



 文章介绍了卷积神经网络的基础,包括AlexNet的网络结构和改进,如ReLU激活函数和双GPU策略。接着讨论了VGG-16的规模增大和结构规整性。然后提到了残差网络解决梯度消失问题的方法,以及常见的数据集,如MNIST、Fashion-MNIST等。最后,文章涉及了深度学习在目标检测中的应用,如YOLO算法及其目标检测的挑战。
文章介绍了卷积神经网络的基础,包括AlexNet的网络结构和改进,如ReLU激活函数和双GPU策略。接着讨论了VGG-16的规模增大和结构规整性。然后提到了残差网络解决梯度消失问题的方法,以及常见的数据集,如MNIST、Fashion-MNIST等。最后,文章涉及了深度学习在目标检测中的应用,如YOLO算法及其目标检测的挑战。
五、卷积神经网络基础
5.4 基本卷积神经网路
5.4.1 AlexNet
网络结构:
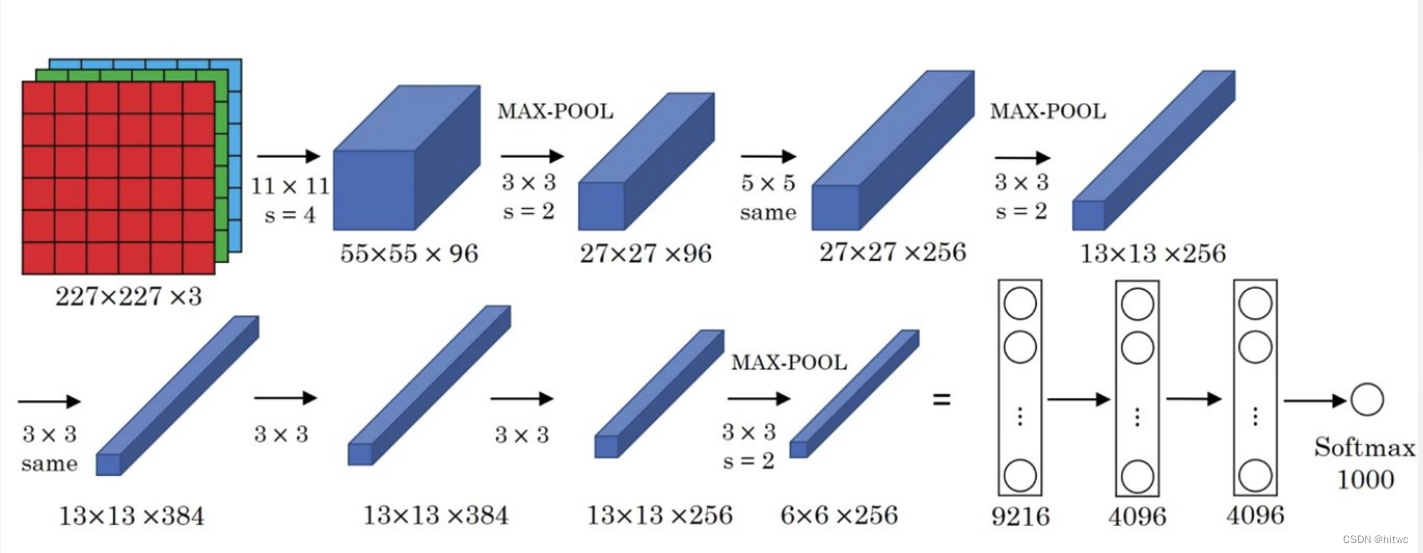
网络说明:
- 网络一共有8层可学习层——5层卷积层和3层全连接层
