



在读有关机器学习的文章的时候,不收敛、过拟合、欠拟合、泛化能力、鲁棒性是经常出现的术语。一方面,他们能够体现和证明智能算法的优劣;另一方面,也是智能算法追求与创新的重要方向。说的直白点,把机器学习算法比作人的话,他们描述了这个人(算法)要去办事行不行,还差在哪?
希望伙伴们一次能看明白,促进机器学习算法的设计与应用能力,让我们开始吧。
一、不收敛
不收敛:算法训练就好比解方程,不收敛就像解不出方程的解类似。通俗的讲就是算法从样本数据中找不到规律性,始终找不到最优解。
举个例子:把算法当成探险家,目标是找到藏在大山深处的一个最温暖、最舒适的山洞(这个山洞就代表我们机器学习算法想找到的最优解,比如最准的模型参数)
在例子中,不收敛主要有两种情况:
1.永远在路上,越走越远/原地打转型:你(算法)走进了一个巨大的、没有尽头的迷宫(问题本身可能没有最优解,或者最优解在无穷远处)。或者,你手里那张地图是错的,或者指南针坏了(算法设计有问题,比如学习率设置不当)。你拼命走,但那个温暖的山洞似乎永远找不到(损失函数不下降,甚至可能越来越大,参数乱跑)。你(算法)永远达不到目标,也停不下来。
第一种情况在算法运行运行上的具体表现为:损失函数的值不下降,或者上下剧烈波动不停止,或者甚至越来越大。算法参数在疯狂地变来变去,就是找不到一个稳定的好位置。
2.在山洞门口瞎溜达,就是进不去型:你其实已经非常接近那个温暖的山洞了!但你像是喝醉了酒,一直在洞口来回踱步、左右横跳。你能感觉到洞里的温暖(损失函数在一个比较低的水平),但你就是稳不住,始终没法安安稳稳地坐进入目标山洞里(算法在最优解附近震荡,无法稳定下来)。
第二种情况再算法运行上的具体表现为:损失函数的值在一个相对低的水平附近来回跳动(震荡),无法稳定在一个最低点。算法参数也在一个小的范围内不断变化。
不收敛的原因主要有(如果你的算法出现这个问题,对照逐一排查啊):
(1)学习率太大: 步子迈得太大,一步跨过了山洞,下一步又跨回来,来回震荡。
(2)学习率太小: 步子迈得太小(像蜗牛爬),走到天荒地老也到不了山洞。
(3)数据本身有问题: 数据噪音太大,或者特征没选好,地图本身就是错的。
(4)模型太复杂/太简单: 模型太复杂可能容易“乱跑”(过拟合也可能导致训练困难),太简单可能根本找不到好解(欠拟合)。
(5)问题本身太难: 那个“温暖山洞”可能藏得太深,或者根本不存在唯一最好的山洞(非凸优化问题)。
对于不收敛的问题,可以尝试调整学习率、优化算法,或者重新审视数据和模型结构。
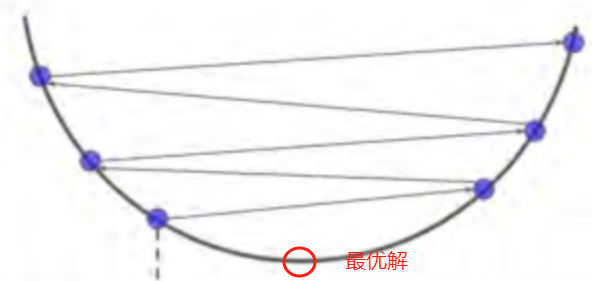
像这个图,变量一直在最值附近震荡,永远也达不成收敛状态。

