




 本文详细介绍了Spark Streaming的基本概念、内部处理机制及其应用场景。包括Spark Streaming与Structured Streaming的区别,通过实例演示如何使用Spark Streaming处理来自不同数据源的数据,如TCP套接字、文件系统及Kafka等。
本文详细介绍了Spark Streaming的基本概念、内部处理机制及其应用场景。包括Spark Streaming与Structured Streaming的区别,通过实例演示如何使用Spark Streaming处理来自不同数据源的数据,如TCP套接字、文件系统及Kafka等。
在开篇之前需要注意的是:
Spark Streaming Programming Guide | Note
Spark Streaming is the previous generation of Spark’s streaming engine. There are no longer updates to Spark Streaming and it’s a legacy project. There is a newer and easier to use streaming engine in Spark called Structured Streaming. You should use Spark Structured Streaming for your streaming applications and pipelines.
sparkStreaming目前已不在更新,Structured Streaming 作为一个新的、更易用的流引擎用来处理我们的流任务。
所以本篇的主要作用是对spark streaming的一个理解。大家可轻松阅读。
文章目录
一. SparkStreaming概述
1. 初认识
sparkStreaming是spark 核心api的一个延伸,用于流式数据的处理。数据源可以是:Kafka,Flume,文件,简单的TCP套接字等,可以使用map、reduce、join、window等高阶函数去处理数据,最后数据可以被推送到文件系统(HDFS等)、数据库,甚至是实时看板。

2. spark Streaming内部处理机制:消费者生产者模型
如下图,spark Streaming的内部处理机制是,接收实时流数据,并按照一定的时间间隔拆分成一批批数据,通过Spark Engine处理这些数据,最后得到这些数据。

生产者与消费者模型
批数据对应的是一个RDD实例,所以流数据的Dstream(continuous stream of data)可以看成是一组RDDs,一个RDD序列。通俗一点讲流数据分成一批批后,通过一个先进先出的队列,然后Spark Engine 从该队列中依次取出,然后将批数据封装成一个RDD,然后进行处理,这是一个典型的生产者消费者模型。
所以spark的流处理实际是将流数据封装为一个个RDD,然后依然通过spark Engine去处理这些数据,所以本质上Spark Streaming的计算还是由spark Core的计算引擎来实现的。
DStream:是离散流,代表了持续不断的数据流,通过上面的分析可以知道DStream中一批RDD。

