







LMDeploy 量化部署进阶实践
任务描述
- 使用结合
W4A16量化与kv cache量化的internlm2_5-1_8b-chat模型封装本地API 并与大模型进行一次对话,作业截图需包括显存占用情况与大模型回复,参考 4.1 API 开发,请注意 2.2.3节 与 4.1节 应使用作业版本命令。 - 使用
Function call功能让大模型完成一次简单的"加"与"乘"函数调用,作业截图需包括大模型回复的工具调用情况,参考4.2 Function call(选做)。
以下内容参考教程。
InternLM2.5 量化与部署
环境配置
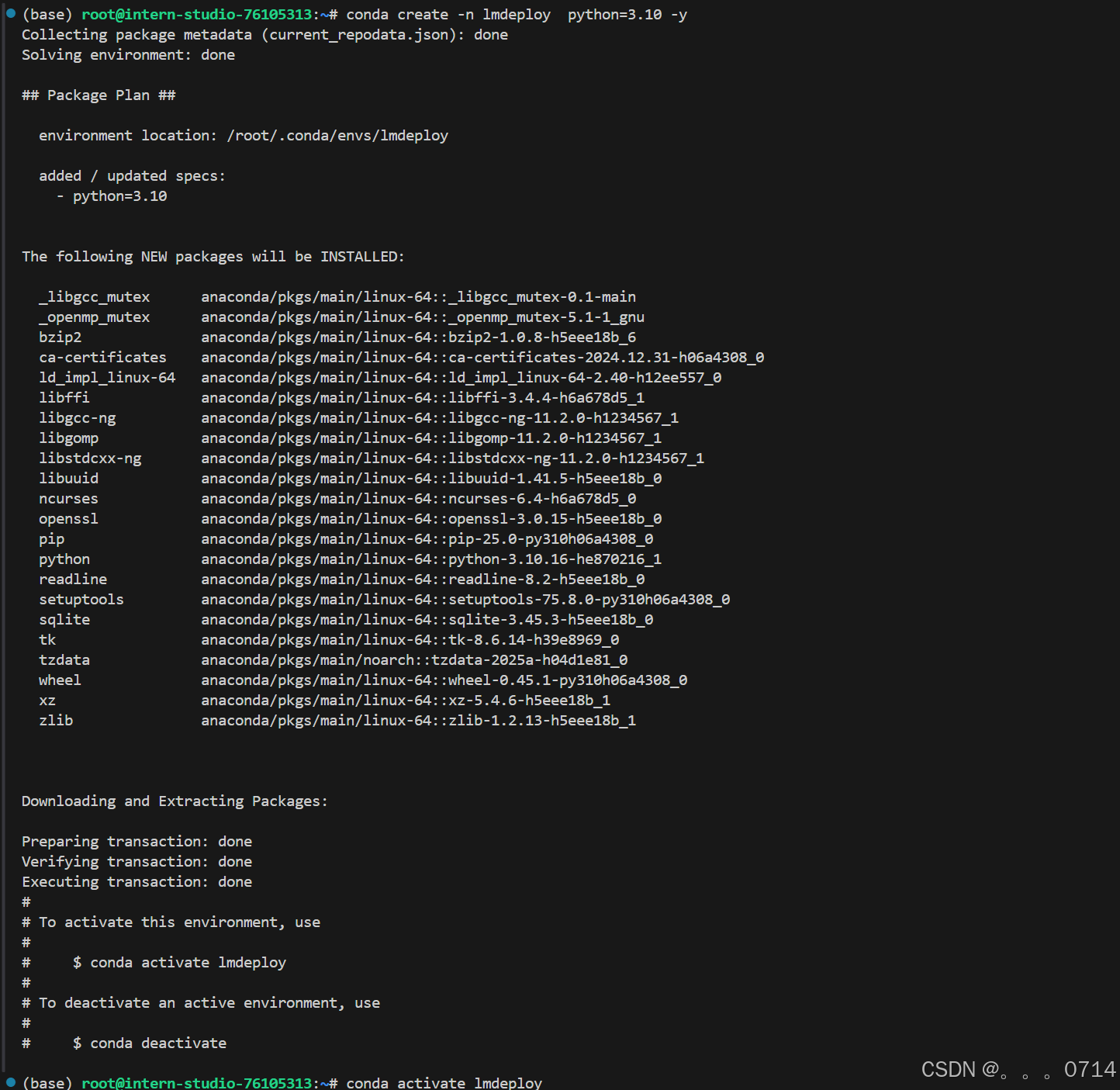