- 改进
- -池化层均采用最大池化
- -选用ReLU作为非线性环节激活函数
- -网络规模扩大,参数数量接近6000万
- -出现“多个卷积层+一个池化层”的结构
- 普遍规律
- -随网络深入,宽、高衰减,通道数增加。下图左侧为连接数,右侧为参数。

该网络做了以下多个方面的改进:
(1)改进:输入样本
采用最简单、通用的图像数据变形的方式
a.从原始图像(256,256)中,随机的crop出一些图像(224,224)。【平移变换,crop】
b.水平翻转图像。【反射变换,flip】
c.给图像增加一些随机的光照。【光照、彩色变换,color jittering】

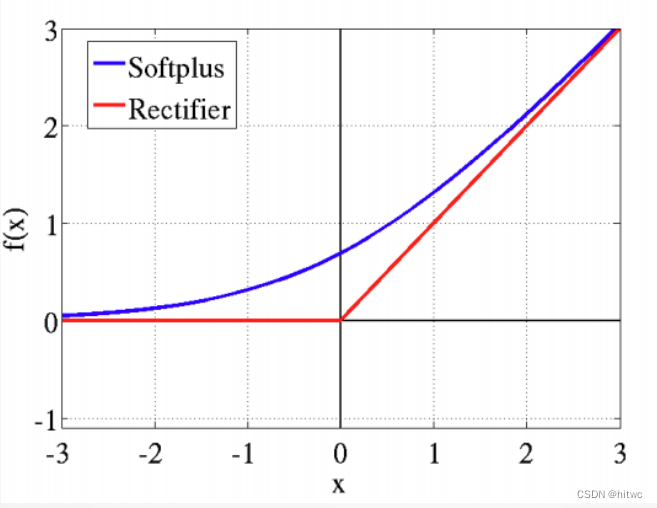
(2)改进:激活函数
a.采用ReLU替代 Tan Sigmoid。
b.用于卷积层与全连接层之后。
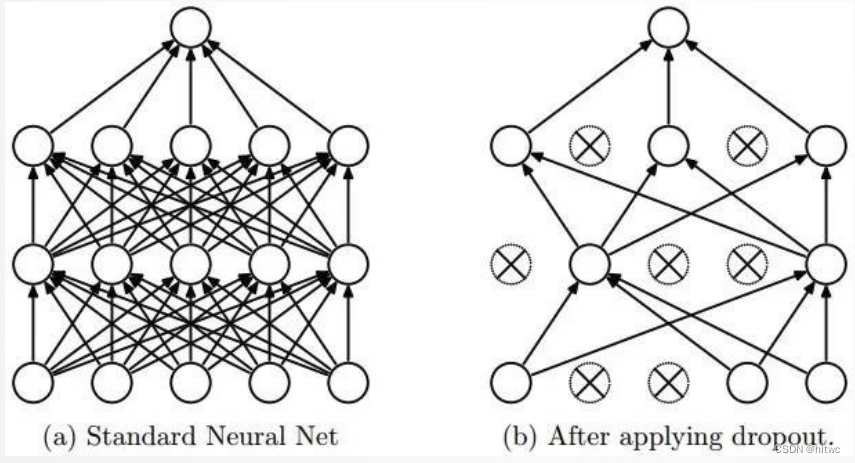
(3)改进: Dropout
