







 本文详述Go语言中map的实现原理,包括数据结构、初始化、访问与写入、扩容及删除操作。同时探讨了map的非协程安全特性,并解析了sync.map的线程安全实现及其适用场景。
本文详述Go语言中map的实现原理,包括数据结构、初始化、访问与写入、扩容及删除操作。同时探讨了map的非协程安全特性,并解析了sync.map的线程安全实现及其适用场景。
文章目录
前言
本文主要记录:
1.map的实现原理。
2.拉链法原理。
3.map是否协程安全的。
4.sync.map的实现原理。
一、map的实现原理
1.数据结构:
go中的map是同时使用了多个数据结构结合哈希表来实现的。go使用runtime.hmap这个struct来表示map
type hmap struct {
// 存储的元素的个数
count int
flags uint8
// 当前哈希表拥有的桶的数量
B uint8
noverflow uint16
// hash时用到的值
hash0 uint32
// []bmap 桶数组
buckets unsafe.Pointer
oldbuckets unsafe.Pointer
nevacuate uintptr
extra *mapextra
}
type mapextra struct {
overflow *[]*bmap
oldoverflow *[]*bmap
nextOverflow *bmap
}
// bmap实际上是一个可以存8个元素的uint8数组,存储的是 高8位的hash值
type bmap struct {
tophash [bucketCnt]uint8
}
// 这里展示了更多的bmap数据结构的字段
type bmap struct {
topbits [8]uint8
keys [8]keytype
values [8]valuetype
pad uintptr
overflow uintptr
}

2.初始化:
map的初始化分为字面量(编译器)和运行期初始化两种方式。
2.1 字面量初始化方式:
1)当使用字面量进行初始化的key value键值对的个数小于25个时,底层实际上会一次性将所有的键值对都加进hashmap中。如下代码所示:
hash := make(map[string]int, 3)
hash["1"] = 2
hash["3"] = 4
hash["5"] = 6
- 当元素大于25个时,底层会使用两个切片,一个key的切片,一个value的切片,然后通过循环下标的方式对hash进行赋值操作。()
hash := make(map[string]int, 26)
vstatk := []string{"1", "2", "3", ... , "26"}
vstatv := []int{1, 2, 3, ... , 26}
for i := 0; i < len(vstatk); i++ {
hash[vstatk[i]] = vstatv[i]
}
2.2 运行时创建map的方式:
当创建的map容量比较小的时候,例如小于bucketSize 8 时,会在栈上创建,并且golang底层会使用如下的方式快速创建:
var h *hmap
var h1 hmap
var bv bmap
// 直接赋值初始化一个 hmap
h = &h1
b := &bv
// 初始化一个bmap
h.buckets = b
// 获得一个hash种子
h.hash0 = fashtrand0()
2.3 make(map) 底层实际的函数代码
以下代码是makemap底层的代码,它实际做了以下的事情:
1)判断hint是否超出能分配的最大值,hint值实际上就是
m := make(map[string]int, 1000) 中的用户传入的1000,这里假设要分配存入1000个元素。如果overflow了或者超出了最大可分配的内存,就会赋值为0。
2) h.hash0 = fastrand() 得到一个hash种子
3) 通过hint计算需要存储的桶的个数
4)通过makeBucketArray创建桶数组(也就是[]bmap)
5)makeBucketArray 中溢出桶的初始化需要留意,当:
- 当桶的数量小于 24 时,由于数据较少、使用溢出桶的可能性较低,会省略创建的过程以减少额外开销;
- 当桶的数量多于 24 时,会额外创建 2𝐵−4 个溢出桶;
func makemap(t *maptype, hint int, h *hmap) *hmap {
mem, overflow := math.MulUintptr(uintptr(hint), t.bucket.size)
if overflow || mem > maxAlloc {
hint = 0
}
if h == nil {
h = new(hmap)
}
h.hash0 = fastrand()
B := uint8(0)
for overLoadFactor(hint, B) {
B++
}
h.B = B
if h.B != 0 {
var nextOverflow *bmap
h.buckets, nextOverflow = makeBucketArray(t, h.B, nil)
if nextOverflow != nil {
h.extra = new(mapextra)
h.extra.nextOverflow = nextOverflow
}
}
return h
}
3.访问与写入
3.1 map的访问:
map的访问有如下两种方式,其在编译阶段生成的中间代码是注释所展示的。
v := hash[key] // => v := *mapaccess1(maptype, hash, &key)
v, ok := hash[key] // => v, ok := mapaccess2(maptype, hash, &key)
*mapacess函数代码:
func mapaccess1(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
//1) t.hasher是一个函数,它可以传入key和种子得到一个hash值。
hash := t.hasher(key, uintptr(h.hash0))
m := bucketMask(h.B)
//2) 通过传入桶数组,得到具体桶的下标。
b := (*bmap)(add(h.buckets, (hash&m)*uintptr(t.bucketsize)))
if c := h.oldbuckets; c != nil {
if !h.sameSizeGrow() {
// There used to be half as many buckets; mask down one more power of two.