二. hello SparkSteaming:从telnet计算wordcount
1. 需求
使用netcat工具向9999端口不断的发送数据,通过SparkStreaming读取端口数据并每三秒统计不同单词出现的次数
2. 实现
依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>2.1.1</version>
</dependency>
编程
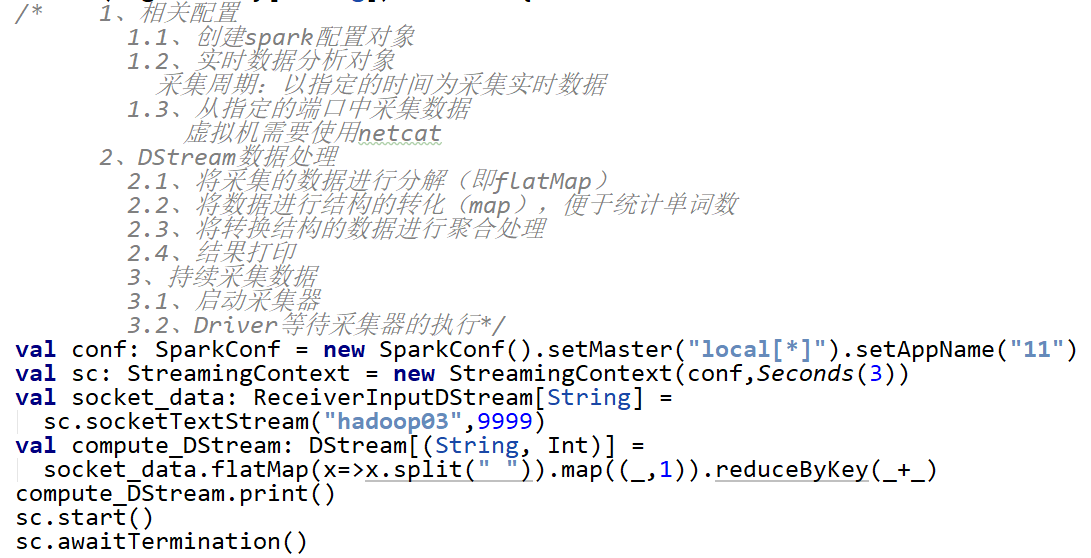
启动与结果展示
nc -lk 9999
hello atguigu
三. sparkStreaming数据源
在上节我们已经了解到了使用ssc.socketTextStream处理来自TCP socket的数据。接下来我们完整的看一下spark streaming支持的数据源。
1. File Streams ing
支持的文件系统:sparkStreaming能够读取所有HDFS API兼容的文件系统文件
读取:a DStream can be created as viaStreamingContext.fileStream[KeyClass, ValueClass, InputFormatClass].
监控:Spark Streaming 将会监控 dataDirectory 目录并不断处理移动进来的文件,目前不支持嵌套目录。
注意:文件夹中的文件对应的数据都是相同格式的;监控到的方式:移动文件或重命名;不可修改:一旦进入目录则不允许修改,修改也不会读取
ing
2. 自定义数据源
package com.aura.bigdata.SparkStreaming
import java.io.{BufferedReader, InputStream, InputStreamReader}
import java.net.Socket
import org.apache.spark.SparkConf
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.receiver.Receiver
import org.apache.spark.streaming.{Seconds, StreamingContext}
//wordcount
object SparkStreaming03_ReadfromReceiver{
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("11")
val streamingContext = new StreamingContext(sparkConf,Seconds(3))
val rDS: ReceiverInputDStream[String] = streamingContext.receiverStream(new MyReceiver("hadoop03",9999))
val wordDStream: DStream[String] = rDS.flatMap(line=>line.split(" "))
val mapDStream: DStream[(String, Int)] = wordDStream.map((_,1))