在每个全连接层后面使用一个 Dropout 层,以概率 p 随机关闭激活函数。
(4)改进:双GPU策略
AlexNet使用两块GTX580显卡进行训练,两块显卡只需要在特定的层进行通信。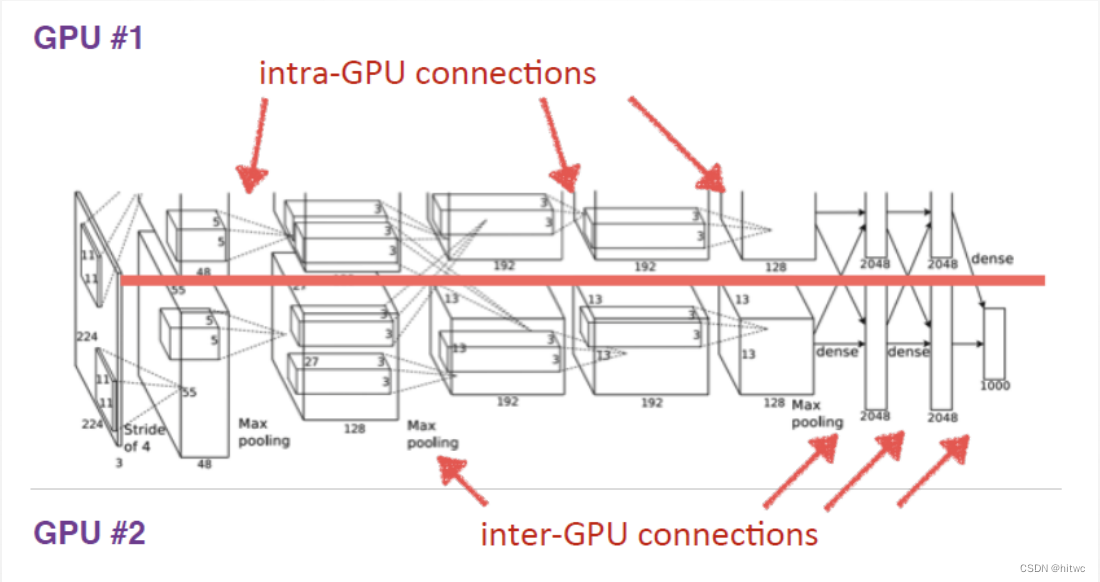
详细解释:以第一层conv1为例
(1)relu1:max(0,x),作为激活函数紧接在卷积层后面。
(2)norm1:局部响应归一化LRN。LRN层作用不大,在CNN中并不常用。
(3)pool1:采用max pooling。
- pooling核大小为3×3
- stride为2,即pooling核的步长是2,即2倍降采样
- 此处的pool1层是有交叠的池化层,即pooling核在相邻位置有重叠
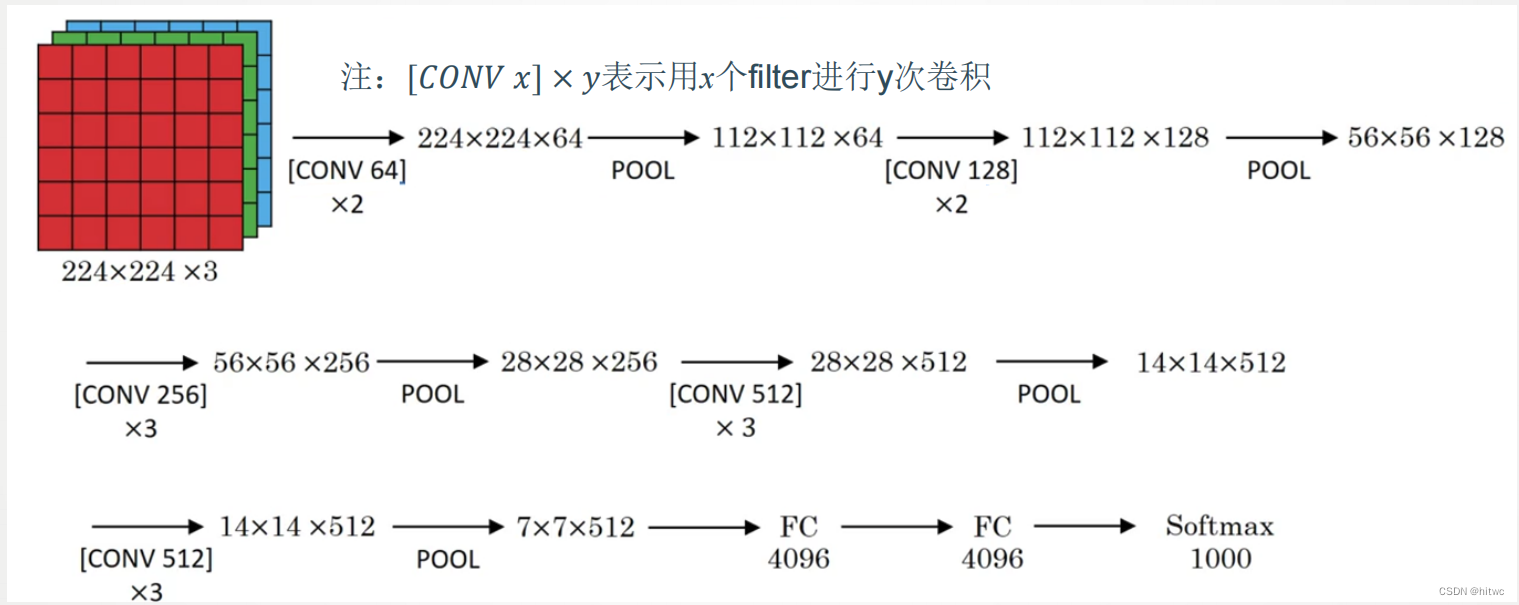
5.4.2 VGG-16
网络结构:
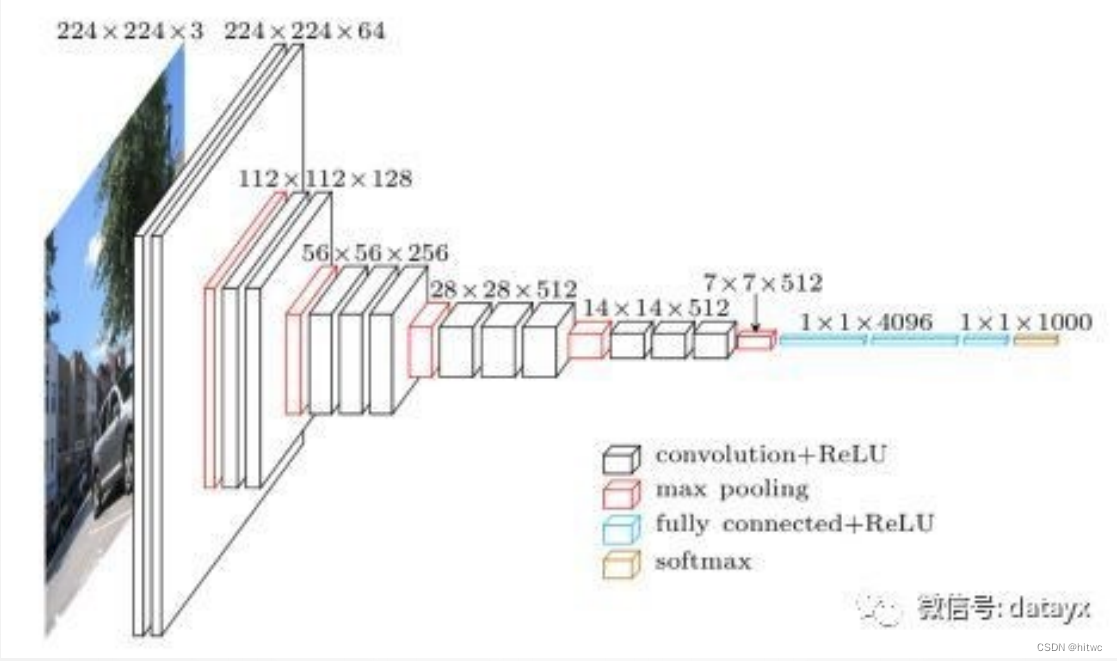
参数数量变化如下图所示:
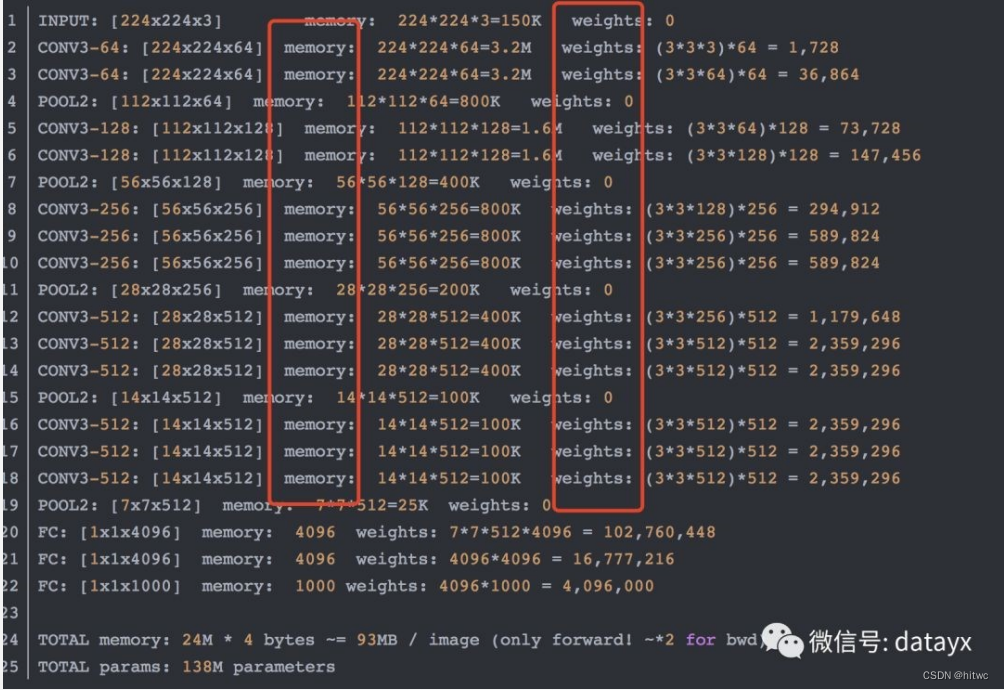
网络说明:
- 改进
- -网络规模进一步增大,参数数量约为1.38亿
- -由于各卷积层、池化层的超参数基本相同,整体结构呈现出规整的特点。
- 普遍规律
- -随网络深入,高和宽衰减,通道数增多。
5.4.3 残差网络
非残差网络的缺陷
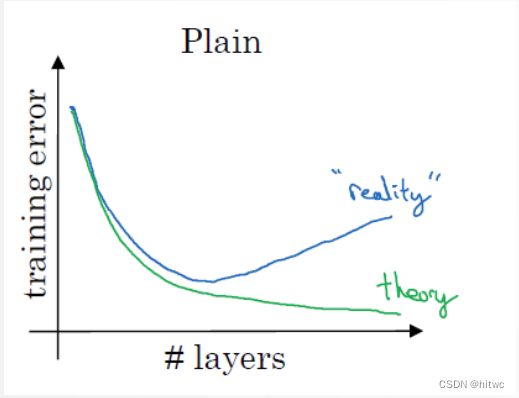
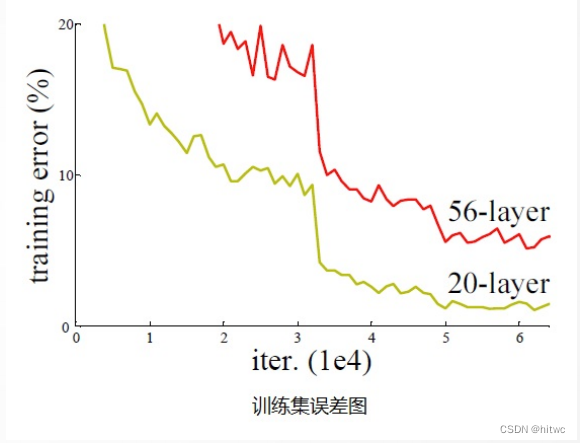
残差网络的优势
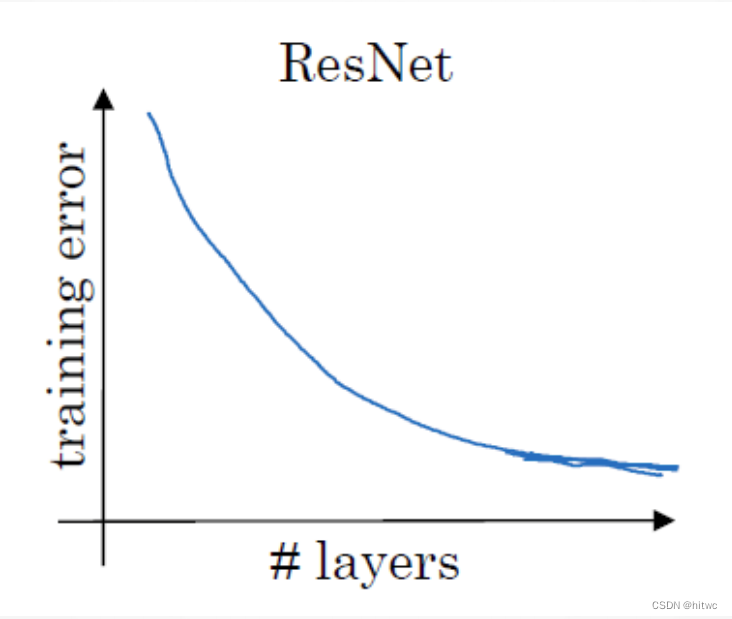
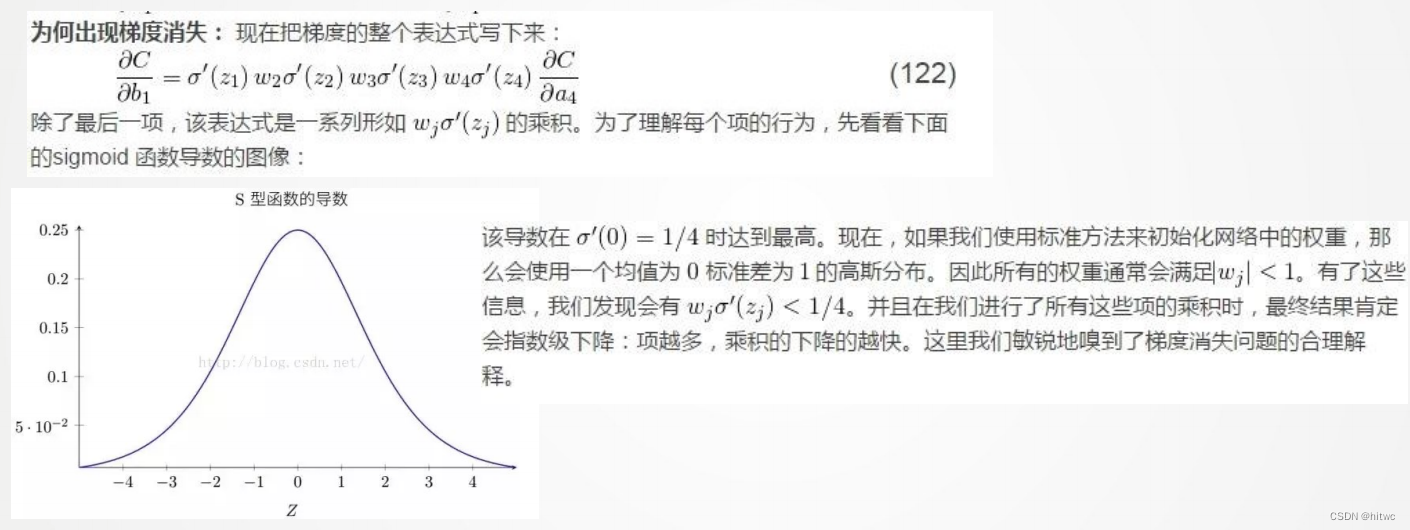
梯度消失问题

残差块
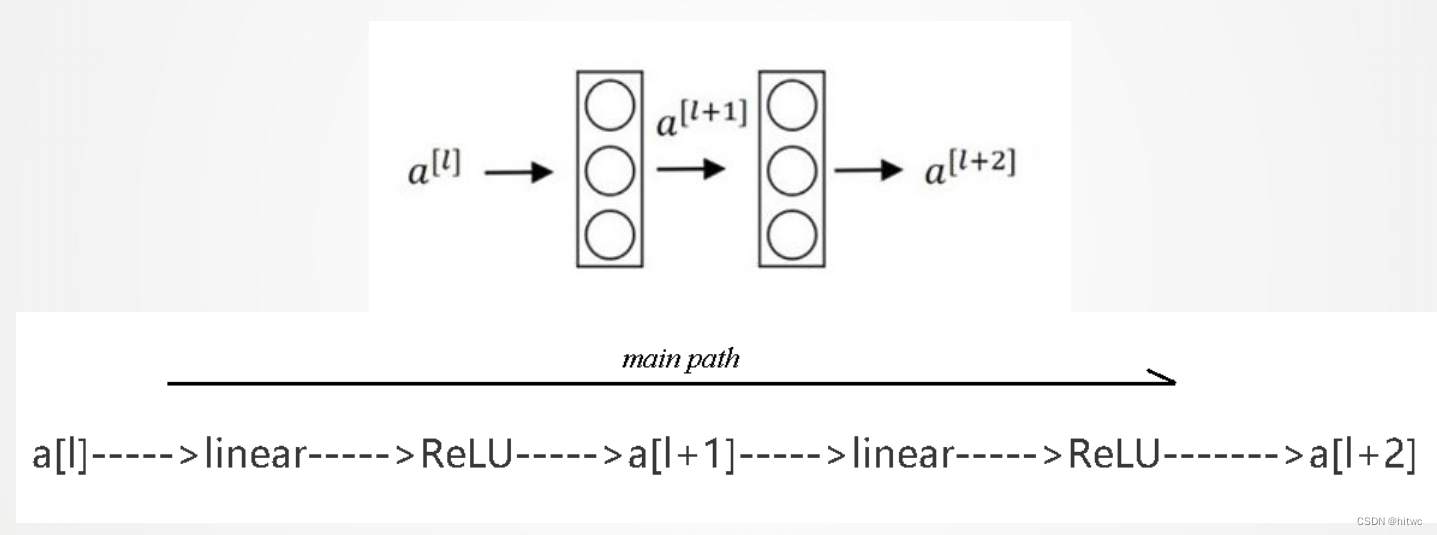
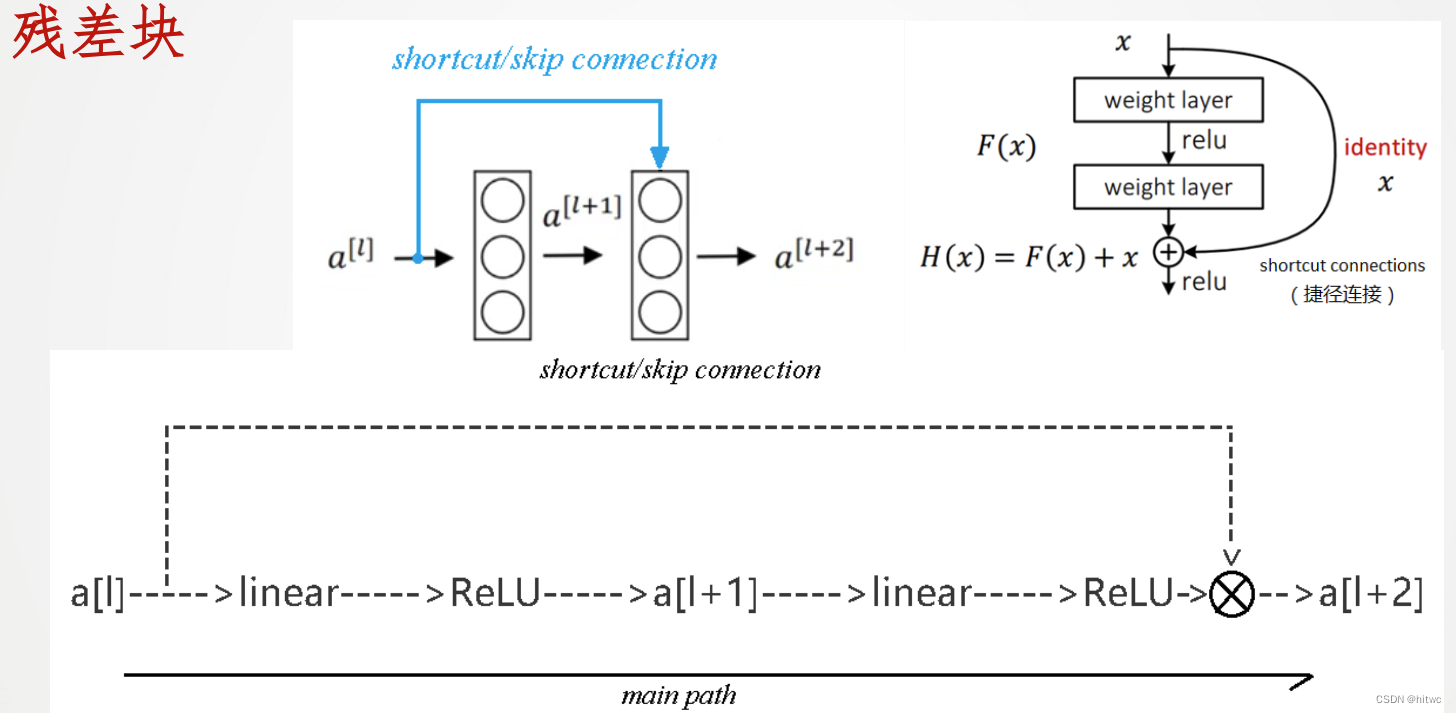
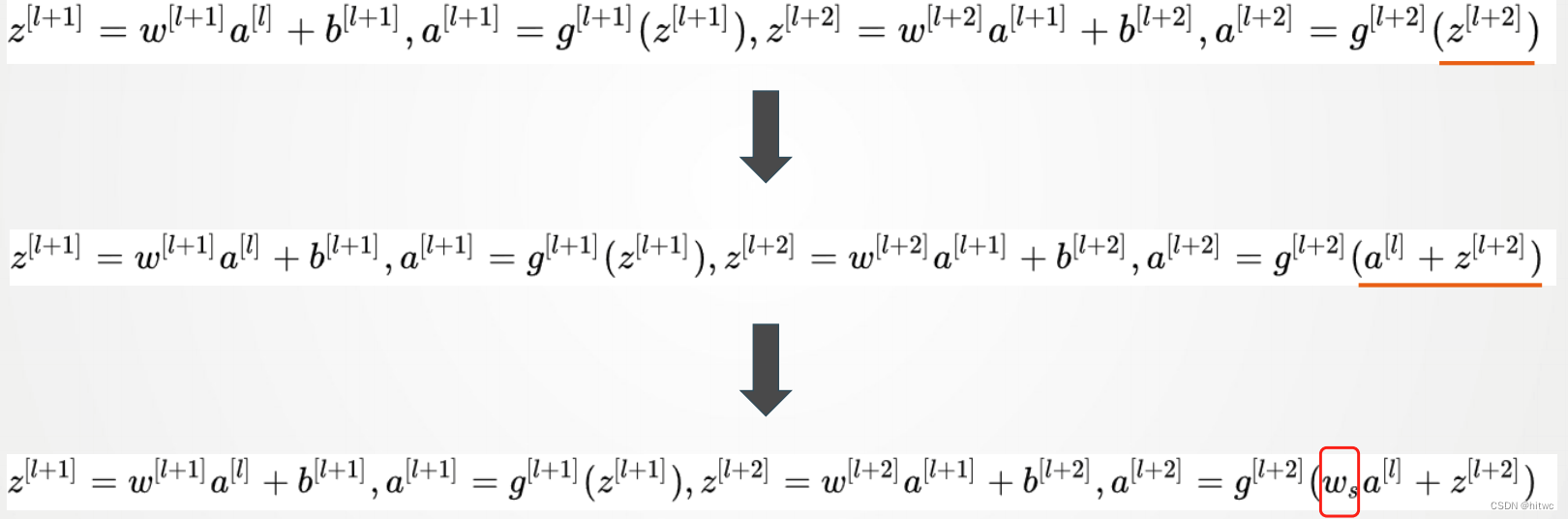