m >>= 1
}
oldb := (*bmap)(add(c, (hash&m)*uintptr(t.bucketsize)))
if !evacuated(oldb) {
b = oldb
}
}
//3) 得到hash的高8位
top := tophash(hash)
bucketloop:
for ; b != nil; b = b.overflow(t) {
for i := uintptr(0); i < bucketCnt; i++ {
if b.tophash[i] != top {
if b.tophash[i] == emptyRest {
break bucketloop
}
continue
}
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
if t.indirectkey() {
k = *((*unsafe.Pointer)(k))
}
if t.key.equal(key, k) {
e := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.elemsize))
if t.indirectelem() {
e = *((*unsafe.Pointer)(e))
}
return e
}
}
}
return unsafe.Pointer(&zeroVal[0])
}
在bucketloop的循环中:
1)哈希会依次遍历正常桶和溢出桶的数据。
2)通过比较传入的与桶中的tophash。
3)如果tophash相等,就可以通过指针和偏移量获取哈希中存储的键key[0]并与key进行比较,如果相同,那么该key对应的值就是需要的值value[0]就会直接返回。
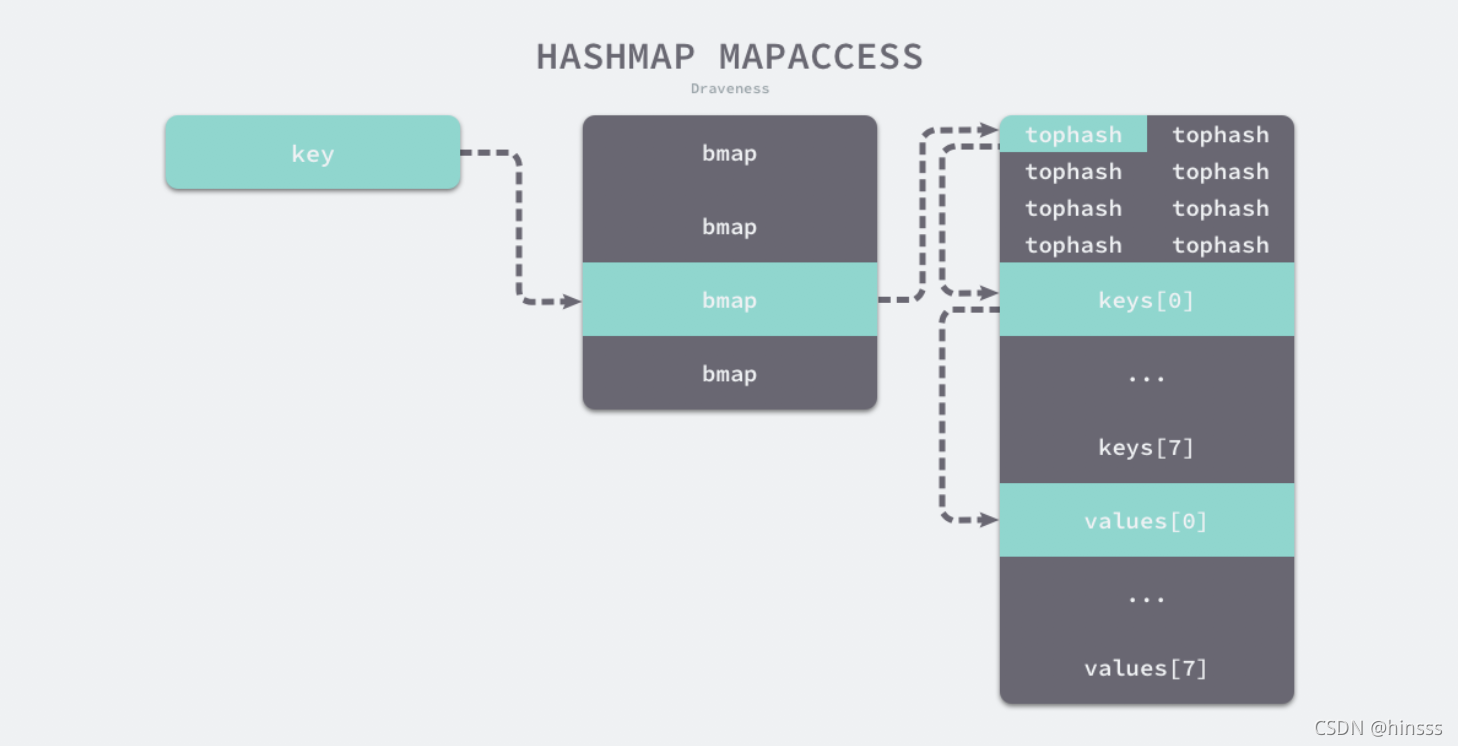
