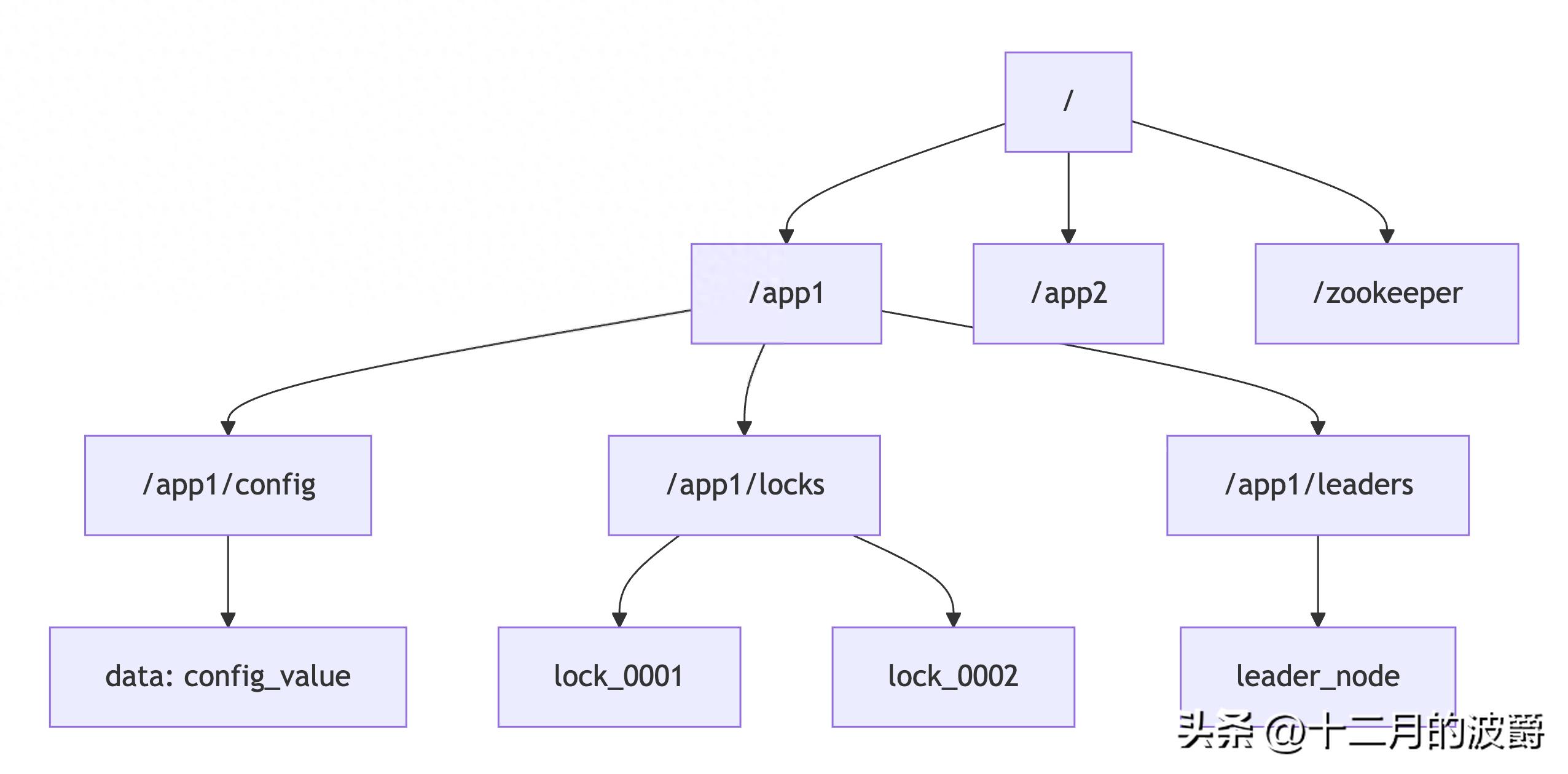
ZooKeeper的数据模型类似于文件系统,采用层次化的目录树结构:
// ZooKeeper数据节点的Java表示
public class ZNodeStructure {
// 每个znode包含的数据和元数据
public class ZNode {
private String path; // 节点路径,如"/app/config"
private byte[] data; // 节点数据(最大1MB)
private List<ACL> acl; // 访问控制列表
private Stat stat; // 元数据信息
// 节点类型
private CreateMode mode; // 持久节点、临时节点、顺序节点等
}
// 节点类型详解
public enum ZNodeTypes {
PERSISTENT, // 持久节点:客户端断开后依然存在
EPHEMERAL, // 临时节点:客户端会话结束自动删除
PERSISTENT_SEQUENTIAL,// 持久顺序节点:自动添加顺序编号
EPHEMERAL_SEQUENTIAL // 临时顺序节点:临时+顺序
}
}
2. ZAB协议:ZooKeeper的共识引擎
2.1 ZAB协议的设计目标
ZAB(ZooKeeper Atomic Broadcast)协议是专门为ZooKeeper设计的崩溃恢复的原子广播协议,它保证了ZooKeeper集群中所有节点的数据一致性。
public class ZABDesignGoals {
// ZAB要解决的核心问题
public class CoreProblems {
// 1. 领导者选举:集群启动或Leader故障时快速选出新Leader
// 2. 原子广播:确保所有更新操作以相同顺序应用到所有节点
// 3. 崩溃恢复:处理Leader故障时的数据一致性
}
// 与Paxos/Raft的对比
public class Comparison {
// 相似点:都基于多数派原则,都有领导者选举
// 不同点:ZAB更关注消息顺序,为ZooKeeper特定场景优化
}
}
2.2 ZAB协议的核心概念
节点角色定义
public class ZABRoles {
// 领导者(Leader)
public class Leader {
// 职责:
// 1. 处理所有写请求
// 2. 提出提案(Proposal)
// 3. 维护与Follower的心跳
// 4. 管理事务日志的复制
}
// 跟随者(Follower)
public class Follower {
// 职责:
// 1. 响应Leader的心跳
// 2. 参与写操作的投票
// 3. 接受Leader的提案并应用
// 4. 处理客户端的读请求
}
// 观察者(Observer)
public class Observer {
// 特殊角色:
// 1. 不参与投票,只同步数据
// 2. 处理读请求,提高读性能
// 3. 不影响写操作的可用性
}
}
ZAB协议的两个阶段

ZAB协议主要分为两个模式:消息广播(正常情况)和崩溃恢复(异常情况)。
2.3 崩溃恢复模式(选举与同步)
领导者选举过程
public class LeaderElectionProcess {
// ZAB选举算法的核心:Fast Leader Election
public class FastLeaderElection {
// 选举状态
public enum ElectionState {
LOOKING, // 寻找Leader状态
FOLLOWING, // 跟随者状态
LEADING // 领导者状态
}
// 投票规则:基于(zxid, serverId)的优先级
public class Vote {
private long zxid; // 最后事务ID,越大优先级越高
private long serverId; // 服务器ID,zxid相同时比较
public boolean isBetterThan(Vote other) {
if (this.zxid > other.zxid) return true;
if (this.zxid == other.zxid && this.serverId > other.serverId) return true;
return false;
}
}
// 选举流程
public void startElection() {
// 1. 每个节点初始为自己投票
Vote myVote = new Vote(getLastZxid(), getMyServerId());
// 2. 广播投票信息给所有节点
broadcastVote(myVote);
