



1、进程、线程、协程
进程:
process
进程是资源分配的基本单位,包括内存、文件描述符等。是计算机运行程序的一个独立单位。每个进程具有自己独立的内存空间,进程之间不能直接访问彼此的数据。
线程:
thread
cpu调度的基本单位,一个进程可以包含多个线程,线程除了有一些自己的必要的堆栈空间之外,其他资源都是共享线程中的,共享的资源包括:
- 所有线程共享相同的虚拟地址空间,即它们可以访问同样的代码段、数据段和堆栈段
- 文件描述符:进程打开的文件描述符进程级别的资源,所以同一个进程中的线程可以共享打开的文件描述符,意味着它们可以同时读写同一个文件
- 全局变量:全局变量是进程级别的变量,可被同一个进程中的所有线程访问和修改
- 静态变量:静态变量也是进程级别的变量,在同一个进程中的线程之间共享内存空间
- 进程id、进程组id
独占的资源:
- 线程id
- 寄存器组的值
- 线程堆栈
- 错误返回码
- 信号屏蔽码
- 线程的优先级
协程:
用户态的线程,可以通过用户程序创建、删除。协程切换时不需要切换内核态 ,上下文切换的开销比线程和进程更小。协程是用户态的轻量级线程,允许在程序中执行非阻塞操作。
协程与线程的区别
- 线程是操作系统的概念,而协程是程序级的概念。线程由操作系统调度执行,每个线程都有自己的执行上下文,包括程序计数器、寄存器等。而协程由程序自身控制。
- 多个线程之间通过切换执行的方式实现并发。线程切换时需要保存和恢复上下文,涉及到上下文切换的开销。而协程切换时不需要操作系统的介入,只需保存和恢复自身的上下文,切换开销较小。
- 线程是抢占式的并发,即操作系统可以随时剥夺一个线程的执行权。而协程是合作式的并发,协程的执行权由程序自身决定,只有当协程主动让出执行权时,其他协程才会得到执行机会。
线程的优点:
- 创建一个新线程的代价要比创建一个新进程小的多
- 线程之间的切换相较于进程之间的切换需要操作系统做的工作很少
- 线程占用的资源要比进程少很多
- 能充分利用多处理器的可并行数量
线程的缺点
共享内存带来的安全性问题、缺乏隔离性、复杂的同步机制、调试困难等
有栈协程和无栈协程
- 有栈协程为每个协程分配独立的堆栈。同一协程的局部变量存储在这个堆栈上。切换协程时,需要保存当前协程的堆栈上下文,恢复目标协程的堆栈上下文。这意味着在切换时需要一定的开销(保存和恢复堆栈信息),但不涉及操作系统内核。Go语言中的有栈协程:goroutines
- 无栈协程不为每个协程单独分配堆栈,而是将局部变量和协程状态保存在共享的堆中。切换时通过某种状态机制进行,而无需显式的上下文切换。JavaScript中的无栈协程async/await,用于异步编程,状态机来管理,await中断当前执行,把上下文存储在公共内存中,后续某个点时继续。
2、Go语言–垃圾回收
GC-垃圾回收-Garbage Collection

(1)Go v1.3之前的标记-清除:
1、暂停业务逻辑,找到不可达的对象,和可达对象
2、开始标记,程序找出它所有可达的对象,并做上标记
3、标记完了之后,然后开始清除未标记的对象
4、停止暂停,让程序继续跑。然后循环重复这个过程,直到process程序生命周期结束
标记-清除的缺点:
1、STW(stop the world):在标记和清除过程中,程序会暂停所有的正常执行操作,对于实时系统会出现短暂的应用卡顿
2、标记需要扫描整个heap(堆,内存空间),查看每一个对象是否仍可被程序引用,在大型应用程序中,这个过程可能会耗费大量时间资源
3、清除数据会产生heap碎片:在清除阶段,已标记为无需保留的对象会被去掉,留下的不连续的内存空间称为碎片。如果堆中碎片过多,可能造成内存分配效率低,尤其是下一次需要分配大块内存时。
为了减少STW的时间,对“标记-清除”中的第三步和第四步进行了替换。
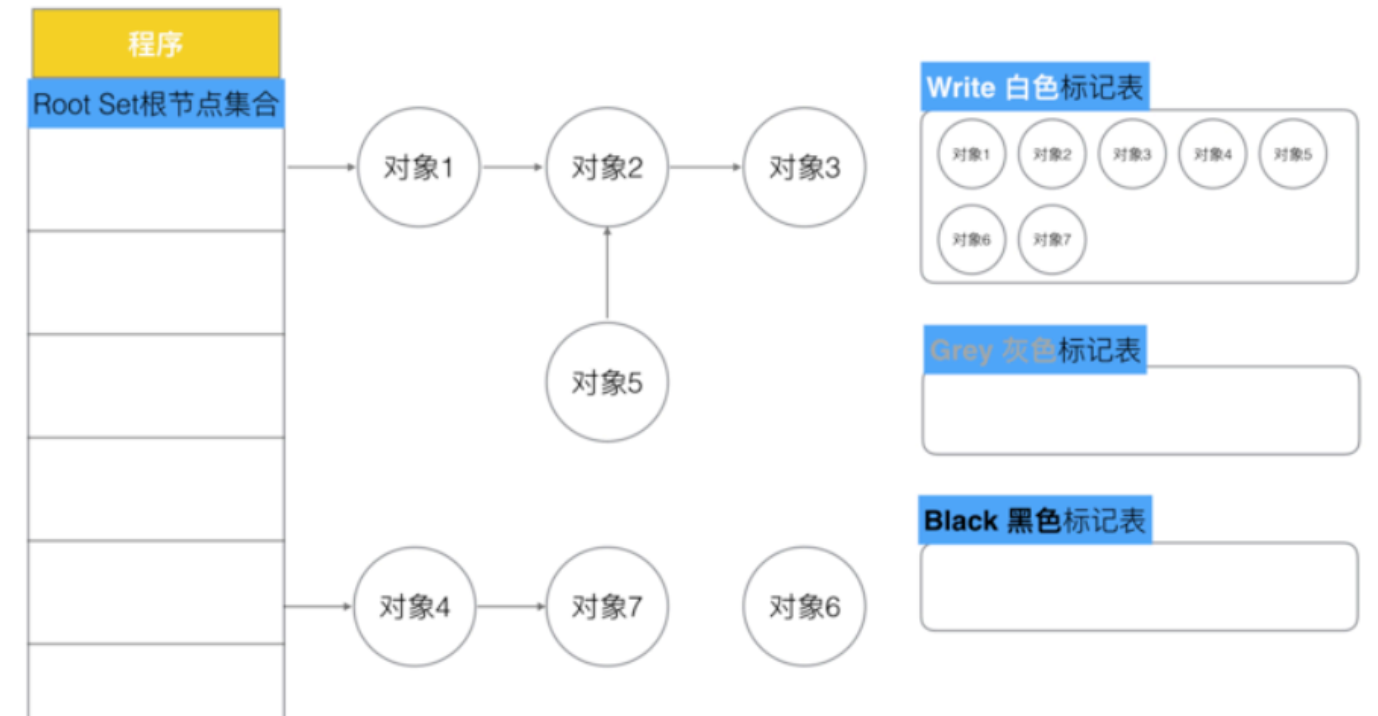
(2)Go v1.5 三色标记法
- **白色:**未被访问的对象【待回收】
- 灰色:已被访问但其引用尚未被完全扫描的对象【正在检查】
- 黑色:已被访问且其所有引用都已被扫描的对象【不可回收】
1、把新创建的对象,默认的颜色都标记为“白色”
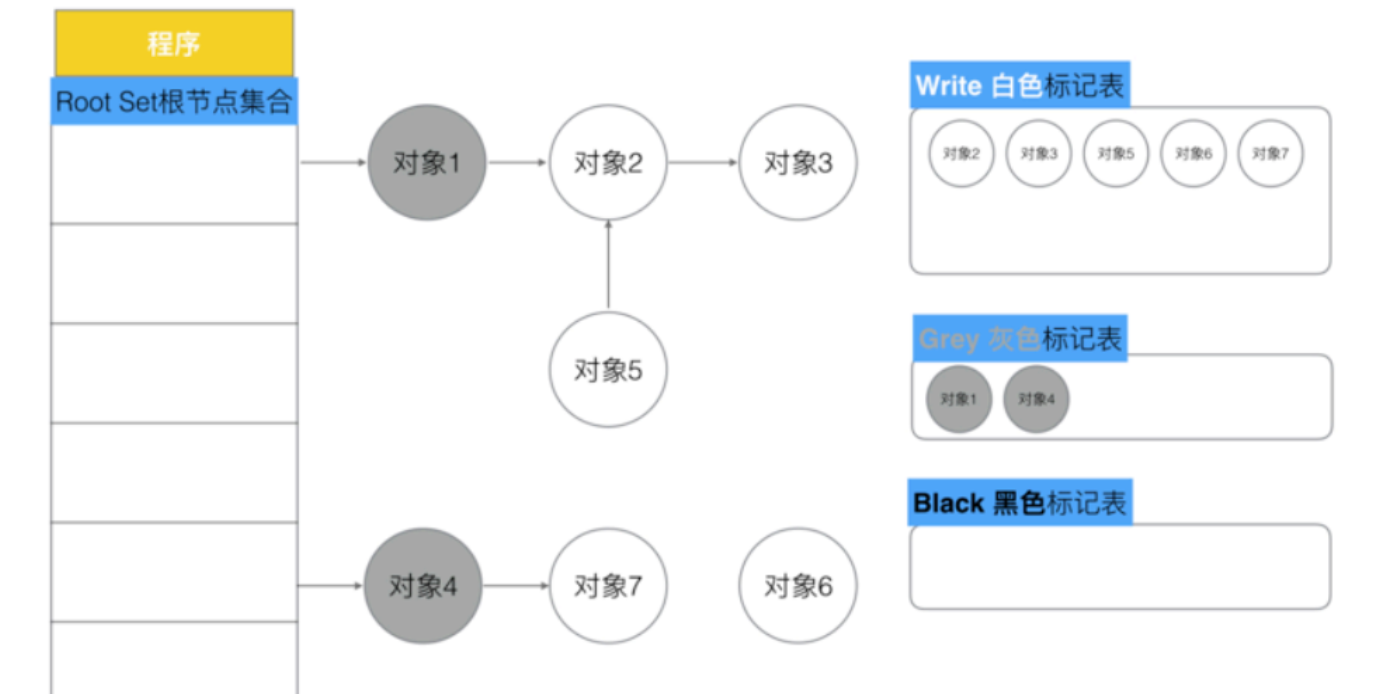
2、每次GC回收开始,然后从根节点开始遍历所有对象,把遍历到的对象从白色集合放入“灰色”集合
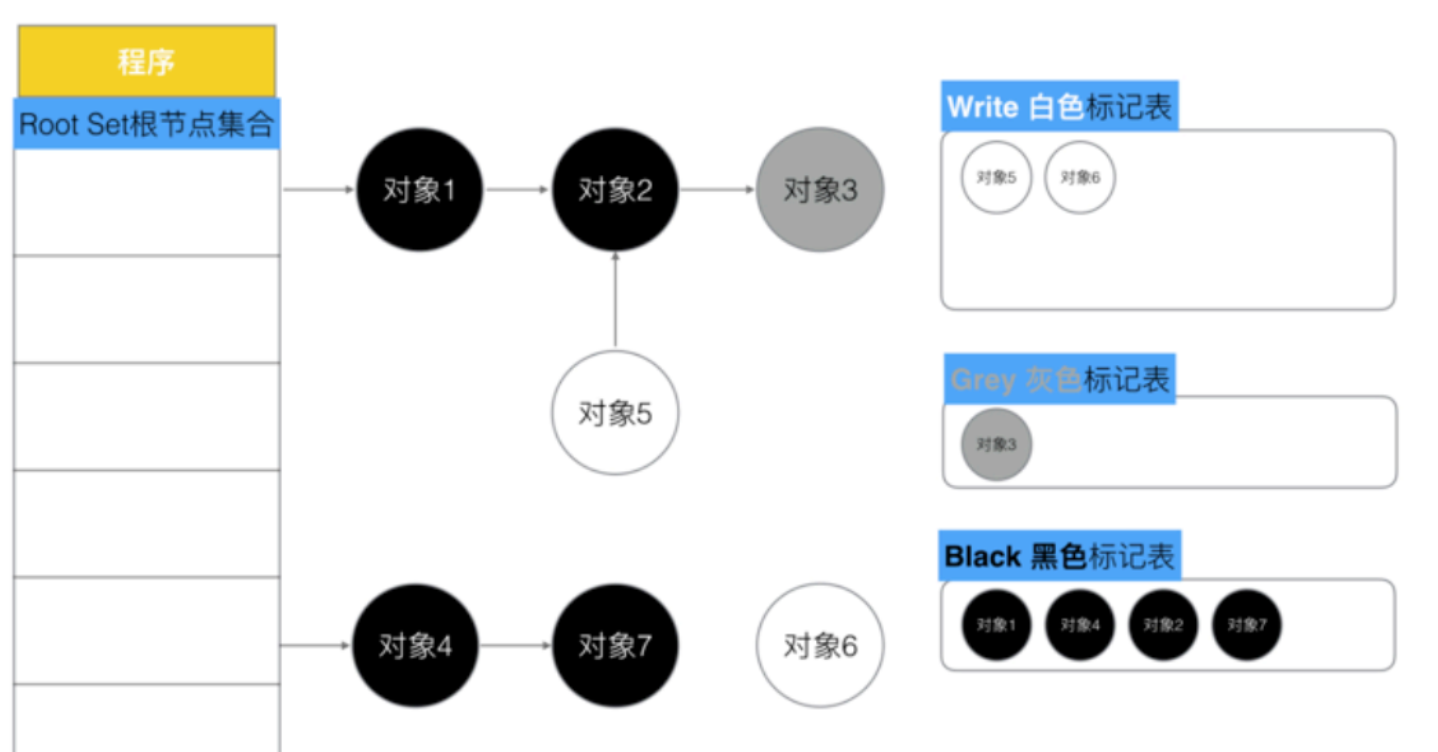
3、遍历灰色集合,将灰色对象引用的对象从白色集合放入灰色集合,之后将此灰色对象放入到黑色集合

4、重复第三步,直到灰色无任何对象
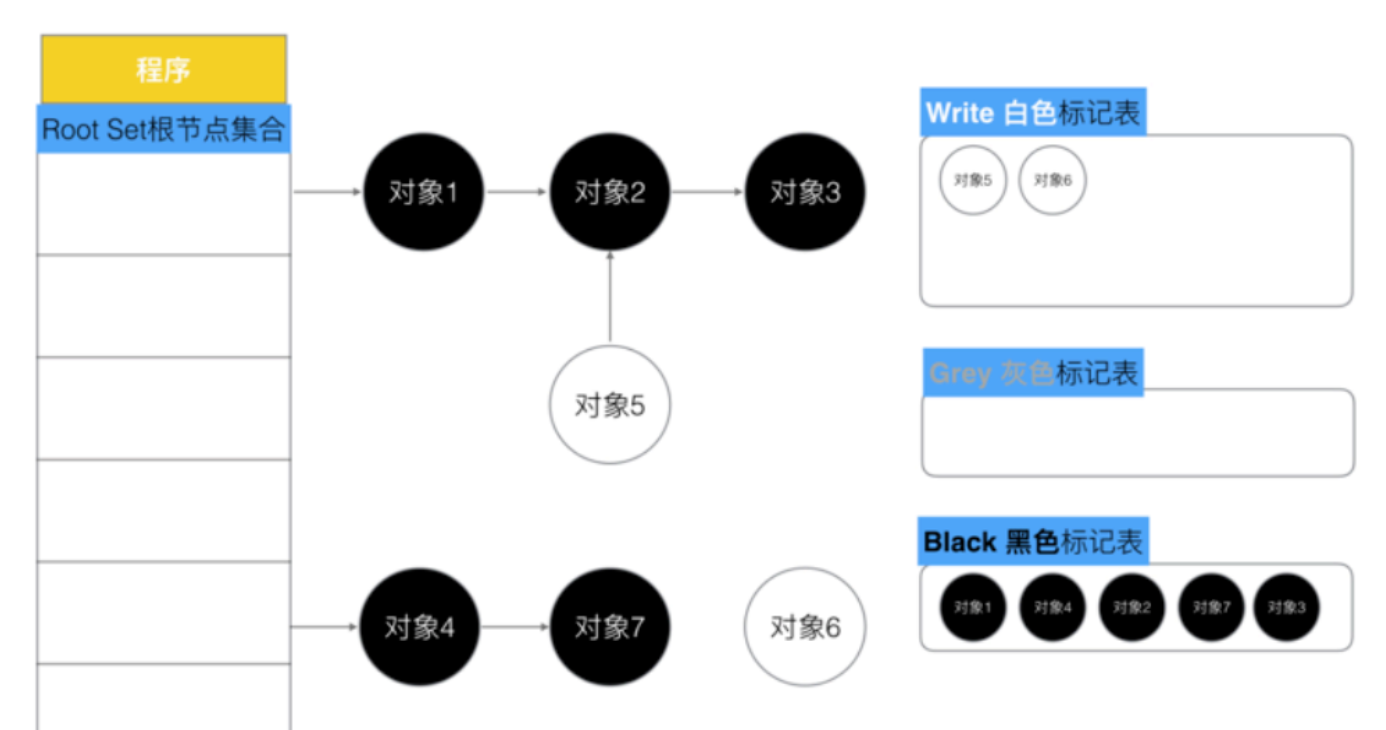
5、回收所有的白色标记的对象,回收垃圾
三色标记法不采用STW时可能出现的问题:
需同时满足如下条件:
1、白色对象被黑色对象引用:
如果在标记期间,程序动态地创建了指向白色对象的新引用,而白色对象被黑色对象引用,可能没有被标记为灰色,这个白色对象就不被视为可达对象,从而可能错误地被回收
2、灰色对象对白色对象的引用丢失
一个仍然存在的对象但因引用关系错变而被错误地标记为白色,进而被回收的错误

这两种情况同时满足,会出现对象丢失
强三色不变式
- 定义:黑色对象不能直接引用白色对象,只能通过灰色对象间接引用白色对象
- 本质:保证了黑色对象和白色对象之间必须有灰色对象作为“中间人”
弱三色不变式
- 定义:所有被黑色对象引用的白色对象,必须直接或间接地被某个灰色对象引用
- 本质:保证了从根对象出发,能够访问所有活跃的对象
屏障
-
插入屏障
工作原理:当程序中一个已经确认保留的对象(黑色)引用了一个可能被回收的对象(白色)时,系统会立即将那个白色对象标记为“需要再检查”(灰色),这样就不会错误地回收它。
适用范围:只在内存的“堆”区域自动工作,但在“栈”区域不会自动触发。
额外措施:在真正开始回收前,系统会专门再检查一次栈空间中的所有对象,并暂停程序运行(STW),确保没有遗漏任何不该回收的对象