3.2 map的写入
如果有hash[k]这样的表达式出现在赋值语句的左边时,意味着就是map的赋值操作。编译时会转换成中间代码,调用runtime.mapassign()方法完成hashmap的赋值操作。
*mapassign代码如下:
1)首先还是根据传入的key得到hash和桶的下标。
2)接着是遍历桶中的tophash数组,比较传入的hash值是否相等,如果有相等的,那么则是更新操作,通过指针和偏移量修改value的值。
如果找不到相同的,且桶未满,则通过指针偏移量设置key 和 value.
3)当桶存储的key value满了的时候,就会使用到溢出桶来存储新增的键值对。
func mapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
alg := t.key.alg
hash := alg.hash(key, uintptr(h.hash0))
h.flags ^= hashWriting
again:
bucket := hash & bucketMask(h.B)
b := (*bmap)(unsafe.Pointer(uintptr(h.buckets) + bucket*uintptr(t.bucketsize)))
top := tophash(hash)
*总结: 哈希的遍历与写入共同点都会有以下的步骤:
1)根据传入的key计算hash
2)计算桶的下标
3)遍历桶中的hash来判断相等。并且遍历的过程还会包括溢出桶的遍历。
写入时会创建溢出桶。
4)溢出桶的使用是在当前bmap中的元素满了之后。
它的设计就是为了临时存放一些溢出的键值对,从而尽量减少扩容操作。
4.哈希的扩容:
4.1 哈希会在以下两种情况下触发扩容:
- 装载因子超过6.5(也就是键值对的数量是桶的数量的6.5倍(?))
