






这里写目录标题
中间还有一些小知识点
HashMap面试题整理:
(自己先做,然后再查)
* 1)JDK1.7与JDK1.8HashMap有什么区别和联系
* 2)用过HashMap没?说说HashMap的结构(底层数据结构 + put方法描述)
* 3)说说HashMap的扩容过程
* 4)HashMap中可以使用自定义类型作为其key和value吗?
* 5)HashMap中table.length为什么需要是2的幂次方
* 6)HashMap与HashTable的区别和联系
* 7)HashMap、LinkedHashMap、TreeMap之间的区别和联系?
* 8)HashMap与WeakHashMap的区别和联系
* 9)WeakHashMap中涉及到的强弱软虚四种引用
* 10)HashMap是线程安全的吗?引入HashTable和ConcurrentHashMap(后面讲)
JDK1.7与JDK1.8HashMap有什么区别和联系
1. 最重要的一点是底层结构不一样,1.7是数组+链表,1.8则是数组+链表+红黑树结构;
2. jdk1.7中当哈希表为空时,会先调用inflateTable()初始化一个数组;而1.8则是直接调用resize()扩容;
3. 插入键值对的put方法的区别,1.8中会将节点插入到链表尾部,而1.7中是采用头插;
4. jdk1.7中的hash函数对哈希值的计算直接使用key的hashCode值,而1.8中则是采用key的hashCode异或上key的hashCode进行无符号右移16位的结果,避免了只靠低位数据来计算哈希时导致的冲突,计算结果由高低位结合决定,使元素分布更均匀;
5. 扩容时1.8会保持原链表的顺序,而1.7会颠倒链表的顺序;而且1.8是在元素插入后检测是否需要扩容,1.7则是在元素插入前;
6. jdk1.8是扩容时通过hash&cap==0将链表分散,无需改变hash值,而1.7是通过更新hashSeed来修改hash值达到分散的目的;
7. 扩容策略:1.7中是只要不小于阈值就直接扩容2倍;而1.8的扩容策略会更优化,当数组容量未达到64时,以2倍进行扩容,超过64之后若桶中元素个数不小于7就将链表转换为红黑树,但如果红黑树中的元素个数小于6就会还原为链表,当红黑树中元素不小于32的时候才会再次扩容。
Hashtable、HashMap、TreeMap都实现了Map接口,使用键值对的形式存储数据和操作数据。
Hashtable是java早期提供的,方法是同步的(加了synchronized)。key和value都不能是null值。
HashMap的方法不是同步的,支持key和value为null的情况。行为上基本和Hashtable一致。由于Hashtable是同步的,性能开销比较大,一般不推荐使用Hashtable。通常会选择使用HashMap。
HashMap进行put和get操作,基本上可以达到常数时间的性能
TreeMap是基于红黑树的一种提供顺序访问的Map,和HashMap不同,它的get或put操作的时间复杂度是O(log(n))。具体的顺序由指定的Comparator来决定,或者根据键key的具体顺序来决定。
linkedhashmap是按照插入顺序迭代的,因为链表采用的是双向链表但因此也使得占用的内存比较大。
hashmap和hashtable
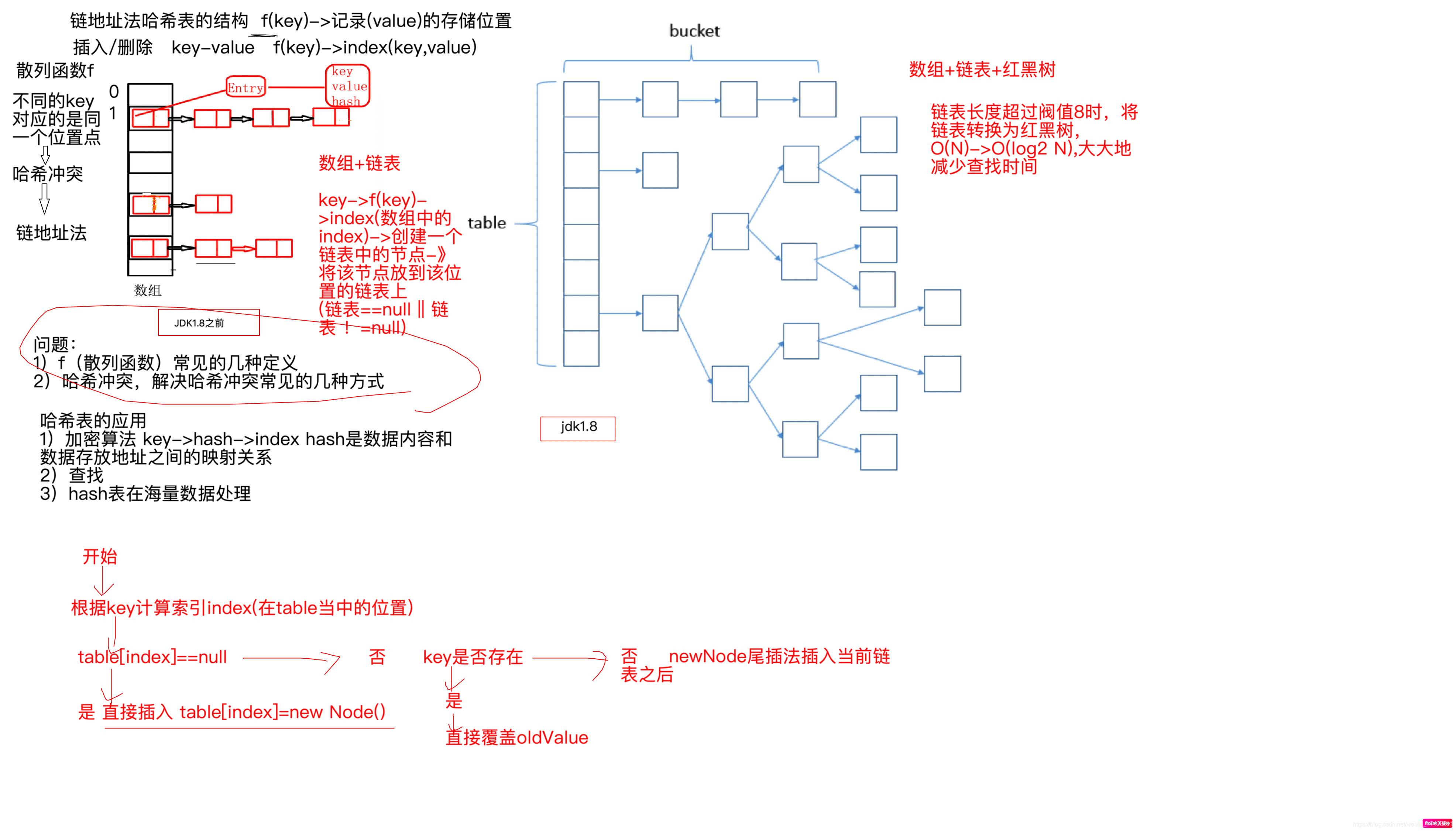
hashmap是线程安全。
Hashtable同样是基于哈希表实现的,同样每个元素是一个key-value对,其内部也是通过单链表解决冲突问题
紫色部分即代表哈希表,也称为哈希数组,数组的每个元素都是一个单链表的头节点,链表是用来解决冲突的,如果不同的key映射到了数组的同一位置处,就将其放入单链表中。
哈希表也叫散列表,hashmap的底层结构是基于哈希表(散列表)实现的


学到这里的时候把这个补充完整。

对于基本数据类型号比较的是值,对于引用数据类型号比较的是地址。
所以一般比较引用数据类型用.equals方法 不过要重写。Compare接口一般对泛型比较大小(引用数据类型的比较.equals方法和Compare)
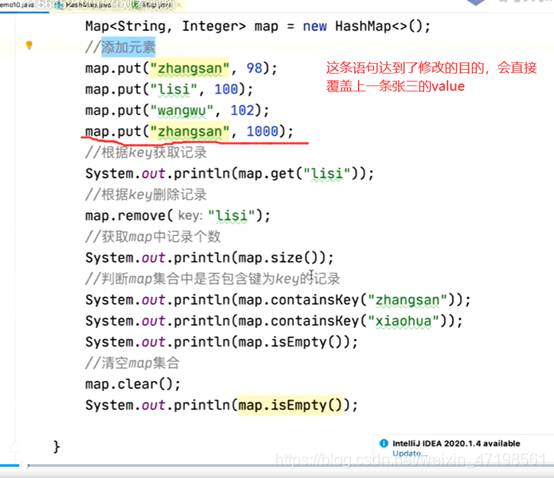
Hashmap有node结点组成的数组,可以往某个结点上续链表。
总结一下hashmap两个方法(add,remove)的步骤:
1获取散列码
2获取位置
3.1firstnode为空
3.2firstnode不为空,
3.2.2.1遍历到最后一个是或不是
3.2.2.2没有遍历到最后一个即找到了。

while (tmp.next!=null&&!tmp.key.equals(key)&&tmp.hash!=hash){
//这里把hash值在比较一下的原因是上面的hash函数返回的hashcode可能会撞值。
pre =tmp;
tmp =tmp.next;
}
HashMap的实现
*自己实现一个哈希表,hash算法类比HashMap中hash算法,解决哈希冲突采用链
* 地址法,实现put(key, value), get(K key), remove(K Key)等方法
*
* 回顾:
* 基于哈希表(散列表),jdk1.8之前采用数组+链表的结构解决哈希冲突,jdk1.8开始
* 采用数组+链表+红黑树
* key->f(key)->index O(1)
* key->f(key)->index->LinkedList O(N)
* -》红黑树 O(log2 N)
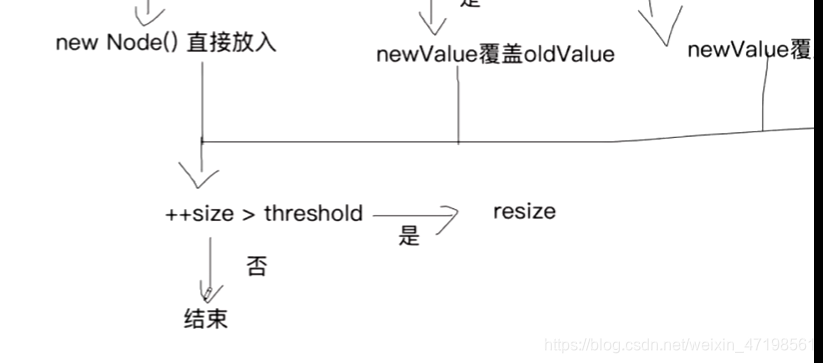
* 以put方法引入
* 自定义put方法
* 1)key-> hash(key) 散列码 -> hash & table.length-1 index
* 2)table[index] == null 是否存在节点
* 3)不存在 直接将key-value键值对封装成为一个Node 直接放到index位置
* 4)存在 key不允许重复
* 5)存在 key重复 考虑新值去覆盖旧值
package collection;
import java.util.Iterator;
/**
* HashMap的实现
* 自己实现一个哈希表,hash算法类比HashMap中hash算法,解决哈希冲突采用链
* 地址法,实现put(key, value), get(K key), remove(K Key)等方法
*
* 回顾:
* 基于哈希表(散列表),jdk1.8之前采用数组+链表的结构解决哈希冲突,jdk1.8开始
* 采用数组+链表+红黑树
* key->f(key)->index O(1)
* key->f(key)->index->LinkedList O(N)
* -》红黑树 O(log2 N)
* 以put方法引入
* 自定义put方法
* 1)key-> hash(key) 散列码 -> hash & table.length-1 index
* 2)table[index] == null 是否存在节点
* 3)不存在 直接将key-value键值对封装成为一个Node 直接放到index位置
* 4)存在 key不允许重复
* 5)存在 key重复 考虑新值去覆盖旧值
* 6)存在 key不重复 尾插法 将key-value键值对封装成为一个Node 插入新节点
*/
class MyHashMap<K,V> {
private int size; //表示map中有多少个键值对
private Node<K, V>[] table;
class Node<K, V> {
protected K key;
protected V value;
private Node<K, V> next;
private int hash;
public Node(int hash, K key, V value) {
this.hash = hash;
this.key = key;
this.value = value;
}
}
public MyHashMap(int capacity) {
table = new Node[capacity];
}
public int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
public void put(K key, V value) {
//key->Hash值->index
int hash = hash(key);//散列码
int index = table.length - 1 & hash;
//当前index位置不存在节点
Node<K, V> firstNode = table[index];
if (firstNode == null) {
//table[index]位置不存在节点 直接插入
table[index] = new Node(hash, key, value);
size++;
return;
}
//key不允许有重复的
//查找当前链表中key是否已经存在
//当前位置存在节点 判断key是否重复
if (firstNode.key.equals(key)) {
firstNode.value = value;
} else {
//遍历当前链表
Node<K, V> tmp = firstNode;
while (tmp.next != null && !tmp.key.equals(key)) {
tmp = tmp.next;
}
if (tmp.next == null) {
//表示最后一个节点之前的所有节点都不包含key
if (tmp.key.equals(key)) {
//最后一个节点的key与当前所要插入的key是否相等,考虑新值覆盖旧值
tmp.value = value;
} else {
//如果不存在,new Node,尾插法插入链表当中
tmp.next = new Node(hash, key, value);
size++;
}
} else {
//如果存在,考虑新值覆盖旧值
tmp.value = value;
}
}
}
public V get(K key) {
//获取key所对应的value
//key->index
int hash = hash(key);
int index = table.length - 1 & hash;
//在index位置的所有节点中找与当前key相等的key
