



将知识与实际的应用场景、设计背景关联起来,这是学以致用、刨根问底知识的一种直接方式。
本文介绍
- 状态数据管理,了解InternalKvState接口的设计以及KeyedState和OperatorState在实现上的区别;
- 状态数据初始化的流程,了解有状态计算的底层实现原理。
一. 状态使用概览
flink中状态存在的意义是什么,涉及到哪些场景。
- 实时聚合:比如,计算过去一小时内的平均销售额。这时,你会需要使用到Flink的状态来存储过去一小时内的所有销售数据。
- 窗口操作:Flink SQL支持滚动窗口、滑动窗口、会话窗口等。这些窗口操作都需要Flink的状态来存储在窗口期限内的数据。
- 状态的持久化与任务恢复:实时任务挂掉之后,为了快速从上一个点恢复任务,可以使用savepoint和checkpoint。
- 多流join:Flink至少存储一个流中的数据,以便于在新的记录到来时进行匹配。
二. 状态的数据类型
从数据集与接口实现两个层面介绍状态分类,与状态的全部类型
1. 算子层面
分类
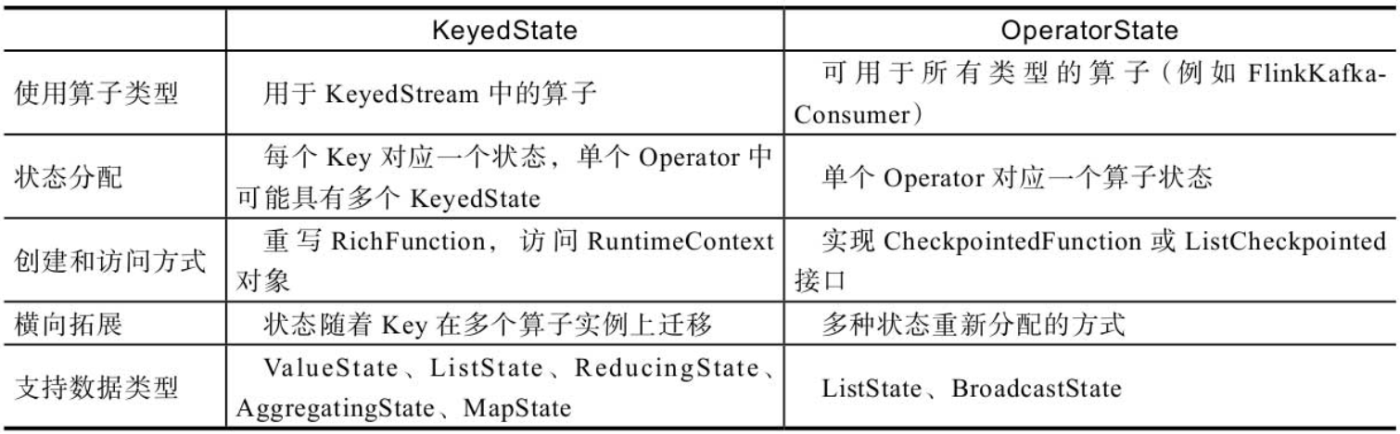
根据DataStream数据集是否基于Key进行分组,可将算子中的状态数据分为KeyedState和OperatorState两种类型。
