







 本文详细介绍了如何使用Scrapy框架从gaoqing.la网站抓取电影图片,包括解析HTML、配置管道和存储图片。重点在于图片爬取流程和ITEM_PIPELINES配置。
本文详细介绍了如何使用Scrapy框架从gaoqing.la网站抓取电影图片,包括解析HTML、配置管道和存储图片。重点在于图片爬取流程和ITEM_PIPELINES配置。
1.爬虫文件-高清图片
from ..items import GaoqingItem
import requests
class GqSpider(scrapy.Spider):
name = 'gq'
allowed_domains = ['gaoqing.la']
start_urls = ['http://gaoqing.la/?s=%E7%94%B5%E5%BD%B1']
def parse(self, response):
#获取电影
nodes=response.xpath('//*[@id="post_container"]/li[*]/div/div[2]/h2/a')
for node in nodes:
item =GaoqingItem() #对象item
# 获取电影名称
title =node.xpath('./@title').get()
# 获取电影详情url
href=node.xpath('./@href').get()
#存储数据
item['title']=title
item['href']=href
# print(item)
#再次发送请求,并传递参数meta={}
yield scrapy.Request(href,callback=self.parse_data,meta={'item2':item})
#回调数据
def parse_data(self, response):
#获取参数的值
item=response.meta.get('item2')
#获取电影图片url
img_url=response.xpath('//*[@id="post_content"]/p[1]/a/img/@src').get()
# print('图片url>>>',img_url)
# 保存到固定字段
item['image_urls']=img_url
# print(item['image_urls'])
# 注意这个必须返回哦到管道!
yield item #返回到管道
2.存储items文件
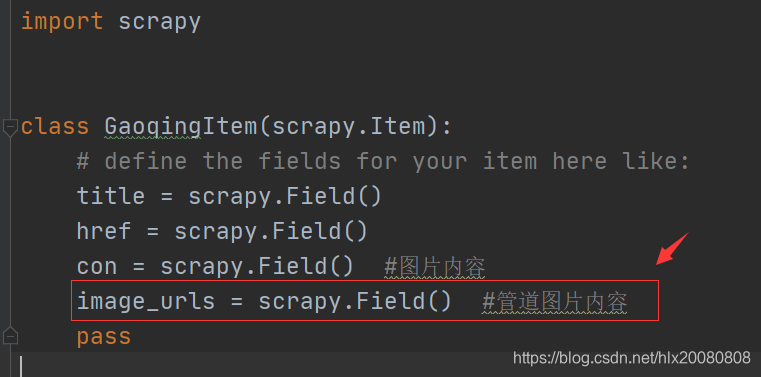
3.管道文件 pipeline.py
from itemadapter import ItemAdapter
#导入图片管道类
from scrapy.pipelines.images import ImagesPipeline
import scrapy
# 图片管道类
class ImgPipeline(ImagesPipeline):
# 1.根据图片进行请求
def get_media_requests(self, item, info):
print('图片管道方法执行!')
res = scrapy.Request(url=item['image_urls'], meta={'item': item})
yield res
# 2.指定图片路径/名字
def file_path(self, request, response=None, info=None, *, item=None):
# 保存名字
item = request.meta['item']
name = item['title'] + '.jpg'
# print('name-->', name)
return name
# 3.将item传递给下一个即将被执行的管道类
def item_completed(self, results, item, info):
return item
自定义类继承ImagesPipeline无法执行,查看源码
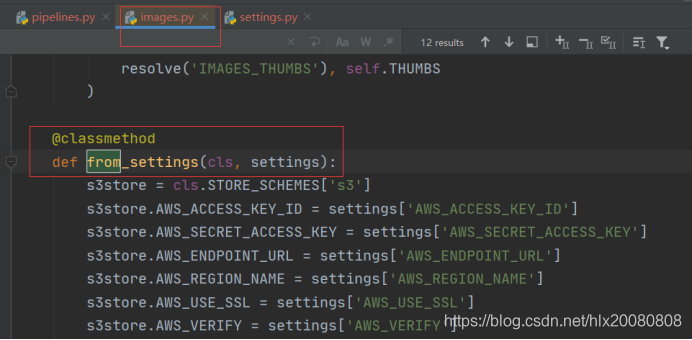
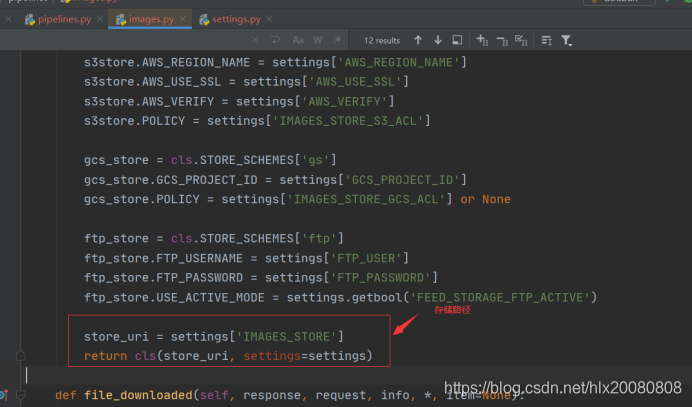
4.设置文件settings.py
#设置使用图片管道保存的路径
IMAGES_STORE='./imgs'
#开启管道
ITEM_PIPELINES = {
# 'gaoqing.pipelines.GaoqingPipeline': 300,
'gaoqing.pipelines.ImgPipeline': 300,
}
5.运行 scrapy crawl gq --nolog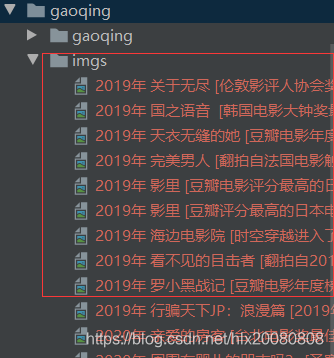
总之:使用scrapy保存数据到文件,需要注意以下三点:
1. pipelines文件正确配置
2. 配置settings.py文件
3. 爬虫文件parse()函数一定要由yield语句

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









