




文章目录
一. word2vec向量计算

我们知道词向量的夹角和词义相关,夹角越小,词义越相近。 分析词向量的夹角:
- 使用余弦相似度来计算词向量之间的夹角。 余弦相似度公式: cos ( θ ) = a ⃗ ⋅ b ⃗ ∥ a ⃗ ∥ ∥ b ⃗ ∥ \cos(\theta)=\frac{\vec{a}\cdot\vec{b}}{\|\vec{a}\|\|\vec{b}\|} cos(θ)=∥a∥∥b∥a⋅b
- 对于 A A A和 B B B: cos ( θ A B ) = − 1.8125 1.8125 × 1.8125 = − 1 \cos(\theta_{AB})=\frac{-1.8125}{\sqrt{1.8125}\times\sqrt{1.8125}}=-1 cos(θAB)=1.8125×1.8125−1.8125=−1,这表明 A A A和 B B B的词义相差很大。
- 对于 C C C和 D D D: cos ( θ C D ) = 5.25 5.0625 × 5.4477 ≈ 0.96 \cos(\theta_{CD})=\frac{5.25}{\sqrt{5.0625}\times\sqrt{5.4477}}\approx0.96 cos(θCD)=5.0625×5.44775.25≈0.96,这表明 C C C和 D D D的词义很相近。推测D可能是一种比较正面的动词,比如祝贺等
对于B
大家的第一反应是B很有可能是一个贬义词,比如“坏”“低劣”等。但是这个推论是错误的。好和坏虽然是反义词,距离应该比较大,但是不应该距离这么大(A和B的夹角已经是最大可能了)。好和坏都是形容词,起码词性一样。
考虑到C和A词性不同、夹角已经90度了,说明A和B的词义应该有着巨大的不同。因此随便猜一个名词都是合理的,比如你可以猜北京、清华、皇家马德里、旧金山,都没问题。
二. word2vec的原理

1. 总体思路
2. 基于word2vec的原理
- 训练词向量:用包含大量地理名称的语料库训练 word2vec 模型,得到地理名称的词向量。
- 分析向量关系
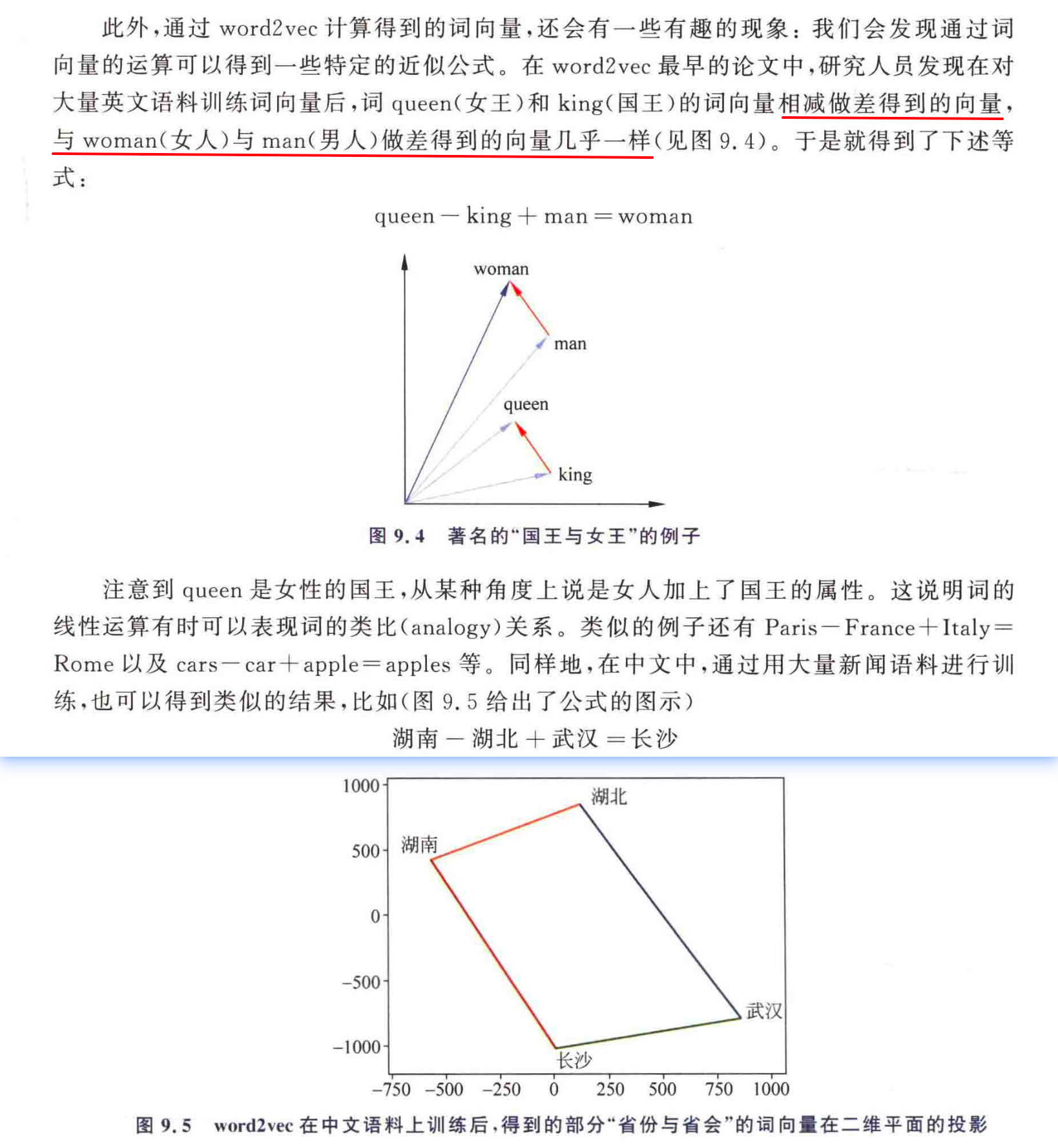
以“湖北 - 湖南 + 长沙 = 武汉”为例:“湖北”和“湖南”在地理位置上相邻,并且都是省份。 “长沙”是“湖南”的省会,“武汉”是“湖北”的省会。 当进行向量运算时,从向量空间的角度来看,“湖北”向量减去“湖南”向量(表示两者在某些语义特征上的差异),再加上“长沙”向量(因为省会与省份有紧密联系),得到的结果向量在向量空间中接近“武汉”向量。
3. 寻找类似例子的思路
首先找出其他相邻省份的组合,例如“山东”和“江苏”是相邻省份,然后找出对应的省会,“山东”的省会是“济南”,“江苏”的省会是“南京”,推测“山东 - 江苏 + 南京”在向量空间中的结果可能接近“济南”。
除了相邻省份,还可以考虑其他地理关系,比如同属于一个地理区域的省份。例如,“广东”和“广西”都属于华南地区。对应的省会分别是“广州”和“南宁”,可以推测“广东 - 广西 + 南宁”在向量空间中的结果可能接近“广州”。
三. 训练写诗