创建一个名为lmdeploy的conda环境,python版本为3.10,创建成功后激活环境并安装0.5.3版本的lmdeploy及相关包。
conda create -n lmdeploy python=3.10 -y
conda activate lmdeploy
conda install pytorch==2.1.2 torchvision==0.16.2 torchaudio==2.1.2 pytorch-cuda=12.1 -c pytorch -c nvidia -y
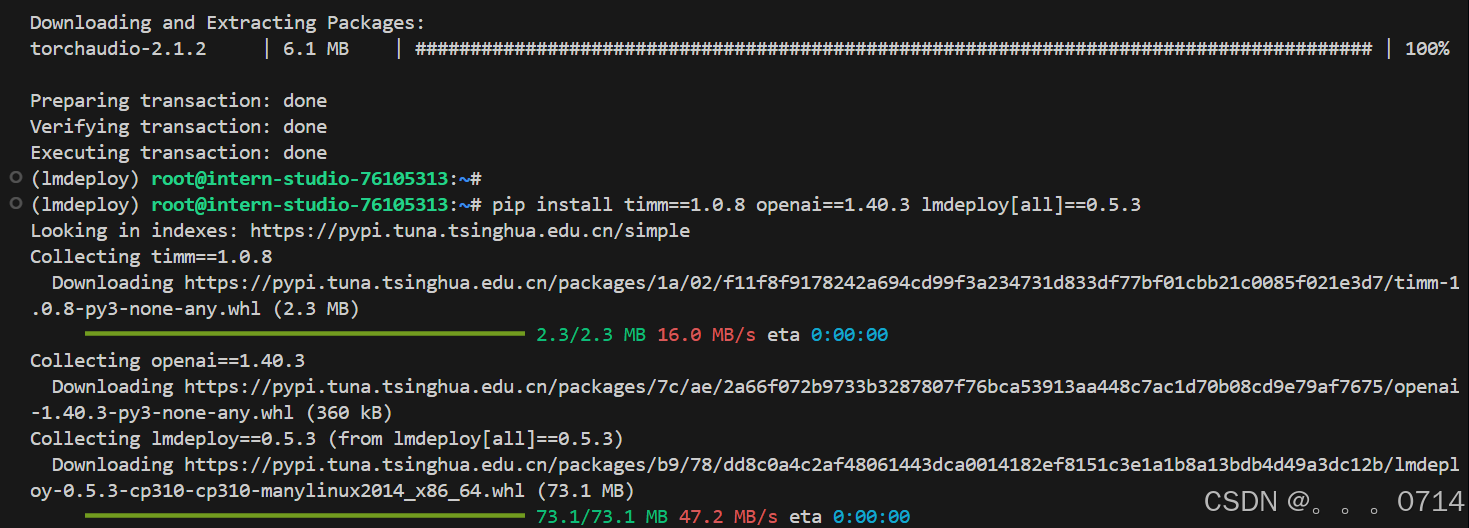
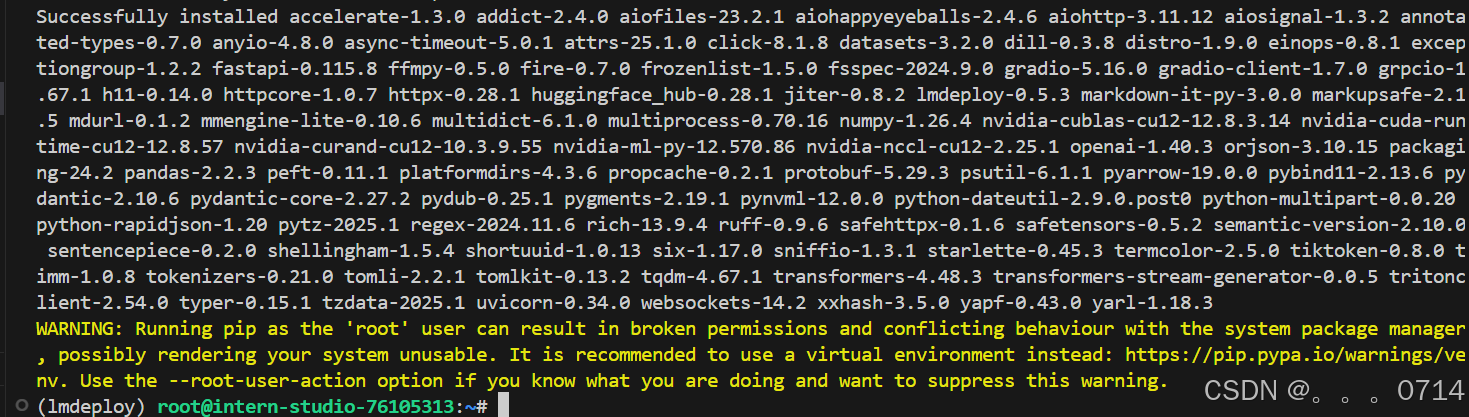
pip install timm==1.0.8 openai==1.40.3 lmdeploy[all]==0.5.3
