



 文章介绍了目标检测的基本概念,包括边界框、锚框和交并比,以及目标检测数据集的创建和读取。接着讨论了语义分割的任务,与目标检测和图像分割的区别,并提及了PascalVOC2012数据集。此外,还阐述了风格迁移的过程和损失函数。最后提到了人脸识别,特别是人脸验证的Siamese网络方法。
文章介绍了目标检测的基本概念,包括边界框、锚框和交并比,以及目标检测数据集的创建和读取。接着讨论了语义分割的任务,与目标检测和图像分割的区别,并提及了PascalVOC2012数据集。此外,还阐述了风格迁移的过程和损失函数。最后提到了人脸识别,特别是人脸验证的Siamese网络方法。
6.3 目标检测实现
6.3.1 目标检测预备知识
目标检测基本原理:很多时候图像里有多个我们感兴趣的目标,我们不仅想知道它们的类别,还想得到它们在图像中的具体位置。在计算机视觉里,我们将这类任务称为目标检测(object detection)或物体检测。目标检测在多个领域中被广泛使用。例如,在无人驾驶里,我们需要通过识别拍摄到的视频图像里的车辆、行人、道路和障碍的位置来规划行进线路。机器人也常通过该任务来检测感兴趣的目标。安防领域则需要检测异常目标,如歹徒或者炸弹。
边界框:在目标检测里,我们通常使用边界框(bounding box)来描述目标位置。边界框是一个矩形框,可以由矩形左上角的x和y轴坐标与右下角的x和y轴坐标确定。
锚框:目标检测算法通常会在输入图像中采样大量的区域,然后判断这些区域中是否包含我们感兴趣的目标,并调整区域边缘从而更准确地预测目标的真实边界框(ground-truth bounding box)。不同的模型使用的区域采样方法可能不同。这里我们介绍其中的一种方法:它以每个像素为中心生成多个大小和宽高比(aspect ratio)不同的边界框。这些边界框被称为锚框(anchor box)。