// 3. 收集其他节点的投票
List<Vote> receivedVotes = collectVotes();
// 4. 统计投票,如果某个节点获得多数派支持
if (hasMajority(receivedVotes)) {
// 5. 宣布选举结果,进入数据同步阶段
announceLeader();
}
}
}
}
数据同步阶段
public class DataSynchronization {
// 新Leader选举后的数据同步过程
public class SyncProcess {
// 不同的同步策略
public enum SyncStrategy {
SNAP, // 全量快照同步
DIFF, // 差异日志同步
TRUNC // 日志截断同步
}
public void synchronizeData() {
// 1. Leader确定每个Follower需要同步的数据范围
for (Follower follower : followers) {
long followerZxid = follower.getLastZxid();
long leaderZxid = getLastZxid();
// 2. 根据Follower的落后程度选择同步策略
SyncStrategy strategy = chooseStrategy(followerZxid, leaderZxid);
// 3. 执行同步
switch (strategy) {
case SNAP:
sendSnapshot(follower); // 发送完整快照
break;
case DIFF:
sendDiffLogs(follower); // 发送差异日志
break;
case TRUNC:
truncateLogs(follower); // 截断多余日志
break;
}
}
// 4. 所有Follower同步完成后,进入消息广播模式
switchToBroadcastMode();
}
}
}
2.4 消息广播模式(正常操作)
两阶段提交过程
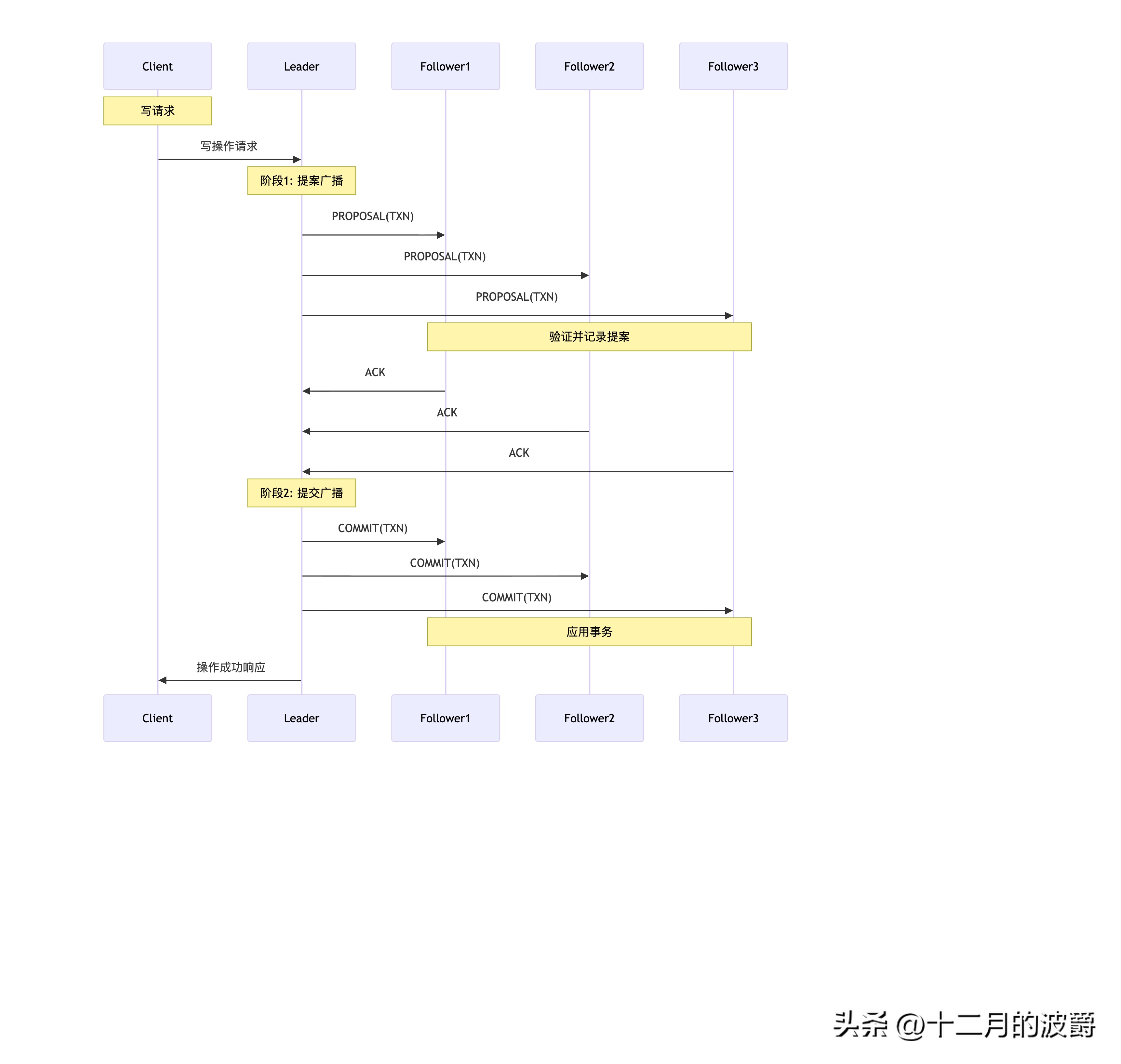
public class MessageBroadcast {
// 事务ID(ZXID)结构
public class Zxid {
private long epoch; // 选举周期(32位)
private long counter; // 事务计数器(32位)
// ZXID = (epoch << 32) | counter
// 保证全局唯一且严格递增
}
// 消息广播的详细流程
public class BroadcastProcess {
public void broadcastTransaction(Transaction txn) {
// 1. Leader为事务生成ZXID
long zxid = generateNextZxid();
txn.setZxid(zxid);
// 2. 将事务写入本地日志(WAL)
writeToLog(txn);
// 3. 广播PROPOSAL给所有Follower
Proposal proposal = new Proposal(zxid, txn);
for (Follower follower : followers) {
sendProposal(follower, proposal);
}
// 4. 等待多数派Follower的ACK
if (waitForMajorityAck(zxid)) {
// 5. 多数派确认后,广播COMMIT
broadcastCommit(zxid);
// 6. 应用事务到内存数据库
applyToMemoryDB(txn);
// 7. 响应客户端
sendResponseToClient(txn);
} else {
// 多数派未确认,操作失败
handleFailure(txn);
}
}
}
}
3. ZooKeeper的典型应用场景
3.1 分布式锁实现
// 基于ZooKeeper的分布式互斥锁
public class DistributedLock {
private ZooKeeper zk;
private String lockPath;
private String currentLockPath;
/**
* 获取分布式锁
* @param timeout 超时时间
* @return 是否获取成功
*/
public boolean lock(long timeout) throws Exception {
// 创建临时顺序节点
currentLockPath = zk.create(lockPath + "/lock-",
null,
ZooDefs.Ids.OPEN_ACL_UNSAFE,