- 溢出桶的数量使用过多
4.2 溢出桶的等量扩容
如果扩容操作是溢出桶使用过多导致的,那么这一次扩容是等量的,这里强调的是新创建等量的桶来装东西。
4.3 装载因子超过6.5的扩容
这种情况下哈希会创建一组新的桶和预创建的溢出桶,随后将原有的桶数组设置到oldbuckets上,并将新的空桶设置到buckets中,溢出桶也是同样的逻辑,随后进行从旧桶到新桶间的数据迁移工作。
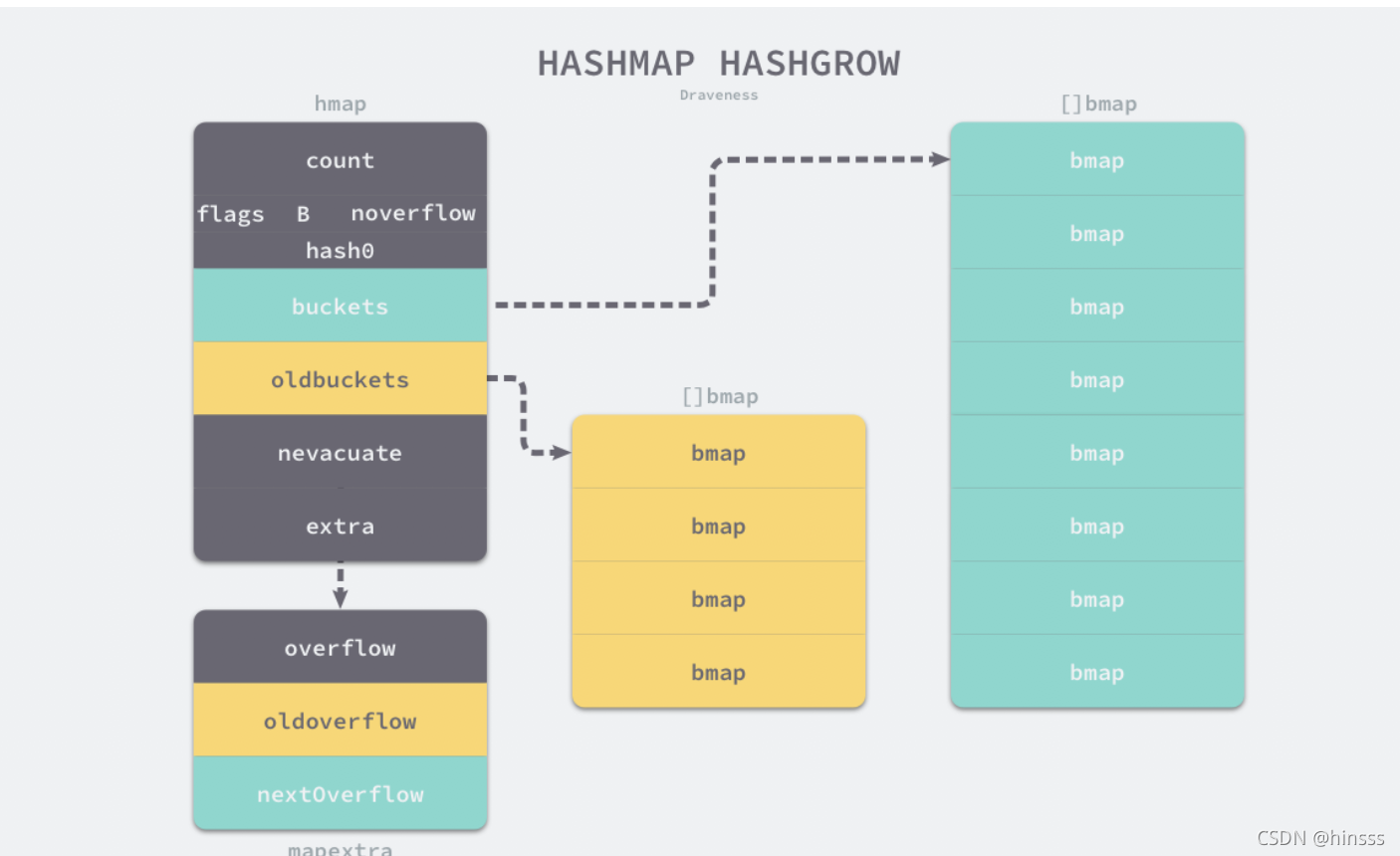
数据迁移的工作是在runtime.evacuate中进行的,这个过程会将一个旧桶的数据分流到两个新桶中,所以它会创建两个用于保存分配上下文的runtime.evacDst结构体,这两个结构体分别指向了一个新桶:
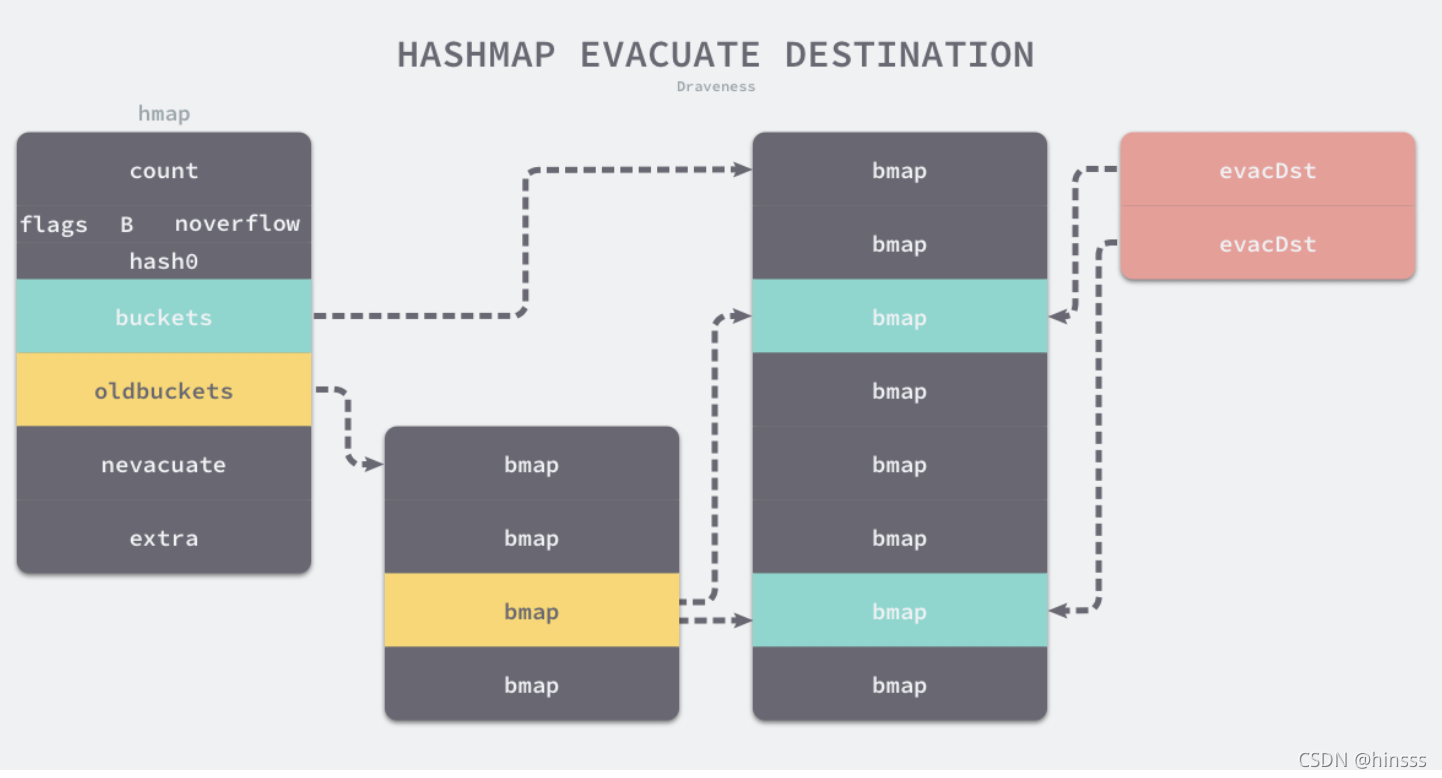