交并比:如何量化某个锚框好不好呢?一种直观的方法是衡量锚框和真实边界框之间的相似度。我们知道,Jaccard系数(Jaccard index)可以衡量两个集合的相似度。给定集合A和B,它们的Jaccard系数即二者交集大小除以二者并集大小:
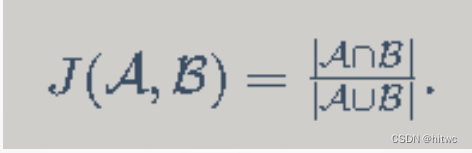
6.3.2 目标检测数据集
数据集的介绍
在目标检测领域并没有类似MNIST或Fashion-MNIST那样的小数据集。为了快速测试模型,我们合成了一个小的数据集。
- 首先,用一个开源的皮卡丘3D模型生成了1000张不同角度和大小的皮卡丘图像。
- 然后我们收集了一系列背景图像,并在每张图的随机位置放置一张随机的皮卡丘图像。
数据集的下载
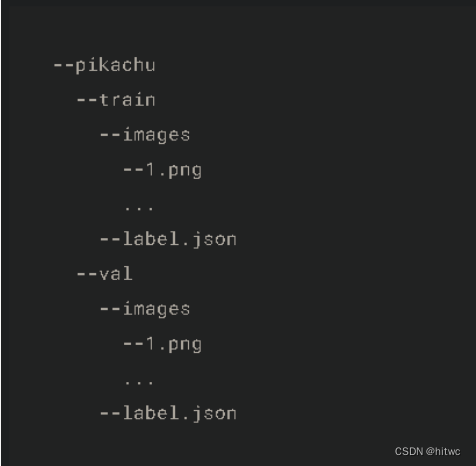
皮卡丘数据集使用MXNet提供的im2rec工具将图像转换成了二进制的RecordIO格式,但是我们后续要使用PyTorch,所以我们先用脚本将其转换成了PNG图片并用json文件存放对应的label信息。最终pikachu文件夹的结构如下:
数据集的读取
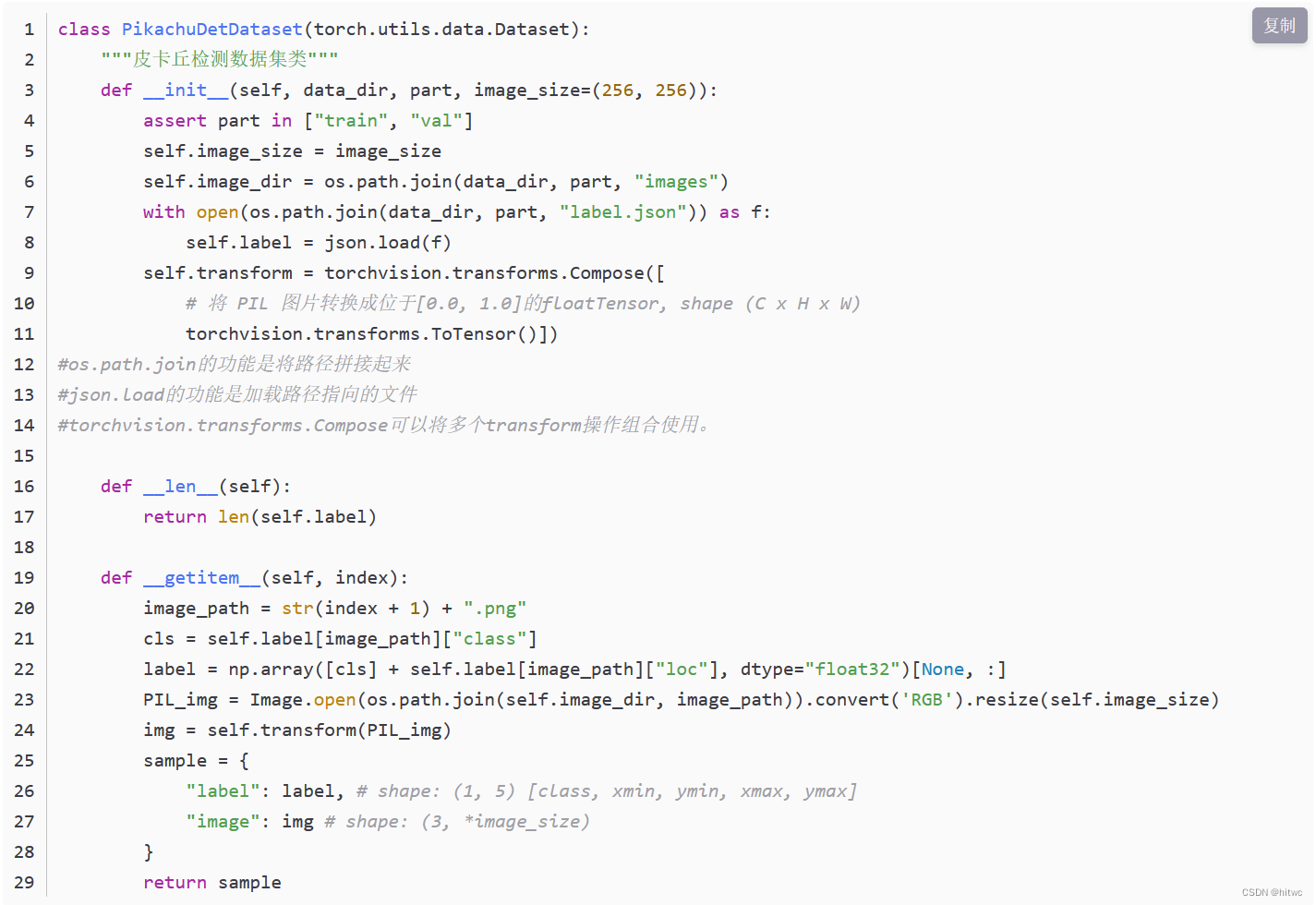
首先定义一个数据集类PikachuDetDataset,数据集每个样本包含label和image。label是一个m×5m×5 的向量,即m个边界框,每个边界框由[class, x_min, y_min, x_max, y_max]表示,这里的皮卡丘数据集中每个图像只有一个边界框,因此m=1。image是一个所有元素都位于[0.0, 1.0]的浮点tensor,代表图片数据。
我们用以下代码画出10张图像和它们中的边界框。可以看到,皮卡丘的角度、大小和位置在每张图像中都不一样。当然,这是一个简单的人工数据集。实际中的数据通常会复杂得多。