CreateMode.EPHEMERAL_SEQUENTIAL);
// 获取锁的所有候选节点
List<String> lockNodes = zk.getChildren(lockPath, false);
Collections.sort(lockNodes); // 按序列号排序
// 检查当前节点是否是最小序列号(获得锁)
if (currentLockPath.equals(lockPath + "/" + lockNodes.get(0))) {
return true; // 获得锁
}
// 监听前一个节点
String previousNode = getPreviousNode(currentLockPath, lockNodes);
if (previousNode != null) {
CountDownLatch latch = new CountDownLatch(1);
Stat stat = zk.exists(lockPath + "/" + previousNode,
new LockWatcher(latch));
if (stat != null) {
// 等待前一个节点释放锁(或超时)
return latch.await(timeout, TimeUnit.MILLISECONDS);
}
}
return true;
}
/**
* 释放锁
*/
public void unlock() throws Exception {
if (currentLockPath != null) {
zk.delete(currentLockPath, -1);
currentLockPath = null;
}
}
// 监听器:当前一个节点删除时(锁释放)通知
private static class LockWatcher implements Watcher {
private CountDownLatch latch;
public LockWatcher(CountDownLatch latch) {
this.latch = latch;
}
@Override
public void process(WatchedEvent event) {
if (event.getType() == Event.EventType.NodeDeleted) {
latch.countDown();
}
}
}
}
3.2 配置管理中心
// 基于ZooKeeper的分布式配置管理
@Service
public class ConfigCenter {
@Autowired
private ZooKeeper zk;
private Map<String, String> configCache = new ConcurrentHashMap<>();
private Map<String, List<ConfigListener>> listeners = new ConcurrentHashMap<>();
/**
* 获取配置值
*/
public String getConfig(String key) throws Exception {
// 先从缓存读取
if (configCache.containsKey(key)) {
return configCache.get(key);
}
// 缓存不存在,从ZooKeeper读取
String path = "/config/" + key;
byte[] data = zk.getData(path, new ConfigWatcher(key), null);
String value = new String(data, StandardCharsets.UTF_8);
// 更新缓存
configCache.put(key, value);
return value;
}
/**
* 更新配置
*/
public void updateConfig(String key, String value) throws Exception {
String path = "/config/" + key;
byte[] data = value.getBytes(StandardCharsets.UTF_8);
// 检查节点是否存在
if (zk.exists(path, false) != null) {
zk.setData(path, data, -1); // 更新现有节点
} else {
zk.create(path, data, ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
}
// 本地缓存会在Watcher中更新
}
/**
* 注册配置变更监听器
*/