Node<K, V> firstNode = table[index];
//当前位置点是否存在节点 不存在
if (firstNode == null) {
return null;
}
//判断第一个节点
if (firstNode.key.equals(key)) {
return firstNode.value;
} else {
//遍历当前位置点的链表进行判断
Node<K, V> tmp = firstNode.next;
while (tmp != null && !tmp.key.equals(key)) {
tmp = tmp.next;
}
if (tmp == null) {
return null;
} else {
return tmp.value;
}
}
}
public boolean remove(K key) {
//key->index
//当前位置中寻找当前key所对应的节点
int hash = hash(key);
int index = table.length - 1 & hash;
Node<K, V> firstNode = table[index];
if (firstNode == null) {
//表示table桶中的该位置不存在节点
return false;
}
//删除的是第一个节点
if (firstNode.key.equals(key)) {
table[index] = firstNode.next;
size--;
return true;
}
//相当于在链表中删除中间某一个节点
while (firstNode.next != null) {
if (firstNode.next.key.equals(key)) {
//firstNode.next是所要删除的节点
//firstNode是它的前一个节点
//firstNode.next.next是它的后一个节点
firstNode.next = firstNode.next.next;
size--;
return true;
} else {
firstNode = firstNode.next;
}
}
return false;
}
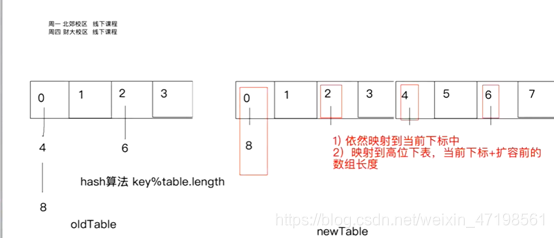
public void resize() {
//HashMap的扩容
//table进行扩容 2倍的方式 扩容数组
Node<K, V>[] newTable = new Node[table.length * 2];
//index -> table.length-1 & hash
//重哈希
for (int i = 0; i < table.length; i++) {
rehash(i, newTable);
}
this.table = newTable;
}
public void rehash(int index, Node<K, V>[] newTable) {
//相当于对原先哈希表中每一个有效节点 进行 重哈希的过程
Node<K, V> currentNode = table[index];
if (currentNode == null) {
return;
}
Node<K, V> lowHead = null; //低位的头
Node<K, V> lowTail = null;//低位的尾
Node<K, V> highHead = null;//高位的头
Node<K, V> highTail = null;//高位的尾
while (currentNode != null) {
//遍历index位置的所有节点
int newIndex = hash(currentNode.key) & (newTable.length - 1);
if (newIndex == index) {
//当前节点链到lowTail之后
if (lowHead == null) {
lowHead = currentNode;
lowTail = currentNode;
} else {
lowTail.next = currentNode;
lowTail = lowTail.next;
}
} else {
//当前节点链到highTail之后
if (highHead == null) {
highHead = currentNode;
highTail = currentNode;
} else {
highTail.next = currentNode;
highTail = highTail.next;
}
}
currentNode = currentNode.next;
}
//要么在原位置 (低位位置)
if (lowHead != null && lowTail != null) {
lowTail.next = null;
newTable[index] = lowHead;
}
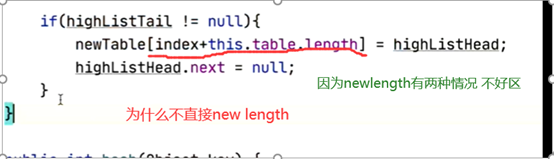
//要么跑到原位置 + 扩容前长度 (高位位置)
if (highHead != null && highTail != null) {
highTail.next = null;