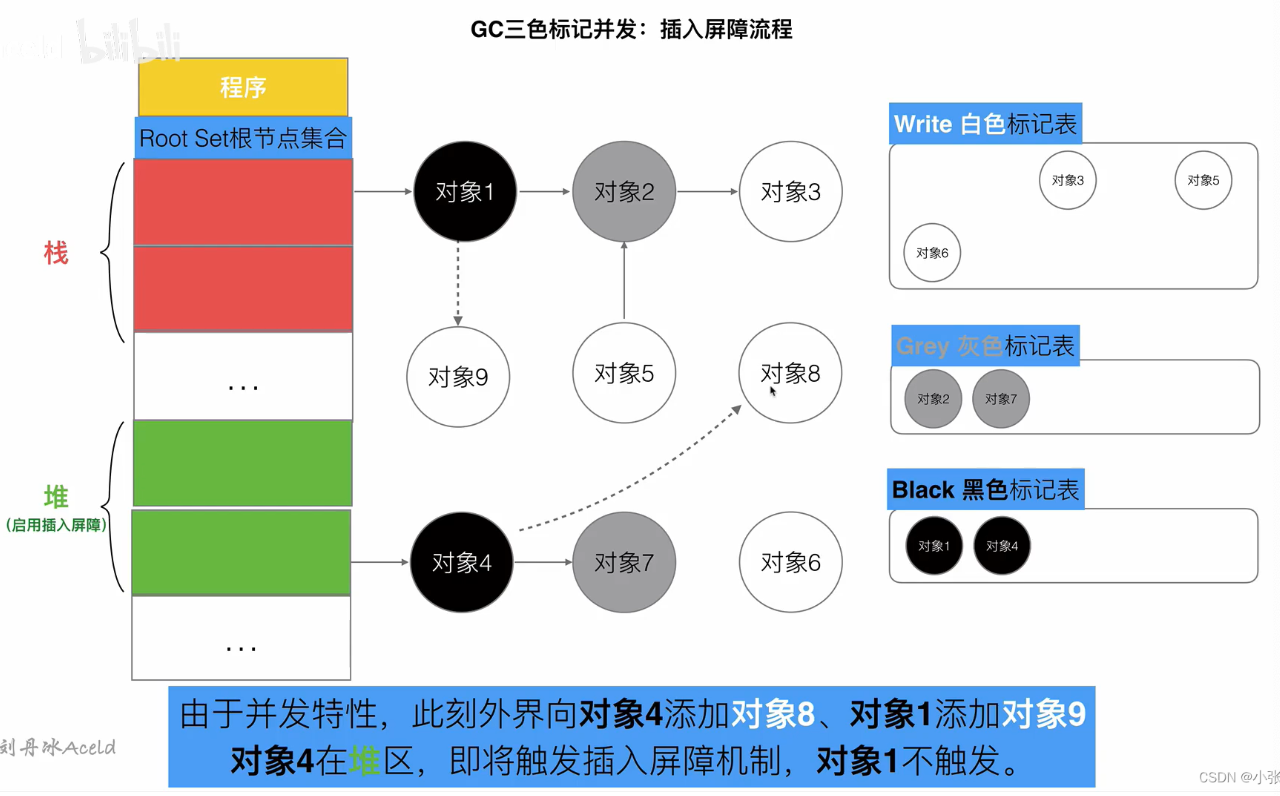
-
删除屏障:当程序中删除了某个对象的引用时,如果失去引用的对象是灰色或白色的,系统会将它标记为灰色。这确保了这个对象会被重新检查,不会因为失去某个引用而被错误回收。
不足:即使某个对象失去了所有引用(实际上已成为垃圾),但它仍然会被标记为灰色,而灰色对象在当前这轮GC中是不会被回收的。
(3)Go v1.8的三色标记法+混合写屏障机制
初始状态:所有对象的初始状态都是白色(包括栈上和堆上的所有对象)
[1] GC开始将栈上的可达对象全部扫描并标记为黑色(之后不再进行第二次重复扫描,无需STW)
[2] GC期间,任何在栈上创建的新对象,均为黑色
[3] 堆上被删除对象标记为灰色
[4] 堆上被添加的对象标记为灰色
GC垃圾收集的多个阶段
第一阶段:准备打扫(标记准备阶段)
- 安排一位打扫人员准备工作(启动后台标记任务)
- 短暂地请所有人停止活动,暂时"冻结现场"(STW暂停程序)
-如果这次是特别要求的大扫除,先处理上次没清理完的区域(如果当前垃圾收集循环是强制触发的,我们还需要处理还未被清理的内存管理单元;) - 记下所有明显应该保留的物品,比如你手中的、桌上正在用的东西(将根对象入队)
- 安装监控系统,记录接下来物品的挪动情况(开启写屏障)
第二阶段:边用边打扫(标记阶段)
- 让大家继续正常活动(恢复用户协程)
- 打扫人员开始工作,用三种标签标记物品(使用三色标记法开始标记,此时用户协程和标记协程并发执行):
白色:可能是垃圾
灰色:正在检查
黑色:确定要保留
重要的是,在这个阶段你可以继续使用房间,而打扫人员会同时工作
第三阶段:确认标记完成(标记终止阶段)
- 再次短暂请大家停止活动(暂停用户协程)
- 计算下次什么时候需要再次打扫(计算下一次GC触发时机)
- 叫醒负责清理的工作人员(唤醒后台清扫协程)
第四阶段:实际清理(清理阶段)
- 关闭监控系统(关闭写屏障)
- 让大家继续正常活动(恢复用户协程)
- 清理人员悄悄地、渐进地把所有没标记保留的物品(白色物品)清理掉,这个过程不影响大家正常使用房间(异步清理回收)
根对象
**根对象(root object)**是指那些能够从全局可达的地方访问到的对象。垃圾回收器会从根对象开始,再遍历根对象的引用关系,逐步追踪并标记所有可达的对象。任何未被标记的对象都会被认为是垃圾,最终被回收释放。
[1] 全局变量
// 全局变量作为根对象的例子
var globalCache = make(map[string]*UserData)
type UserData struct {
Name string
Age int
// 其他字段...
}
func main() {
// 即使没有其他引用,这个对象也不会被回收
// 因为它可以从全局变量访问到
globalCache["user1"] = &UserData{Name: "张三", Age: 30}
// 这里即使调用了GC也不会回收globalCache中的对象
runtime.GC()
}
[2]当前正在执行的函数的局部变量
func processUser() {
// 局部变量作为当前函数的根对象
userData := &UserData{Name: "李四", Age: 25}
// userData在函数内可访问,是当前函数的根对象
fmt.Println(userData.Name)
// 函数结束后,userData不再是根对象
// 如果没有其他引用,它将被回收
}
[3]当前正在执行的 goroutine 的栈中的变量
func main() {
// 启动一个goroutine
go func() {
// 这个userData对象在goroutine栈中
// 是这个goroutine的根对象
userData := &UserData{Name: "王五", Age: 40}
// 只要goroutine还在运行,这个对象就不会被回收
time.Sleep(10 * time.Second)
fmt.Println(userData.Name)
}()
// 主程序继续执行
time.Sleep(20 * time.Second)
}
[4]其他和运行时系统相关的数据结构和变量
三色标记法的缺点:会让程序偶尔卡顿,消耗额外内存,在大量垃圾时效率下降,并可能导致内存变得“七零八落”不好利用。
3、GC的触发条件
主动触发(手动触发):通过调用runtime.GC来触发GC,此调用阻塞式地等待当前GC运行完毕
package main
import (
"fmt"
"runtime"
"time"
)
func main() {
// 创建一些垃圾数据
for i := 0; i < 10000; i++ {
_ = make([]byte, 1024)
}
fmt.Println("手动触发GC前的内存统计:")
printMemStats()
// 手动触发GC
fmt.Println("手动触发GC...")
runtime.GC()
fmt.Println("手动触发GC后的内存统计:")
printMemStats()
}
func printMemStats() {
var m runtime.MemStats
runtime.ReadMemStats(&m)
fmt.Printf("系统分配的内存: %v KB\n", m.Sys/1024)
fmt.Printf("已使用的内存: %v KB\n", m.Alloc/1024)
fmt.Printf("累计分配的内存: %v KB\n", m.TotalAlloc/1024)
fmt.Printf("GC执行次数: %v\n", m.NumGC)
fmt.Println()
}
被动触发
[1]步调(pacing)算法
控制内存增长的比例,每次内存分配时检查当前内存分配量是否已经达到阈值(环境变量GOGC):默认100%,即当内存扩大一倍时启动GC
[2]系统监控
当超过两分钟没有产生任何GC时,强制触发GC
4、GC调优
- 控制内存分配速度和Goroutine 数量
- 少量使用“+”连接字符串。每次"+"连接,go都会创建一个全新的字符串,而不是在原有基础上添加。使用strings.Builder代替“+”连接
package main
import (
"fmt"
"strings"
"time"
)
func main() {
// 低效方式:使用+连接
start := time.Now()
result := ""
for i := 0; i < 10000; i++ {
result += "a"
}
fmt.Printf("使用+连接耗时: %v\n", time.Since(start))
// 高效方式:使用strings.Builder
start = time.Now()
var builder strings.Builder
for i := 0; i < 10000; i++ {
builder.WriteString("a")
}
result = builder.String()
fmt.Printf("使用Builder耗时: %v\n", time.Since(start))
}
使用+连接耗时: 10.500625ms
使用Builder耗时: 73.667µs
3.slice提前分配内存
4.避免map key对象过多
5.变量复用,减少对象分配
6.增大GOGC的值
5、GMP调度和CSP模型
- CSP模型是”以通信的方式来共享内存“,不同于传统的多线程通过共享内存来通信。用于描述两个独立的并发实体通过共享的通讯channel来进行通信的并发模型。用“传纸条”代替“共用笔记本”
- GMP调度
G:goroutine,go的协程,每个go关键字都会创建一个协程,”工人“
M:machine,工作线程,数量对应真实的cpu数,”机器“
P:process,包含运行go代码所需的必要资源,用来调度G和M之间的关联关系,其数量可以通过GOMAXPROCS来设置,默认为核心数,”工作台“
线程想运行任务就得获取 P,从 P 的本地队列获取 G,当 P 的本地队列为空时,M 也会尝试从全局队列或其他 P 的本地队列获取 G。M 运行 G,G 执行之后,M 会从 P 获取下一个 G,不断重复下去。如下图: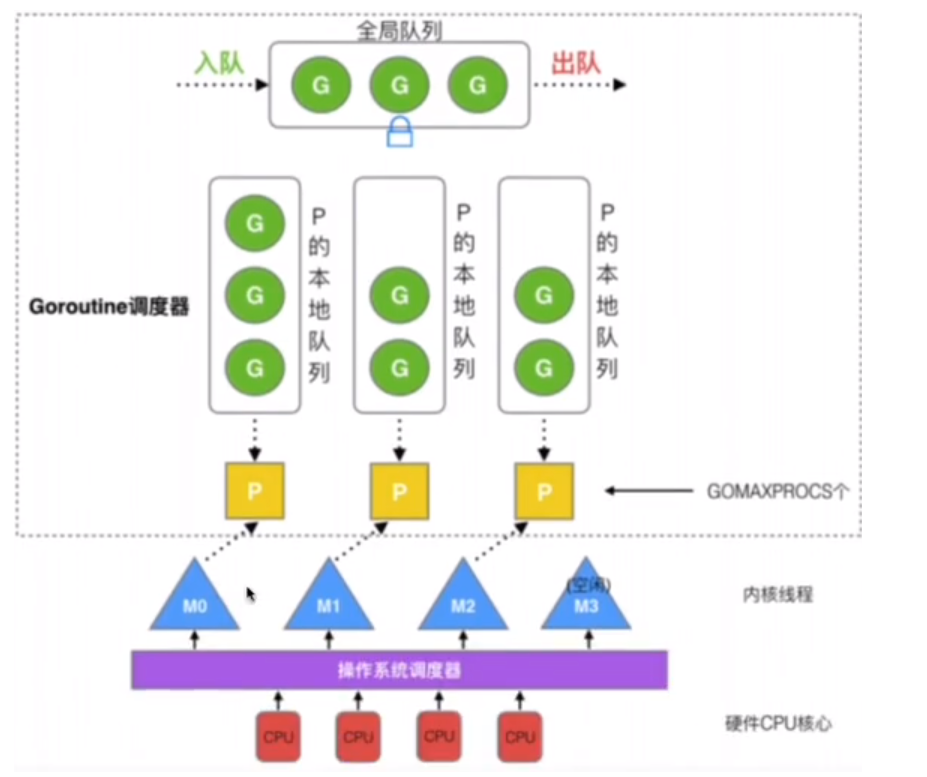
go语言运行时(runtime)系统中GMP调度模型的核心数据结构
[1]G 结构体 - Goroutine(工人)
type g struct {
goid int64 // 唯一的goroutine的ID
sched gobuf // goroutine切换时,用于保存g的上下文
stack stack // 栈
gopc // 创建这个goroutine的go语句的程序计数器位置
startpc uintptr // goroutine函数的程序计数器位置
// ...其他字段省略...
}
[2] P 结构体 - Processor(工作台)
type p struct {
lock mutex
id int32
status uint32 // 工作台状态:空闲/运行中/...
runqhead uint32 // 本地队列队头
runqtail uint32 // 本地队列队尾
runq [256]guintptr // 本地队列,固定大小为256的数组
runnext guintptr // 下一个优先执行的goroutine
// ...其他字段省略...
}
[3] M 结构体 - Machine(机器)
type m struct {
g0 *g // 每个M都有一个自己的G0
curg *g // 当前正在执行的G
// ...其他字段省略...
}
[4] 全局调度器结构体
type schedt struct {
runq gQueue // 全局队列,链表(长度无限制)
runqsize int32 // 全局队列长度
// ...其他字段省略...
}
[5] Goroutine上下文结构体
type gobuf struct {
sp uintptr // 保存CPU的rsp寄存器的值
pc uintptr // 保存CPU的rip寄存器的值
g guintptr // 记录当前这个gobuf对象属于哪个Goroutine
ret sys.Uintreg // 保存系统调用的返回值
// ...其他字段省略...
}
Goroutine调度策略
- 队列轮转:P会周期性的将G调度到M中执行,执行一段时间后,保存上下文,将G放到队列尾部,然后从队列中再取出一个G进行调度,P还会周期性的查看全局队列是否有G等待调度到M中执行
- 系统调用:当G0即将进入系统调用时,M0将释放P,进而某个空闲的M1获取P,继续执行P队列中剩下的G。M1的来源有可能是M的缓冲池,也可能是新建的。“当某个工人因为外部原因(如I/O操作需要等待时,不会浪费宝贵的工作台和机器资源,其他工人可以继续工作 ”
- 当G0系统调用结束后,如果有空闲的P,则获取一个P,M0与G0重新绑定,继续执行G0;如果没有,则将G0放入全局队列,等待被其他的P调度,然后M0将进入缓存池睡眠。
6、Goroutine切换时机
- select操作阻塞时
func worker() {
for {
select {
case data := <-channelA:
// 处理来自通道A的数据
fmt.Println("收到A的数据:", data)
case data := <-channelB:
// 处理来自通道B的数据
fmt.Println("收到B的数据:", data)
case <-time.After(2 * time.Second):
// 如果2秒内没有数据,做其他事情
fmt.Println("等待超时,先做点别的")
}
// 这里,如果所有case都阻塞,这个goroutine会让出CPU
}
}
- IO阻塞
func readFileWorker(filename string) {
// 打开文件操作可能阻塞,会触发goroutine切换
file, err := os.Open(filename)
if err != nil {
fmt.Println("无法打开文件:", err)
return
}
defer file.Close()
// 读取文件也可能阻塞,再次触发切换
data := make([]byte, 1024)
_, err = file.Read(data)
if err != nil {
fmt.Println("读取失败:", err)
return
}
fmt.Println("读取成功:", string(data))
}
// 调用
go readFileWorker("大文件.txt")
fmt.Println("不会等待文件读完,会继续执行")
- 阻塞在channel
func producer(ch chan int) {
for i := 0; i < 10; i++ {
// 如果通道已满,这里会阻塞并切换goroutine
ch <- i
fmt.Println("生产者生产了:", i)
time.Sleep(100 * time.Millisecond)
}
close(ch)
}
func consumer(ch chan int) {
for {
// 如果通道为空,这里会阻塞并切换goroutine
value, ok := <-ch
if !ok {
break // 通道关闭
}
fmt.Println("消费者消费了:", value)
time.Sleep(200 * time.Millisecond)
}
}
func main() {
ch := make(chan int, 3) // 容量为3的缓冲通道
go producer(ch)
go consumer(ch)
time.Sleep(3 * time.Second)
}
- 程序员显式编码操作
func cooperativeWorker(id int) {
for i := 0; i < 3; i++ {
fmt.Printf("工人%d正在工作...\n", id)
// 做一些工作
time.Sleep(100 * time.Millisecond)
// 显式让出CPU,让其他goroutine运行
runtime.Gosched()
fmt.Printf("工人%d回来继续工作\n", id)
}
}
func main() {
// 启动3个工人
for i := 1; i <= 3; i++ {
go cooperativeWorker(i)
}
// 等待所有工人完成
time.Sleep(2 * time.Second)
}
- 等待锁
var (
counter = 0
mutex = &sync.Mutex{}
)
func lockedWorker(id int) {
for i := 0; i < 3; i++ {
fmt.Printf("工人%d准备获取锁...\n", id)
// 尝试获取锁,如果锁被占用,会阻塞并切换
mutex.Lock()
fmt.Printf("工人%d获得了锁\n", id)
// 临界区 - 操作共享资源
counter++
fmt.Printf("工人%d修改counter为%d\n", id, counter)
time.Sleep(100 * time.Millisecond) // 模拟工作
// 释放锁
mutex.Unlock()
fmt.Printf("工人%d释放了锁\n", id)
// 不操作共享资源的其他工作
time.Sleep(50 * time.Millisecond)
}
}
func main() {
// 启动3个工人
for i := 1; i <= 3; i++ {
go lockedWorker(i)
}
// 等待工人完成
time.Sleep(2 * time.Second)
fmt.Printf("最终counter值: %d\n", counter)
}
- 程序调用:CPU密集任务的强制调度,在Go 1.14之前,函数调用点(如调用heavyCalculation)可能是调度点;在Go 1.14及之后,无论如何,运行过久的goroutine会被强制调度让出CPU
func cpuIntensiveWorker(id int) {
start := time.Now()
count := 0
for time.Since(start) < 3*time.Second {
// 非常消耗CPU的操作
for i := 0; i < 1000000; i++ {
count++
}
// 即使这个工人不主动休息,Go运行时也会在某些点强制它休息
// 例如,函数调用可能是一个调度点
heavyCalculation(id)
fmt.Printf("工人%d已工作: %v, 计数: %d\n",
id, time.Since(start), count)
}
}
func heavyCalculation(id int) int {
// 这个函数调用可能是一个调度点
result := 0
for i := 0; i < 100000; i++ {
result += i
}
return result
}
func main() {
// 启动两个CPU密集型工人
for i := 1; i <= 2; i++ {
go cpuIntensiveWorker(i)
}
// 等待工人完成
time.Sleep(4 * time.Second)
fmt.Println("所有工人完成工作")
}
7、Goroutine调度原理
g0协程:每个P(process处理器)都有一个特殊的协程叫g0,专门用于执行调度工作。这不是用户创建的普通协程,而是系统内部使用的调度协程。
调度循环:整个Go程序运行过程中不断重复的一个过程:
- 切换到g0协程执行调度逻辑
- 决定下一个要运行的普通协程 g
- 从g0切换到协程g让它执行
- 协程g执行一段时间后切换回g0
- 重复以上过程
从g0协程切换到普通协程 g时,会经历三个关键函数:
- schedule函数:选择下一个要执行的协程。根据多种因素(如协程优先级、等待时间等)决定哪个协程可以获得执行机会
- execute函数:进行必要的准备工作:更新协程状态(从等待状态变为运行状态);将协程g与操作系统线程(即M结构体)建立关联;设置运行环境
- gogo函数:保存当前协程g0的cpu寄存器状态;切换到新协程g的栈空间;恢复新协程的cpu寄存器状态,使程序从上次中断的地方继续执行
当普通协程g需要让出执行权(比如等待IO、睡眠或完成任务)时,会调用mcall函数:保存当前协程g的执行状态(包括程序计数器、栈指针等寄存器);切换回g0协程,开始新一轮的调度
goroutine调度的本质是将Goroutine按照一定算法放到CPU上去执行
cpu感知不到goroutine,只知道内核线程,所以需要Go调度器将协程调度到内核线程上面去,然后操作系统调度器将内核线程放到cpu上执行
M是对内核级线程的封装,所以Go调度器的工作就是将G分配到M
Go调度器的实现:GM模型->GMP模型 不支持抢占->协作式抢占->基于信号的异步抢占
G(Goroutine)的来源与排队机制
- P的runnext位置:每个P(处理器)都有一个特殊位置,只能存放一个G。根据局部性原理,这个位置的G总是最先被调度执行,因为它可能与刚刚执行的G 有关联,数据还在cpu缓存中。
- P的本地队列:每个P维护一个本地G对列,采用数组形式实现,最多可容纳256个等待执行的G。这是第二个优先查找的地方
- 全局G队列:所有P共享的一个对列,采用链表形式,没有数量限制。当P的本地对列满了,会将一部分G转移到全局队列。
- 网络轮询器(network poller):存放因网络I/O操作(如读写socket)而被阻塞的G。当网络操作就绪时,这些G会被重新放回可运行队列。
netpoller中拿到的G是_Gwaiting状态(存放的是因为网络IO被阻塞的G),从其他地方拿到的是_Grunnable状态
P(Processor)处理器的来源:
- 全局P队列:系统中所有的P都存在于这个数组中,数量由环境变量GOMAXPROCS决定,通常等于cpu核心数
- P数量决定了Go程序能够同时执行多少个goroutine
M(Machine)的来源与状态:操作系统线程,负责实际执行G的代码:
- 休眠线程队列:未绑定P的空闲线程会进入休眠状态,放入这个队列。如果长时间未被使用,会被垃圾回收器回收并销毁,以节省系统资源
- 运行线程:已绑定P的M,正在执行P中的某个G的代码
- 自旋线程:虽然绑定了P,但当前没有G可执行,处于自旋状态(忙等待)的M。它指向的是M自己的g0(调度协程),等待新的G到来时立即执行,避免线程休眠再唤醒的开销
运行线程数+自旋线程数 <= P的数量(GOMAXPROCS)
M个数>=P的个数
协程的生命周期:
-
创建协程:当你在代码中写 go func()时,Go语言会创建一个新的协程。这就像是给系统安排了一个新任务。
-
保存协程:新创建的协程G需要排队等待执行:首先尝试放在处理器的“特快通道”runnext位置;如果特快通道已被占用,原来的协程会被移到普通队列,新协程占据特快通道;如果普通队列也满了,会把一半协程转移到全局队列
-
准备执行:系统会唤醒一个空闲的工作线程或创建新线程M来执行这些排队的协程
-
获取协程:工作线程M按照以下顺序寻找任务:先看特快通道;再看自己负责的队列;如果没有,就看全局队列;实在没有,就”偷“其他队列的一半工作work stealing
-
执行协程:工作线程M开始执行协程任务G,期间遇到系统调用(如读写文件):工作线程M和协程G都会暂停;处理器P会转而寻找新的工作线程M继续其他任务;当系统调用完成后,协程G会重新排队等待执行。遇到网络操作(如网络请求):只暂停协程G,工作线程M继续处理其他任务;协程G被移交给网络监控器network poller管理;网络操作完成后,协程G重新回到队列等待执行;把耗时的等待变成了高效的cpu任务切换
-
完成任务:协程G执行完毕后,工作线程M会切换到调度模式G0,开始寻找下一个要执行的协程G,重复上述过程。
Go协程调度类型:
- 抢占式调度:当一个协程运行时间过长(例如陷入死循环或长时间睡眠)时,go语言中的系统监控器(sysmon)会发现这种情况,系统会强制停止该协程的执行,控制权会转移到调度协程g0,由它来决定下一个执行哪个协程,这确保了单个协程不会长时间独占cpu资源
- 主动调度:协程自愿让出cpu的几种情况:当创建新协程或当前协程执行完毕时,会触发调度过程;可以调用runtime.Gosched()函数,主动让当前协程暂停,给其他协程执行的机会;垃圾回收完成后,Go会重新进行调度,选择合适的协程继续执行
- 被动调度:系统调用阻塞(如读写文件):协程G和执行它的线程M都会暂停,处理器P会与当前线程M分离,并交给其他线程M继续执行队列P中的其他协程G,确保一个协程的系统调用不会阻塞其他协程的运行;网络IO阻塞:只有协程G被暂停,执行线程M不会被阻塞;被暂停的协程会被移到网络轮询器中等待,执行线程M继续处理P中其他协程G,当网络操作完成后,等待的协程会被放回可执行队列;并发原语阻塞(如互斥锁、通道操作):协程会被暂停并放入特定的等待队列,执行线程M继续处理P中其他协程G,当阻塞条件解除(如获得锁、通道有数据)时,协程会被放回可执行队列
8、Goroutine的抢占式调度
-
非协作式的抢占式调度
由runtime来决定一个goroutine运行多长时间,即使goroutine不主动让出cpu,runtime可以强制抢占它,然后让其他goroutine获得执行机会。 -
基于协作的抢占式调度流程
[1] 编译器会在调用函数前插入runtime.morestack,让运行时有机会在这段代码中检查是否需要执行抢占调度
[2] go语言运行时会在垃圾回收暂停程序、系统监控发现goroutine运行超过10ms,那么会在这个协程设置一个抢占标记
[3] 当发生函数调用时,可能会执行编译器插入的runtime.morestack,它调用的 runtime.newstack会检查抢占标记,如果有抢占标记就会触发让出cpu,切到调度主协程里 -
基于信号的抢占式调度
[1] 信号处理准备:每个执行线程M都会注册一个特殊的信号处理函数,用于接收SIGURG信号;处理函数名为sighandler,它能在收到信号时中断当前执行
[2] 系统监控:sysmon监控线程,会定期检查所有正在运行的协程;监控间隔时动态调整的,最短20微秒,最长10毫秒;当监控发现某个协程连续占用处理器P超过10毫秒时,会采取行动
[3] 发送抢占信号:监控器会向运行这个长时间执行协程的线程发送SIGURG信号;这个信号不会终止程序,但会打断正常执行流程
[4] 处理抢占:线程收到信号后,操作系统会暂停当前执行,转而执行预先注册的信号处理函数;信号处理函数会将当前协程的状态从_Grunning改为_Grunnable,被抢占的协程会被放到全局队列中等待后续执行;线程会继续寻找其他协程来执行
[5] 协程恢复:当被抢占的协程再次被调度执行时,它会从被中断的地方继续执行;对于协程本身来说,这个过程是透明的,它感知不到自己曾被抢占
9、context结构原理
context是什么?
context在go语言中是一种管理多个协程goroutine的工具,它能够:在多个协程之间传递信息;控制协程的取消信号;设定协程的执行期限。
当你启动很多协程时,需要一种方式来统一管理它们,比如告诉它们“该停止了”,这就是context的主要用途。
context接口的四种方法
type Context interface {
Deadline() (deadline time.Time, ok bool) //获取设定的截止时间
Done() <-chan struct{} //返回一个通道,用于接收取消信号
Err() error //返回取消的原因
Value(key interface{}) interface{} //获取context中存储的值
}
- Deadline方法:告诉你这个context什么时候会自动取消,如果设置了截止时间,ok会返回true
- Done方法:返回一个通道,当context被取消时,这个通道会被关闭。可以通过检查这个通道来判断是否需要停止当前工作
- Err方法:告诉你context为什么被取消了。如果还没被取消,返回nil
- Value方法:从context中获取之前存储的键值对数据
package main
import (
"context"
"fmt"
"time"
)
// 自定义类型作为context键,避免冲突
type userIDKey struct{}
type authTokenKey struct{}
// 模拟一个需要控制超时的任务
func processRequest(ctx context.Context) {
// 1. 使用Deadline方法检查是否设置了截止时间
deadline, hasDeadline := ctx.Deadline()
if hasDeadline {
fmt.Printf("任务必须在 %v 之前完成\n", deadline.Format("15:04:05"))
timeRemaining := time.Until(deadline)
fmt.Printf("剩余时间: %.2f 秒\n", timeRemaining.Seconds())
} else {
fmt.Println("任务没有设置截止时间")
}
// 2. 使用Value方法获取context中的值
if userID, ok := ctx.Value(userIDKey{}).(string); ok {
fmt.Printf("处理用户 %s 的请求\n", userID)
}
if token, ok := ctx.Value(authTokenKey{}).(string); ok {
fmt.Printf("使用认证令牌: %s\n", token)
}
// 模拟一个耗时的操作
select {
// 3. 使用Done方法监听取消信号
case <-ctx.Done():
// 4. 使用Err方法获取取消原因
fmt.Printf("任务被取消,原因: %v\n", ctx.Err())
return
case <-time.After(5 * time.Second):
fmt.Println("任务成功完成")
}
}
func main() {
fmt.Println("=== 示例1: 使用超时限制 ===")
// 创建一个带超时的context
timeoutCtx, cancel := context.WithTimeout(context.Background(), 2*time.Second)
defer cancel() // 良好实践:总是调用cancel函数,即使context会自动取消
// 添加值到context
valueCtx := context.WithValue(timeoutCtx, userIDKey{}, "user-123")
valueCtx = context.WithValue(valueCtx, authTokenKey{}, "auth-xyz789")
// 执行任务
processRequest(valueCtx)
// 等待一会儿,确保第一个示例完成
time.Sleep(3 * time.Second)
fmt.Println("\n=== 示例2: 手动取消 ===")
// 创建一个可取消的context
cancelCtx, cancel := context.WithCancel(context.Background())
// 添加值到context
valueCtx = context.WithValue(cancelCtx, userIDKey{}, "user-456")
// 在新的goroutine中执行任务
go processRequest(valueCtx)
// 1秒后手动取消
time.Sleep(1 * time.Second)
fmt.Println("主动取消任务...")
cancel()
// 等待一会儿,确保第二个示例完成
time.Sleep(1 * time.Second)
fmt.Println("\n=== 示例3: 使用截止时间 ===")
// 创建一个带有具体截止时间点的context
deadline := time.Now().Add(3 * time.Second)
deadlineCtx, cancel := context.WithDeadline(context.Background(), deadline)
defer cancel()
// 执行任务
processRequest(deadlineCtx)
}
=== 示例1: 使用超时限制 ===
任务必须在 10:23:00 之前完成
剩余时间: 2.00 秒
处理用户 user-123 的请求
使用认证令牌: auth-xyz789
任务被取消,原因: context deadline exceeded
=== 示例2: 手动取消 ===
任务没有设置截止时间
处理用户 user-456 的请求
主动取消任务...
任务被取消,原因: context canceled
=== 示例3: 使用截止时间 ===
任务必须在 10:23:08 之前完成
剩余时间: 3.00 秒
任务被取消,原因: context deadline exceeded
context的几种实现
- Background和TODO:最基础的context,通常作为整个程序的根context。它们不能被取消,也不能存储值
- WithCancel:创建一个可以手动取消的context。当调用返回的cancel函数或父context取消时,它就会取消
- WithTimeout:设置一个超时时间,到时间后自动取消
- WithDealline:设置一个截止时间点,到那个时间点自动取消
- WithValue:在context中存储键值对数据
10、context原理与应用场景
当一个通道被关闭时,所有正在等待这个通道的协程都会收到通知
context利用这个特效实现了“取消信号”的传递:
- 每个context内部都有一个Done()方法,返回一个通道
- 当context被取消时,这个通道会被关闭【从已关闭的通道接收数据时,会立即返回该通道类型的零值,而不会阻塞;无数据但通道未关闭时:阻塞等待,直到有数据可读或通道被关闭】
- 所有监听(读取)这个通道的协程都会立即得到通知
- 子context会继承父context的取消信号,形成一个取消链
这种设计使得我们可以优雅地管理复杂的协程树,一旦父context被取消,所有子context都会收到通知
context使用场景:RPC调用、pipeline、超时请求、http服务器的request互相传递数据
11、Golang内存分配机制
Go语言不依赖操作系统直接分配内存,而是自己管理内存。
- Go语言把内存分成非常小的块,并进行多级管理;
- 每个线程goroutine都有自己的本地缓存,需要内存时,先从本地缓存拿,不够再去中央内存池申请;
- 当Go程序不再使用某块内存时,这块内存不会立即还给操作系统,而是放回Go自己的内存池,等待下次重新使用。只有当发现回收的内存太多、长时间没人用时,Go才会把一部分内存还给操作系统
基于TCMalloc的设计
Google的Thread-Caching Malloc,为线程提供缓存的内存分配器,减少锁竞争,提高内存分配和回收的速度
当你在Go程序中创建变量时:
- Go先检查这个变量需要多大的内存
- 然后看当前goroutine的本地内存池中是否有合适大小的空闲块
- 如果有,直接分配,非常快速(无需加锁)
- 如果本地内存池没有合适的,就向中央内存池申请一批同样大小的内存块
- 使用一块,剩下的留在本地内存池中,供将来使用
- 当变量不再使用时,对应的内存块会通过垃圾回收放回内存池,而不是立即归还给操作系统
为什么这样设计很高效?
- 减少系统调用:向操作系统申请内存是昂贵的操作,Go通过批量申请和复用,大大减少了这类调用
- 减少锁竞争:每个线程有自己的内存池,大多数情况下无需加锁,提高了并发程序的性能
- 内存复用:回收的内存不立即释放,而是重复使用,减少了申请和释放的开销
- 分级管理:根据大小分类管理,使得内存分配更加高效,减少了碎片
Golang的内存管理组件主要有:mspan[仓库中的货架单元]、mcache[每个工人随身携带的工具箱]、mcentral[仓库的中央配送区]和mheap[整个仓库的管理中心]
mspan:内存的“货架单元”
mspan是内存管理的基本单元,该结构体中包含next和prev两个字段,它们分别指向了前一个和后一个mspan ,每个mspan都管理npages个大小为8KB的页,一个span是由多个page组成的。这里的页不是操作系统的内存页,它们是操作系统内存页的整数倍。
type mspan struct {
next *mspan //后指针
prev *mspan //前指针
startAddr uintptr //管理页的起始地址,指向page
npages uintptr //页数
spanclass spanClass //规格,字节数
...
}
type spanclass uint8
mspan的种类
规格编号 每个对象占用的字节数 整个mspan的总字节数 可以存放的对象数量 末尾浪费的字节数 最大浪费比例
// class bytes/obj bytes/span objects tail waste max waste
//
// 1 8 8192 1024 0 87.50%
// 2 16 8192 512 0 43.75%
// 3 24 8192 341 8 29.24%
// 4 32 8192 256 0 21.88%
// 5 48 8192 170 32 31.52%
// 6 64 8192 128 0 23.44%
// 略...
// 62 20480 40960 2 0 6.87%
// 63 21760 65536 3 256 6.25%
// 64 24576 24576 1 0 11.45%
// 65 27264 81920 3 128 10.00%
// 66 28672 57344 2 0 4.91%
// 67 32768 32768 1 0 12.50%
线程缓存:mcache 每个工人的私人工具箱
mcache是什么?
mcache是Go语言中给每个处理器P分配的本地内存缓存。
- 每个处理协程goroutine工作时都会绑定一个处理器P上
- 每个处理器都有自己的mcache“工具箱”
- 这个“工具箱”预先装满了各种规格的内存块,随取随用
type mcache struct{
alloc [numSpanClasses]*mspan
}
_NumSizeClasses=68
numSpanClasses=_NumSizeClasses<<1
mcache的结构与特点
- 全规格收藏
mcache用Span classes作为索引管理多个用于分配的mspan,它包含所有规格的mspan。它是_NumSizeClasses的2倍,682=136,其中2是将spanClass分成了有指针和无指针两种,方便垃圾回收。 - 分成两类的设计
对于每种规格,有2个mspan,一个mspan不包含指针,另一个mspan则包含指针。对于无指针对象的mspan在进行垃圾回收的时候无需进一步扫描它是否引用了其他活跃的对象。 - 按需补充
mcache在初始化的时候没有任何mspan资源,在使用过程中会动态地从mcentral申请,之后会缓存下来。当对象小于等于32KB大小时,使用mcache的相应规格的mspan进行分配。 - 使用标记
mcache拥有一个allocCache字段,作为一个位图,来标记span中的元素是否被分配。 - 补货机制
当请求的mcache中对应的span没有可以使用的元素时,需要从mcentral中加锁查找,分别遍历mcentral中有空闲元素的nonempty链表和没有空闲元素的empty链表。没有空闲元素的empty链表可能会有被垃圾回收标记为空闲的还未来得及清理的元素,这些元素也是可用的。
中心缓存:mcentral
mcentral管理全局的mspan供所有线程使用,全局mheap变量包含mcentral字段,每个mcentral结构都维护在mheap结构体内
type mcentral struct{
spanclass spanClass //当前规格大小
partial [2]spanSet //有空闲object的mspan列表
full [2]spanSet //没有空闲object的mspan列表
}
每个mcentral管理一种spanClass的mspan,并将有空闲空间和没有空闲空间的mspan分开管理。partial和full的数据类型为spanSet,表示mspans集,可以通过pop、push来获得mspans
type spanSet struct {
spineLock mutex
spineunsafe.Pointer //指向[]span的指针
spineLen uintptr //Spine array length,accessed atomically
spineCap uintptr // Spine array cap,accessed under lock
index headTailIndex//前32位是头指针,后32位是尾指针
}
mcache从mcentral获取和归还mspan的流程:
- 获取:加锁,从partial链表找到一个可用的mspan;并将其从partial链表删除;将取出的mspan加入full链表,将mspan返回给工作线程,解锁
- 归还:加锁,将mspan从 full链表删除;将mspan加入partial链表,解锁
页堆:mheap
mheap管理go的所有动态分配内存,go程序持有的整个堆空间,全局唯一
type mheap struct{
lock mutex //全局锁
pages pageAlloc //页面分配的数据结构
allspans []*mspan //存储所有已分配的内存块mspan的切片
//二堆数组,用于管理所有的堆内存区域
arenas [1 << arenaL1Bits]*[1 << arenaL2Bits]*heapArena
//存储所有规格的中心缓存
central [numSpanClasses]struct{
mcentral mcentral //实际的中心缓存结构
pad [cpu.CacheLinePadSize - unsafe.Sizeof(mcentral()%cpu.CacheLinePadSize]byte //填充字节,避免false sharing(伪共享)影响性能
}
...
}
所有mcentral的集合则是存放于mheap中。mheap 里的arena区域是堆内存的抽象,运行时会将8KB看做一页,这些内存中存储了所有在堆上初始化的对象。运行时使用二维的runtime.heapArena数组管理所有内存,每个runtime.heapArena都会管理64MB的内存