public void addConfigListener(String key, ConfigListener listener) {
listeners.computeIfAbsent(key, k -> new ArrayList<>()).add(listener);
}
// 配置变更监听器
private class ConfigWatcher implements Watcher {
private String key;
public ConfigWatcher(String key) {
this.key = key;
}
@Override
public void process(WatchedEvent event) {
if (event.getType() == Event.EventType.NodeDataChanged) {
try {
// 重新读取配置
String path = "/config/" + key;
byte[] data = zk.getData(path, this, null);
String newValue = new String(data, StandardCharsets.UTF_8);
// 更新缓存
configCache.put(key, newValue);
// 通知监听器
notifyListeners(key, newValue);
} catch (Exception e) {
logger.error("处理配置变更失败", e);
}
}
}
}
}
3.3 领导者选举服务
// 基于ZooKeeper的领导者选举
@Service
public class LeaderElectionService {
private ZooKeeper zk;
private String electionPath = "/election";
private String currentNodePath;
private volatile boolean isLeader = false;
@PostConstruct
public void init() throws Exception {
// 确保选举路径存在
if (zk.exists(electionPath, false) == null) {
zk.create(electionPath, null, ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
}
// 参与选举
participateElection();
}
private void participateElection() throws Exception {
// 创建临时顺序节点
currentNodePath = zk.create(electionPath + "/node-",
null,
ZooDefs.Ids.OPEN_ACL_UNSAFE,
CreateMode.EPHEMERAL_SEQUENTIAL);
// 检查当前节点是否是最小节点(领导者)
checkLeadership();
}
private void checkLeadership() throws Exception {
List<String> nodes = zk.getChildren(electionPath, false);
Collections.sort(nodes);
String smallestNode = nodes.get(0);
String currentNode = currentNodePath.substring(electionPath.length() + 1);
if (currentNode.equals(smallestNode)) {
// 当前节点是领导者
becomeLeader();
} else {
// 当前节点是跟随者,监听前一个节点
becomeFollower(nodes);
}
}
private void becomeLeader() {
isLeader = true;
logger.info("当前节点成为领导者");
// 执行领导者职责
startLeaderTasks();
}
private void becomeFollower(List<String> nodes) throws Exception {
isLeader = false;
String currentNode = currentNodePath.substring(electionPath.length() + 1);
// 找到前一个节点
int currentIndex = nodes.indexOf(currentNode);
String previousNode = nodes.get(currentIndex - 1);
// 监听前一个节点