像这个图,一直在迭代,迟迟不能收敛的情况。
二、欠拟合与过拟合
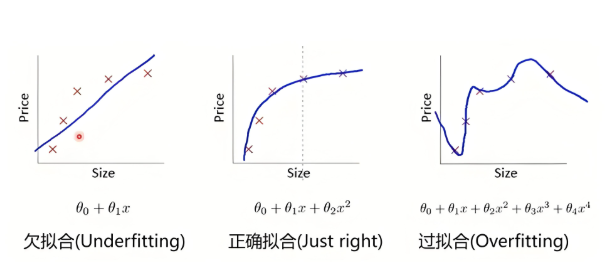
欠拟合:通俗的讲就是算法“学得太糙,啥都没学会”。核心问题是模型能力不足(模型问题)或训练(数据样本特征或者数据量的问题)严重不足。模型没有抓住数据中真正的规律。
打个比方: 就像你只告诉学生“会动的东西就是生物”,然后学生就把汽车、电风扇都当成生物了。学得太少、太浅,理解太片面。
为了防止欠拟合,可以尝试使用更复杂的模型架构,或者增加模型的训练时间和训练数据。
过拟合:“死记硬背,过犹不及,不会举一反三”。通俗的讲就是把样本数据全都学会了(只见树木不见森林了,太强调样本个体数据,没有把数据背后的规律学习训练好),但是实际应用中的其他数据反而不会啦。核心问题是 模型太复杂 或 训练过度。算法模型把数据中的“个性”(噪声)当成了“共性”(规律)。作业(训练数据)成绩超级好! 考试(新数据)成绩一塌糊涂!
打个比方: 就像学生把语文课本上《静夜思》那一页的纸张纹理、印刷墨点都背下来了,考试时默写,换张不同纸张印的《静夜思》,他就不敢下笔了,觉得是假诗。记得太细、太死板,不懂变通。
防止过拟合的策略包括引入正则化技术(如L1/L2正则化、dropout)、早停(early stopping)、数据增强等。
上图吧,看图更明白。
三、泛化能力
泛化能力,就是你的模型在“考试”(没见过的新数据)上考得好的本事!它能把在“练习题”(训练数据)上学到的“真本事”(通用规律),灵活运用到“实战”(实际应用问题)中去。白话讲就是训练的模型在研究中和应用中都用着十分OK!
泛化能力差有三种表现:一、泛化能力弱,模型始终掌握不了规律,不管遇到样本训练数据和应用测试数据都不会做,既是欠拟合的表现;二、泛化能力弱,只会死记硬背,一到未知的新数据就不会了,既是过拟合的表现;三、完全不会,运行应用全靠瞎蒙,既是不收敛的表现。大家对应看上面的图重新理解。
为了提高模型的泛化能力,可以尽量使用代表性和多样化的训练数据集,使用交叉验证。
四、鲁棒性
鲁棒性和泛化能力都是考察训练的算法对新数据适应能力的指标。两个指标容易混淆,细微的区别要细细体会。我们还是举例说明。
泛化能力是模型在“没见过但合理”的新数据上表现好的能力。注意这个合理数据,即新数据与训练的老数据的特征是一致的,没啥意外加进来。
鲁棒性:鲁棒性理解为模型对数据变化的容忍度,模型在“被故意捣乱”或“意外出错”的数据上依然表现稳定的能力,表现的是应对“意外干扰”的能力。注意,鲁棒性是在合理数据的基础上叠加了意外的特征进去,比如故障诊断中一些未知的干扰。
当数据出现干扰偏差时,只对模型输出产生较小的影响,某些特征仍表现稳定,称模型是鲁棒的。
看个例子吧。

上图原本以57.7%的概率模型被判定为熊猫。但部分细节被修改后,被算法识别为猿。表明该算法的抗干扰性差,鲁棒性低。
提升鲁棒性,核心是让模型“见多识广”且“抗干扰”:通过数据增强(加入噪声、模糊、遮挡等)、对抗训练(主动攻击并修正模型)、使用鲁棒损失函数/正则化(抑制对微小扰动敏感)、选择或设计本身更稳健的模型结构,使算法在面对输入噪声、损坏或恶意攻击时,性能保持稳定。
以上就是全部文章内容。感谢看到最后的您。
如果您有收获请关注、点赞、收藏吧!

















 1027
1027

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