12、竞态、内存逃逸
(1)竞态条件[race condition]
多个goroutine同时读写同一块内存区域而导致数据不一致的情况
go提供了内置的竞态检测器
go run -race main.go
go build -race
go test -race
通过锁机制确保同一时刻只有一个goroutine能访问共享资源
sync.Mutex //互斥锁
sync.RWMutex //读写锁
(2)内存逃逸 memory escape
本应该在栈上分配的变量,因为某些原因必须在堆上分配
栈内存:函数调用时自动分配,函数返回时自动回收,分配和回收速度快
堆内存:需要手动申请和释放(在Go中由垃圾回收器处理),有额外开销
当一个变量的生命周期超过函数作用域,它就会“逃逸”到堆上
检测方法:
go build -gcflags="-m" main.go
常见逃逸场景:
[1] 指针逃逸:返回局部变量的指针
func createValue() *int {
x:=42 //在正常情况下应该在栈上分配
return &x //但因为返回了指针,x会逃逸到堆上
}
[2] 栈空间不足逃逸:当分配的内存过大时
func createLargeArray() {
arr := [10000000]int{} //可能因为太大而逃逸到堆上
}
[3] 变量大小不确定逃逸
func createSlice(size int) []int{
return make([]int,size)//大小在编译器无法确定
}
[4] 动态类型逃逸:编译期间不确定参数的类型、参数的长度也不确定的情况下就会发生逃逸
空接口interface(可以表示任意的类型,如果函数参数为interface),编译期间很难确定其参数的具体类型,也会发生逃逸
func printAny(v interface{}){
fmt.Println(v) //参数v会逃逸到堆上
}
[5] 闭包引用对象逃逸
func createCounter() func() int {
count := 0
return func() int {
count++ //count被闭包引用,会逃逸到堆上
return count
}
}
为什么Go中内存逃逸是安全的?
go编译器会通过逃逸分析,自动决定变量是分配在栈上还是堆上,确保内存安全:
- 对于可能导致悬空指针的情况,变量会自动逃逸到堆上
- 堆上的内存由垃圾回收器管理,避免了手动内存管理的风险
13、golang内存对齐机制
内存对齐是指计算机在存储数据时,会将数据存放在特定的内存地址上,使得找个地址值是某个数值(通常是2、4、8字节)的整数倍。
为什么需要内存对齐?提高cpu访问内存的效率
- 硬件限制:现代cpu通常一次读取4字节或8字节的数据,如果数据跨越了这些边界,cpu需要多次读取并合并数据,降低效率
- 提高访问速度:对齐的内存访问通常更快,某些cpu架构甚至不支持非对齐内存访问
- 原子操作要求:某些原子操作需要内存对齐才能保证原子性
Go语言的对齐系数
- 32位系统对齐系数:4
- 64位系统对齐系数:8
- 每种类型都有自己的对齐系数,可以通过unsafe.Alignof()获取
常见类型的对齐系数:
bool/int8/uint8(byte)/uintptr:1字节
int16/uint16:2字节
int32/uint32/float32:4字节
int64/uint64/float64/指针:8字节(在64位系统上)
Go语言的内存对齐原则
[1] 成员对齐
结构体中每个字段的偏移量必须是该字段大小和对齐系数两者中较小值的整数倍。
[2] 整体对齐
整个结构体的大小必须是结构体中最大对齐系数和编译器默认对齐系数两者较小值的整数倍
[3] 空结构体的特殊处理
空结构体struct{}本身大小为0;当空结构体作为结构体中间字段时,不占用空间也不参与对齐;当空结构体作为最后一个字段时,需要考虑整体对齐规则
字段顺序对内存分布的影响
type T2 struct{
i8 int8 // 1字节
i64 int64 // 8字节
i32 int32 // 4字节
}
type T3 struct{
i8 int8 // 1字节
i32 int32 // 4字节
i64 int64 // 8字节
}
T2内存布局:
i8: 占1字节 偏移量: 0
填充: 7字节对齐 偏移量: 1-7
i64: 占8字节 偏移量: 8-15
i32: 占4字节 偏移量: 16-19
填充: 4字节对齐 偏移量: 20-23
总大小: 24字节
T3内存布局:
i8: 占1字节 偏移量: 0
填充: 3字节对齐 偏移量: 1-3
i32: 占4字节 偏移量: 4-7
i64: 占8字节 偏移量: 8-15
总大小: 16字节
仅仅调整字段顺序, T3字段比T2节省了8字节!
空结构体位置的影响:
type C struct {
a struct{} // 0字节
b int64 // 8字节
c int64 // 8字节
}
type D struct {
a int64 // 8字节
b struct{} // 0字节
c int64 // 8字节
}
type E struct {
a int64 // 8字节
b int64 // 8字节
c struct{} // 0字节
}
type F struct {
a int32 // 4字节
b int32 // 4字节
c struct{} // 0字节
}
C: 16字节 (空结构体在中间不占空间,两个int64共16字节)
D: 16字节 (空结构体在中间不占空间,两个int64共16字节)
E: 24字节 (因为空结构体在末尾,需要按8字节对齐,所以总大小是24字节而不是16字节)
F: 12字节 (int32+int32=8字节,再加上末尾空结构体的4字节对齐)
如何查看内存对齐情况:
使用unsafe.Sizeof()查看结构体占用的内存大小:
fmt.Println(unsafe.Sizeof(C{})) // 16
fmt.Println(unsafe.Sizeof(D{})) // 16
fmt.Println(unsafe.Sizeof(E{})) // 24
fmt.Println(unsafe.Sizeof(F{})) // 12
使用unsafe.Offsetof()可以查看字段的偏移量:
type Example struct {
a bool
b int32
c int8
}
e := Example{}
fmt.Println(unsafe.Offsetof(e.a)) // 0
fmt.Println(unsafe.Offsetof(e.b)) // 4
fmt.Println(unsafe.Offsetof(e.c)) // 8
14、golang中new和make的区别?