String previousNodePath = electionPath + "/" + previousNode;
zk.exists(previousNodePath, new LeaderWatcher());
logger.info("当前节点成为跟随者,监听节点: {}", previousNode);
}
private class LeaderWatcher implements Watcher {
@Override
public void process(WatchedEvent event) {
if (event.getType() == Event.EventType.NodeDeleted) {
try {
// 前一个节点消失,重新检查领导权
checkLeadership();
} catch (Exception e) {
logger.error("处理领导者变更失败", e);
}
}
}
}
public boolean isLeader() {
return isLeader;
}
}
4. ZooKeeper集群部署与配置
4.1 集群配置详解
# zoo.cfg 配置文件示例 # 基本配置 tickTime=2000 initLimit=10 syncLimit=5 dataDir=/var/lib/zookeeper clientPort=2181 # 集群节点配置 server.1=192.168.1.101:2888:3888 server.2=192.168.1.102:2888:3888 server.3=192.168.1.103:2888:3888 server.4=192.168.1.104:2888:3888:observer # 观察者节点 server.5=192.168.1.105:2888:3888:observer # 观察者节点 # 高级配置 autopurge.snapRetainCount=3 autopurge.purgeInterval=24 maxClientCnxns=60 minSessionTimeout=4000 maxSessionTimeout=40000
4.2 集群监控与管理
// ZooKeeper集群监控工具
@Component
public class ZKClusterMonitor {
@Autowired
private ZooKeeper zk;
/**
* 获取集群状态
*/
public ClusterStatus getClusterStatus() throws Exception {
ClusterStatus status = new ClusterStatus();
// 获取集群节点信息
Stat stat = new Stat();
byte[] data = zk.getData("/", false, stat);
status.setZxid(stat.getCzxid());
status.setVersion(stat.getVersion());
status.setNodeCount(stat.getNumChildren());
// 检查领导者
status.setLeaderId(findLeaderId());
// 获取各个服务器状态
status.setServerStats(getServerStats());
return status;
}
/**
* 监控关键指标
*/
@Scheduled(fixedRate = 30000)
public void monitorMetrics() {
try {
// 监控连接数
monitorConnections();
// 监控延迟
monitorLatency();
// 监控数据大小
monitorDataSize();
// 监控Watch数量
monitorWatchCount();
} catch (Exception e) {
logger.error("监控ZooKeeper集群失败", e);
}
}
// 四字命令监控
public String sendFourLetterCommand(String command) throws IOException {
Socket socket = new Socket("localhost", 2181);
PrintWriter out = new PrintWriter(socket.getOutputStream(), true);
BufferedReader in = new BufferedReader(new InputStreamReader(socket.getInputStream()));
out.println(command);