val wordToSumDStream: DStream[(String, Int)] = mapDStream.reduceByKey(_+_)
wordToSumDStream.print()
//因为数据是不断发送的所以streamingContext采集程序不能停止
//streamingContext.stop()
streamingContext.start()
streamingContext.awaitTermination()
}
}
//自定义socket数据流规则:当输入END字符时,socket关闭连接。
//1)继承Receiver
class MyReceiver(host:String,port:Int) extends Receiver[String](StorageLevel.MEMORY_ONLY){
var socket:Socket=null;
def receive():Unit={
//创建sokect进行网络通讯(从虚拟机上)
socket= new Socket(host,port)
val reader = new BufferedReader(new InputStreamReader(socket.getInputStream,"utf-8"))
var line:String=null
while((line=reader.readLine())!=null){
//将采集到的数据
//1、以“END”作为停止采集的标志
if ("END".equals(line)){
return
}else{
//2、储存数据
this.store(line)
}
}
}
//启动线程(持续)实现数据的接收
override def onStart(): Unit ={
new Thread(new Runnable {
override def run(): Unit = {
receive()
}
}).start()
}
override def onStop(): Unit = {
if(socket!=null){
socket.close()
socket=null
}
}
}
3. kafka数据源
需求:
通过SparkStreaming从Kafka读取数据,并将读取过来的数据做简单计算(WordCount),最终打印到控制台。
实现
依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-8_2.11</artifactId>
<version>2.1.1</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>0.11.0.2</version>
</dependency>
程序
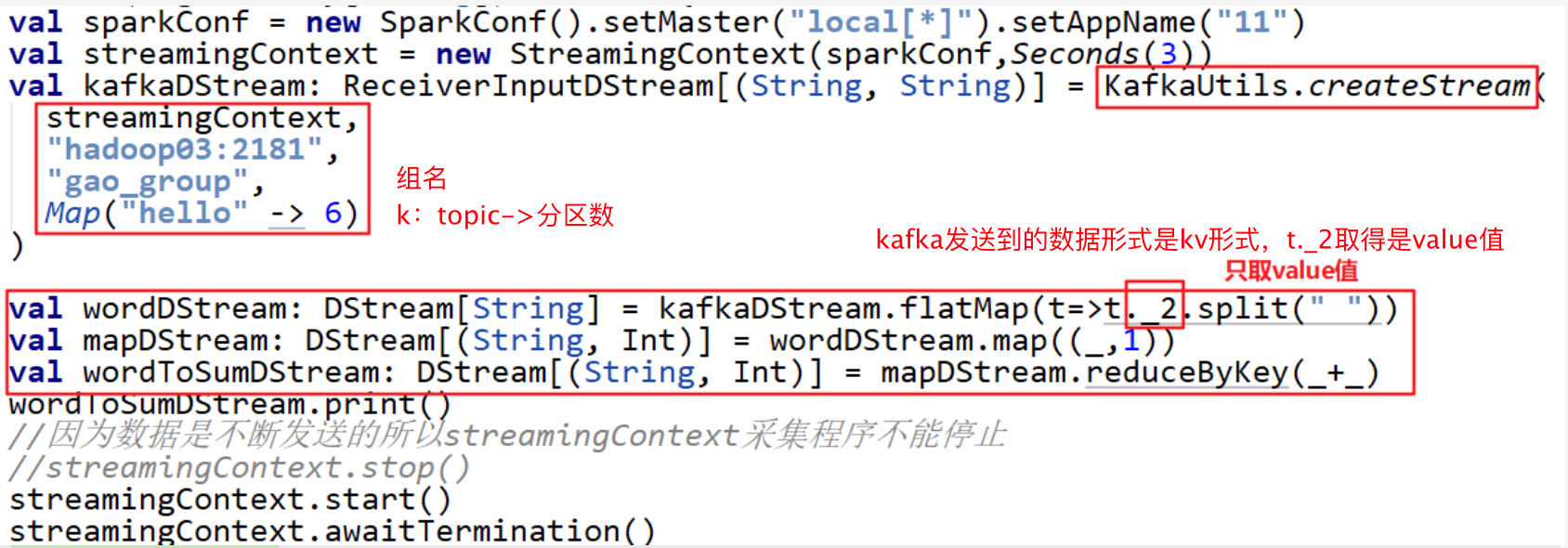
四. Transformations on DStreams
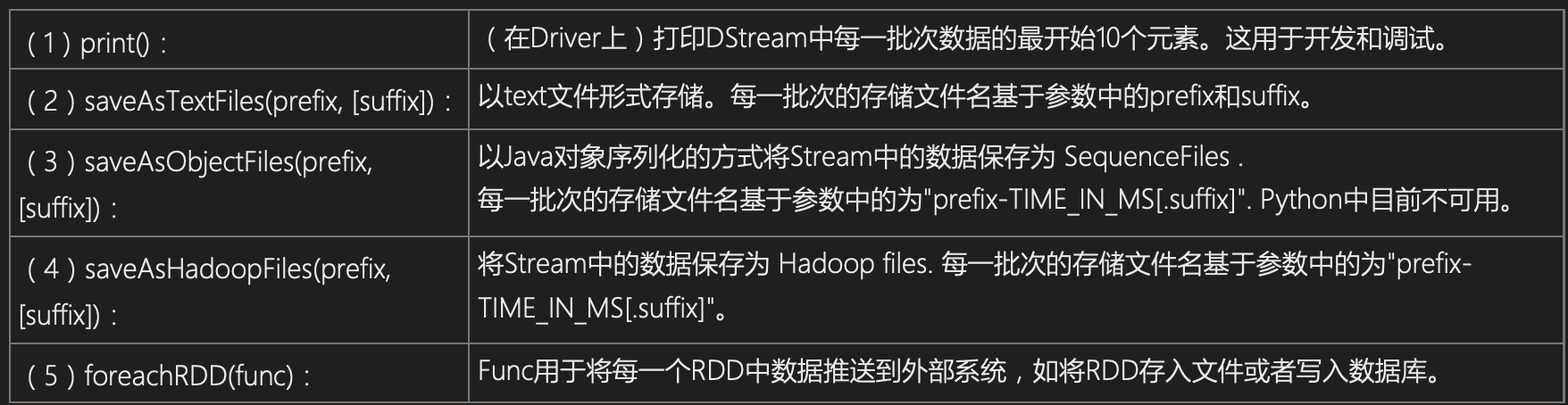
1. 常用的算子
DStreams support many of the transformations available on normal Spark RDD’s.