变量声明与零值
当var声明值类型变量时,go会自动为其分配内存并初始化为该类型的零值
var i int // 0
var f float64 // 0.0
var b bool // false
var s string // ""
var a [3]int // [0, 0, 0]
var st struct {
name string
age int
} // {name:"", age:0}
引用类型变量
对于引用类型变量(指针、切片、映射、通道等),声明时只声明了变量本身,而不是它指向的数据,默认零值是nil
var p *int // nil
var s []int // nil
var m map[string]int // nil
var c chan int // nil
var f func() // nil
var i interface{} // nil
尝试直接使用这些未初始化的引用类型会导致问题:
var m map[string]int
m["key"] = 1 // 运行时错误: assignment to entry in nil map
make函数详解
make函数专门用于创建并初始化三种引用类型:切片(slice)、映射(map)和通道(channel)
1、创建切片
// 参数1:类型,参数2:长度,参数3:容量(可选,默认等于长度)
s := make([]int, 3) // 创建长度为3的切片 [0,0,0]
s2 := make([]int, 3, 5) // 创建长度为3,容量为5的切片
fmt.Println(s, len(s), cap(s)) // [0 0 0] 3 3
fmt.Println(s2, len(s2), cap(s2)) // [0 0 0] 3 5
2、创建映射
// 参数1:类型,参数2:初始容量大小(可选)
m := make(map[string]int) // 创建空map
m2 := make(map[string]int, 10) // 创建初始容量为10的map
m["apple"] = 5
fmt.Println(m) // map[apple:5]
3、创建通道
// 参数1:类型,参数2:缓冲区大小(可选,默认为0-无缓冲)
ch := make(chan int) // 创建无缓冲通道
ch2 := make(chan string, 3) // 创建缓冲区大小为3的通道
// 无缓冲通道需要有接收者才能发送成功
go func() { ch <- 1 }()
fmt.Println(<-ch) // 1
new函数详解
new函数可以用于任何类型,它分配内存,将内存置零,并返回指向该内存的指针
// new接受一个类型参数,返回指向该类型零值的指针
p := new(int) // *int 类型,指向值为0的int
fmt.Println(*p) // 0
s := new([]int) // *[]int 类型,指向nil切片
fmt.Println(*s) // []
new创建引用类型的限制:
m := new(map[string]int) // 创建一个指向nil map的指针
// (*m)["key"] = 1 // 错误:不能对nil map赋值
*m = make(map[string]int) // 必须先初始化
(*m)["key"] = 1 // 正确
fmt.Println(*m) // map[key:1]
make与new的关键区别
1、使用类型
// make只适用于slice, map, channel
slice := make([]int, 3)
m := make(map[string]int)
ch := make(chan bool)
// new可用于任何类型
intPtr := new(int)
slicePtr := new([]int)
structPtr := new(struct{ name string })
2、返回类型
// make返回初始化后的引用类型本身
s := make([]int, 3)
fmt.Printf("类型: %T\n", s) // 类型: []int
// new返回指向零值的指针
p := new(int)
fmt.Printf("类型: %T\n", p) // 类型: *int
3、初始化程度
// make进行初始化,直接可用
s := make([]int, 3)
s[0] = 1 // 正确,可直接使用
// new只置零,引用类型仍需额外初始化
m := new(map[string]int)
// (*m)["key"] = 1 // 错误,map需要先make
15、golang的slice的实现原理
切片的底层结构
type slice struct {
array unsafe.Pointer //指向底层数组的指针
len int //切片的长度
cap int //切片的容量
}
这个结构体在64位系统上总共占用24个字节:
- array:8字节,指向实际存储数据的数组
- len:8字节,表示切片当前的长度(可访问的元素个数)
- cap:8字节,表示切片的容量(底层数组的大小)
初始化slice调用的是runtime.makeslice,makeslice函数的工作主要是计算slice所需内存大小,然后调用mallocgc进行内存的分配
所需内存的大小=切片中元素大小*切片的容量
silce 扩容策略go1.18之后:
- 如果新容量大于当前容量的两倍,则新容量就是新申请的容量
- 否则,如果当前容量小于256,则新容量为当前容量的2倍;
- 如果当前容量大于等于256,则新容量为当前容量的1.25倍
为什么切片不是线程安全的?
由于切片共享底层数组,并且其结构(len和cap)可能被同时修改,因此在多个goroutine同时操作同一个切片时会导致数据竞争,问题包括:
- 多个goroutine同时调用append可能会相互覆盖
- 读取len和cap的同时,其他goroutine可能正在修改这些值
- 扩容操作不是原子的
16、golang中array和slice的区别
(1)数组长度不同
数组初始化必须指定长度,并且长度就是固定的
切片的长度是不固定的,可以追加元素,在追加时可能使切片的容量增大
// 声明数组时必须指定长度
var scores [5]int // 创建一个可以存放5个整数的数组
// 或者通过初始化值推断长度
primes := [3]int{2, 3, 5} // 长度为3的数组
// 创建切片可以不指定长度
scores := []int{90, 85, 78} // 创建切片
// 可以动态添加元素
scores = append(scores, 95, 89) // 切片现在包含5个元素
(2)函数传参不同
- 数组是值类型,将一个数组赋值给另一个数组时,传递的是一份深拷贝,函数传参操作都会复制整个数组数据,会占用额外的内存,函数内对数组元素值的修改,不会修改原数组内容
- 切片是引用类型,将一个切片赋值给另一个切片时,传递的是一份浅拷贝,函数传参操作不会拷贝整个切片,只会复制len和cap,底层共用同一个数组,不会占用额外的内存,函数内对数组元素值的修改,会修改原数组内容
func modifyArray(arr [3]int) {
arr[0] = 100 // 这个修改不会影响原数组
}
func main() {
nums := [3]int{1, 2, 3}
fmt.Println("原始数组:", nums) // [1 2 3]
modifyArray(nums)
fmt.Println("函数调用后:", nums) // 仍然是[1 2 3],没有被修改
// 赋值也是复制整个数组
another := nums
another[0] = 999
fmt.Println("修改副本后,原数组:", nums) // 仍然是[1 2 3]
}
func modifySlice(slc []int) {
slc[0] = 100 // 这个修改会影响原切片
}
func main() {
nums := []int{1, 2, 3}
fmt.Println("原始切片:", nums) // [1 2 3]
modifySlice(nums)
fmt.Println("函数调用后:", nums) // [100 2 3],第一个元素被修改了
// 赋值也是共享底层数组
another := nums
another[1] = 999
fmt.Println("修改副本后,原切片:", nums) // [100 999 3],也被修改了
}
(3)计算数组长度方式不同
数组需要遍历计算数组长度,时间复杂度为o(n)
切片底层包含len字段,可以通过len计算切片长度,时间复杂度为o(1)
17、golang的map实现原理详解
map:键值对的快速查找和存储
本质上是一个指针,占用8个字节,指向底层的hmap结构体。其底层实现基于哈希表结合链地址法来解决冲突问题。
map的主要特点:
- 键不能重复:每个键只能出现一次
- 键必须可哈希:如int、bool、float、string、array等类型
- 无序性:map中的元素无法按照插入顺序进行遍历
底层数据结构:hmap结构体
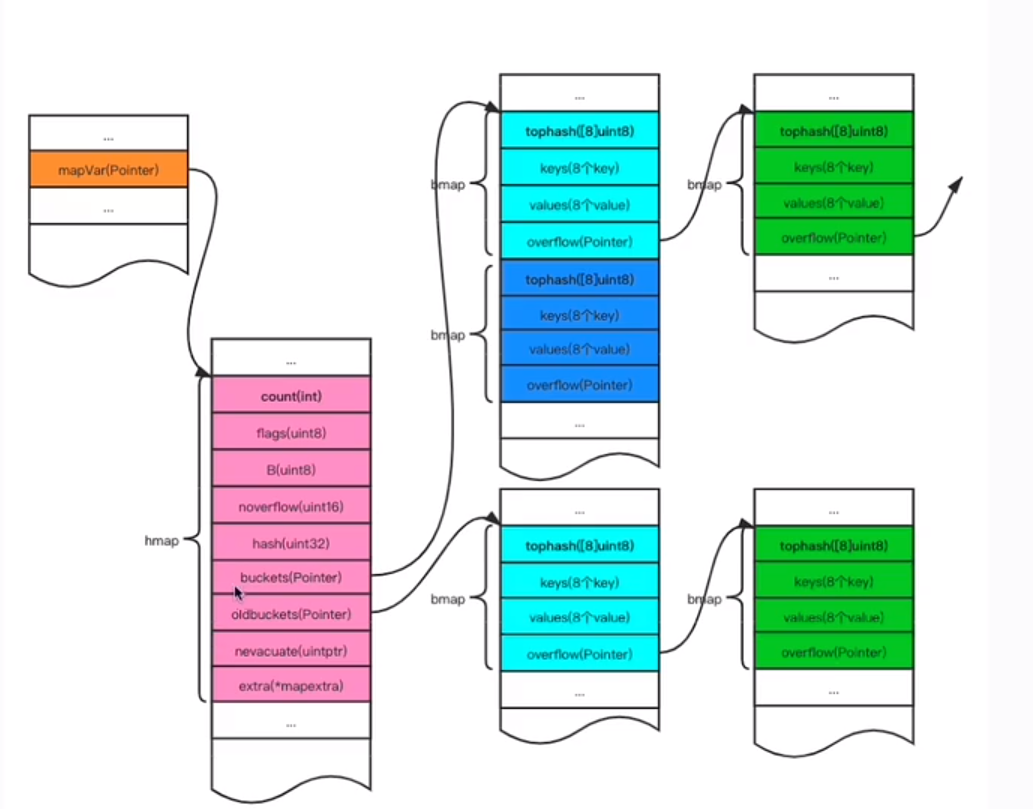
定义在src/runtime/map.go文件中:
type hmap struct{
count int //元素个数,调用len(map)时返回该值
flags uint8 //状态标志,如是否处于写入状态
B uint8 //桶(buckets)的对数,桶数量 = 2^B
noverflow uint16 //溢出桶的数量
hash0 uint32 //hash种子,能让hash结果更随机
buckets unsafe.Pointer //指向桶数组的指针
oldbuckets unsafe.Pointer //扩容时指向旧桶数组的指针,非扩容状态为nil
nevacuate uintptr //扩容进度,小于该地址的buckets已迁移完成
extra *mapextra //存储溢出桶,为优化GC设计
}
bmap 结构(桶)
存储实际的键值对
//编译时的静态结构
type bmap struct{
tophash [bucketCnt]uint8 //bucketCnt 为8,存储hash值的高8位
}
//运行时动态拓展结构,在编译过程中runtime.bmap会拓展成以下结构体:
type bmap struct{
tophash [8]uint8 //hash值的高8位,用于快速查找
keys [8]keytype //存储最多8个键
values [8]elemtype //存储最多8个值
overflow uintptr //指向溢出桶的指针
}
tophash数组用于快速定位key,存储key哈希值的高8位。当查找某个key时,先比较tophash值,如果匹配才进一步比较key值,提高查找效率。
tophash还会存储一些特殊状态值:
emptyRest= 0 //表明此桶单元为空,且更高索引的单元也是空
emptyOne=1 //表明此桶单元为空
evacuatedX= 2 //用于表示扩容迁移到新桶前半段区间
evacuatedY= 3 //用于表示扩容迁移到新桶后半段区间
evacuatedEmpty = 4 //用于表示此单元已迁移
minTopHash= 5 // key的tophash值与桶状态值分割线值,小于此值的一定代表着桶单元的状态,大于此值的一定是key对应的tophash值
func tophash(hash uintptr) uint8 {
top := uint8(hash >> (goarch.PtrSize*8 - 8))
if top < minTopHash {
top += minTopHash
}
return top
}
为避免key哈希值的高8位值和这些状态值相等产生混淆情况,当key给哈希值高8位若小于minTopHash时,自动将其值加上minTopHash作为该key的tophash
key和value是各自放在一起的。当key和value类型不一样,key和value占用字节大小不一样,使用 key/value这种形式可能会因为内存对齐导致内存空间浪费。所以,go采用key和value 分开存储的设计,更节省内存空间
map的初始化过程:
- 创建一个hmap结构体对象
- 生成一个哈希因子hash0并赋值到hmap对象中(用于后续为key创建哈希值)
- 根据hint=10[初始容量提示],并根据算法规则来创建B,此时B为1. 用户说他们大约需要存10个东西。每个桶能放8个,但我们不想让桶太满(最好只装65%左右,装载因子:6.5)。所以我们实际需要能放约15-16个东西的空间。2^1=2个桶刚好能放16个元素,所以我们选B=1
- 根据B去创建桶(bmap 对象)并存放在bucket数组中。当前的Bmap的数量为2
B<4时,根据B创建桶的个数的规则为:2^B(标准桶)
B>=4时,根据B创建桶的个数的规则为:

golang map的渐进式扩容
Go map扩容,数据迁移不是一次性迁移,而是等到访问到具体某个bucket时才将数据从旧bucket中迁移到新bucket中
- 一次性迁移会涉及到cpu资源和内存资源的占用,在数据量较大时,会有较大的延时,影响正常业务逻辑。因此Go采用渐进式的数据迁移,每次最多迁移两个bucket的数据到新的buckets中(一个是当前访问key所在的bucket,然后再多迁移一个bucket)
- cpu资源:扩容时需要迁移map中oldbuckets的元素,其中的rehash操作会消耗cpu的计算资源,有可能会影响到用户协程的调度
18、golang的map为什么是无序的?
使用range多次遍历map时输出的key和value的顺序可能不同。原因:
- 随机起点遍历:每次遍历时,都会从一个随机值序号的bucket,再从其中随机的cell开始后续按序遍历。
- 扩容导致的顺序变化:但map在扩容后,会发生key的迁移,原来落在一个bucket中的key,迁移后,有可能会落到其他bucket中了。
如果想顺序遍历map,需要对map key先排序,再按照key的顺序遍历map
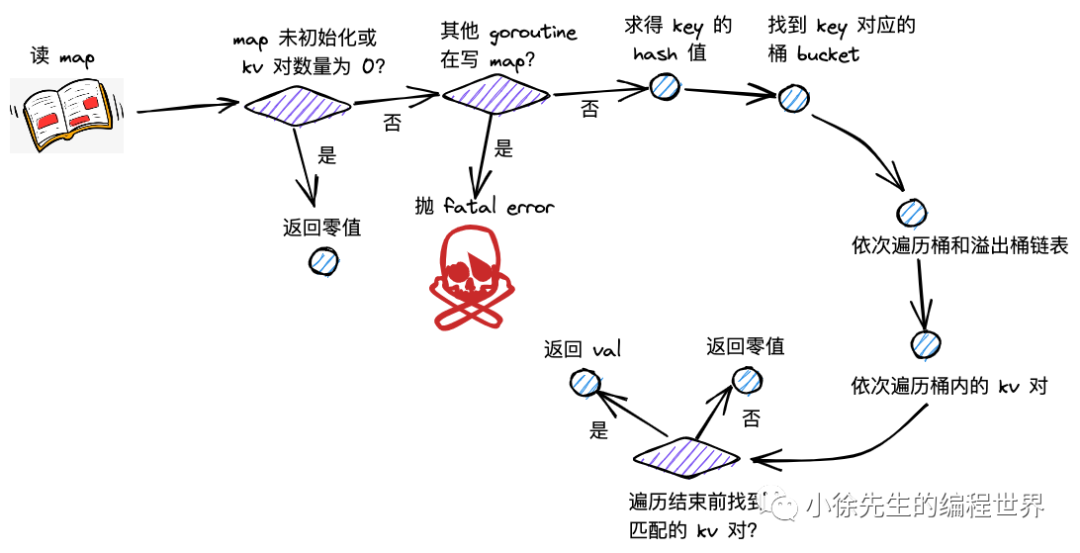
19、Golang的map如何查找?
[1] 写保护检测
函数首先会检查map的标志位flags。如果flags的写标志位此时被置1了,说明有其他协程在执行“写”操作,进而导致程序panic,说明map不是线程安全的
if h.flags&&hashWriting!=0{
throw("concurrent map read and map write")
}
[2] 计算hash值
hash := t.hasher(key, uintptr(h.hash0)
key经过哈希函数计算后,得到的哈希值如上,不同类型的key会有不同的hash函数
[3] 找到hash对应的bucket
哈希值的低B个bit位,用来定位key所存放的bucket。如果正在扩容中,并且定位到旧bucket数据还未完成迁移,则用旧的bucket(扩容前的bucket)
//计算哈希值
hash := t.hasher(key, uintptr(h.hash0))
//计算桶掩码,比如111
m := bucketMask(h.B)
//定位到桶:hash&m得到bucket号,计算该bucket的内存地址
b := (*bmap)(add(h.buckets, (hash&m)*uintptr(t.bucketsize))
//检查是否在扩容,旧bucket不为空,说明正在扩容
if c:= h.oldbucket;c!=nil{
// 扩容类型检查,是否为等量扩容
// 非等量,旧桶数量是新桶数量的一半,掩码m也需要进行调整
if !h.sameSizeGrow(){
m >> 1
}
}
//定位到旧桶
oldb := (*bmap)(add(c, (hash&m)*uintptr(t.bucketsize))
//检查是否已迁移,否,就去旧桶找
if !evacuated(oldb){
b=oldb
}
[4] 遍历bucket查找
tophash值定位:哈希值的高8个bit位,用来快速判断key是否已在当前bucket中(若不在,需要去bucket的overflow中查找)
top := tophash(hash)
func tophash(hash uintptr) uint8 {
//64位系统,PtrSize为8,uint8(hash >> 56),即top取出来的值就是hash的高8位值
top := uint8(hash >> (goarch.PtrSize*8 - 8)
if top < minTopHash {
top += minTopHash
}
return top
}
查找过程:
//遍历bucket链表
for ; b != nil ;b = b.overflow(t) {
for i := unitptr(0); i < bucketCnt; i++ {//遍历bucket中的8个槽位
//比较tophash值
if b.tophash[i] != top {
//如果找到空槽位,说明key不存在
if b.tophash[i] == emptyRest {
break bucketloop
}
continue
}
//tophash匹配,获取key的指针并比较完整key,key定位公式
k := add(unsafe.Pointer(b), dataOffset+i*unitptr(t.keysize))
if t.key.equal(key, k){
//找到匹配的key,获取对应value的指针,value定位公式
e := add(unsafe.Pointer(b), dataOffset+bucketCnt*unitptr(t.keysize)+i*unitptr(t.elemsize))
return e //返回value的指针
}
}
}
dataOffset = unsafe.Offsetof(struct{
b bmap
v int64
}{}.v)
[5] 返回key对应的指针
20、为什么Golang的Map的负载因子是6.5?
负载因子 load factor,衡量当前哈希表中空间占用率的核心指标,每个bucket桶存储的平均个数
负载因子 = 哈希表存储的元素个数 / 桶个数
负载因子与扩容、迁移等重新散列(rehash)行为有直接关系:
在程序运行时,会不断地进行插入、删除等,会导致bucket不均,内存利用率低,需要迁移
在程序运行时,出现负载因子过大,需要做扩容
需平衡buckets的存储空间大小和查找元素时的性能高低
负载因子越大,填入的元素越多,空间利用率就越高,但发生哈希冲突的几率就变大。反之,负载因子越小,填入的元素越少,冲突发生的几率减少,但空间浪费也会变得更多,而且还会提高扩容操作的次数。
Go官方取了一个相对适中的值,把Go中map的负载因子硬编码为6.5.
在Go语言中,当map存储的元素个数大于或等于6.5*桶个数时,就会触发扩容行为
21、Golang map如何扩容
扩容时机:
- 超过负载 map元素个数>6.5*桶个数
- 溢出桶太多

// 检查当前map是否不在扩容过程中;检查添加新元素后,map的负载因子是否会超过阈值;检查map是否有太多的溢出桶
if !h.growing() && (overLoadFactor(h.count+1,h.B)||tooManyOverflowBuckets(h.noverflow, h.8)){
hashGrow(t, h)//如果满足扩容条件,调用此函数开始扩容过程
goto again
}
//判断是否在扩容
func (h *hmap) growing() bool{
return h.oldbuckets != nil
}
func overLoadFactor(count int, B uint8) bool {
return count > bucketCnt && unitptr(count)>loadFactor*bucketShift(B)
}
//bucketCnt=8,一个桶可以装的最大元素个数
//loadFactor=6.5,负载因子,平均每个桶的元素个数
//bucketShift(8),桶的个数