StringBuilder response = new StringBuilder();
String line;
while ((line = in.readLine()) != null) {
response.append(line).append("\n");
}
socket.close();
return response.toString();
}
}
5. ZAB协议的实际应用案例
5.1 Apache Kafka的控制器选举
// Kafka使用ZooKeeper进行控制器选举
public class KafkaControllerElection {
// 控制器节点路径
private static final String CONTROLLER_PATH = "/controller";
/**
* Kafka控制器的选举过程
*/
public void electController() throws Exception {
ZooKeeper zk = getZooKeeper();
// 尝试创建控制器节点
String controllerData = String.format("{\"version\":1,\"brokerid\":%d,\"timestamp\":%d}",
brokerId, System.currentTimeMillis());
try {
// 创建临时节点,成功创建的Broker成为控制器
zk.create(CONTROLLER_PATH,
controllerData.getBytes(),
ZooDefs.Ids.OPEN_ACL_UNSAFE,
CreateMode.EPHEMERAL);
// 成为控制器
becomeController();
} catch (KeeperException.NodeExistsException e) {
// 节点已存在,当前Broker不是控制器
// 设置监听器,监听控制器节点变化
zk.exists(CONTROLLER_PATH, new ControllerWatcher());
}
}
private class ControllerWatcher implements Watcher {
@Override
public void process(WatchedEvent event) {
if (event.getType() == Event.EventType.NodeDeleted) {
try {
// 控制器节点被删除,重新选举
electController();
} catch (Exception e) {
logger.error("控制器选举失败", e);
}
}
}
}
}
5.2 Hadoop YARN的资源管理器
// YARN ResourceManager使用ZooKeeper实现高可用
public class YARNResourceManagerHA {
private static final String RM_STATE_PATH = "/yarn/rm-state";
private static final String RM_ACTIVE_PATH = "/yarn/rm-active";
/**
* ResourceManager的Active-Standby切换
*/
public void startHA() throws Exception {
// 1. 启动时尝试成为Active RM
attemptToBecomeActive();
// 2. 如果失败,成为Standby RM并监听Active节点
becomeStandbyAndWatch();
}
private void attemptToBecomeActive() throws Exception {
try {
// 创建临时节点,成功则成为Active
zk.create(RM_ACTIVE_PATH,
getRMInfo().getBytes(),
ZooDefs.Ids.OPEN_ACL_UNSAFE,
CreateMode.EPHEMERAL);
// 成为Active RM
transitionToActive();
} catch (KeeperException.NodeExistsException e) {
// 已有Active RM,当前成为Standby
transitionToStandby();
}
}
private void becomeStandbyAndWatch() throws Exception {
// 监听Active节点
zk.exists(RM_ACTIVE_PATH, new ActiveRMWatcher());
// 定期检查状态
scheduledHealthCheck();
}