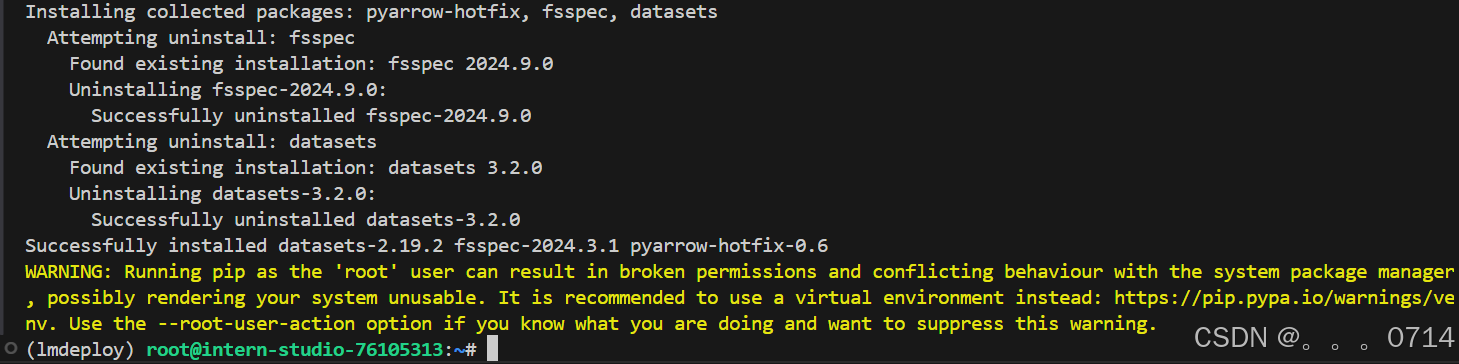
pip install datasets==2.19.2
运行以下命令,进入/root/model文件夹并设置开发机共享目录的软链接。


lmdeploy chat /root/model/internlm2_5-1_8b-chat验证获取的模型文件能否正常工作。
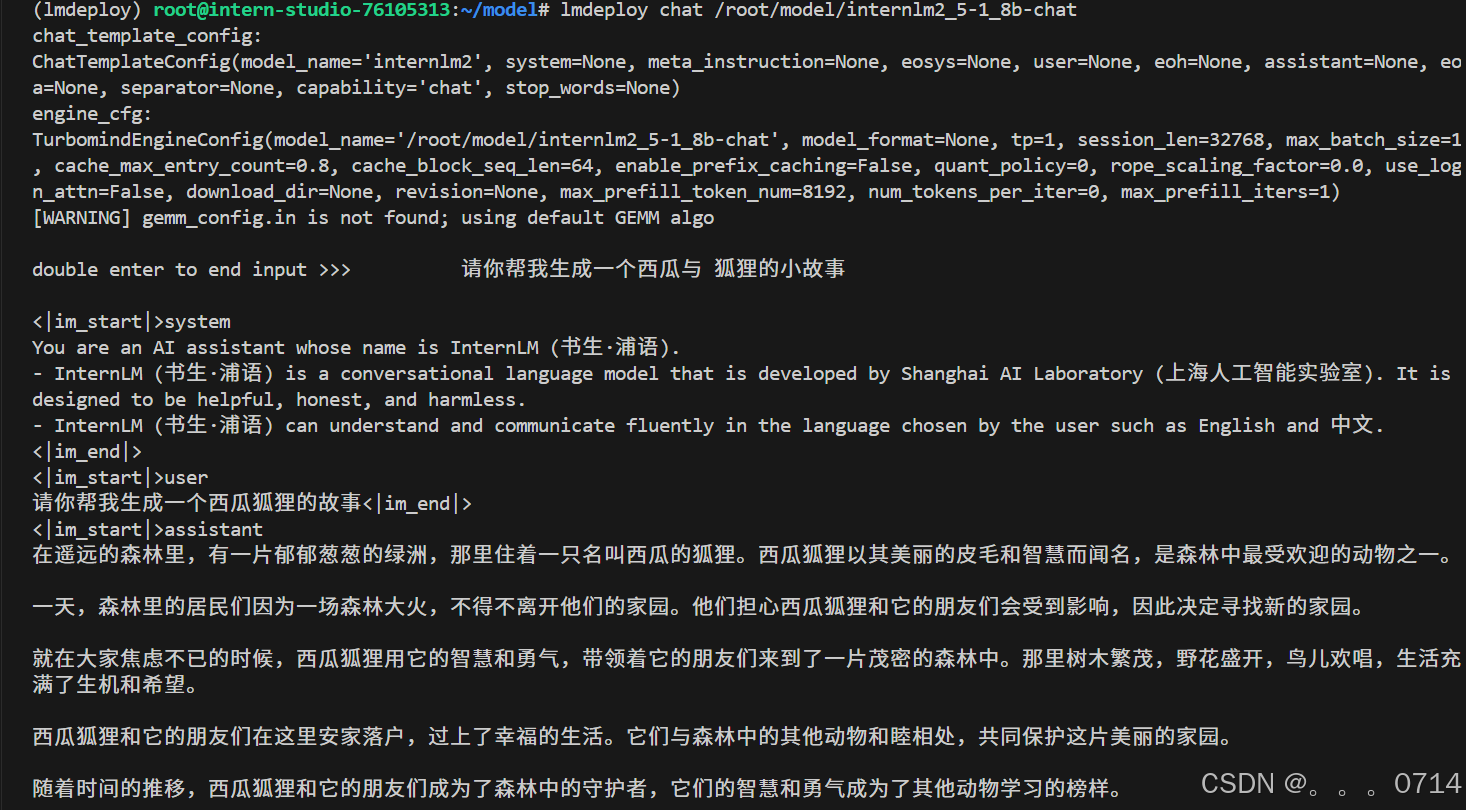
查看模型显存占用。理论上,kv cache 显存占用是根据剩余内存计算的。可以使用studio-smi观测虚拟化后的显存使用情况。
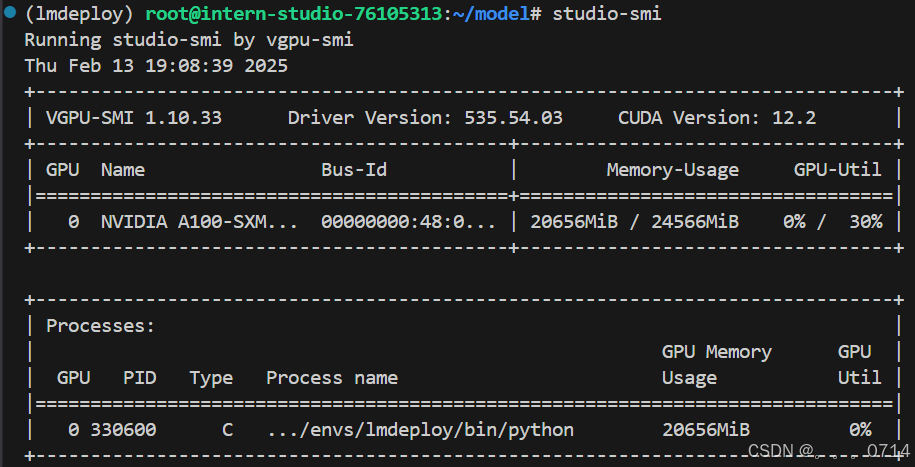
或者进入开发机界面查看可视化的资源监控。

此时显存占用约20GB。