扩容机制:
- 双倍扩容:解决负载过高问题:增加桶的数量(2倍),降低平均每个桶的元素数量,减少哈希冲突概率;提高查找效率
- 等量扩容:解决空间利用不均问题:不增加总桶数,重新分布元素,消除或减少溢出桶,使元素分布更加紧密,提高空间利用率和查询速度
22、Golang的sync.Map
Go语言中并发安全的Map实现
type Map struct {
mu Mutex //互斥锁
//实际存储数据的map;标记amended表示是否有新数据还没放入这个map中
read atomic.Value //无锁化读,包含两个字段 m map[interface)l*entry数据和amended bool标识只读map是否缺失数据
//dirty是另一个存储数据的地方,但访问它时必须先获取锁。存储一些可能还没来得及放到read中的新数据
dirty map[interface}*entry //存在锁的读写
//记录了多少次在read中找不到数据而必须去dirty中查找的次数;当这个数字变大时,系统会把dirty中的数据复制到read中,提高后续查找效率
misses int //无锁化读的缺失次数
}
这种”空间换时间“的设计,牺牲了一些内存(维护两份数据),但换来了极高的并发读取效率,特别适合”读多写少“的场景
读操作优先查看read;只有read中找不到才去dirty查找;当发现经常需要去dirty查找时,misses计数增加,系统会将dirty中的数据全部复制到read数据,提高后续查找速度
type entry struct{
p unsafe.Pointer
}
kv中的value,统一采用unsafe.Pointer的形式进行存储,通过entry.p的指针进行链接。entry.p指向分为三种情况:
- 存活态:正常指向元素,kv对仍未删除
- 软删除态:指向nil,read map和dirty map底层的map结构仍存在key-entry对,但在逻辑上该key-entry对已经被删除,因此无法被用户查询到。举例,书架上标记“已售出”的书本
- 硬删除态:指向固定的全局变量expunged,dirty map中已不存在该key-entry对
无锁化读的read m是dirty的子集,amended标识是true时代表缺失数据,此时再去读dirty,并把misses加1,当misses到一定阈值之后,同步dirty到read m中
range会同步dirty到read的m中:当使用for循环遍历sync.Map时,系统会自动将dirty中的数据同步到read中
和原始map+RWLock的实现并发的方式相比,sync.Map减少了加锁对性能的影响。允许同时读取read map,只有当必要时才去访问dirty map。在“读多写少”的场景中,大部分操作都能在无锁的read map完成,不会相互阻塞。但在写多的场景,会导致read map缓存失效,需要加锁,冲突变多,性能急剧下降。
23、Golang中对nil的slice和空slice的处理是一致的吗?
两种不同的切片初始化方式:
[1] 空切片(Empty Slice):一个已经存在但不包含任何元素的容器
slice := make([]int, 0)
创建一个长度为0的切片,这个切片不是nil,它有确定的底层结构。它像一个空的容器,已经准备好了,只是里面还没有放东西;在内存中,它指向了一个实际存在的(虽然容量为0的)底层数据
[2] nil切片(Nil Slice):一个不存在的容器
var slice []int
声明了一个切片变量,但没有初始化它;这个切片的值是nil,它完全不指向任何底层数组;它像一个尚未制作的容器,连容器本身都不存在;在内存中,它的指针部分为nil
处理上的不同:
JSON序列化时的区别: nil切片会被序列化为null;空切片会被序列化为[]空数组
用作函数返回值:nil切片常用于表示“没有结果”或“出错了”。空切片则表示“有结果,但结果集为空”
24、Golang的内存模型中为什么小对象多了会造成GC压力?
当系统中有大量小对象时:
垃圾回收器需要扫描、标记和处理的对象数量大增;每个对象都有管理开销,哪怕对象本身很小;大量小对象间的引用关系复杂,增加了标记工作量
优化思路:减少对象分配
对象复用:重复使用已有对象而非创建新对象;合并小对象:将多个小对象合并为一个大对象;使用值类型:在栈上分配而非在堆上分配;对象池:使用sync.Pool等技术预先分配和复用对象;减少临时对象:避免在循环中频繁创建临时对象
25、channel的实现原理
[1] 概念
Go中的channel是一个队列,遵循先进先出的原则,负责协程之间的通信
Go语言提倡“不要通过共享内存来通信,而是通过通信来实现内存共享,CSP(CommunicatingSequential Process)并发模型,就是通过goroutine和channel来实现的
[2] 使用场景
停止信号监听、定时任务、生产方和消费方解耦、控制并发数
[3] 底层数据结构
通过var声明或者make函数创建的channel变量是一个存储在函数栈帧上的指针,占用8个字节,指向堆上的hchan结构体,源码包中src/runtime/chan.go定义了hchan的数据结构:
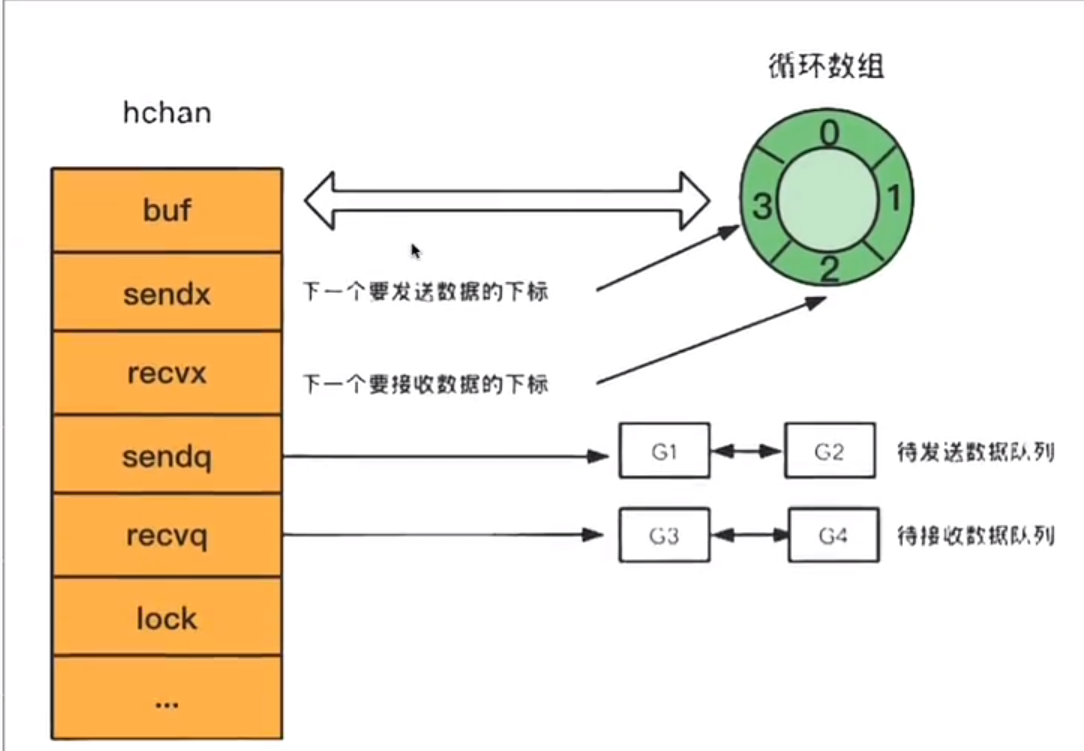
hchan结构体:
type hchan struct{
closed unit32 //channel是否关闭的标志,是否再接收新消息
elemtype *_type //channel中的元素类型
//channel分为无缓冲和有缓存两种。
//对于有缓存的channel存储数据,使用ring buffer(环形缓冲区)来缓存写入的数据,本质是循环数组
//普通数组容量固定更适合指定的空间,弹出元素时,普通数组需要全部都前移。循环数组当下标超过数组容量后会回到第一个位置,需要两个字段记录当前读和写的下标位置
//举例:环形缓冲区像一个旋转餐台,当一个位置的食物被取走后,转动餐台就可以了,不需要移动其他食物
buf unsafe.Pointer //指向底层循环数组的指针(环形缓冲区)
qcount uint //循环数组中的元素数量,记录当前有多少个元素在队列中
dataqsiz uint // 循环数组的长度,表示缓冲区的总大小
elemsize unit16 // 元素的大小,记录每个元素占用的内存大小
sendx unit//下一次写下标的位置,下一个元素应该放在数组的哪个位置
recvx unit//下一次读下标的位置,下一次应该从数组的哪个位置取出元素
recvq waitq // 等待接收数据的goroutine
sendq waitq // 等待发送数据的goroutine
lock mutex //互斥锁,确保同一时间只有一个goroutine可以修改channel的内部状态
}
等待对列
type waitq struct{
first *sudog //头节点
last *sudog //尾节点
}
type sudog struct{
g *g //哪个协程在等待
next *sudog
prev *sudog
elem unsafe.Pointer //等待发送/接收的数据在哪里
c *hchan //等待的是哪个channel
...
}
当channel不能立即满足操作时(比如向已满的channel发送数据,或从空channel接收数据),goroutine就会被包装成一个sudog结构,插入到相应的等待对列(sendq或recvq)中。当条件满足时(有新数据或有空间),channel会从对列中唤醒合适的goroutine继续执行。
channel的创建方式
make(chan T, cap)
T是channel传输数据的类型,cap是可选的缓冲区大小
go编译器会将它转换为对makechan64或makechan函数的调用。
func makechan64(t *chantype, size int64) *chan {
//比喻:从一个大杯子倒水到一个小杯子,再倒回大杯子的过程。如果小杯子装不下(int容量不足),水就会溢出(数值被截断),倒回大杯子后的水量就会与原始水量不同
if int64(int(size)) != size {
panic(panicError("makechan: size out of range"))
}
return makechan(t, int(size))
}
channel创建时的安全检查:
- 元素大小限制:每个元素大小不能超过64KB
- 元素对齐要求:元素的内存对齐大小不能超过8字节
- 总内存检查:计算出的总内存大小不能超过系统限制
不同类型的channel的内存分配策略:
- 无缓冲channel:只为channel结构体本身分配内存;就像只准备了一个传递窗口,没有额外的等待区域;发送者必须等到有人接收,接收者必须等到有人发送
- 有缓存且元素不含指针的channel:为hchan结构体和底层数据分配一块连续的内存。想象成:在同一个大房间里设置了接待区和等候区,紧密相连。这样做可以提高内存访问效率,减少内存碎片
- 有缓冲且元素含指针的channel:为hchan结构体和底层数据分配不同的内存块。想象成:接待区和等候区在不同的房间,但有明确的指引。这样做是为了方便垃圾回收系统追踪和管理指针引用关系。
发送
发送操作,编译时转换为runtime.chansend函数
//4个参数: c, 指向channel指针;ep, 指向要发送数据的指针;block,是否是阻塞式发送;callerpc,调用该函数的代码位置信息
func chansend(c *hchan, ep unsafe.Pointer, block bool, callerpc uintptr) bool
阻塞式发送与非阻塞式发送
阻塞式:调用chansend函数,并且block=ture
ch <- 10
非阻塞式:调用chansend函数,并且block=false
select{
case ch <- 10:
...
default
}
**阻塞式发送:**普通的channel发送操作会阻塞当前goroutine,直到数据被接收
非阻塞式发送:在select语句中带有default分支的发送操作,如果不能立即发送则执行default分支而不阻塞
发送数据时的执行步骤:检查和发送数据
- 如果channel的读等待队列存在接收者goroutine,将数据直接发送给第一个等待的goroutine,唤醒接收的goroutine
- 如果channel的读等待队列不存在接收者goroutine
如果循环数组buf未满,那么将会把数据发送到循环数组buf的队尾
如果循环数组buf已满,这个时候就会走阻塞发送的流程,将当前goroutine加入写等待队列,并挂起等待唤醒
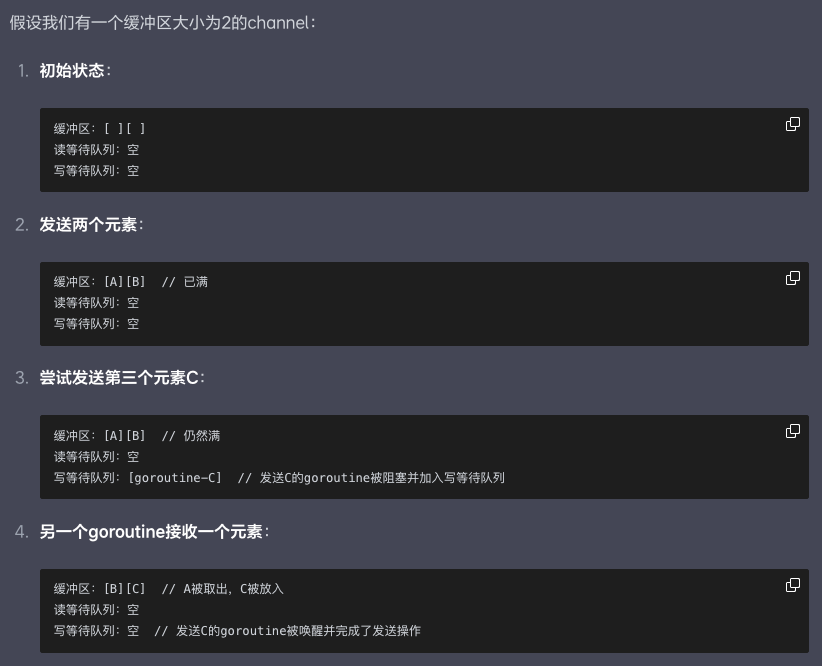
接收
//3个参数:channel指针,存放接收数据的内存位置指针,是否以阻塞方式接收
//返回:是否被选中,是否成功接收数据
func chanrecv(c *hchan, ep unsafe.Pointer, block bool) (selected, received bool)
数据接收流程:检查和接收数据
- 写等待队列有发送者的情况
当有goroutine正在等待发送数据时(写等待队列非空):
[1] 对于无缓冲channel:直接从等待的发送者那里获取数据,类似于接力棒传递,然后唤醒那个发送者goroutine继续执行
[2] 对于已满的有缓冲区channel:先取出缓冲区队首的数据给接收者,然后把等待发送的goroutine的数据放入缓冲区末尾,最后唤醒那个发送者。
写等待队列没有发送者的情况
如果channel的写等待队列不存在发送者goroutine
[1] 如果循环数组buf非空,将循环数组buf的队首元素拷贝给接收变量
[2] 如果循环数组buf未空,这时会走阻塞接收流程,将当前goroutine加入读等待队列,并挂起等待唤醒
指针类型元素的内存处理:
当通道的元素类型包含指针时,确实需要单独分配内存空间的原因主要有以下两个方面:
[1] 避免竞态条件:在多个goroutine之间共享内存时,需要确保内存的安全和一致性。当通道的元素类型为指针时,不同goroutine可能会同时修改或访问同一指针指向的内存区域,造成竞争条件。为了避免这种情况,通道会对每个元素都单独分配内存空间,确保每个goroutine都持有独立的内存副本,避免竞争条件的发生。
package main
import (
"fmt"
"sync"
)
func main() {
ch := make(chan *struct{ value int }, 1)
var wg sync.WaitGroup
// 初始数据
data := &struct{ value int }{0}
ch <- data // 将指针放入channel
// 启动100个goroutine
for i := 0; i < 100; i++ {
wg.Add(1)
go func() {
// 从channel获取指针
ptr := <-ch
// 修改数据
ptr.value++
// 放回channel
ch <- ptr
wg.Done()
}()
}
wg.Wait()
result := <-ch
fmt.Println("最终值:", result.value) // 总是100,因为channel保证了顺序访问
}
[2] 管理生命周期:通道作为一种线程安全的数据传输机制,其内部会负责管理元素的生命周期。当通道的元素类型为指针时,通道会确保在元素被发送或接收完成后,正确释放对应的内存空间。通过单独分配内存空间,通道可以更好地管理元素的生命周期,防止内存泄露等问题的发生。
package main
import (
"fmt"
"time"
)
type Message struct {
Content string
}
func main() {
ch := make(chan *Message, 1)
// 发送方:创建一个消息并发送指针
originalMsg := &Message{Content: "Hello"}
fmt.Printf("发送前:原始地址=%p,内容=%s\n", originalMsg, originalMsg.Content)
ch <- originalMsg // 发送指针到channel
// 修改原始消息(在发送后)
originalMsg.Content = "Modified after sending"
fmt.Printf("修改后:原始地址=%p,内容=%s\n", originalMsg, originalMsg.Content)
// 接收方:从channel接收消息
receivedMsg := <-ch
fmt.Printf("接收到:接收地址=%p,内容=%s\n", receivedMsg, receivedMsg.Content)
/*
输出将显示:
发送前:原始地址=0xc000010250,内容=Hello
修改后:原始地址=0xc000010250,内容=Modified after sending
接收到:接收地址=0xc000010250,内容=Modified after sending
这说明channel传递的是指针的值,而不是创建新的副本
*/
// 但如果我们使用有缓冲channel且不立即接收,channel会如何处理?
bufCh := make(chan *Message, 5)
// 通过函数作用域演示生命周期管理
func() {
localMsg := &Message{Content: "Temporary message"}
fmt.Printf("局部变量:地址=%p\n", localMsg)
bufCh <- localMsg // 发送局部变量到channel
}() // 函数结束,localMsg已超出作用域
// 等待一下,确保垃圾回收有机会运行
time.Sleep(100 * time.Millisecond)
// 尽管原始变量已超出作用域,但channel保存了数据的副本
survivedMsg := <-bufCh
fmt.Printf("保存的消息:地址=%p,内容=%s\n", survivedMsg, survivedMsg.Content)
// 输出显示消息仍然可用,channel确保了数据的生命周期延长
}
它会确保通过它传递的指针所指向的数据在整个传输和处理过程中保持有效。这种机制使得我们可以安全地在goroutine之间共享数据,而不必担心内存管理问题
channel是并发安全的
通道的发送和接收操作是原子的,即一个完整的发送和接收操作是一个原子操作,不会被其他goroutine中断。
当一个 goroutine向channel发送数据时,如果channel已满,则发送操作会被阻塞,直到有其他goroutine从该channel中接收数据后释放空间,发送操作才会继续执行。该情况下,channel内部会获取一个锁,保证只有一个goroutine能够往其中写入数据。
当一个goroutine从channel中接收数据时,如果channel为空,则接收操作会被阻塞,直到有其他goroutine向该channel中发送数据后才能继续执行。该情况下,channel内部也会获取一个锁,保证只有一个goroutine能够从其中读取数据。
26、channel是异步的
channel存在3种状态:
- nil,未初始化的状态,只进行了声明或手动赋值为nil
- active,正常的channel,可读或可写
- closed,已关闭,对已关闭channel读写都会panic
27、channel死锁场景
[1] 非缓存channel只写不读
func deadlock1(){
ch:=make(chan int)
ch <- 3 //这里会发生一直阻塞的情况,执行不到下一句
}
[2] 非缓存channel读在写后面
func deadlock2(){
ch := make(chan int)
ch <- 3 // 这里会发生阻塞的情况,执行不到下一句
num := <-ch
fmt.Println("num=", num)
}
[3] 缓存channel写入超过缓存区数量
func deadlock3(){
ch := make(chan int, 3)
ch <- 3
ch <- 4
ch <- 5
ch <- 6
}
[4] 空读
func deadlock4(){
ch := make(chan int)
fmt.Println(<-ch)
}
[5] 多个协程相互等待
func deadlock5(){
ch1 := make(chan int)
ch2 := make(chan int)
go func(){
for{
select {
case num := <-ch1:
fmt.Println("num=", num)
ch2 <- 100
}
}
for{
select {
case num := <-ch2:
fmt.Println("num=", num)
ch1 <-300
}
}
}
}
28、golang互斥锁的实现原理
互斥锁底层结构是sync.Mutex结构体,位于src/sync/mutex.go中
type Mutex struct{
state int32
sema int32
}
state表示锁的状态,有锁定、被唤醒、饥饿模式等,并且是用state的二进制来标识的,不同模式下会有不同的处理方式
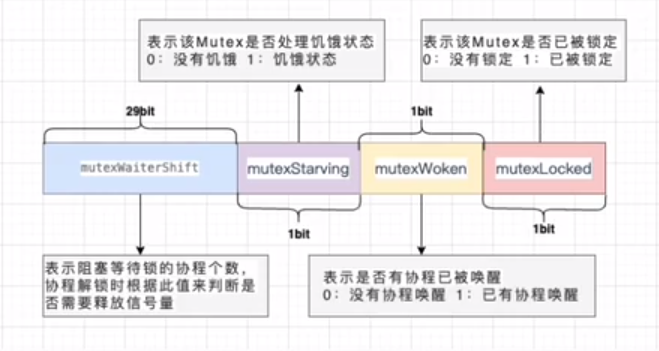
state字段表示当前互斥锁的状态信息,int32类型,低3位的二进制均有相应的状态含义。
mutexLocked是state中的低1位,代表该互斥锁是否被加锁
mutexWoken:低2位,代表互斥锁上是否有被唤醒的goroutine
mutexStarving:低3位,代表当前互斥锁是否处于饥饿模式
mutexWaiterShift:state剩下的29位用于统计在互斥锁上的等待队列中goroutine数目(waiter)
**正常模式:**新来的goroutine和被唤醒的goroutine竞争,谁抢到锁谁先用;**饥饿模式:**锁直接交给等待时间最长的goroutine,新来的不参与竞争
sema表示信号量,mutex阻塞队列的定位是通过这个变量来实现的,从而实现goroutine的阻塞和唤醒
sema锁是信号量/信号锁。uint32,同时可并发数量。
每一个sema锁都对应一个SemaRoot结构体,其中有一个平衡二叉树用于协程队列;
获取sema锁,将sema值减一,如果这个操作成功,便获取了锁 atomic.Xadd(addr, -1),如果减1后结果>=0,表示成功获取锁,goroutine继续执行;如果减1后结果<0,表示没有可用资源,当前goroutine需要被阻塞
释放sema锁,将sema值加一,如果这个操作成功,atomic.Xadd(addr, 1);如果加1后结果<=0,说明有goroutine在等待资源,需唤醒一个等待的goroutine;如果加1后结果>0,说明没有goroutine在等待,只需增加计数器
获取锁的时候,如果uint32值一开始就为0,或减到了0,则协程休眠,goparklock(),进入堆树等待
29、Goroutine的抢锁模式
[1] 正常模式(非公平锁)
- 在刚开始时,处于正常模式(Barging),当一个G1持有着一个锁的时候,G2会自旋地去尝试获取这个锁
- 当自旋超过4次还没有能获取到锁时,G2会被加入到获取锁的等待队列里,并阻塞等待唤醒goroutine,新请求锁的goroutine具有优势:它正在cpu上执行,而且可能有好几个,所以刚唤醒的goroutine很大可能在锁竞争中失败,长时间获取不到锁,就会切换饥饿模式
[2] 饥饿模式(公平锁)
当一个goroutine等待锁时间超过1毫秒时,它可能会遇到饥饿问题。在版本1.9中,这种场景下Go mutex切换到饥饿模式(handoff),解决饥饿问题
starving = runtime_nanotime() - waitStartTime > 1e6
队列中排在第一位的goroutine(队头),饥饿模式下,新进来的goroutine不会参与抢锁也不会进入自旋状态,会直接进入等待队列的尾部,这样很好地解决了老的goroutine一直抢不到锁的场景
从饥饿模式回归正常模式需满足下述条件之一:
G的等待的时间是否小于1ms;等待队列已经全部清空了
Go的抢锁过程,在正常模式和饥饿模式中来回切换
30、读写锁原理
RWMutex的5个方法:
Lock/Unlock–写操作时调用的方法
RLock/RUnlock–读操作时调用的方法
RLocker–读操作时返回的Locker接口的对象,它的Lock方法会调用RLock,Unlock方法会调用RUnlock方法
type RWutex struct{
w Mutex //互斥锁
writerSem uint32 //信号量,写锁等待读取完成
readerSem uint32 //信号量,读锁等待写入完成
readerCount int32 //当前正在执行的读操作的数量,正数表示读,负数表示写
readerWait int32 //写操作被阻塞时等待的读操作数量
}
读锁操作
1、当一个协程想要读取共享资源时,首先会通过一个原子操作,将readerCount加1
2、如果readerCount>=0,表示当前没有写锁在使用,那么这个协程可以立即获得读权限并返回
3、如果readerCount<0,表示当前有写锁正在使用资源,那么读锁需要借助readSem排队等待。
4、释放读锁时,如果没有写锁在等待,只需将readerCount减1即可
5、如果有写锁在等待,则调用rUnlockSlow判断当前是否为最后一个释放的读锁,如果是则唤醒等待的写锁
写锁操作
1、写锁申请时必须先获取互斥锁。接着readerCount减去rwmutexMaxReaders阻止后续读操作
2、获取到互斥锁并不一定能直接获取写锁,如果当前已经有其他goroutine持有互斥锁的读锁,那么当前协程加入全局等待队列并进入休眠状态,当最后一个读锁被释放时,会唤醒该协程
3、解锁时,调用Unlock方法,将readerCount加上rwmutexMaxReader,表示不会阻塞后续的读锁,依次唤醒所有等待中的读锁,当所有的读锁唤醒完毕后会释放互斥锁
31、Golang的原子操作有哪些?
Go atomic包是最轻量级的锁(无锁结构),可以在不形成临界区和创建互斥量的情况下完成并发安全的值替换操作,只支持int32/int62/uint32/uint64/uintptr这几种数据类型的一些基础操作(增减、交换、载入、存储等)
原子操作仅会由一个独立的cpu指令代表和完成。原子操作是无锁的,常常直接通过cpu指令直接实现。事实上,其他同步技术的实现常常依赖于原子操作。
使用场景
对某个变量并发安全的修改,保证对变量的读取或修改期间不会被其他协程所影响。
atomic包提高的原子操作能够确保任意时刻只有一个goroutine对变量进行操作,善用atomic能够避免程序中出现大量的锁操作。
atomic操作的对象是一个地址,你需要把可寻址的变量的地址作为参数传递给方法,而不是把变量的值传递给方法
增减操作
func AddInt32(addr *int32,delta int32)(new int32)
func AddInt64(addr *int64, delta int64) (new int64)
func AddUint32(addr *uint32, delta uint32)(new uint32)
func AddUint64(addr suint64,delta uint64)(new uint64)
func AddUintptr(addr *uintptr,delta uintptr) (new uintptr)
func add(addr *int64, delta int64) {
atomic.AddInt64(addr, delta)//加操作
fmt.Println("add opts: ",*addr)
}
载入操作
func LoadInt32( addr *int32)(val int32)
func LoadInt64(addr *int64)(val int64)
func LoadPointer(addr *unsafe.Pointer) (val unsafe.Pointer)
func LoadUint32( addr *uint32)(val uint32)
func LoadUint64(addr *uint64) (val uint64)
func LoadUintptr(addr *uintptr) (val uintptr)
//特殊类型:Value类型,常用于配置变更
func (v *Value) Load() (x interface{}){}
比较并交换
CAS 用来实现乐观锁
func CompareAndSwapInt32(addr *int32,old,new int32)(swapped bool)
func CompareAndSwapInt64(addr *int64,old,new int64) (swapped bool)
func CompareAndSwapPointer(addr *unsafe.Pointer,old,new unsafe.Pointer) (swapped bool)
func CompareAndSwapUint32(addr *uint32,old,new uint32)(swapped bool)
func CompareAndSwapUint64(addr *uint64,old,new uint64) (swapped bool)
func CompareAndSwapUintptr(addr *uintptr,old,new uintptr) (swapped bool)
该操作在进行交换前首先确保变量的值未被更改,即仍然保持参数old所记录的值,满足此前提下才进行交换操作。
乐观锁:假设数据一般情况下不会发生冲突,只在数据更新时检查是否有冲突,如果有冲突就重试或放弃操作
32、原子操作和锁的区别
1、原子操作由底层硬件支持,而锁是基于原子操作+信号量完成的。若实现相同功能,原子操作通常会更有效率
2、原子操作是单个指令的互斥操作;互斥锁/读写锁是一种数据结构,可以完成临界区(多个指令)的互斥操作,扩大原子操作的范围
3、原子操作是无锁操作,属于乐观锁;互斥锁/读写锁属于悲观锁
4、原子操作存在于各个指令/语言层级,比如“机器指令层级的原子操作”,“汇编指令层级的原子操作”,"Go语言层级的原子操作“等
5、锁也存在于各个指令/语言层级中,比如”机器指令层级的锁“,”汇编指令层级的锁“,”Go语言层级的锁“等
33、Goroutine的实现原理
Goroutine是一种Go语言的协程(轻量级线程),是Go支持高并发的基础,属于用户态的线程,由Go runtime管理而不是操作系统。
底层数据结构
type g struct{
goid int64 //唯一的goroutine的ID
sched gobuf //goroutine切换时,用于保存g的上下文
stack stack //栈,存放局部变量和函数调用信息
gopc //创建这个goroutine的go语句的程序计数器
startpc uintptr //goroutine函数的程序计数器
}
// 保存工作状态的记事本
type gobuf struct{
sp uintptr //栈指针位置
pc uintptr //运行到的程序位置
g guintptr //指向goroutine
ret uintptr //保存系统调用的返回值
...
}
//goroutine的工作空间
type stack struct{
lo uintptr //栈的下界内存地址
hi uintptr //栈的上界内存地址
}
goroutine的状态流转
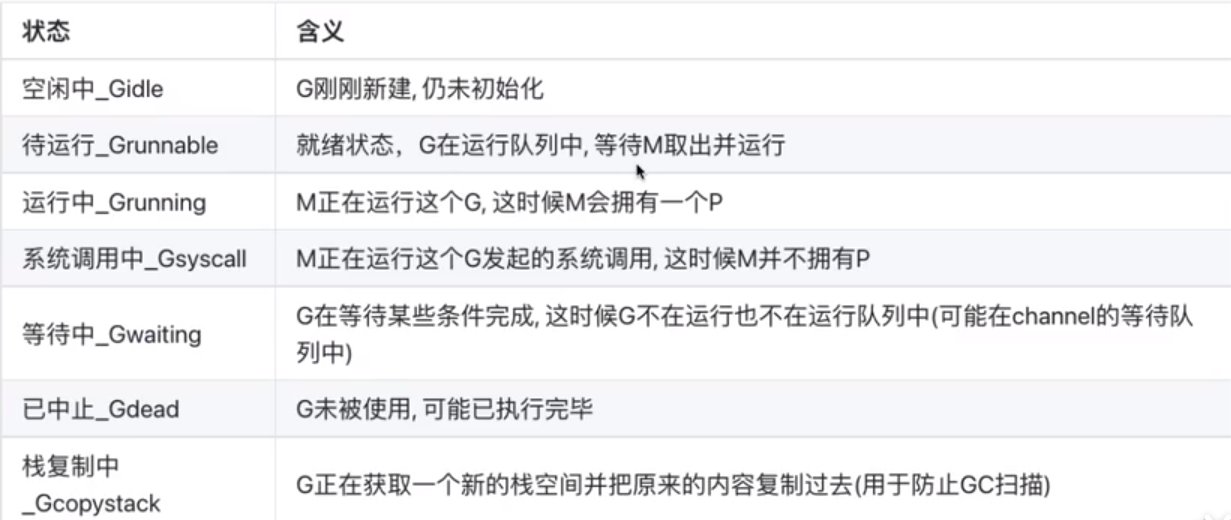
1、创建:go关键字会调用底层函数runtime.newproc()创建一个goroutine,调用该函数之后,goroutine会被设置成runnable状态
创建好的这个goroutine会新建一个自己的栈空间,同时在G的sched中维护栈地址与程序计数器这些信息。每个G在被创建之后,都会被优先放入到本地对列中,如果本地对列已经满了,就会被放入到全局队列中。
2、运行:goroutine本身只是一个数据结构,真正让goroutine运行起来的是调度器。Go实现了一个用户态的调度器(GMP模型),这个调度器充分利用现代计算机的多核特性,同时让多个goroutine运行,同时goroutine设计的很轻量级,调度和上下文切换的代价都比较小。
调度时机:新起一个协程、协程执行完毕;会阻塞的系统调用(比如文件io、网络io);channel、mutex等阻塞操作;time.sleep;垃圾回收之后;主动调用runtime.Gosched();运行过久或系统调用过久等等