5.删除操作
在编译期间,map的delete关键字会被替换成ODELETE节点,而最终执行的代码是runtime.mapdelete()的底层库代码:
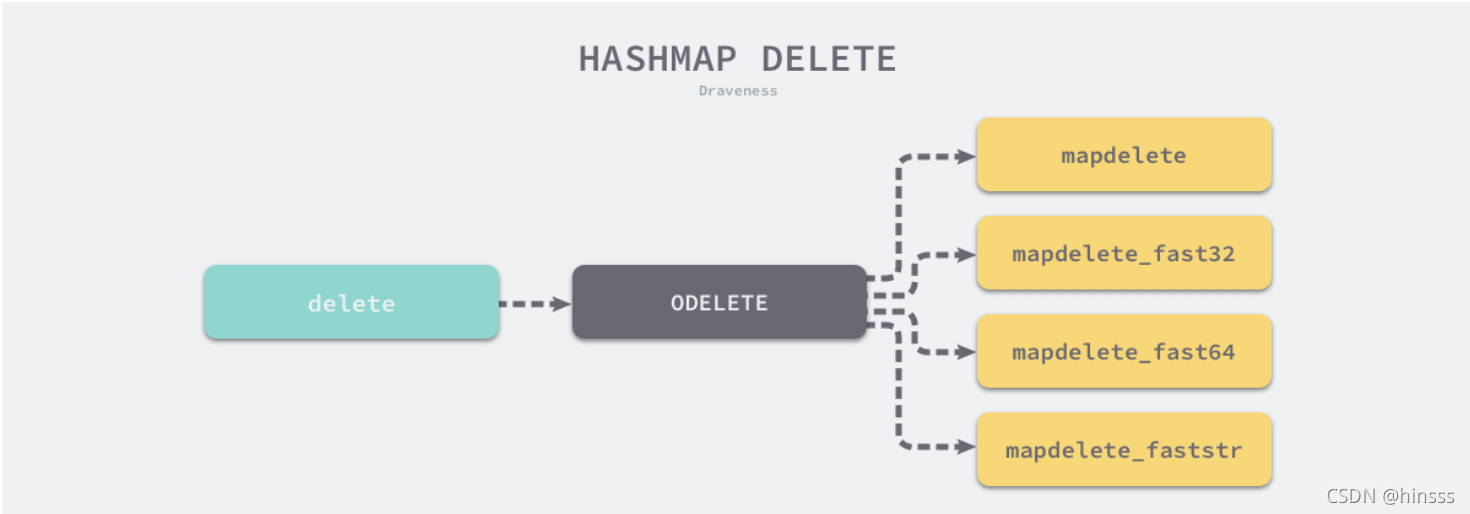
map的删除与新增过程基本差不多,都是需要将传入的key得到hash值、计算桶的下标,遍历比较tophash,如果能找到对应的值则清空key value。没有就没有了。delete(key)关键字不会返回任何东西。
func delete(m map[Type]Type1, key Type) // 无返回值
二、拉链法原理
拉链法是指数组+链表来实现哈希表的底层数据结构。
-
使用拉链法写入键值对:
1)首先需要通过哈希函数来计算哈希值,然后通过哈希值对桶数组的长度取模得到桶的索引。
2)当有多个key计算出了同一个桶后,分为两个操作,如果key相同则更新key的value,如果key不相同则直接往链表的尾部添加元素。 -
使用拉链法读取数据时:
首先也是通过哈希函数得到桶的下标,然后遍历链表,找到key相同的元素返回,如果遍历完都找不到,说明元素不在哈希表中。 -
使用拉链法读取数据时:
拉链法的扩容与装载因子有关,一个性能较好的哈希表中,全部桶里都会有1~2个元素,哈希表的性能消耗主要在 计算哈希、定位桶、遍历链表三个过程里。装载因子的计算公式 =元素数量÷桶数量 ; 一般装载因子都不会超过1,当装载因子比较大例如超过0.75这个数时,就会触发扩容 rehash机制,重新将所有的元素 做写入键值对的操作,只是桶的数量多了,计算的桶索引变了。
三、map是否协程安全的?