- 利用教材中的建模方式,使用唐诗宋词训练写诗AI的效果
- 风格模仿: 能学到古典诗词韵律,如平仄、押韵,还能掌握经典意象的使用,使诗句有古典韵味。
- 内容生成: 诗句可能含蓄、凝练,但因基于数据模仿,缺乏情感和创新,内容可能存在拼凑感,思想深度不足。
- 使用中文预训练模型并结合唐诗宋词数据训练写诗AI的效果
- 基础优势: 预训练模型已掌握中文语法、语义等知识,在此基础上用唐诗宋词训练,能更好理解诗词语言特点。
- 效果提升:
- 语法与韵律:能更准确把握诗词语法和韵律,处理语序、省略等情况更流畅。
- 语义理解与创新:提升语义理解,生成诗句更具创新性,减少机械模仿感。
- 泛化能力:面对不同主题,能生成更多样、贴合要求的诗句。
总之,使用中文预训练模型并结合唐诗宋词训练写诗AI,在诗句质量、风格、韵律和创作灵活性上有明显提升。
四. Word2vec的逻辑
Word2vec的核心是
- 将词向量的计算转化成机器学习的分类问题,并把每个词的词向量看作机器学习模型的参数,以及把训练语料看成训练数据;
- 然后定义一个分类损失函数,并通过梯度下降算法进行优化;
- 最后分类模型训练收敛后得到的参数就是最终的词向量。
五. 什么是预训练语言模型
预训练语言模型是采用迁移学习的方法,通过无监督学习从大规模的数据中获得与具体任务无关的预训练模型,然后用训练好的预训练模型提高下游任务性能的一种数据增强方法。
- 训练过程
- 通过无监督学习从大规模的数据中获取知识。无监督学习意味着不需要人工标注的数据,模型自己从大量文本中学习语言的规律和特征。例如,从互联网上大量的文章、书籍等文本数据中进行学习。
- 在这个过程中,得到的是与具体任务无关的预训练模型。这个预训练模型能够学习到语言的通用知识,比如语法结构、词汇语义、常见的语言表达方式等。
- 应用过程
- 可以将训练好的预训练模型应用到下游的具体任务中,如文本分类、命名实体识别、文本生成等任务。
- 通过对预训练模型进行微调(在预训练模型的基础上,根据具体任务的数据和目标进行进一步训练),可以提高下游任务的性能,这是一种有效的数据增强方法。例如,在预训练模型基础上,针对文本分类任务,用有标签的分类数据进一步训练,让模型适应分类任务的要求。
(迁移学习是一种机器学习方法,其核心思想是将从一个或多个源任务中学习到的知识和经验,应用到目标任务中,帮助目标任务更好地学习和预测。)
六. GPT和BERT模型
GPT和BERT都使用了Transformer架构,GPT使用了Transformer架构的decoder(解码器)部分,BERT使用了Transformer架构的encoder(编码器)部分。
GPT属于自回归模型,通过预测序列中的下一个词来生成文本,其训练目标是最大化给定前面词的条件概率,即预测下一个词(类似于单词接龙),自回归模型只能使用左侧的上下文信息,因此是单向的,适用于文本生产任务,
BERT属于自编码模型,训练目标是通过掩蔽输入序列中的一些词,训练模型去预测这些被掩蔽的词(类似于完形填空),自编码模型能够使用左右两侧的上下文信息,因此是双向的,适用于文本分类与命名实体等任务。



















 13
13

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