newTable[index + table.length] = highHead;
}
}
public Iterator<Node<K,V>> iterator(){
return new Itr();
}
class Itr implements Iterator<Node<K,V>> {
private int cursor; //指向当前遍历到的元素所在位置点
private Node<K,V> currentNode; //需要反馈的元素节点
private Node<K,V> nextNode; //下一个元素节点
public Itr(){
//由于哈希表数据分布是不连续的,所以在迭代器初始化的过程中需要
//currentIndex currentNode nextNode 初始化
if(MyHashMap.this.size <= 0){
return;
}
//找到第一个非空的位置点,避免无效的迭代
for(int i=0; i<table.length; i++){
if(table[i] != null){
cursor=i;
nextNode = table[i];
return;
}
}
}
@Override
public boolean hasNext() {
return nextNode != null;
}
@Override
public Node<K,V> next() {
//暂时保存需要返回的元素节点
currentNode = nextNode;
//nextNode往后走一个 如果没有到达末尾nextNode
nextNode = nextNode.next;
//迭代器的游标到达某一个桶链表的末尾
if(nextNode == null){
//迭代器的游标需要跳转到下一个非空的位置点
for(int j=cursor+1; j<table.length; j++){
if(table[j] != null){
//table[j]表示该位置的第一个元素
cursor = j;
nextNode = table[j];
break;
}
}
}
return currentNode;
}
}
}
public class HashMapTest {
public static void main(String[] args) {
MyHashMap<Integer, String> map = new MyHashMap<>(16);
map.put(1, "dksjfkjd");
map.put(17, "jd");
map.put(43, "tree");
map.put(21, "hgf");
map.put(67, "uytr");
map.put(7, "iiuyt");
map.put(19, "ygv");
map.put(25, "rdfc");
map.put(33, "edx");
map.put(77, "asdf");
Iterator<MyHashMap<Integer, String>.Node<Integer, String>> itr = map.iterator();
while(itr.hasNext()){
MyHashMap<Integer, String>.Node<Integer, String> next = itr.next();
System.out.println(next.key + ":: "+next.value);
}
}
}
Hashmap中迭代器的用法
(迭代器的实现在hashmap的实现代码里)





HashMap源码分析
/**
* HashMap源码分析
* 1)类的继承关系
* public class HashMap<K,V> extends AbstractMap<K,V>
* implements Map<K,V>, Cloneable, Serializable
* HashMap允许空值和空键
* HashMap是非线程安全
* HashMap元素是无序 LinkedHashMap TreeMap
* (HashTable不允许为空 线程安全)
* 2)类的属性
* static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; 16 默认初始容量 用来给table初始化
* static final int MAXIMUM_CAPACITY = 1 << 30;
* static final float DEFAULT_LOAD_FACTOR = 0.75f; //扩容机制
* static final int TREEIFY_THRESHOLD = 8; //链表转为红黑树的节点个数
* static final int UNTREEIFY_THRESHOLD = 6;//红黑树转为链表的节点个数
* static final int MIN_TREEIFY_CAPACITY = 64;
* static class Node<K,V> implements Map.Entry<K,V>
* transient Node<K,V>[] table; //哈希表中的桶