1、每个M开始执行P的本地对列中的G,goroutine会被设置成running状态
2、任务获取机制:如果某个M的本地对列中的G都执行完成之后,然后就会去全局队列中拿G。每次去全局队列拿G的时候,都需要上锁,避免同样的任务被多次拿。不会一次拿太多,遵循:
N = min(全局队列长度/cpu核心数,全局队列长度/2)
如果全局队列都被拿完了,而当前M也没有更多的G可以执行时,它会去其他P的本地对列中拿任务,work stealing机制。每次拿走一半的任务,向下取整。
当全局队列为空,M也没办法从其他的P中拿任务的时候,就会让自身进入自旋状态,等待有新的G进来。最多只会有cpu核心数个M在自旋状态,过多M的自旋会浪费cpu资源。
3、阻塞:channel的读写操作、等待锁、等待网络数据、系统调用等都有可能发生阻塞,会调用底层函数runtime.gopark(),会让出CPU时间片,让调度器安排其他等待的任务运行,并在下次某个时候从该位置恢复执行。goroutine会被设置成waiting状态。
4、唤醒:处于waiting状态的goroutine,在调用runtime.goready()函数之后会被唤醒。唤醒的goroutine会被重新放到M对应的上下文P对应runqueue中,等待被调度。goroutine会被设置成runnable状态。
5、退出:当goroutine执行完成后,会调用底层函数runtime.Goexit(),goroutine会被设置成dead状态
34、Goroutine的泄露
泄漏原因:
[1] Goroutine内进行channel/mutex等读写操作被一直阻塞
[2] Goroutine内的业务逻辑进入死循环,资源一直无法释放
[3] Goroutine内的业务逻辑进入长时机等待,有不断新增的goroutine进入等待
35、怎么查看Goroutine的数量?怎么限制Goroutine的数量?
使用函数runtime.NumGoroutine()函数
import (
"fmt"
"runtime"
)
func main() {
fmt.Println("当前goroutine数量:", runtime.NumGoroutine())
// 创建一些goroutine...
fmt.Println("创建后goroutine数量:", runtime.NumGoroutine())
}
使用有缓存的通道作为信号量,可以限制Goroutine的数量
// 创建一个有10个缓冲的通道,意味着最多允许10个并发goroutine
var sem = make(chan struct{}, 10)
func worker(job int) {
fmt.Println("完成工作:", job)
}
func main() {
for i := 0; i < 100; i++ {
// 获取令牌,如果通道已满则阻塞
sem <- struct{}{}
go func(job int) {
defer func() {
// 工作完成后释放令牌
<-sem
}()
worker(job)
}(i)
}
}
36、Goroutine与线程的区别
1、一个线程可以有多个协程
2、线程和进程是操作系统级别的概念,由操作系统内核负责调度。当一个线程执行时,它会一直执行直到:被操作系统强制暂停(抢占式调度)、主动放弃执行(如等待I/O操作)、执行结束
协程则采用协作式调度,主要是在用户空间运行。它们可以主动让出执行权,使得一个线程上的多个协程能够交替执行,实现并发。
3、协程可以保留上一次调用时的状态。
4、协程需要线程来承载运行。线程是操作系统分配CPU时间片的基本单位,直接与CPU执行相关。协程是组织好的代码流程,最终还是需要线程来执行这些代码。
37、Go的struct能不能比较?
相同struct类型可以比较,不同struct类型的不可以比较,编译都不过,类型不匹配。
1、相同struct类型的可以比较
两个相同类型的结构体变量可以直接使用==或!=运算符进行比较。当所有对应字段的值都相等时,这两个结构体才被认为是相等的。
package main
import "fmt"
// 定义一个Person结构体
type Person struct {
Name string
Age int
}
func main() {
// 创建两个相同类型的结构体实例
p1 := Person{Name: "张三", Age: 25}
p2 := Person{Name: "张三", Age: 25}
p3 := Person{Name: "李四", Age: 30}
// 相同类型的结构体可以直接比较
fmt.Println("p1 == p2:", p1 == p2) // 输出: true (所有字段值都相等)
fmt.Println("p1 == p3:", p1 == p3) // 输出: false (字段值不同)
// 还可以比较不等
fmt.Println("p1 != p3:", p1 != p3) // 输出: true
}
相同类型的结构体,即使是通过类型别名定义的,也可以比较:
type Employee Person
func compareAliasTypes() {
p := Person{Name: "王五", Age: 35}
// 使用类型转换可以比较
e := Employee(p)
// 注意:必须先转换为相同类型才能比较
// fmt.Println(p == e) // 这行会编译错误
fmt.Println(p == Person(e)) // 输出: true
}
2、不同struct类型的不可以比较
如果两个结构体是不同的类型(即使它们有完全相同的字段),它们之间不能直接比较,编译会报错:
package main
import "fmt"
type Person struct {
Name string
Age int
}
// 与Person有完全相同字段的另一个类型
type Student struct {
Name string
Age int
}
func main() {
p := Person{Name: "张三", Age: 25}
s := Student{Name: "张三", Age: 25}
// 编译错误: invalid operation: p == s (mismatched types Person and Student)
// fmt.Println(p == s)
// 正确做法是先转换类型
fmt.Println(p == Person(s)) // 这样可以编译通过
}
3、结构体可比较条件
结构体只有在其所有字段都可比较的情况下才可比较。包含不可比较字段的结构体也是不可比较的
package main
import "fmt"
type ComparablePerson struct {
Name string
Age int
// 所有字段都是可比较的
}
type NonComparablePerson struct {
Name string
Age int
Hobby []string // 切片是不可比较的
}
func main() {
p1 := ComparablePerson{Name: "张三", Age: 25}
p2 := ComparablePerson{Name: "张三", Age: 25}
// 可以比较,因为所有字段都是可比较的
fmt.Println(p1 == p2) // 输出: true
n1 := NonComparablePerson{Name: "李四", Age: 30, Hobby: []string{"读书", "旅游"}}
n2 := NonComparablePerson{Name: "李四", Age: 30, Hobby: []string{"读书", "旅游"}}
// 编译错误: invalid operation: n1 == n2 (struct containing []string cannot be compared)
// fmt.Println(n1 == n2)
// 如果需要比较含有不可比较字段的结构体,可以使用反射或自定义比较函数
}
不可比较的字段类型包括:
切片 (slice)
映射 (map)
函数 (function)
包含上述类型字段的结构体
如果需要比较包含不可比较字段的结构体,可自定义比较方法或使用reflection进行深度比较
import "reflect"
// 使用反射深度比较
equal := reflect.DeepEqual(n1, n2)
fmt.Println("使用反射比较:", equal) // 输出: true
38、Go的slice如何扩容?
Go 1.18之前的扩容规则:
1、大容量直接满足:如果需要的新容量超过当前容量的2倍,Go会直接使用需要的容量值,不会按倍数增长
如果 cap(新) > 2 * cap(旧) 则 newcap = cap(新)
2、小切片翻倍增长:如果切片较小(长度小于1024),则简单地将容量翻倍
如果 len(旧) < 1024 则 newcap = 2 * cap(旧)
3、大切片增长更节制:如果切片已经较大(长度>=1024),则增长比例降低到每次增加25%
如果 len(旧) >= 1024 则 newcap = cap(旧) * 1.25
4、防止溢出保护:如果计算出的新容量溢出了整数范围,则直接使用请求的容量
Go 1.18之后的扩容规则
1、小容量翻倍不变:如果容量小于256,依然是每次扩容为原来的2倍
如果 cap(旧) < 256 则 newcap = 2 * cap(旧)
2、大容量增长更精确:如果容量大于等于256,使用新公式:(旧容量+3*256)/4,也就是1.25倍+192
如果 cap(旧) >= 256 则 newcap = cap(旧) + (cap(旧)+3*256)/4

