



L2G1000
L2G2000
无插件

加入ArxivSearch插件后

加入了两个插件ArxivSearch,WeatherQuery后与没有加入插件对比

百度搜索结果

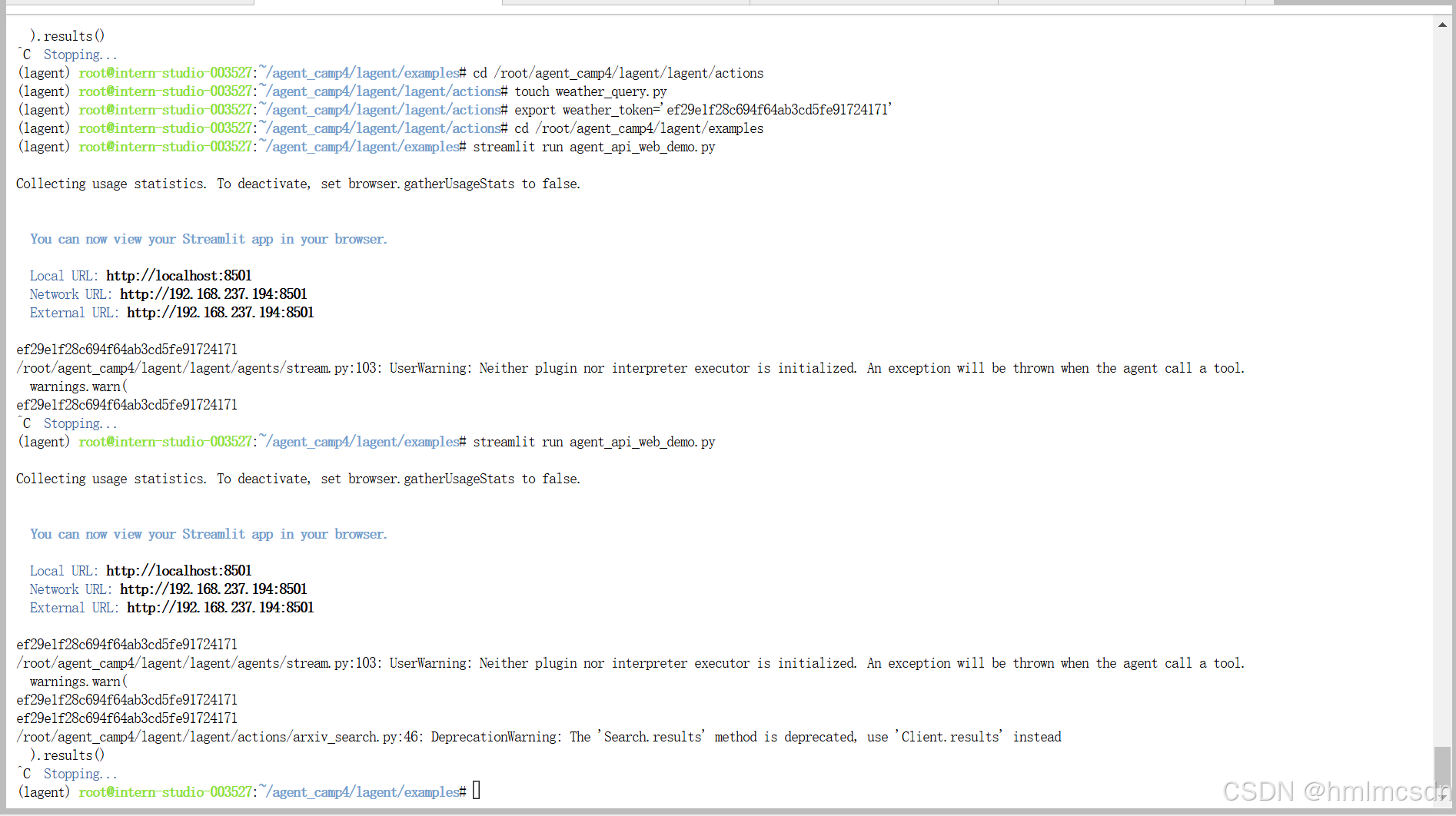
Multi-Agents多智能体博客写作系统



L2G3000
1.3 LMDeploy验证启动模型文件
对于24GB的显卡,即30%A100,权重占用14GB显存,剩余显存24-14=10GB,因此kv cache占用10GB*0.8=8GB,加上原来的权重14GB,总共占用14+8=22GB。

而对于40GB的显卡,即50%A100,权重占用14GB,剩余显存40-14=26GB,因此kv cache占用26GB*0.8=20.8GB,加上原来的权重14GB,总共占用34.8GB。

2.1 LMDeploy API部署InternLM2.5
2.1.1 启动API服务器

2.1.2 以命令行形式连接API服务器

2.1.3 以Gradio网页形式连接API服务器
端口接力转发


2.2.2 设置在线 kv cache int4/int8 量化
显存状态

正常对话

2.2.3 W4A16 模型量化和部署





2.2.4 W4A16 量化+ KV cache+KV cache 量化

3.1 LMDeploy Lite
3.1.1 W4A16 模型量化和部署
4.1 API开发


4.2 Function call
L2G4000
SSH连接

端口转发


图片测试

微调过程

内存不够改用50%A100显卡

微调前后对比

微调后

L2G6000
2.4. GitHub CodeSpace启动MindSearch




2.5. 部署到自己的 HuggingFace Spaces上



















 1385
1385

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