| 算子 | 解释 |
|---|---|
| map(func) | 一个输入一个输出 |
| flatMap(func) | 一个输入多个输出 |
| filter(func) | 根据func保留返回为ture的数据 |
| repartition(numPartitions) | 重新生成指定分区数的DStream |
| union(otherStream) | 和另外一个DStream组成一个新的DStream |
| count() | 记录元素数量 |
| reduce(func) | 聚合 |
| countByValue() | 计算source中每个key出现的频率 |
| reduceByKey(func, [numTasks]) | 根据func规则去聚合source数据 |
| join(otherStream, [numTasks]) | When called on two DStreams of (K, V) and (K, W) pairs, return a new DStream of (K, (V, W)) pairs with all pairs of elements for each key. |
| cogroup(otherStream, [numTasks]) | When called on a DStream of (K, V) and (K, W) pairs, return a new DStream of (K, Seq[V], Seq[W]) tuples. |
| updateStateByKey(func) | 返回一个新的“状态”DStream,其中每个键的状态通过在键的前一个状态和键的新值上通过func规则来更新。这可用于维护每个键的任意状态数据。 |
2. UpdateStateByKey Operation:有状态跨批次数据累加
功能:此函数用于实现跨批次结果的累加,它记录了历史状态,并提供了对状态变量的访问。
使用
状态的更新,需要做两步
• 定义状态:可以是一个任意的数据类型
• 定义状态更新函数:状态值与输入流的更新操作需要配置检查点目录,会使用检查点来保存状态
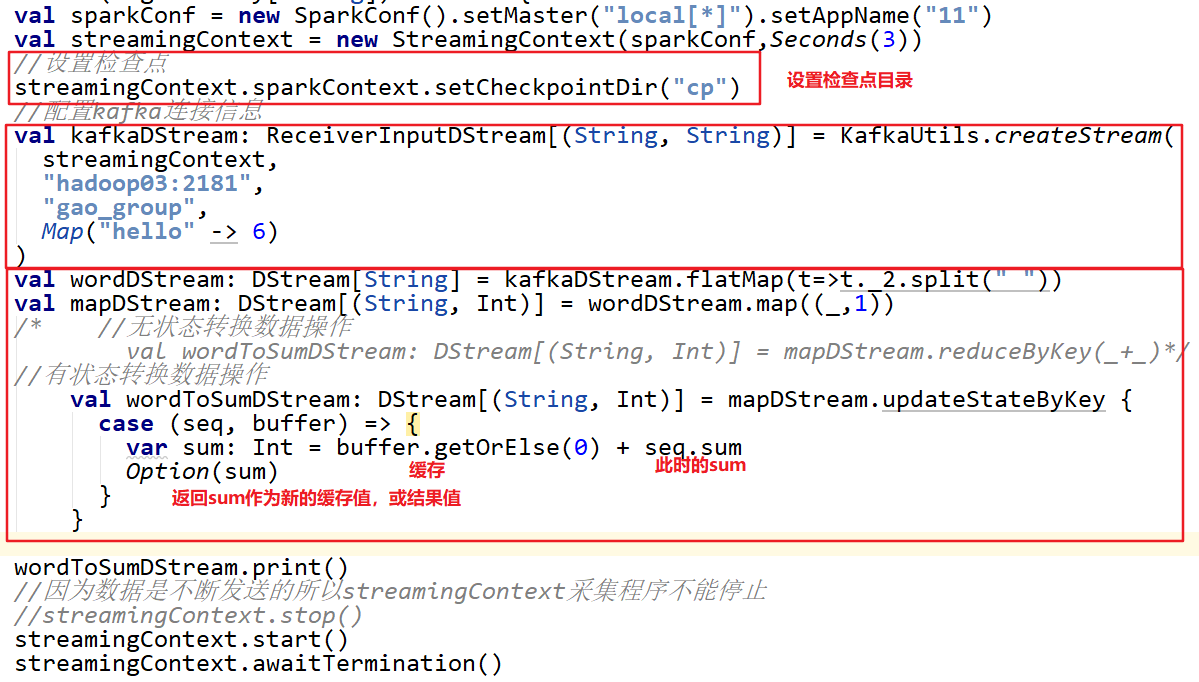
updateFunc方法逻辑:
• Seq[int]:map(_,1)中的1,去形成序列(1,1,1,1…)
• Option[S]:代表的是缓冲区的数据(可能为null)
• 更新函数:seq+缓冲区的数据做交互,返回一个新的Option更新到缓冲区(最新的聚合数据)
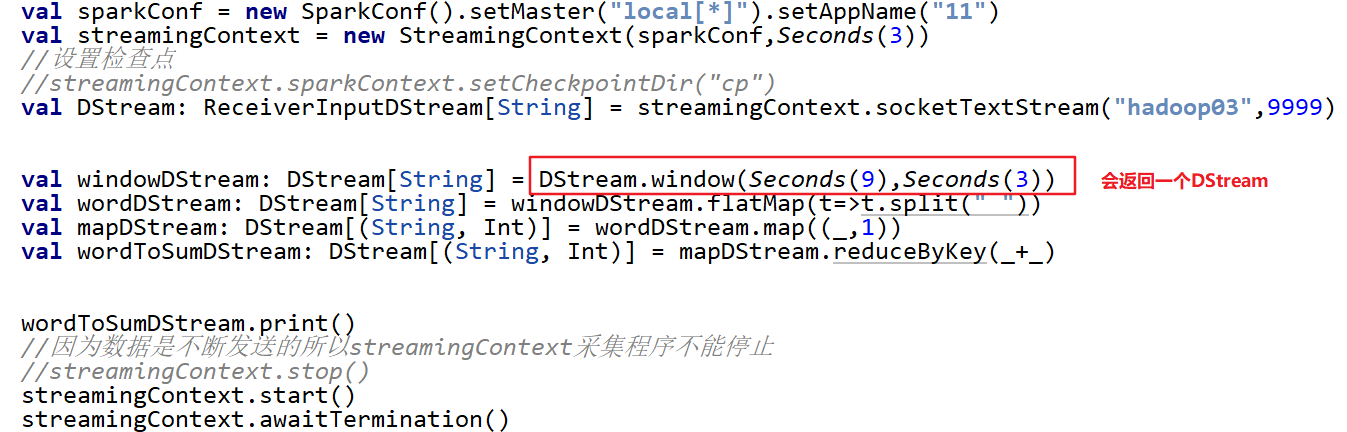
3. window函数
一个窗口内会处理更多批次的结果
窗口需要两个参数:窗口时长+滑动步长,注意两个参数都是批次间隔的整数倍。
4. join ing


















 1074
1074

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