39、Go语言中的内存泄漏与检测
1、Goroutine的内存消耗:每个Goroutine都需要占用内存来存储:执行栈(初始为2KB,可增长到1GB)、程序计数器(记录执行位置)、上下文信息(局部变量、参数等)
2、泄漏原理:如果程序不断创建新的Goroutine,却不终止旧的,这些Goroutine会一直占用内存,导致内存不断增长而不释放,最终可能耗尽系统内存。
3、检测方法:Go提供了两种主要工具来检测这类问题:
pprof:Go语言内置的性能分析工具
Gops:用于查看和诊断当前系统中运行的Go进程
使用pprof检测
import (
"net/http"
_ "net/http/pprof" // 导入pprof
)
func main() {
// 启动pprof服务
go http.ListenAndServe(":6060", nil)
// 你的程序代码...
}
检测步骤:
- 运行程序
- 访问 http://localhost:6060/debug/pprof/
- 点击"goroutine"查看所有运行的goroutine
- 使用命令行工具进行深入分析:
go tool pprof http://localhost:6060/debug/pprof/heap
使用Gops检测
# 安装gops
go get -u github.com/google/gops
# 查看系统中的Go进程
gops
# 查看特定进程的内存统计
gops memstats <pid>
# 查看进程中的goroutine数量
gops stats <pid>
40、interface 底层原理
type iface struct {
tab *itab //存储接口的类型信息,记录这个接口是什么类型、能做什么
data unsafe.Pointer //存储接口动态类型的数据指针,指向具体实现接口的那个值
}
接口类型信息表itab
type itab struct {
inter *interfacetype //类型的静态类型信息
_type *_type //接口存储的动态类型,实际类型的详细信息
hash uint32 //接口动态类型的唯一标识,_type中hash的副本,快速判断类型是否相同
_ [4]byte //用于内存对齐
fun [1]uintptr //动态类型的函数指针列表,存放所有方法的地址
}
类型信息结构(_type)
type _type struct {
size uintptr //类型大小(占多少字节)
ptrdata uintptr //指针数据区域大小
hash uint32 //类型的哈希值(唯一标识)
tflag tflag //类型的特殊标记
align uint8 //内存对齐大小
fieldAlign uint8 //字段对齐大小
kind uint //类型的种类
equal func(unsafe.Pointer, unsafe.Pointer) bool //判断两个该类型值是否相等的函数
gcdata *byte //垃圾回收相关数据
str nameoff //类型名称在二进制文件中的偏移量
ptrToThis typeoff //指向自身类型信息的指针偏移量
}
接口类型定义(interfacetype)
type interfacetype struct{
typ _type //接口本身的类型信息
pkgpath name //接口所在的包名
mhdr []imethod //接口中所有方法的信息列表
}
接口interface包含两种类型:
一种是接口自身的类型,成为接口的静态类型,比如io.Reader等,用于确定接口类型,直接存储在itab结构体中
一种是接口所持有数据的类型,称为接口的动态类型,用于在反射或者接口转换时确认所持有数据的实际类型,存储在运行时runtime/_type结构体中
var reader io.Reader // 静态类型是io.Reader,动态类型是nil(还没赋值)
reader = bytes.NewBuffer([]byte("hello"))
// 静态类型依然是io.Reader
// 动态类型变成了*bytes.Buffer
reader = &os.File{}
// 静态类型依然是io.Reader
// 动态类型变成了*os.File
类似于:一个鞋盒(接口)可以装各种鞋(具体类型)。盒子始终是鞋盒(静态类型),但里面可能是运动鞋、皮鞋或拖鞋(动态类型)。
hash是一个uint32类型的值,实际上可以看作是类型的校验码,当将接口转换成具体的类型的时候,会通过比较二者的hash值确定是否相等,只有hash相等,才能进行转换。
package main
import "fmt"
type Reader interface {
Read(p []byte) (n int, err error)
}
type StringReader string
func (s StringReader) Read(p []byte) (n int, err error) {
copy(p, s)
return len(s), nil
}
type ByteReader []byte
func (b ByteReader) Read(p []byte) (n int, err error) {
copy(p, b)
return len(b), nil
}
func main() {
// 创建接口变量
var r Reader
r = StringReader("hello")
// 类型断言 - 这里会用到hash进行快速类型匹配
if str, ok := r.(StringReader); ok {
fmt.Println("成功转换为StringReader:", string(str))
}
// 类型断言到错误类型 - hash不匹配导致失败
if b, ok := r.(ByteReader); ok {
fmt.Println("成功转换为ByteReader:", string(b)) // 不会执行
} else {
fmt.Println("类型断言失败 - hash不匹配")
}
}
func最终指向的是接口的方法集,即存储了接口所有方法的函数的指针。通常比较接口的方法集和类型的方法集,用于判断类型是否实现了该接口。看作一个虚函数表,运行时多态,动态分派效率高,编译时安全。
package main
import "fmt"
type Writer interface {
Write(p []byte) (n int, err error)
}
type ConsoleWriter struct {
prefix string
}
// 实现Write方法
func (c ConsoleWriter) Write(p []byte) (n int, err error) {
fmt.Printf("%s: %s\n", c.prefix, string(p))
return len(p), nil
}
func main() {
// 创建接口变量
var w Writer = ConsoleWriter{"日志"}
// 接口方法调用 - 这里使用了fun数组中存储的函数指针
w.Write([]byte("接口调用方法"))
// 幕后发生的事情:
// 1. Go运行时查找w的itab
// 2. 从itab.fun[0]获取Write方法的函数指针
// 3. 调用该函数,传入数据指针和参数
}
空接口
type eface struct {//两个指针,16byte
_type *_type //指向一个内部表
data unsafe.Pointer //指向持有的数据
}
空接口是单独的唯一的一种接口类型,不需要itab中的接口类型字段了;空接口也没有任何方法,不存在itab中的方法集
41、两个interface可以比较吗?
是的,Go中两个接口变量可以直接使用==和!=进行比较,规则如下:
如果两个接口都是nil,则它们相等
如果只有一个是nil,则不相等
如果都不是nil,那么当且仅当满足以下两个条件时,它们才相等:
它们的动态类型相同
它们的动态值相等(根据该类型的比较规则)
var a, b interface{}
fmt.Println(a == b) // true,都是nil
a = 42
fmt.Println(a == b) // false,一个是int,一个是nil
b = 42
fmt.Println(a == b) // true,类型相同(int),值相同(42)
b = "42"
fmt.Println(a == b) // false,类型不同
注意:如果接口的动态类型是不可比较的(如切片、映射、函数),直接比较会导致运行时panic!
1、判断类型是否一样:
reflect.TypeOf(a).Kind() == reflect.TypeOf(b).Kind()
这行代码比较的是两个值的类型种类(Kind),而非具体类型:
a := 42 // int类型
b := int64(42) // int64类型
// Kind()返回类型的"种类",而非具体类型
fmt.Println(reflect.TypeOf(a).Kind() == reflect.TypeOf(b).Kind()) // false
// 因为a是reflect.Int,b是reflect.Int64
c := []int{1, 2}
d := []string{"a", "b"}
fmt.Println(reflect.TypeOf(c).Kind() == reflect.TypeOf(d).Kind()) // true
// 因为它们的Kind都是reflect.Slice,虽然具体类型不同
正确比较具体类型应该是:
reflect.TypeOf(a) == reflect.TypeOf(b)
2、判断两个interface{}是否相等:
reflect.DeepEqual(a, b)
a := []int{1, 2, 3}
b := []int{1, 2, 3}
c := []int{1, 2, 4}
// 切片不能直接用==比较
// fmt.Println(a == b) // 编译错误
// 使用DeepEqual
fmt.Println(reflect.DeepEqual(a, b)) // true
fmt.Println(reflect.DeepEqual(a, c)) // false
// 复杂结构体比较
type Person struct {
Name string
Friends []string
}
p1 := Person{"Alice", []string{"Bob", "Charlie"}}
p2 := Person{"Alice", []string{"Bob", "Charlie"}}
fmt.Println(reflect.DeepEqual(p1, p2)) // true
3、将一个interface{}赋值给另一个interface{}:reflect.ValueOf(&a).Elem().Set(reflect.ValueOf(b))
func main() {
var a interface{}
b := "hello world"
// 通过反射赋值
reflect.ValueOf(&a).Elem().Set(reflect.ValueOf(b))
fmt.Println(a) // "hello world"
// 相当于:a = b
}
42、go 打印时 %v %+v %#v 的区别?
%v 只输出所有的值;
%+v 先输出字段名字,再输出该字段的值;
%#v 先输出结构体名字值,再输出结构体(字段名字+字段的值);
package main
import "fmt"
type student struct {
id int32
name string
}
func main() {
a := &student{id: 1, name: "微客鸟窝"}
fmt.Printf("a=%v \n", a) // a=&{1 微客鸟窝}
fmt.Printf("a=%+v \n", a) // a=&{id:1 name:微客鸟窝}
fmt.Printf("a=%#v \n", a) // a=&main.student{id:1, name:"微客鸟窝"}
}
43、什么是rune类型?
rune类型基础
在Go语言中,rune是一个重要的基本类型,专门用于处理Unicode字符:
- byte (alias for uint8): 表示一个字节(8位),处理ASCII字符
- rune (alias for int32): 表示一个Unicode码点(32位),可以处理任何字符
简单来说,rune能够表示世界上几乎所有的书面字符,而byte只能处理英文字母、数字和符号。
为什么需要rune类型?
在Go中,字符串是以UTF-8编码存储的。UTF-8是一种可变长编码:
- ASCII字符(如英文字母)只占1个字节
- 中文等字符通常占3个字节
- 一些特殊Unicode字符可能占4个字节
因此,当需要处理中文等非ASCII字符时,必须使用rune类型。
44、空 struct{} 占用空间么?用途是什么?
什么是空结构体?
空结构体 struct{} 是Go语言中一个特殊的类型,它不包含任何字段,且不占用任何内存空间(实际上编译器可能会分配一个全局的零字节实例作为所有空结构体的共享实例)。
package main
import (
"fmt"
"unsafe"
)
func main() {
var s struct{}
fmt.Println(unsafe.Sizeof(s)) // 输出: 0
}
空结构体的三大用途
1、将map作为集合Set使用
Go语言没有内置的Set类型,但可以用map[KeyType]struct{}模拟,既节省内存,又能保持高效的查找、添加和删除操作:
package main
import "fmt"
func main() {
// 创建一个字符串集合
set := make(map[string]struct{})
// 添加元素到集合
set["apple"] = struct{}{}
set["banana"] = struct{}{}
set["orange"] = struct{}{}
// 检查元素是否存在
if _, exists := set["apple"]; exists {
fmt.Println("apple 在集合中")
}
// 删除元素
delete(set, "banana")
// 遍历集合
fmt.Println("集合中的水果:")
for fruit := range set {
fmt.Println(fruit)
}
// 获取集合大小
fmt.Printf("集合大小: %d\n", len(set))
}
为什么用struct{}而不用bool?
使用map[string]bool也能实现类似功能,但struct{}不占用额外内存,当集合元素数量庞大时,可以节省大量内存。
2、不发送数据的通道channel
当channel只用于通知或同步时,不需要传递任何数据,使用chan struct{}比其他类型更高效,只用来通知子协程(goroutine)执行任务,或只用来控制协程并发度:
package main
import (
"fmt"
"sync"
"time"
)
func worker(id int, jobs <-chan int, done chan<- struct{}) {
for j := range jobs {
fmt.Printf("工作者 %d 开始处理任务 %d\n", id, j)
time.Sleep(time.Second) // 模拟工作耗时
fmt.Printf("工作者 %d 完成任务 %d\n", id, j)
done <- struct{}{} // 仅发送信号,不传递数据
}
}
func main() {
jobs := make(chan int, 5)
done := make(chan struct{}, 5)
// 启动3个工作协程
for w := 1; w <= 3; w++ {
go worker(w, jobs, done)
}
// 发送5个工作任务
for j := 1; j <= 5; j++ {
jobs <- j
}
close(jobs)
// 等待所有工作完成
for a := 1; a <= 5; a++ {
<-done // 只是等待信号,不关心接收到的值
}
fmt.Println("所有工作已完成")
}
3、仅包含方法的结构体
当你需要一个类型只是为了它的方法,而不需要保存任何状态时,空结构体非常有用:
package main
import "fmt"
// EventEmitter 是一个事件发射器
type EventEmitter struct{}
// 为EventEmitter添加方法
func (e EventEmitter) Emit(event string, data interface{}) {
fmt.Printf("事件 '%s' 被触发,数据: %v\n", event, data)
}
func (e EventEmitter) Subscribe(event string) {
fmt.Printf("已订阅事件: '%s'\n", event)
}
// Logger 类型
type Logger struct{}
func (l Logger) Info(msg string) {
fmt.Printf("[INFO] %s\n", msg)
}
func (l Logger) Error(msg string) {
fmt.Printf("[ERROR] %s\n", msg)
}
func main() {
// 创建事件发射器
emitter := EventEmitter{}
emitter.Subscribe("user.login")
emitter.Emit("user.login", "用户已登录")
// 创建日志记录器
logger := Logger{}
logger.Info("系统启动")
logger.Error("发生错误")
}
45、golang值接收者和指针接收者的区别
golang函数与方法的区别是,方法有一个接收者
- 函数function是独立的代码块,不依附于任何类型
- 方法method是与特定类型关联的函数,这个特定类型就是“接收者”
如果方法的接收者是指针类型,无论调用者是对象还是对象指针,修改的都是对象本身,会影响调用者
如果方法的接收者是值类型,无论调用者是对象还是对象指针,修改的都是对象的副本,不影响调用者
package main
import "fmt"
type Person struct {
age int
}
func (p *Person) IncrAge1() {
p.age += 1
}
func (p Person) IncrAge2() {
p.age += 1
}
func (p Person) GetAge() int {
return p.age
}
func main() {
p := Person{
22,
}
p.IncrAge1()
fmt.Println(p.GetAge()) //23
p.IncrAge2()
fmt.Println(p.GetAge()) //23
p2 := &Person{
age: 22,
}
p2.IncrAge1()
fmt.Println(p2.GetAge()) //23
p2.IncrAge2()
fmt.Println(p2.GetAge()) //23
}
通常我们使用指针类型作为方法的接收者的理由:
1、使用指针类型能够修改调用者的值
2、使用指针类型可以避免在每次调用方法时复制该值,在值的类型为大型结构体时,这样做更加高效
46、引用传递和值传递
什么是引用传递?
将实参的地址传递给形参,函数内对形参值内容的修改,将会影响实参的值内容。Go语言是没有引用传递的,在C++中,函数参数的传递方式有引用传递。
Go的值类型(int、struct等)、引用类型(指针、slice、map、 channel)
int类型:形参和实际参数内存地址不一样,证明是值传递﹔参数是值类型,所以函数内对形参的修改,不会修改原内容数据
指针类型:形参和实际参数内存地址不一样,证明是值传递,由于形参和实参是指针,指向同一个变量。函数内对指针指向变量的修改,会修改原内容数据
func add(x *int) {
fmt.Printf("函数里指针地址:%p\n", &x)
fmt.Printf("函数里指针指向变量的地址:%p\n", x)
*x += 2
}
func main() {
a := 2
p := &a
fmt.Printf("原始指针地址:%p\n", &p)
fmt.Printf("原始指针指向变量的地址:%p\n", p)
add(p)
fmt.Println(a)
}
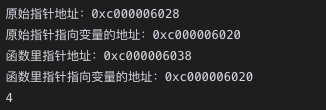
这说明函数调用时,传递的依然是指针的副本,依然是值传递,但指针指向的是同一个地址,所以能修改值
slice:slice 是一个结构体,他的第一个元素是一个指针类型,这个指针指向的是底层数组的第一个元素。当参数是slice类型的时候,frmt printf通过%p打印的slice变量的地址其实就是内部存储数组元素的地址,所以打印出来形参和实参内存地址一样。
// 在runtime/slice.go中的定义(简化版)
type slice struct {
array unsafe.Pointer // 指向底层数组的指针
len int // 长度
cap int // 容量
}
func add(x []int) {
fmt.Printf("函数里指针地址:%p\n", &x)
fmt.Printf("函数里指针指向变量的地址:%p\n", x)
}
func main() {
a := []int{1, 2, 3}
fmt.Printf("原始指针地址:%p\n", &a)
fmt.Printf("原始指针指向变量的地址:%p\n", a)
add(a)
}
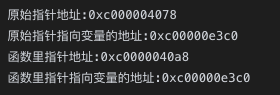
47、defer关键字的实现原理
Go14中编译器会将defer函数直接插入到函数的尾部,无需链表和栈上参数拷贝,性能大幅提升。把defer函数在当前函数内展开并直接调用,open code defer
1、函数退出前,按照先进后出的顺序,执行defer函数
2、panic后的defer不会被执行(遇到panic,如果没有捕获错误,函数会立即终止)
3、panic没有被recover时,抛出的panic到当前goroutine最上层函数时,最上层函数直接异常终止
package main
import "fmt"
func F() {
defer func() {
fmt.Println("b") // [2] 执行这个defer函数
}()
panic("a") // [1] 发生panic
}
func main() {
defer func() {
fmt.Println("c") // [3] 执行main函数中的defer
}()
F() // 调用F()函数,内部发生panic
fmt.Println("继续执行") // 这行不会被执行
}

4、panic有被recover时,当前goroutine最上层函数正常执行
package main
import "fmt"
func F() {
defer func() {
if err := recover(); err != nil { // [2] 捕获panic
fmt.Println("捕获异常", err) // [3] 打印捕获的panic值
}
fmt.Println("b") // [4] 继续执行defer函数剩余部分
}()
panic("a") // [1] 发生panic
}
func main() {
defer func() {
fmt.Println("c") // [6] 执行main中的defer
}()
F() // F函数内部panic但被恢复了
fmt.Println("继续执行") // [5] panic被recover后,main函数继续执行
}
当panic发生时:
- Go运行时获取当前goroutine的指针(g)
- 通过g获取注册的defer链表
- 按照后进先出顺序执行defer
- 如果在defer中遇到新的panic,会暂停当前panic处理,转而处理新的panic
- 如果在defer中调用recover(),并且它是直接在defer函数体内调用的,则:将当前panic标记为已恢复;recover()返回panic的值;函数正常返回到调用者,继续执行
defer func() {
if r := recover(); r != nil { // 有效
// 处理panic
}
}()
// 这样无效
defer recover() // 无效!
defer: 确保清理代码被执行,无论函数是正常返回还是发生panic
panic: 表示一个严重错误,会中断正常执行流程,但会执行已注册的defer
recover: 捕获并处理panic,仅在defer函数内部直接调用时有效
48、select 底层原理
scase结构体,select case的底层表示
type scase struct {
c *hchan // 通道指针
elem unsafe.Pointer // 数据元素指针
kind uint16 // case类型
// 其他字段...
}
kind字段的4种类型:
- caseNil:表示case中的通道为nil
- caseRecv: 表示case从通道接收数据 (case v := <-ch:)
- caseSend: 表示case向通道发送数据 (case ch <- v:)
- caseDefault: 表示default分支 (default:)
selectgo函数
当Go代码中使用select语句时,编译器会将其转换为对selectgo函数的调用。这个函数使用两个关键序列来处理select:
1、pollorder:随机处理顺序
确保select语句中多个就绪的case被随机选择,避免总是选择第一个就绪的case,保证公平性。
2、lockorder:通道锁定顺序
通过对通道按内存地址大小排序后加锁,避免多个goroutine同时对多个通道加锁时可能发生的死锁问题。这是一种常见的死锁预防策略。
Goroutine 1: select { case ch1 <- v1: ... case ch2 <- v2: ... }
Goroutine 2: select { case ch2 <- v3: ... case ch1 <- v4: ... }
如果Goroutine 1先锁ch1,Goroutine 2先锁ch2,然后各自尝试锁定另一个通道,就会发生死锁。通过按地址排序,确保所有goroutine按相同顺序获取锁,避免了死锁问题
selectgo函数执行流程
步骤1: 加锁所有相关通道
按照lockorder序列对所有非nil通道加锁
步骤2: 检查各个case是否就绪
遍历所有的case,尝试找到一个可以立即处理的case:
步骤3: 处理结果
[1]如果找到就绪的case:
执行相应的接收或发送操作
解锁所有通道
返回所选case的索引和接收到的值(如果是接收操作)
[2]如果没有就绪case但有default:
执行default分支
解锁所有通道
返回default的索引
[3]如果没有就绪case且没有default:阻塞等待
为每个case创建sudog结构(表示等待中的goroutine)
将sudog加入相应通道的等待队列
当前goroutine进入休眠
当任一通道就绪时,唤醒goroutine
被唤醒后需要清理:从其他通道的等待队列中移除sudog,因为已经不需要等待了
49、golang中指针的作用?
1、 传递大对象:避免复制开销
2、修改函数外部变量:突破作用域限制
Go是值传递的语言,想在函数内修改外部变量,需要使用指针。
package main
import "fmt"
// 不使用指针 - 修改的只是副本,不影响原值
func incrementByValue(n int) {
n = n + 1
fmt.Printf("函数内部值: %d\n", n)
}
// 使用指针 - 可以修改原始值
func incrementByPointer(n *int) {
*n = *n + 1
fmt.Printf("函数内部值: %d\n", *n)
}
func main() {
x := 10
incrementByValue(x)
fmt.Printf("使用值传递后: %d\n", x) // 输出: 10,原值未改变
incrementByPointer(&x)
fmt.Printf("使用指针传递后: %d\n", x) // 输出: 11,原值被修改
}
3、动态分配内存:运行时创建对象
使用new函数或&操作符可以在堆上分配内存,并获取指向该内存的指针
package main
import "fmt"
type User struct {
ID int
Name string
}
func main() {
// 方法1: 使用new函数动态分配内存
p1 := new(int) // 创建int类型的指针
*p1 = 42 // 设置值
fmt.Printf("p1: %d\n", *p1)
// 方法2: 使用&操作符获取地址
x := 100
p2 := &x
fmt.Printf("p2: %d\n", *p2)
// 为结构体动态分配内存
user1 := new(User)
user1.ID = 1
user1.Name = "Alice"
fmt.Printf("user1: %+v\n", *user1)
// 使用复合字面量和&操作符
user2 := &User{
ID: 2,
Name: "Bob",
}
fmt.Printf("user2: %+v\n", *user2)
// 动态创建切片
slice := new([]int)
*slice = append(*slice, 1, 2, 3)
fmt.Printf("slice: %v\n", *slice)
}
动态分配内存允许我们在运行时根据需要创建对象,而不是在编译时确定所有内存需求。这对于大小不确定的数据结构或需要动态生成的对象特别有用
4、函数返回指针:高效返回大型数据或延长生命周期
函数可以返回局部变量的指针,Go编译器会自动将这些变量"逃逸"到堆上。
package main
import (
"fmt"
"math/rand"
)
// 返回指向大型数据结构的指针
func createLargeDataset(size int) *[]int {
// 创建大型数据集
result := make([]int, size)
for i := 0; i < size; i++ {
result[i] = rand.Intn(1000)
}
// 返回指针,避免复制整个切片
return &result
}
// 工厂函数,返回结构体指针
func newPerson(name string, age int) *Person {
// 即使p是局部变量,Go也会将其分配到堆上
p := Person{
Name: name,
Age: age,
}
return &p
}
type Person struct {
Name string
Age int
}
// 生成唯一ID并返回指针
func generateID() *int {
id := rand.Intn(10000) + 1000
return &id // 局部变量逃逸到堆上
}
func main() {
// 获取大型数据集的指针
data := createLargeDataset(1000000)
fmt.Printf("数据集大小: %d, 第一个元素: %d\n", len(*data), (*data)[0])
// 使用工厂函数创建对象
person := newPerson("张三", 25)
fmt.Printf("人物信息: %+v\n", *person)
// 使用生成的ID
userID := generateID()
fmt.Printf("生成的ID: %d\n", *userID)
}

















 1239
1239



 到【灌水乐园】发言
到【灌水乐园】发言