对于一个1.8B(18亿)参数的模型,每个参数使用16位浮点数(等于 2个 Byte)表示,则模型的权重大小约为:
1.8×10^9 parameters×2 Bytes/parameter=3.6GB
18亿个参数×每个参数占用2个字节=3.6GB
对于24GB的显卡,即30%A100,权重占用3.6GB显存,剩余显存24-3.6=20.4GB,因此kv cache占用20.4GB*0.8=16.32GB,加上原来的权重3.6GB,总共占用3.6+16.32=19.92GB。
LMDeploy API部署InternLM2.5
启动API服务器,部署InternLM2.5模型。
lmdeploy serve api_server \
/root/model/internlm2_5-1_8b-chat \
--model-format hf \
--quant-policy 0 \
--server-name 0.0.0.0 \
--server-port 23333 \
--tp 1
命令解释:
lmdeploy serve api_server:这个命令用于启动API服务器。/root/model/internlm2_5-1_8b-chat:这是模型的路径。--model-format hf:这个参数指定了模型的格式。hf代表“Hugging Face”格式。--quant-policy 0:这个参数指定了量化策略。--server-name 0.0.0.0:这个参数指定了服务器的名称。在这里,0.0.0.0是一个特殊的IP地址,它表示所有网络接口。--server-port 23333:这个参数指定了服务器的端口号。在这里,23333是服务器将监听的端口号。--tp 1:这个参数表示并行数量(GPU数量)。
稍待片刻,终端显示如下。
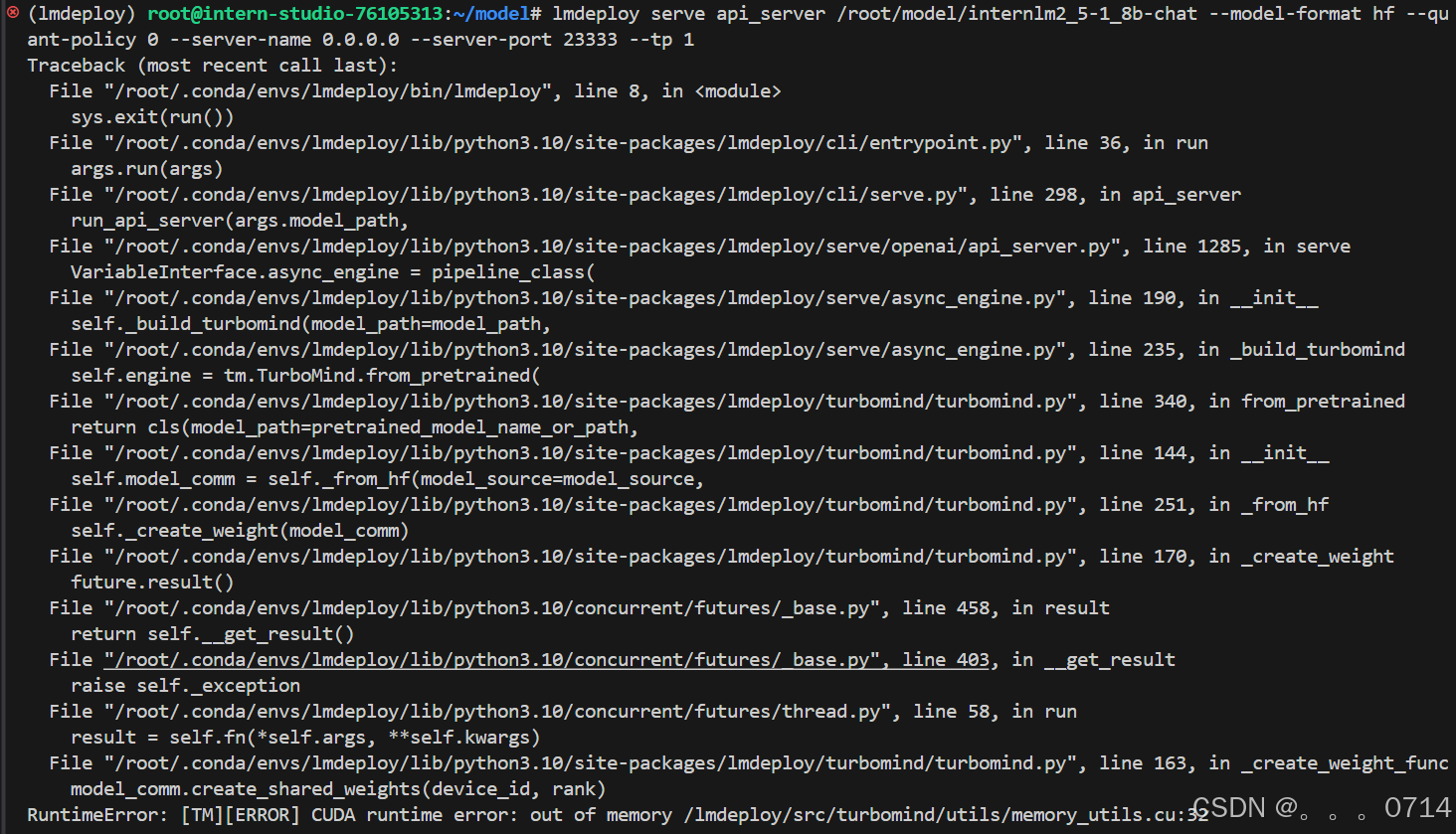
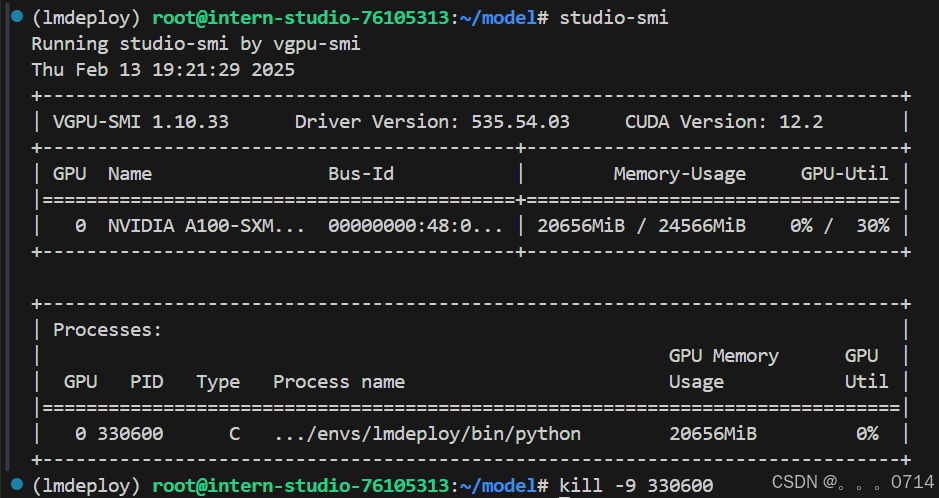
报错是由于之前的模型对话采用了ctrl+z的强制退出方式,模型仍在后台运行。因此使用studio-smi查看模型的PID,并关闭该进程。
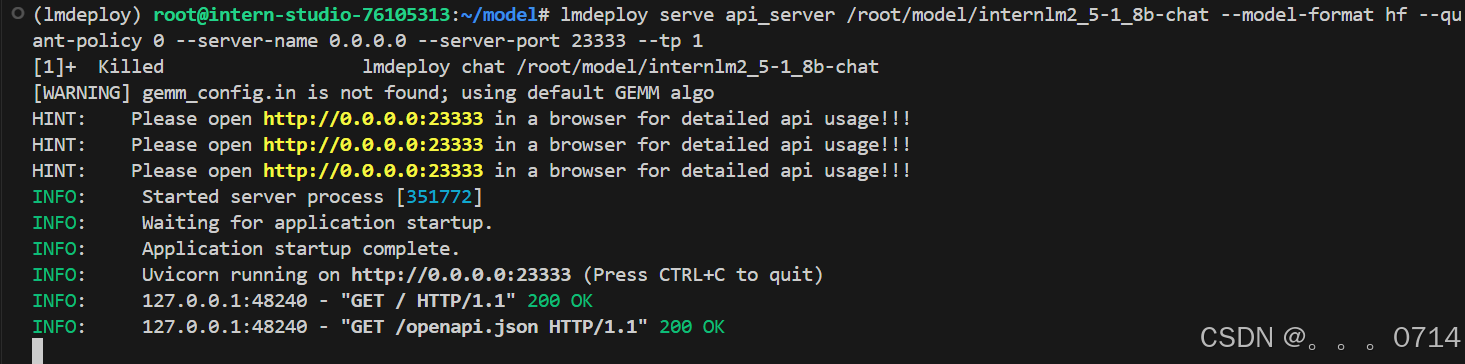
ctrl+右击链接进入 FastAPI 页面表示部署成功。
使用VScode远程连接开发机将会自动进行端口映射。

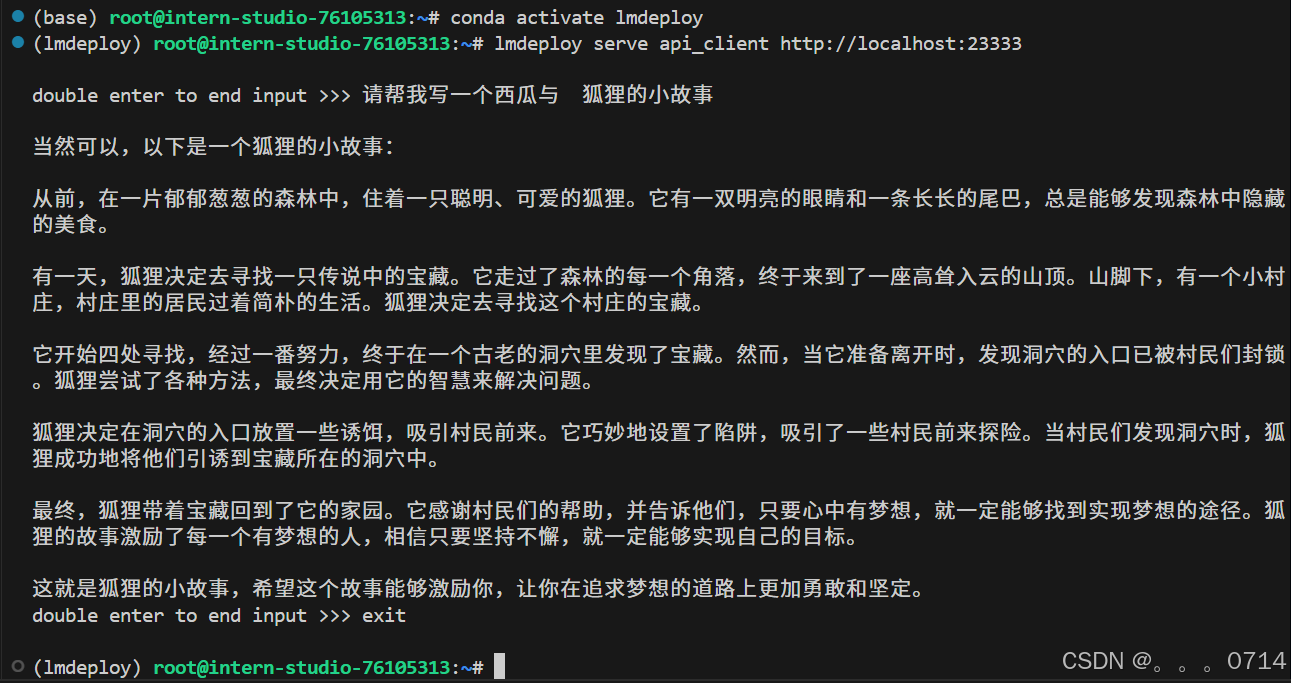
以命令行形式连接API服务器
新建终端运行以下命令。
conda activate lmdeploy
lmdeploy serve api_client http://localhost:23333
以Gradio网页形式连接API服务器
在命令行连接 API 的终端中,输入exit退出对话(也需要 double enter)。之后输入以下命令,使用Gradio作为前端,启动网页。
lmdeploy serve gradio http://localhost:23333 --server-name 0.0.0.0 --server-port  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