* transient Set<Map.Entry<K,V>> entrySet; //迭代器遍历的时候
* transient int size;
* int threshold;
* final float loadFactor;
* 3)类中重要的方法 (构造函数 put remove resize)
* 构造函数中并未给桶进行初始化
*
* put
* if ((tab = table) == null || (n = tab.length) == 0)
* n = (tab = resize()).length;
* //resize() 初始化(和扩容)
* if ((p = tab[i = (n - 1) & hash]) == null)
* tab[i] = newNode(hash, key, value, null);
* //当前位置不存在节点,创建一个新节点直接放到该位置
* else{
* //当前位置存在节点 判断key是否重复
* if (p.hash == hash &&
* ((k = p.key) == key || (key != null && key.equals(k))))
* e = p;
* //判断第一个节点的key是否与所要插入的key相等
* //hashCode 表示将对象的地址转为一个32位的整型返回 不同对象的hashCode有可能相等
* //比较hash相比于使用equals更加高效
* else if (p instanceof TreeNode)
* //判断当前节点是否是红黑树节点
* //是的话,则按照红黑树插入逻辑实现
* e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
* else {
* for (int binCount = 0; ; ++binCount) {
* if ((e = p.next) == null) {
* p.next = newNode(hash, key, value, null);
* if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
* treeifyBin(tab, hash);
* break;
* }
* if (e.hash == hash &&
* ((k = e.key) == key || (key != null && key.equals(k))))
* break;
* //判断e是否是key重复的节点
* p = e;
* }
* }
* }
*/
* resie也比较重要
* 还有remove和get可以看看
使用自定义类型作为HashMap的Key
*** 重写hashCode和equals**
*
* 海量数据处理问题
*
* 1、海量日志数据,提取出某日访问百度次数最多的那个IP
* -》2^32 ip地址 4G文件
* hash(ip)%1000 1000个小文件
* 0,1,2,..., 999 把数据加载到内存中,找出每一个ip最大,
* HashMap<ip, count> 1000个小文件中出现频度的ip
* 1000个ip最大找Top1
*
* 2、给定a、b两个文件,各存放50亿个url,每个url各占64字节,
* 内存限制是4G,让你找出a、b文件共同的url
* -》预估每个文件大小为5G*每个url占64 = 一共占320G,不可能
* 全部加载到内存当中
* 每个大文件分为1000个小文件 hash(url)%1000
* a-> a0,a1,a2,...,a999
* b->b0,b1,b2,...,b999
* 相同url对应到相同的文件中,a0vsb0,....
* 对每个小文件逐个去找相同的url,HashSet(key, value),HashSet不允许
* 重复数据
*
* HashSet基于HashMap实现,key是有效值,value是一个常量,key不允许
* 重复,HashSet里面元素不允许重复
* a0 HashSet
* b0
*/
package collection;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
class Student{
private String name;
private int age;
public Student(){
}
public Student(String name, int age){
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Student student = (Student) o;
return this.age == student.age &&
this.name.equals(student.name);
}
@Override
public int hashCode() {
if (name != null ){
return name.hashCode() + age;
}
return 0;
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
}
public class TestDemo14 {