残差网络
(1)普通网络的基准模型受VGG网络的启发。
(2)卷积层主要有3×3的过滤器,并遵循两个简单的设计规则:①对输出特征图的尺寸相同的各层,都有相同数量的过滤器; ②如果特征图的大小减半,那么过滤器的数量就增加一倍,以保证每一层的时间复杂度相同。
(3)ResNet模型比VGG网络更少的过滤器和更低的复杂性。ResNet具有34层的权重层,有36亿FLOPs,只是VGG-19(19.6亿FLOPs)的18%。
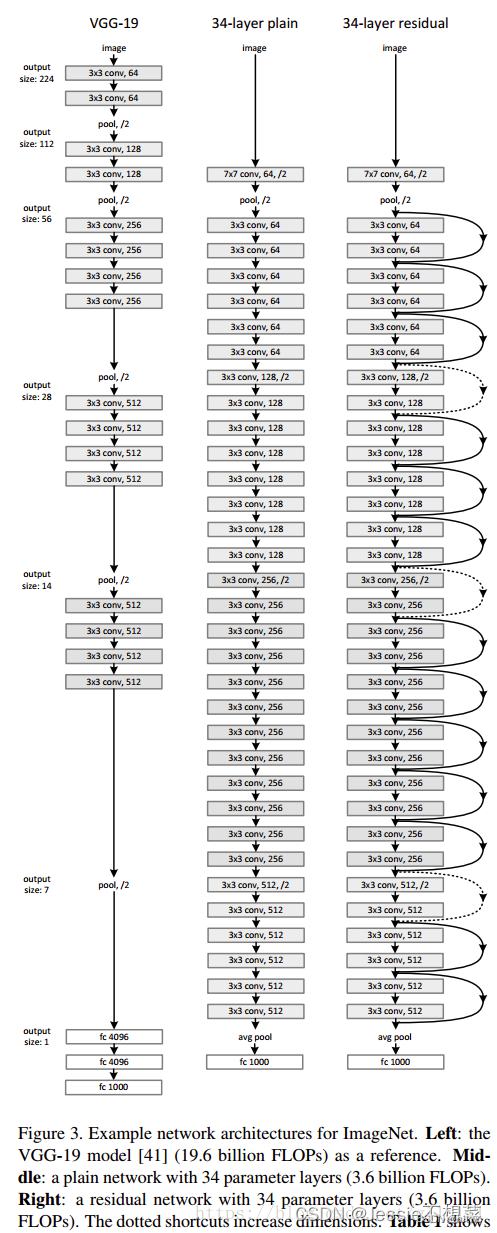
5.4.4 常见数据集
(1) MNIST
MNIST数据集是由0〜9手写数字图片和数字标签所组成的,由60000个训练样本和10000个测试样本组成,每个样本都是一张28 * 28像素的灰度手写数字图片。

(2)Fashion-MNIST数据集
FashionMNIST 是一个替代 MNIST 手写数字集的图像数据集。它是由 Zalando旗下的研究部门提供,涵盖了来自 10 种类别的共 7 万个不同商品的正面图片。
