




第 5 天 字符串
剑指 Offer II 014. 字符串中的变位词
给定两个字符串 s1 和 s2,写一个函数来判断 s2 是否包含 s1 的某个变位词。
换句话说,第一个字符串的排列之一是第二个字符串的 子串 。
示例 1:
输入: s1 = “ab” s2 = “eidbaooo”
输出: True
解释: s2 包含 s1 的排列之一 (“ba”).
示例 2:
输入: s1= “ab” s2 = “eidboaoo”
输出: False
提示:
1 <= s1.length, s2.length <= 104
s1 和 s2 仅包含小写字母
来源:力扣(LeetCode)
链接:https://leetcode.cn/problems/MPnaiL
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
原本我还想着使用一个 vector<vector> array 作为前缀和呢,每一个 vector 保存的是到目前为止出现的字母的个数,vector 第 i 个位置的 int 值表示第 i 个字母出现的次数
但是想想要映射到哈希表我也不知道怎么将 26 个 int 映射成一个地址……
于是我本来想连续查找的
class Solution {
public:
bool checkInclusion(string s1, string s2) {
vector<int> target_count(26, 0), tmp_count(26, 0);
int sum_count = s1.size(), tmp_sum_count = 0;
for (char cha : s1) {
++target_count[cha - 'a'];
}
// 初始化变量
tmp_count = target_count;
tmp_sum_count = sum_count;
for (char cha : s2) {
if (tmp_count[cha - 'a'] > 0) {
--tmp_count[cha - 'a'];
--tmp_sum_count;
if (tmp_sum_count == 0) return true;
}
// 查找连续字符串失败,恢复变量
else {
tmp_count = target_count;
tmp_sum_count = sum_count;
}
}
return false;
}
};
但是遇到了连续查找的问题
输入:
"adc"
"dcda"
输出:
false
预期结果:
true
就,我一开始找 dc 的时候都是正确的,但是之后又遇到了 d,这个时候我会归为连续中断的类型,因为 target 中没有足够的字符可以取了
从这种情况来看,我应该记录第一次找到的字符的位置,并且在连续中断的时候看看是不是我第一个找到的字符,如果是第一个的话就可以撤掉第一个
class Solution {
public:
bool checkInclusion(string s1, string s2) {
vector<int> target_count(26, 0), tmp_count(26, 0);
int sum_count = s1.size(), tmp_sum_count = 0, first_char_idx = -1;
for (char cha : s1) {
++target_count[cha - 'a'];
}
// 初始化变量
tmp_count = target_count;
tmp_sum_count = sum_count;
for (int i = 0; i < s2.size(); ++i) {
if (tmp_count[s2[i] - 'a'] > 0) {
// 如果是第一次找到的字符
if (tmp_sum_count == s1.size()) {
first_char_idx = i;
}
--tmp_count[s2[i] - 'a'];
--tmp_sum_count;
if (tmp_sum_count == 0) return true;
}
// 查找连续字符串失败
else {
// 如果即将连续中断的时候,发现中断的位置的字符与第一个字符相同,那么去掉第一个字符,使得中断的位置可以被接上
if (first_char_idx >= 0 && s2[first_char_idx] == s2[i]) {
++first_char_idx;
continue;
}
// 恢复变量
first_char_idx = -1;
tmp_count = target_count;
tmp_sum_count = sum_count;
}
}
return false;
}
};
后面我觉得可能是因为我某一次查找失败了之后,还要再原地再开始查找
class Solution {
public:
bool checkInclusion(string s1, string s2) {
vector<int> target_count(26, 0), tmp_count(26, 0);
int sum_count = s1.size(), tmp_sum_count = 0, first_char_idx = -1;
for (char cha : s1) {
++target_count[cha - 'a'];
}
// 初始化变量
tmp_count = target_count;
tmp_sum_count = sum_count;
for (int i = 0; i < s2.size(); ++i) {
if (tmp_count[s2[i] - 'a'] > 0) {
// 如果是第一次找到的字符
if (tmp_sum_count == s1.size()) {
first_char_idx = i;
}
--tmp_count[s2[i] - 'a'];
--tmp_sum_count;
if (tmp_sum_count == 0) return true;
}
// 查找连续字符串失败
else {
// 如果即将连续中断的时候,发现中断的位置的字符与第一个字符相同,那么去掉第一个字符,使得中断的位置可以被接上
if (first_char_idx >= 0 && s2[first_char_idx] == s2[i]) {
++first_char_idx;
continue;
}
// 如果是第一次查找失败,那么再在这个位置原地开始
if (first_char_idx != -1) {
first_char_idx = -1;
tmp_count = target_count;
tmp_sum_count = sum_count;
--i;
continue;
}
}
}
return false;
}
};
但是还是在复杂测试用例上出错了