private class ActiveRMWatcher implements Watcher {
@Override
public void process(WatchedEvent event) {
if (event.getType() == Event.EventType.NodeDeleted) {
// Active RM故障,尝试接管
try {
attemptToBecomeActive();
} catch (Exception e) {
logger.error("切换为Active RM失败", e);
}
}
}
}
}
6. ZooKeeper最佳实践与性能优化
6.1 性能优化策略
public class ZKPerformanceOptimization {
// 1. 合理设置会话超时时间
public void optimizeSessionTimeout() {
// 太短:频繁会话过期,影响稳定性
// 太长:故障检测延迟,影响可用性
// 推荐:根据网络环境和业务需求调整
System.setProperty("zookeeper.session.timeout", "20000");
}
// 2. 批量操作优化
public void batchOperations() throws Exception {
// 避免频繁的小操作,使用批量接口
List<Op> ops = new ArrayList<>();
ops.add(Op.create("/path1", "data1".getBytes(),
ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT));
ops.add(Op.setData("/path2", "data2".getBytes(), -1));
ops.add(Op.delete("/path3", -1));
zk.multi(ops); // 原子性批量操作
}
// 3. 合理使用Watch
public void optimizeWatchUsage() {
// 避免设置过多Watch,每个Watch都消耗资源
// 使用exists/getData/getChildren时谨慎设置Watch
// 考虑使用Curator等高级客户端,提供更智能的Watch管理
}
// 4. 数据序列化优化
public void dataSerialization() {
// 使用高效的序列化方案
// 避免存储大对象,ZooKeeper适合存储小量配置数据
// 推荐:Protocol Buffers、Avro等高效序列化工具
}
}
6.2 常见问题与解决方案
public class ZKProblemSolutions {
// 1. 脑裂问题处理
public void splitBrainPrevention() {
// ZAB协议通过多数派原则避免脑裂
// 部署奇数个节点(3、5、7)
// 确保网络分区时最多只有一个分区能形成多数派
}
// 2. 数据一致性保证
public void dataConsistency() {
// 写操作:通过Leader序列化,保证强一致性
// 读操作:默认最终一致性,可设置sync()强制同步读
zk.sync("/path", new SyncCallback() {
@Override
public void processResult(int rc, String path, Object ctx) {
// 同步完成后执行读操作,保证读到最新数据
}
}, null);
}
// 3. 客户端连接管理
public void connectionManagement() {
// 使用连接池避免频繁创建连接
// 实现连接断开自动重连机制
// 监控连接状态,及时处理异常
}
}
总结
ZooKeeper通过ZAB协议提供了一个高度可靠的分布式协调服务,它的核心价值在于:
- 强一致性保证:ZAB协议确保所有更新操作按顺序应用到所有节点
- 高可用性:基于多数派的领导者选举和故障恢复机制
- 简单易用:清晰的数据模型和API设计
- 丰富的应用场景:分布式锁、配置管理、领导者选举等
实际应用建议:
- 对于需要强一致性的协调场景,ZooKeeper是优秀选择
- 合理设计znode结构,避免深层次嵌套
- 注意会话管理和Watch使用,避免资源泄露
- 在生产环境部署奇数个节点,确保高可用性
ZooKeeper虽然在新一代分布式系统中面临Etcd等组件的竞争,但其成熟稳定、生态丰富的特点,使其在很多关键业务系统中仍然发挥着不可替代的作用。


















 736
736

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