map是非协程安全的,以下使用代码进行模拟并发场景下对map中的不同key一个goroutine进行key=1的写入,一个gorountine进行key=2的获取。程序监测到对map的并发读写就会panic。
func main() {
var m = make(map[int]int,10) // 初始化一个map
go func() {
for {
m[1] = 1 //设置key
}
}()
go func() {
for {
_ = m[2] //访问这个map
}
}()
select {}
}
四、sync.map的实现原理
1.由于golang自带的map是非线程安全的,所以我们首先需要思考如何实现一个线程安全的map结构:
-
首先map的基本操作有添加操作,删除操作,更新操作,取值操作,遍历操作。
对于前三种,在操作的前后添加写锁,让写操作优先并与其它操作互斥。
在读操作前后加上读锁,保证可以并发读取。
*缺点: 由于加了锁,实际上会大大降低性能,因为所有的更新操作都会锁住整个map。
针对这一点,优化的思路是: 尽量减少锁的粒度和锁的持有时间 -
采用分片加锁的方法降低锁的粒度,减少锁持有的时间: 将一把锁分成几把锁,每个锁控制一个分片。
var SHARD_COUNT = 32
// 分成SHARD_COUNT个分片的map
type ConcurrentMap []*ConcurrentMapShared
// 通过RWMutex保护的线程安全的分片,包含一个map
type ConcurrentMapShared struct {
items map[string]interface{}
sync.RWMutex // Read Write mutex, guards access to internal map.
}
// 创建并发map
func New() ConcurrentMap {
m := make(ConcurrentMap, SHARD_COUNT)
for i := 0; i < SHARD_COUNT; i++ {
m[i] = &ConcurrentMapShared{items: make(map[string]interface{})}
}
return m
}
// 根据key计算分片索引
func (m ConcurrentMap) GetShard(key string) *ConcurrentMapShared {
return m[uint(fnv32(key))%uint(SHARD_COUNT)]
}
当使用分片锁时,根据你的key通过GetShard方法拿到不同的分片的锁,假设你的map有 1,2,3三个key,当需要并发读写key为1的值时,只拿到管理key为1的分片锁(每个分片的锁都持有自己管理的key value这部分map),其它的key不会被锁住,依然可以读数据。
2.sync.map的使用场景与实现原理:
*sync.map只会在一些特殊的场景上代替读写锁+map来使用:
- 只会增长的缓存系统中,一个 key 只写入一次而被读很多次;
- 多个 goroutine 为不相交的键集读、写和重写键值对。
*sync.map的数据结构:
type Map struct {
mu Mutex
// 基本上你可以把它看成一个安全的只读的map
// 它包含的元素其实也是通过原子操作更新的,但是已删除的entry就需要加锁操作了
read atomic.Value // readOnly
// 包含需要加锁才能访问的元素
// 包括所有在read字段中但未被expunged(删除)的元素以及新加的元素
dirty map[interface{}]*entry
// 记录从read中读取miss的次数,一旦miss数和dirty长度一样了,就会把dirty提升为read,并把dirty置空
misses int
}
type readOnly struct {
m map[interface{}]*entry
amended bool // 当dirty中包含read没有的数据时为true,比如新增一条数据
}
// expunged是用来标识此项已经删掉的指针
// 当map中的一个项目被删除了,只是把它的值标记为expunged,以后才有机会真正删除此项
var expunged = unsafe.Pointer(new(interface{}))
// entry代表一个值
type entry struct {
p unsafe.Pointer // *interface{}
}
*实现原理:
sync.Map采用了空间换时间的思想,如果对于一个map的操作是对于同一个key的更新、访问比较多的话,它的性能会比较好。
- 这是因为,sync.Map的底层的Store Load Delete操作都会优先对read字段进行操作并且这个操作是不会加锁的。
- 当第一次新增一个元素时,read中是不存在的,那么就会加锁访问dirty来进行新增key value的操作。而后来对于同一个key的更新、访问操作等操作,都会在read上进行,那么就是一个无锁的操作。
- missLocked 增加 miss 的时候,如果 miss 数等于 dirty 长度,会将 dirty 提升为 read,并将 dirty 置空。这里的升级就会把dirty的数据迁移到read中,后续操作都会先经过无锁的read进行优先操作。
总结
本文从golang的map的实现上从初始化、访问、新增、删除等操作记录了底层的实现原理。
golang的map本质上是基于拉链法这种 数组+链表的数据结构来实现的,是hash map。
最后从并发的角度了解了如何实现一个线程安全的map并且了解了golang自带的sync.map的实现以及少数的应用场景。
PS:以上图片都是摘自《Go语言设计与实现》一书。

















 973
973

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