public static void main(String[] args) {
HashMap<Student, String> map = new HashMap<>();
map.put(new Student("张三", 20), "hdjhshjh");
map.put(new Student("张三", 20), "tulun111");
//e.hash==hash && e.key == key || e.key.equals(key)
map.put(new Student("李四", 25), "jdshjd");
map.put(new Student("王五", 22), "teiehff");
map.put(new Student("小明", 18), "okeejjej");
map.put(new Student("小李", 19), "fds1");
Iterator<Map.Entry<Student, String>> itr = map.entrySet().iterator();
while(itr.hasNext()){
Map.Entry<Student, String> next = itr.next();
System.out.println(next.getKey()+":: "+next.getValue());
}
}
}
WeakHashMap Java中四大引用
* 强引用
* A a = new A(); //a是强引用
* 只要是强引用,GC就不会回收被引用的对象
*
* 软引用SoftReference
* 一般用户实现Java对象的缓存,缓存可以有可以没有,一般将有用但是非必须的
* 对象用软引用关联
* 只要是软引用关联的对象,在Java发生内存溢出异常之前,会将这些对象列入要
* 回收的范围,如果回收之后发现内存还是不够,才会抛出OOM异常
* map -》 SoftReference -》 SoftReference.get()
*
* 弱引用 WeakReference
* 弱引用是用来一些非必须的对象,比软引用更弱一些
* 只要是被弱引用关联的对象,只能够生存到下一次垃圾回收之前,一旦发生垃圾回收,
* 无论当前内存是否够用,都会回收掉被弱饮用关联的对象
*
* 虚引用 PhantomReference
* 别名幽灵引用 最弱的引用关系,一个对象是否具有虚引用的存在,完全是不会对其生命
* 周期产生影响,也无法通过虚引用获取一个对象的实例,它存在的唯一目的就是在对象被
* 垃圾回收之后收到一个系统通知
*
* 特殊的HashMap,WeakHashMap的键是弱引用对象,只能存活到下一次垃圾回收之前
*
*
* WeakhashMap与HashMap之间的区别和联系:
* 1)类的继承关系
* 2)put方法逻辑/get/remove
* null值的处理、插入节点的方式、求散列码的方式、扩容的方式、expungexxx等
* 3)使用场景
* WeakHashMap的键是弱引用关联对象
class MyArray{
byte[] bytes = new byte[3*1024*1024];
}
class Test{
}
public class TestDemo15 {
public static void main(String[] args) {
// //软引用对象
// //引用队列
// ReferenceQueue<MyArray> queue = new ReferenceQueue<>();
// //创建一个软引用对象
// SoftReference<MyArray> softReference = new SoftReference<>(new MyArray(), queue);
// //获取软引用对象
// System.out.println(softReference.get());
// //判断是否被回收
// System.out.println(softReference.isEnqueued());
//
// //System.gc();//垃圾回收
// byte[] array = new byte[3*1024*1024];
//
// System.out.println(softReference.get());
// System.out.println(softReference.isEnqueued());
//弱引用对象
// ReferenceQueue<Test> queue = new ReferenceQueue<>();
// WeakReference<Test> weakReference = new WeakReference<>(new Test(), queue);
//
// System.out.println(weakReference.get());
// System.out.println(weakReference.isEnqueued());
//
// System.gc();
//
// System.out.println(weakReference.get());
// System.out.println(weakReference.isEnqueued());
