







 本文介绍了卷积神经网络的基本原理,包括局部连接、权重共享和感受野,以及如何通过增大滤波器大小、增加层数和池化操作来改变感受野。接着讲解了一维和二维卷积,强调了卷积层在特征提取中的作用。此外,还讨论了池化的最大池化和平均池化方法。最后,文章聚焦于Text-CNN,它是利用卷积神经网络对文本进行分类的算法,通过一维卷积和不同大小的滤波器提取文本的关键信息。
本文介绍了卷积神经网络的基本原理,包括局部连接、权重共享和感受野,以及如何通过增大滤波器大小、增加层数和池化操作来改变感受野。接着讲解了一维和二维卷积,强调了卷积层在特征提取中的作用。此外,还讨论了池化的最大池化和平均池化方法。最后,文章聚焦于Text-CNN,它是利用卷积神经网络对文本进行分类的算法,通过一维卷积和不同大小的滤波器提取文本的关键信息。
卷积神经网络
卷积神经网络介绍
卷积神经网络(Convolutional Neural Network,CNN或ConvNet)是一种具有局部连接、权重共享,汇聚等特性的深层前馈神经网络。由卷积层、汇聚层和全连接层交叉堆叠而成的,使用反向传播算法进行训练,具有一定程度上的平移、缩放和旋转不变性。和前馈神经网络相比,卷积神经网络的参数更少。
全连接前馈网络存在以下问题:
(1)参数太多,随着隐藏层神经元数量的增多,参数的规模也会急剧增加。这 会导致整个神经网络的训练效率会非常低,也很容易出现过拟合。
(2)局部不变性特征等问题全连接前馈网络很难提取 这些局部不变特征,一般需要进行数据增强来提高性能。
采用卷积来代替全连接,第 l 层的净输入 z(l) 为第 l − 1 层活性值 a(l−1) 和滤波器w(l) ∈Rm的卷积 z(l) = w(l) ⊗ a(l−1) + b(l) 其中滤波器 w(l) 为可学习的权重向量,b(l) ∈ Rnl−1 为可学习的偏置。
局部连接:在卷积层(假设是第 l 层)中的每一个神经元都只和下一层(第 l − 1 层)中某个局部窗口内的神经元相连,构成一个局部连接网络。卷积层和下一层之间的连接数大大减少,有原来的nl ×nl−1个连接变为nl ×m 个连接,m 为滤波器大小。
权重共享:作为参数的滤波器 w(l) 对于第 l 层的所有的神经元都是相同的。所有的同颜色连接上的权重是相同的。
局部连接和权重共享使得卷积层的参数只有一个 m 维的权重 w(l) 和 1 维 的偏置 b(l),共m + 1个参数。参数个数和神经元的数量无关。第 l 层的神经元个数不是任意选择的,而是满足 n(l) = n(l−1) − m + 1
感受野
卷积神经网络是受生物学上感受野的机制而提出。感受野(Receptive Field)主要是指听觉、视觉等神经系统中一些神经元的特性只接受其所支配的刺激区域内的信号。在视觉神经系统中,视觉皮层中的神经细胞的输出依赖于视网膜上的光感受器。视网膜上的光感受器受刺激兴奋时,将神经冲动信号传到视觉皮层,但不是所有视觉皮层中的神经元都会接受这些信号。一个神经元的感受野是指视网膜上的特定区域,只有这个区域内的刺激才能够激活该神经元。
对于一个卷积层,如果希望增加输出单元的感受野,一般可以通过三种方式实现:(1)增加卷积核的大小;(2)增加层数;(3)在卷积之前进行池化操作。前两种操作会增加参数数量,而第三种会丢失一些信息。
一维和二维卷积
一维卷积经常用在信号处理中,用于计算信号的延迟累积。把w1,w2,···称为滤波器(Filter)或卷积核(Convolution Kernel)。 假设滤波器长度为m,它和一个信号序列 x1 , x2 , · · · 的卷积为:
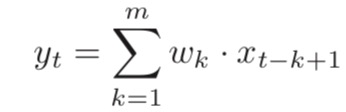
信号序列 x 和滤波器 w 的卷积定义为y = w ⊗ x
二维卷积 经常用在图像处理中,因为图像为一个两维结构。给定一个图像X ∈ RM×N,和滤波器 W ∈ Rm×n,一般 m << M,n << N,其卷积为:
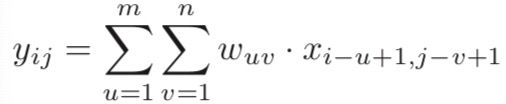
卷积的数学性质
1.交换性
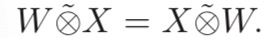
2.导数
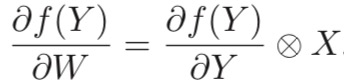
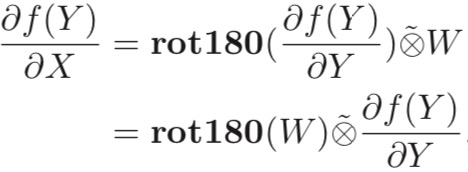
卷积层的作用
卷积层的作用是提取一个局部区域的特征,不同的卷积核相当于不同的特征提取器,为了更充分地利用图像的局部信息,通常将神经元组织为三维结构的神经层,其大小为高度M×宽度N×深度D,有D个M ×N大小的特征映射构成。
特征映射(Feature Map)为一幅图像(或其它特征映射)在经过卷积提取到的特征,每个特征映射可以作为一类抽取的图像特征。在输入层,特征映射就是图像本身。如果是灰度图像,就是有一个特征映射,深度D = 1;如果是彩色图像,分别有RGB三个颜色通道的特征映射,输入层深度D = 3
为了计算输出特征映射Yp,用卷积核Wp,1,Wp,2,··· ,Wp,D分别对输入特 征映射X1,X2,··· ,XD进行卷积,然后将卷积结果相加,并加上一个标量偏置 b得到卷积层的净输入Zp,再经过非线性激活函数后得到输出特征映射Yp。
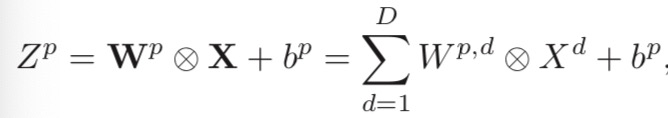
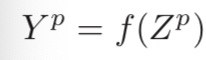
其中Wp ∈ Rm×n×D为三维卷积核,f(·)为非线性激活函数,一般用ReLU函数。在输入为X ∈ RM×N×D,输出为Y ∈ RM′×N′×P 的卷积层中,每一个输入特征映射都需要D个滤波器以及一个偏置。假设每个滤波器的大小为m × n, 那么共需要P ×D×(m×n)+P个参数
池化
池化就是将特征矩阵划分为若干小块,从每个子矩阵中选取一个值替代该子矩阵,这样做的目的是压缩特征矩阵,简化接下来的计算。
池化层(Pooling Layer)也叫子采样层(Subsampling Layer),其作用是进行特征选择,降低特征数量,并从而减少参数数量。卷积层虽然可以显著减少网络中连接的数量,但特征映射组中的神经元个数并没有显著减少。如果后面接一个分类器,分类器的输入维数依然很高,很容易出现过拟合。为了解决这个问题,可以在卷积层之后加上一个池化层,从而降低特征维数,避免过拟合。
1.最大池化 取一个区域内所有神经元的最大值。
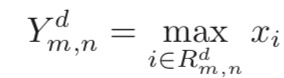 其中 xi 为区域 Rkd 内每个神经元的激活值。
其中 xi 为区域 Rkd 内每个神经元的激活值。
2.平均池化 取区域内所有神经元的平均值
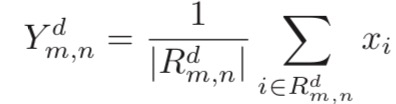
典型的池化层是将每个特征映射划分为 2 × 2 大小的不重叠区域,然后使用最大池化的方式进行下采样。池化层也可以看做是一个特殊的卷积层,卷积核大小为 m × m,步长为 s × s,卷积核为 max 函数或 mean 函数。过大的采样区域会急剧减少神经元的数量,会造成过多的信息损失。