应用位置
- KeyedState用于经过DataStream.keyby()操作后形成的KeyedStream,并按照Key对状态数据进行分区。
- OperatorState和并行的算子实例绑定,与数据元素中的Key无关。每个算子实例中都持有一部分状态数据,并支持在算子并行度发生变化时自动重新分配状态数据。
两者区别
2. 接口层面
状态数据通过统一的状态接口来表示,并根据不同的状态数据类型和使用方式区分接口实现。如下:
- MapState:用于存储分区的Key-Value类型状态数据,此类型状态支持添加、更新和获取操作。
- ValueState:用于单值类型的状态数据,并支持获取和更新状态的方法
- ReadOnlyBroadcastState:提供只读操作的BroadcastState,仅提供get()、contains()等只读方法。
2.1. UML与所有状态类型介绍
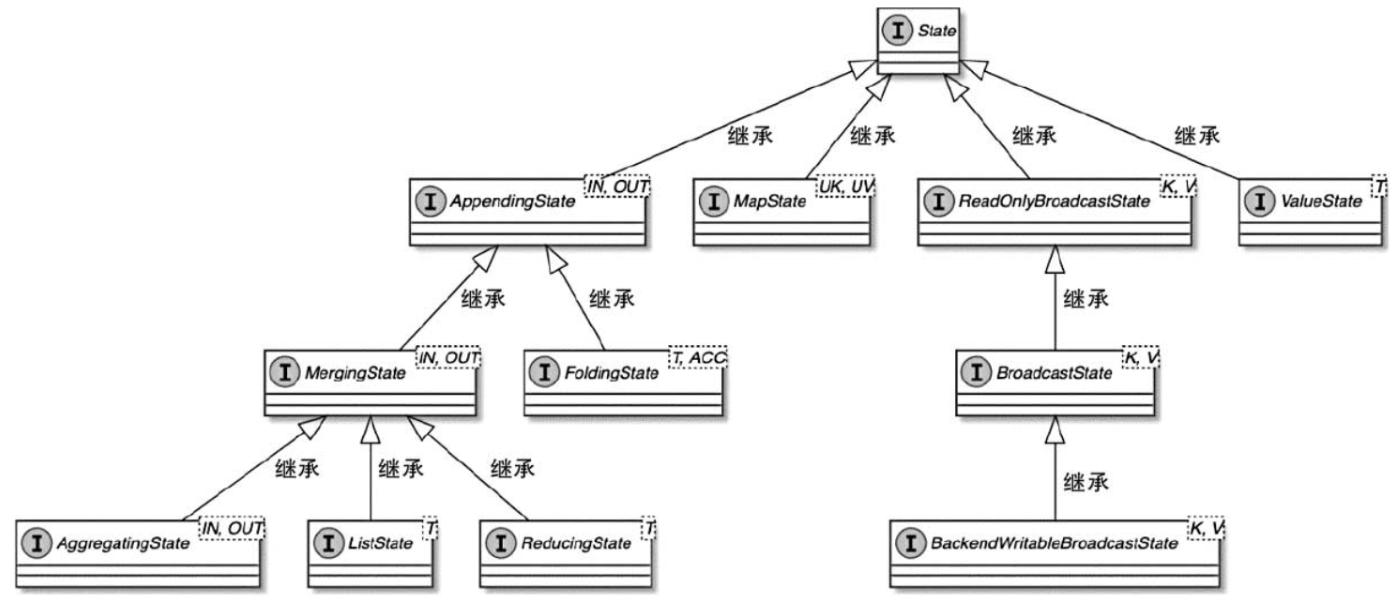
- BroadcastState:用于存储BroadcastStream中的状态数据,BroadcastState中的数据会被发送到指定算子的所有实例中,并保证每个实例中的数据都相同。