//虚引用对象
ReferenceQueue<Test> queue = new ReferenceQueue<>();
PhantomReference<Test> phantomReference = new PhantomReference<>(new Test(), queue);
System.gc();
if(phantomReference.isEnqueued()){
System.out.println("该对象已经被回收");
}else{
System.out.println("该对象已经被回收");
}
}
}
LinkedHashMap
* 维持插入顺序 (1,"a") (2, "b")
* 维持访问顺序
* 主要是底层维护了一个双向链表,该双向链表会将最近访问的数据放到链表的尾部
*
* static class Entry<K,V> extends HashMap.Node<K,V> {
* Entry<K,V> before, after;//
* Entry(int hash, K key, V value, Node<K,V> next) {
* super(hash, key, value, next);
* }
* }
*
* 实现LRU缓存机制
* LRU缓存:内存访问,设计一个缓存,大小固定,读取内存数据,首先会去缓存是否命中,
* 如果命中,直接返回;反之,未命中从内存中读取数据,把数据继续添加到缓存当中,
* 如果缓存已满,删除访问时间最早的数据
*
* 1)使用LinkedHashMap实现
* 重写removeEldestEntry方法
* a. 通过返回结果去删除访问时间最早的数据
* b. map的size()与给定缓存的最大size比较,如果map.size > MaxSize return true
* c. 参数Map.Entry<K,V> eldest
* 2)自定义实现
class LRUCache<K,V> extends LinkedHashMap<K,V>{
private int maxSize; //缓存的大小
public LRUCache(int maxSize){
super(16, 0.75f, true);
this.maxSize = maxSize;
}
@Override
protected boolean removeEldestEntry(Map.Entry<K,V> eldest){
return size() > maxSize;
}
}
public class TestDemo16 {
public static void main(String[] args) {
LRUCache<String, String> cache = new LRUCache<>(3);
cache.put("a", "jfdshjhf");
//a
cache.put("b", "fdjhfjf");
//a - > b
cache.put("c", "all");
//a -> b -> c
cache.get("a");
//b -> c -> a
cache.put("d", "tulun");
//c -> a -> d
System.out.println(cache);
//维护插入顺序
// LinkedHashMap<Integer, String> map = new LinkedHashMap<>();
// map.put(1, "ajhd");
// map.put(5, "fsd");
// map.put(12, "ref");
// map.put(10, "gdfs");
// map.put(19, "hgf");
// map.put(21, "hgf");
//
// Iterator<Integer> iterator = map.keySet().iterator();
// while(iterator.hasNext()){
// System.out.println(iterator.next());
// }
//维持访问顺序
// LinkedHashMap<Integer, String> map = new LinkedHashMap<Integer, String>(16, 0.75f, true);
// map.put(1, "ajhd");
// map.put(5, "fsd");
// map.put(12, "ref");
// map.put(10, "gdfs");
// map.put(19, "hgf");
// map.put(21, "hgf");
//
// map.get(12);
// map.get(10);
//
// Iterator<Integer> iterator = map.keySet().iterator();
// while(iterator.hasNext()){
// System.out.println(iterator.next());
// }
}
}
package collection;
import java.util.HashMap;
/**
* 自定义实现LRU缓存机制
*
* 存数据的容器:HashMap