FashionMNIST 的大小、格式和训练集/测试集划分与原始的MNIST 完全一致。60000/10000 的训练测试数据划分,28x28的灰度图片。你可以直接用它来测试你的机器学习和深度学习算法性能,且不需要改动任何的代码。

(3)CIFAR-10数据集
CIFAR-10数据集由10个类的60000个32x32彩色图像组成,每个类有6000个图像。有50000个训练图像和10000个测试图像。
数据集分为五个训练批次和一个测试批次,每个批次有10000个图像。测试批次包含来自每个类别的恰好1000个随机选择的图像。

(4)PASCAL VOC数据集
a. PASCAL的全称是Pattern Analysis, Statistical Modelling and Computational Learning
b. VOC的全称是Visual Object Classes
c. 目标分类(识别)、检测、分割最常用的数据集之一
d. 第一届PASCAL VOC举办于2005年,2012年终止。常用的是 PASCAL 2012
(5)MS COCO数据集
a. PASCAL的全称是Microsoft Common Objects in Context,起源于微软于2014年出资标注的Microsoft COCO数据集
b. 数据集以scene understanding为目标,主要从复杂的日常场景中截取
c. 包含目标分类(识别)、检测、分割、语义标注等数据集
d. ImageNet竞赛停办后,COCO竞赛就成为是当前目标识别、检测等领域的一个最权威、最重要的标杆
官网:http://cocodataset.org
(6)ImageNet数据集
a. 始于2009年,李飞飞与Google的合作:“ImageNet: A Large-Scale Hierarchical Image Database”
b. 总图像数据:14,197,122
c. 总类别数:21841
d. 带有标记框的图像数:1,034,908
六、深度学习视觉应用
6.1 算法评估
相关概念:
TP:被正确地划分为正例的个数,即实际为正例且被分类器划分为正例的实例数。
FP:被错误地划分为正例的个数,即实际为负例但被分类器划分为正例的实例数。
FN:被错误地划分为负例的个数,即实际为正例但被分类器划分为负例的实例数。
TN:被正确地划分为负例的个数,即实际为负例且被分类器划分为负例的实例数。
假设一个测试集由大雁和飞机组成
置信度与准确率
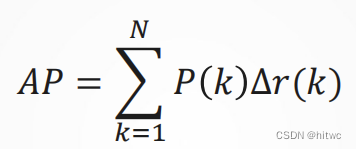
mAP计算(均值平均准确率):
- 每一个类别均可确定对应的AP
- 多类的检测中,取每个类AP的平均值,即为mAP
6.2 目标检测与YOLO
目标检测问题
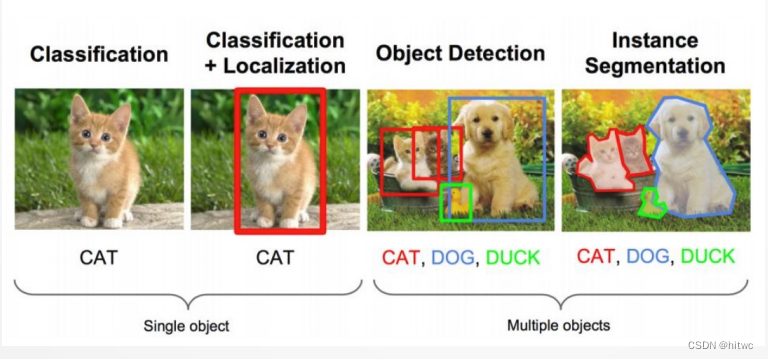
目标检测问题发展
- R-CNN
- SPP NET
- Fast R-CNN
- Faster R-CNN
- 最终实现YOLO





















 到【灌水乐园】发言
到【灌水乐园】发言