- AppendingState:支持累积操作的状态数据。写入的数据元素可以存储在类似List的Buffer数据结构中,也可以聚合成单个Value进行存储。
- MergingState:在AppendingState的基础上增加了合并状态的操作。两个MergingState实例可以合并成一个状态。
- AggregatingState:用于支持基于AggregateFunction转换的状态数据,通过状态中的AggregateFunction可以对接入的数据进行聚合计算,产生聚合状态结果。
- ListState:以数组结构类型存储状态数据,用户可通过自定义函数访问和处理状态数据。
- ReducingState:用于支持ReduceFunction操作状态,给状态添加数据元素后,通过ReduceFunction实现聚合。ReducingState只支持在KeyedStream中获取。
以上就是Flink支持的全部状态类型,不管是用户还是Flink系统内部,都基于这些状态接口实现状态数据的操作,以满足有状态计算的需求。
2.2. 内部状态:InternalKvState
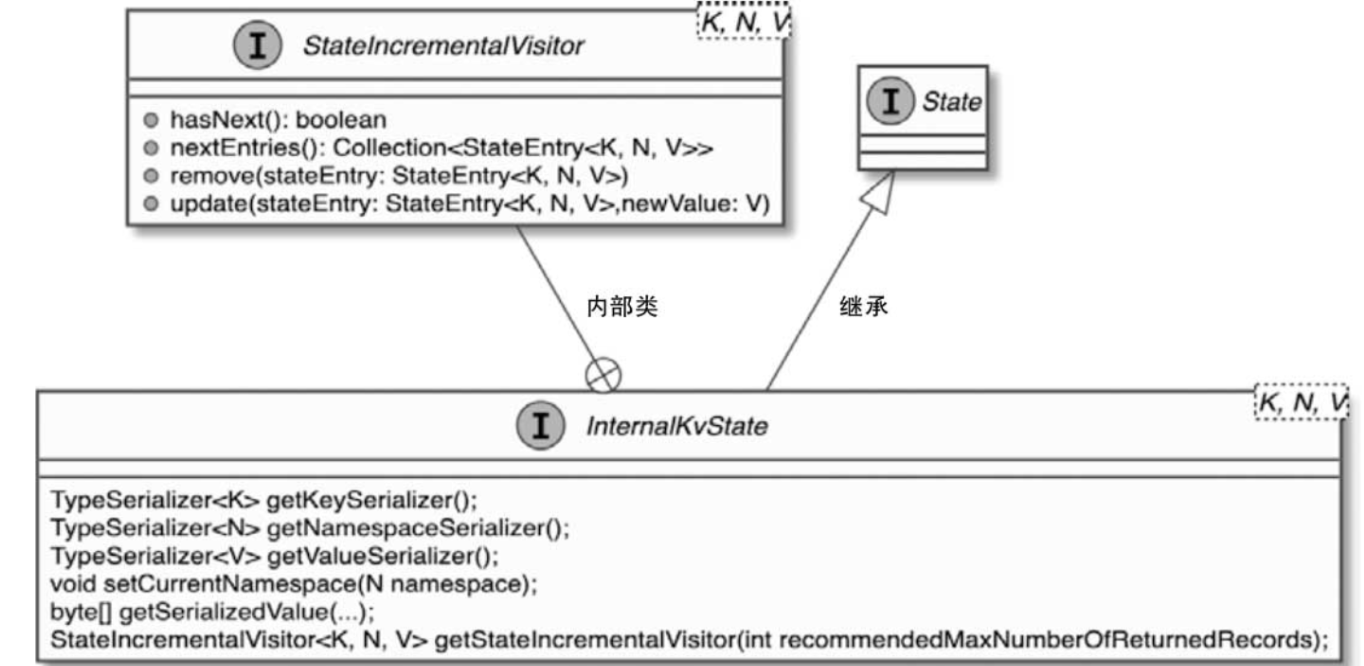