* 维护双向链表 数据按照访问时间
*/
class MyLRUCache<K,V>{
private Node<K,V> head = new Node<>();//头
private Node<K,V> tail = new Node<>();//尾
private final HashMap<Integer,Node> hashMap = new HashMap<>();
private int size; //实际大小
private int capacity;//最大容量
class Node<K, V>{
private K key;
private V value;
private Node pre;
private Node next;
public Node(){
}
public Node(K key, V value){
this.key = key;
this.value = value;
}
}
public MyLRUCache(int capacity){
head.next = tail;
tail.pre = head;
this.capacity = capacity;
size = 0;
}
//添加某个节点
private void add(Node node){
}
//删除某个节点
private void remove(Node node){
}
//添加key-value键值对
public void put(K key, V value){
Node node = hashMap.get(key);
if(node != null){
node.value = value;
//从链表中删除node节点
//再将node节点尾插法重新插入链表
}else{
if(size < capacity){
size++;
}else{
//删除缓存中最近最少使用的节点head.next
}
Node newNode = new Node(key, value);
hashMap.put((int)(Math.random()*100), newNode);
//将newNode尾插法插入链表
}
}
//获取value
public int get(K key){
Node node = hashMap.get(key);
if(node == null){
return -1;
}
//删除node
//尾插法重新插入
return 1;
}
}
public class LRUCacheTest {
public static void main(String[] args) {
}
}
TreeMap
* Map -> HashMap SortMap(接口)-> TreeMap
*
* 1)可以按照自然顺序从小到大
* 2)可以按照给定比较器的顺序
*
* HashMap、LinkedHashMap、TreeMap之间的区别和联系
* Collections 集合访问的工具类
* Collectoins.synchornizedxxx()
class P{
protected String name;
protected int score;
public P(String name, int score){
this.name = name;
this.score = score;
}
@Override
public String toString() {
return "P{" +
"name='" + name + '\'' +
", score=" + score +
'}';
}
}
public class TestDemo17 {
public static void main(String[] args) {
Map<P, Integer> map = new TreeMap<>(new Comparator<P>() {
@Override
public int compare(P o1, P o2) {
if(o1.score == o2.score){
return 0;
}
return o1.score > o2.score ? 1 : -1;
}
});
map.put(new P("djhsjh", 80), 1);
map.put(new P("qoje", 78), 2);
map.put(new P("adf", 100), 3);
for(P key: map.keySet()){
System.out.println(key);
}
System.out.println(map.get(new P("qoje", 78)));
// Map<String, Integer> map = new TreeMap<>();
// map.put("apple", 1);
// map.put("orange", 2);
// map.put("banana", 3);
// for(String key: map.keySet()){
// System.out.println(key);
// }
}


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