小节总结:
- 合成的皮卡丘数据集可用于测试目标检测模型。
- 目标检测的数据读取跟图像分类的类似。然而,在引入边界框后,标签形状和图像增广(如随机裁剪)发生了变化。
6.4 语义分割
6.4.1 语义分割

计算机视觉领域还有2个与语义分割相似的重要问题,即图像分割和实例分割。我们在这里将它们与语义分割简单区分一下。
图像分割将图像分割成若干组成区域。这类问题的方法通常利用图像中像素之间的相关性。它在训练时不需要有关图像像素的标签信息,在预测时也无法保证分割出的区域具有我们希望得到的语义。
实例分割又叫同时检测并分割。它研究如何识别图像中各个目标实例的像素级区域。与语义分割有所不同。
以上一张ppt中的两只狗为例,图像分割可能将狗分割成两个区域:一个覆盖以黑色为主的嘴巴和眼睛,而另一个覆盖以黄色为主的其余部分身体。而实例分割不仅需要区分语义,还要区分不同的目标实例。如果图像中有两只狗,实例分割需要区分像素属于这两只狗中的哪一只。
语义分割数据集

- 样式迁移常用的损失函数由3部分组成:
- 内容损失(content loss)使合成图像与内容图像在内容特征上接近
- 样式损失(style loss)令合成图像与样式图像在样式特征上接近
- 总变差损失(total variation loss)则有助于减少合成图像中的噪点。
6.5.2 代价函数

6.6 人脸识别
6.6.1 人脸验证与人脸识别
人脸验证为一对一的问题,人脸识别为一对多的问题。
6.6.2 人脸验证问题
旧有思路
转化为分类问题
现有思路
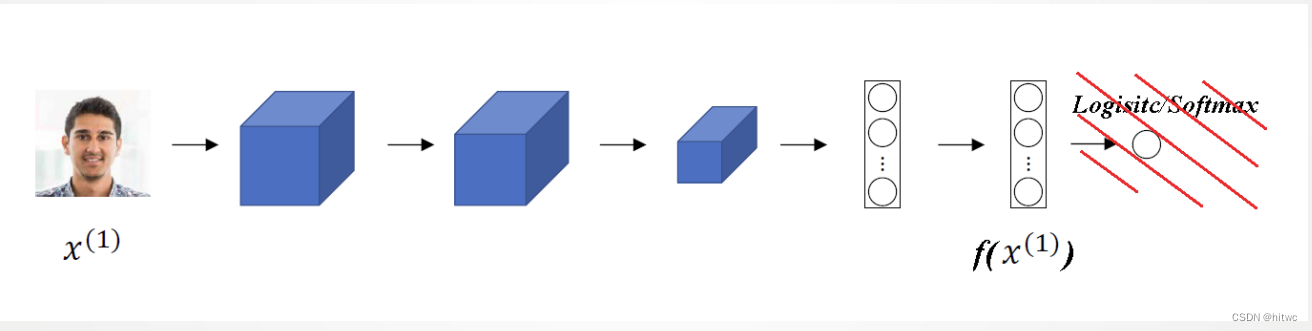
1.构建神经网络(Siamese网络)
对输入图片进行编码
2.训练神经网络
通过训练神经网络,我们希望同一人的两张照片间的相似度函数值尽可能小,不同人的两张片间的相似度函数值尽可能大,下以此为目标制作训练集、定义Loss函数。Loss函数定义如下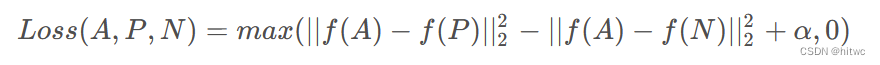
3.运行神经网络
对于训练完毕的神经网络,输入照片,通过简单的for循环语句遍历数据库中存储的所有照片,依次通过相似度函数进行计算,记录遍历过程中相似程度最大的值,在遍历结束后与预先设定的阈值进行比较,得出预测结果,完成人脸识别。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