InternalKvState接口中定义的方法不对用户开放,在接口上会通过Internal进行标记,专门用于系统内部访问状态数据的辅助操作方法。一方面是为了避免引起混淆,另一方面是因为在各个发行版本中,InternalKvState接口的方法是不稳定的。
在InternalKvState接口中提供了 获取和设定命名空间、获取Raw状态和合并状态的方法,以及获取状态Key和Value等类型序列化器的方法。和状态接口作为所有状态数据的根节点相似,InternalKvState也是所有内部状态的根节点。
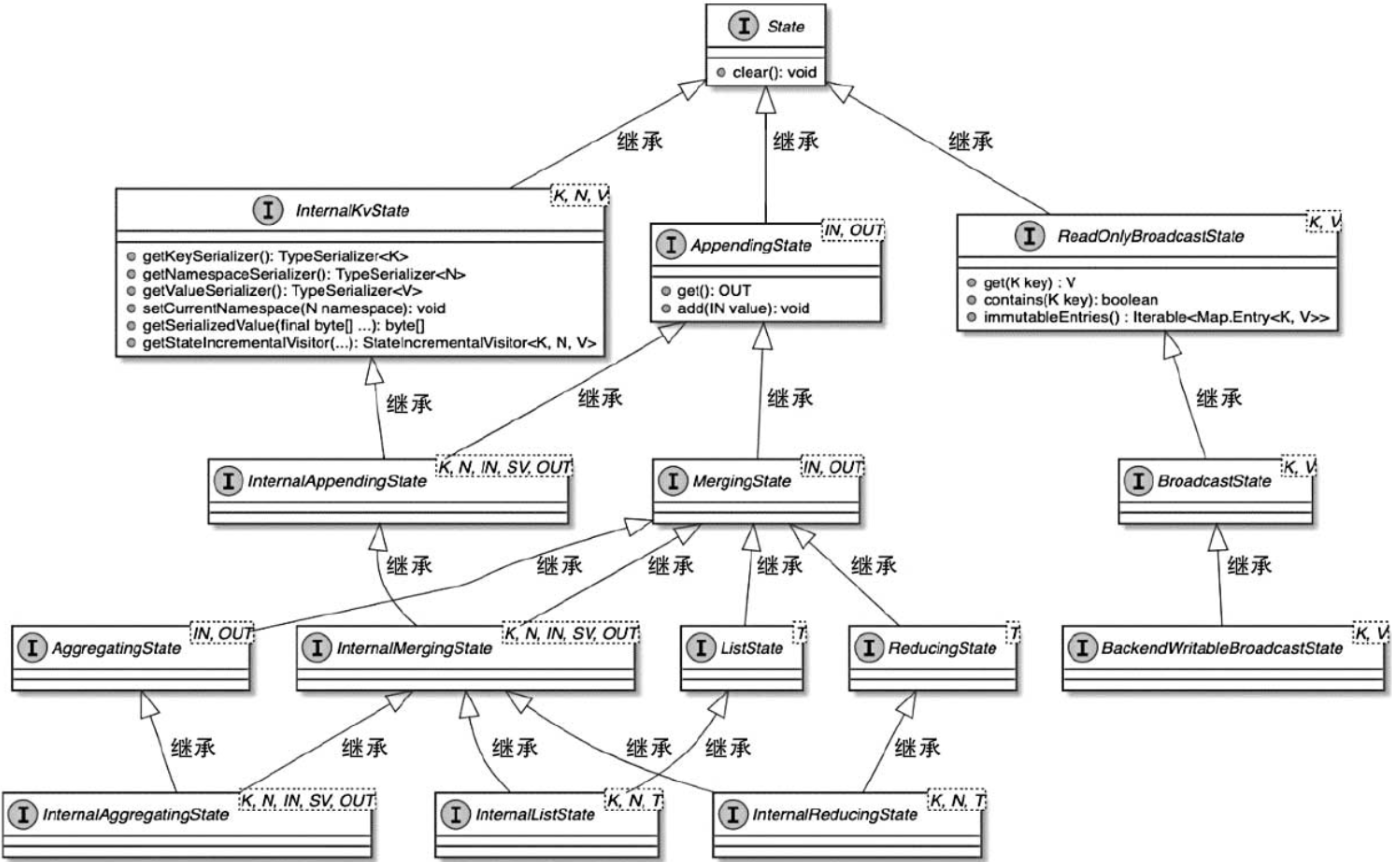
不管是基于堆内存还是RocksDB实现的状态存储后端,都同时继承和实现了InternalState接口和具体状态类型的接口。
例如
- 基于堆内存存储的状态类型有HeapAggregatingState、HeapListState及HeapReducingState等;
- 基于RocksDB存储的状态类型有RocksDBAggregatingState、RocksDBListState及RocksDBReducingState等。
参考:《Flink设计与实现:核心原理与源码解析》



















 879
879

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











