






好久没有发帖咯,对于高低字节,高位与低位的问题,于今天发帖分享一下。如果有用,请不吝点赞则个。。QAQ
好了话不多说,既然标题写了这三个,那么就一个一个开始吧,首先是the first ------大小端---吗?
不,of cruse NO!!!
首先是高位与低位,因为大小端的定义要靠高低位和高低字节理解啦~
1、高位与低位
既然是高位与低位,那先搞清楚什么是位。
比如初学者常听到的32位操作系统,64位操作系统,那位是啥呢? 32位与64位又是什么呢?
此处贴图一张: 
so,32位就是32个0或1组成的长度,64位同理。
既然搞懂了位,那什么是高低位呢?
举例说明:
我用二进制表示数字185(题主本人185..信不信由你);
转换可得10进制185等于二进制1011 1001,因为二进制进位是从右往左(类似于10进制的185,左边也是高位)所以1011便是高4位,1001就是低4位。
恭喜,你已经领悟了此门绝学的三分之一,继续往下看,无需自宫哈~
2、高字节与低字节
再次贴图~

so,上述中的红色字体1011 1001便是一个完整的字节。那什么是高字节和低字节?
我们先将1011 1001转为16进制得到0xB9,emmm...报意思换一个。。。
比如我有一个16进制的数字0x1234(10进制为4660),
我们先将它转为二进制得到 0001 0010 0011 0100。其中左边8位0001 0010对应的便是0x12的二进制表示,既然我们上面已经知道了左边表示高位,那么对于0x1234, 0x12便是高8位,0x34为低8位。(16进制0x****同样默认左边是高位)
再次恭喜,您的修炼已臻化境...只消弄明白最后的三分之一即可白日飞升~
3、大小端
相信大家都知道大小端既是常用于计算机中的两种相反的数据存储模式,定义也都知道:
大端存储:低地址存储高位字节,高地址存储低位字节。
小端存储:低地址存储低位字节,高地址存储高位字节。
既然我们已经弄清楚了什么是高位字节,什么是低位字节,我们只需要知道高低地址即可。
计算机以字节为基本存储单位,一般都是从低地址开始,从低到高(也就是低地址在前)那么,以0x1234再次举例:
大端存储:低地址存储高位字节,那低地址存储高8位的0x12,紧邻的高地址存储低8位的0x34,如果用大端存储的计算机打印出来这个字节数组,便应该先打印0x12,再打印0x34。
(题主的电脑为小端存储,只是做了个简单转换)
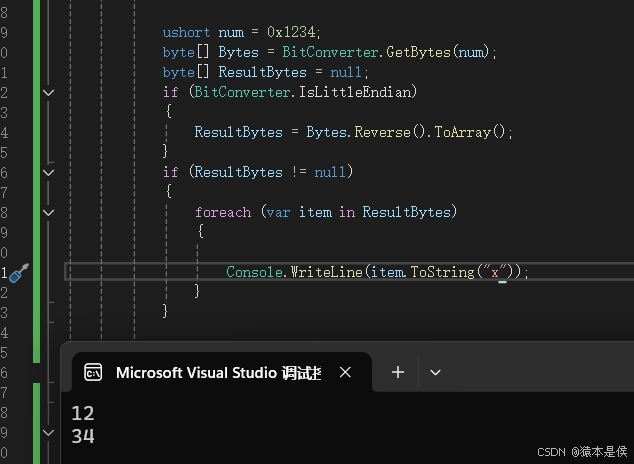
小端存储:低地址存储低位字节,即0x34,高地址存储高位字节, 鸡...(严肃), 即0x12;
那么电脑打印出来应为34在前,34,12。看图:
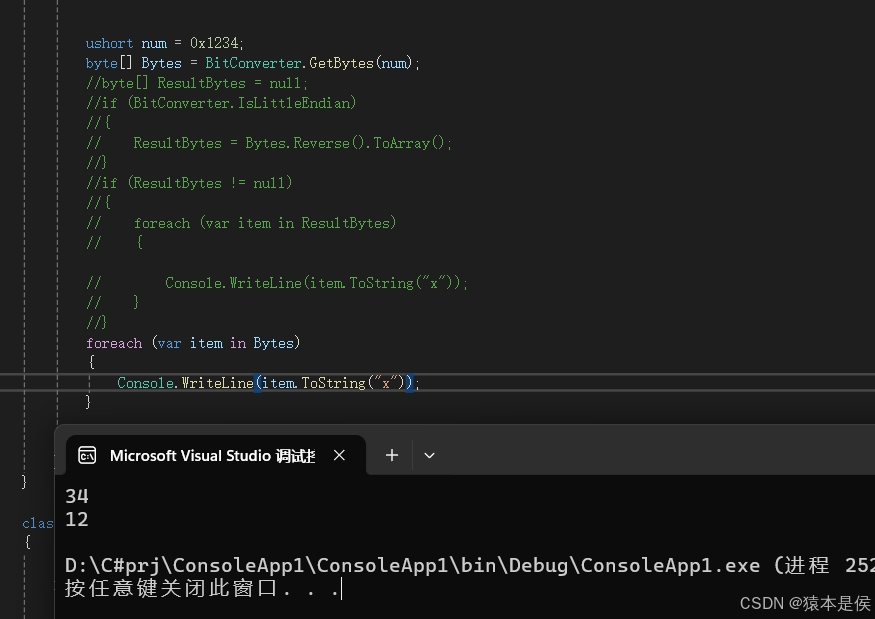
至此~恭喜道友解锁全部功法,respect~
还望不吝点赞则个~

















 876
876

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