text-cnn
text-cnn是利用卷积神经网络对文本进行分类的算法,由于卷积具有局部特征提取的功能, 所以可用cnn来提取句子中类似 n-gram 的关键信息。
text-cnn详细过程:第一层是7乘5的句子矩阵,每行是词向量,维度=5,这个可以类比为图像中的原始像素点。然后经过有filter_size=(2,3,4) 的一维卷积层,每个filter_size 有两个输出 channel。第三层是一个1-max pooling层,这样不同长度句子经过pooling层之后都能变成定长的表示,最后接一层全连接的 softmax 层,输出每个类别的概率。
特征:这里的特征就是词向量,有静态(static)和非静态(non-static)方式。static方式采用比如word2vec预训练的词向量,训练过程不更新词向量,实质上属于迁移学习了,特别是数据量比较小的情况下,采用静态的词向量往往效果不错。non-static则是在训练过程中更新词向量。推荐的方式是 non-static 中的 fine-tunning方式,它是以预训练(pre-train)的word2vec向量初始化词向量,训练过程中调整词向量,能加速收敛。当然如果有充足的训练数据和资源,直接随机初始化词向量效果也是可以的。
通道(Channels):图像中可以利用 (R, G, B) 作为不同channel,而文本的输入的channel通常是不同方式的embedding方式(比如 word2vec或Glove),实践中也有利用静态词向量和fine-tunning词向量作为不同channel的做法。
一维卷积(conv-1d):图像是二维数据,经过词向量表达的文本为一维数据,因此在text-cnn卷积用的是一维卷积。一维卷积带来的问题是需要设计通过不同 filter_size 的 filter 获取不同宽度的视野。
Pooling层:利用cnn解决文本分类问题的文章还是很多的,比如这篇 A Convolutional Neural Network for Modelling Sentences 最有意思的输入是在 pooling 改成 (dynamic) k-max pooling ,pooling阶段保留 k 个最大的信息,保留了全局的序列信息。
关于text-cnn的具体实现可以看下文末参考中大佬的github项目。
需要注意两方面:
1.github中代码兼容支持python2和python3,但是有些python2中的方法在python3中找不到,去掉就可以运行了。
2.遇到Variable *** already exists, disallowed. Did you mean to set reuse=True or reuse=tf.AUTO这类错误,需要在运行代码第一步添加
tf.reset_default_graph()。
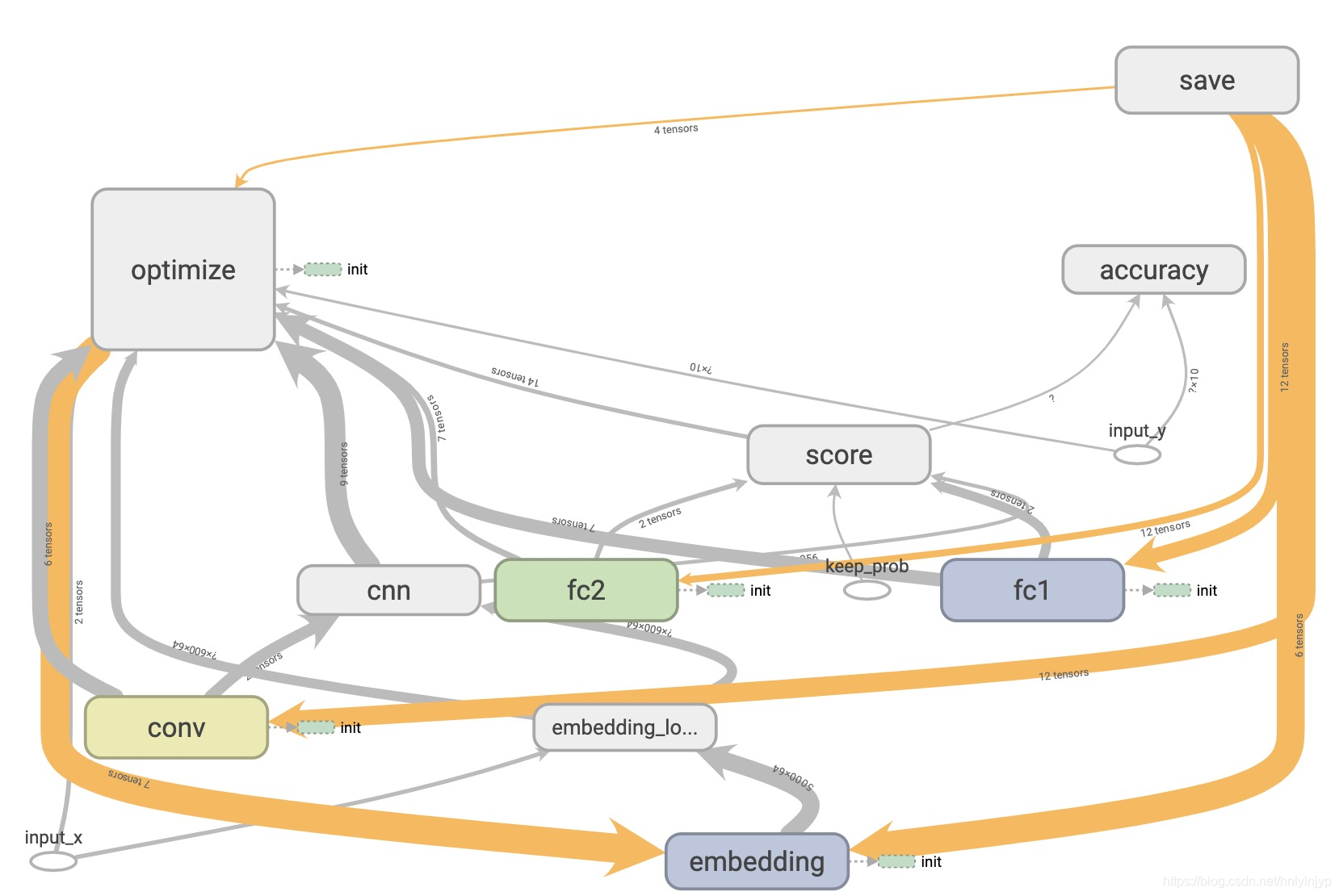
代码运行后生成的网络结构在tensorboard打开如图所示:
参考
《神经网络与深度学习》
用深度学习(CNN RNN Attention)解决大规模文本分类问题 - 综述和实践(转载)
https://github.com/gaussic/text-classification-cnn-rnn

















 2442
2442

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