最终还是用了滑动窗口
class Solution {
public:
bool checkInclusion(string s1, string s2) {
vector<int> target_count(26, 0);
int len1 = s1.size();
for (char cha : s1) {
++target_count[cha - 'a'];
}
for (int i = 0; i < s2.size(); ++i) {
--target_count[s2[i] - 'a'];
if(i >= len1)
++target_count[s2[i - len1] - 'a'];
bool nz = false;
for (int num : target_count) {
if (num != 0) {
nz = true;
break;
}
}
if (nz == false) return true;
}
return false;
}
};
执行用时:4 ms, 在所有 C++ 提交中击败了95.66% 的用户
内存消耗:7 MB, 在所有 C++ 提交中击败了82.23% 的用户
傻瓜式判断,如果当前的 target 数组都为 0,说明这个滑动窗口的所有字母及其出现次数跟目标串都是一样的
之后或许还能再判空这方面优化……我懒得写了hhh
官方题解的思路是,一开始就维护两个字母出现次数的数组,目标串一个,滑动窗口一个
之后优化为 diff,两个数组之差,这样只用维护一个,这就跟我一开始想的是一样的
剑指 Offer II 015. 字符串中的所有变位词
与上一题一样,就是参数稍微改了一下
class Solution {
public:
vector<int> findAnagrams(string s, string p) {
vector<int> ans;
vector<int> target_count(26, 0);
int window_size = p.size();
for (char cha : p) {
++target_count[cha - 'a'];
}
for (int i = 0; i < s.size(); ++i) {
--target_count[s[i] - 'a'];
if(i >= window_size)
++target_count[s[i - window_size] - 'a'];
bool nz = false;
for (int num : target_count) {
if (num != 0) {
nz = true;
break;
}
}
if (nz == false){
ans.push_back(i - window_size + 1);
}
}
return ans;
}
};
剑指 Offer II 016. 不含重复字符的最长子字符串
给定一个字符串 s ,请你找出其中不含有重复字符的 最长连续子字符串 的长度。
示例 1:
输入: s = “abcabcbb”
输出: 3
解释: 因为无重复字符的最长子字符串是 “abc”,所以其长度为 3。
示例 2:
输入: s = “bbbbb”
输出: 1
解释: 因为无重复字符的最长子字符串是 “b”,所以其长度为 1。
示例 3:
输入: s = “pwwkew”
输出: 3
解释: 因为无重复字符的最长子串是 “wke”,所以其长度为 3。
请注意,你的答案必须是 子串 的长度,“pwke” 是一个子序列,不是子串。
示例 4:
输入: s = “”
输出: 0
提示:
0 <= s.length <= 5 * 104
s 由英文字母、数字、符号和空格组成
来源:力扣(LeetCode)
链接:https://leetcode.cn/problems/wtcaE1
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
本来想套之前的滑动窗口,后面想想还是双指针比较好
主要是因为在右指针找到重复的字符之后,左指针需要移动到右指针指向的元素相同的元素的下一位
比如 a b c d e b
一开始
a b c d e b
p2 p1
然后 p1 移动
a b c d e b
p2 p1
这个时候 p2 应该一直移动到 c
a b c d e b
p2 p1
也就是移动到 p1 指向的元素 b 相同的元素的下一位
一开始我还想用一个 int 来存是否出现过呢,后来看是我想多了
class Solution {
public:
int lengthOfLongestSubstring(string s) {
if(s.size() == 0) return 0;
if(s.size() == 1) return 1;
int p1 = 0, p2 = 0;
int flag = 0;
int ans = 1;
flag |= (1 << (s[0] - 'a'));
for(p1 = 1; p1 < s.size(); ++p1){
// 如果没出现过
if(((flag >> (s[p1] - 'a')) & 1) == 0){
flag |= (1 << (s[p1] - 'a'));
ans = max(ans, p1 - p2 + 1);
}
// 如果出现过
else{
while(s[p2] != s[p1]){
flag &= ~(1 << (s[p2] - 'a'));
++p2;
}
++p2;
}
}
return ans;
}
};
后来老老实实用哈希了
class Solution {
public:
int lengthOfLongestSubstring(string s) {
if(s.size() == 0) return 0;
if(s.size() == 1) return 1;
int p1 = 0, p2 = 0;
int flag = 0;
int ans = 1;
unordered_set<char> cha_set;
cha_set.insert(s[0]);
for(p1 = 1; p1 < s.size(); ++p1){
// 如果没出现过
if(cha_set.find(s[p1]) == cha_set.end()){
cha_set.insert(s[p1]);
ans = max(ans, p1 - p2 + 1);
}
// 如果出现过
else{
while(s[p2] != s[p1]){
cha_set.erase(s[p2]);
++p2;
}
++p2;
}
}
return ans;
}
};
第 6 天 字符串
剑指 Offer II 017. 含有所有字符的最短字符串
给定两个字符串 s 和 t 。返回 s 中包含 t 的所有字符的最短子字符串。如果 s 中不存在符合条件的子字符串,则返回空字符串 “” 。
如果 s 中存在多个符合条件的子字符串,返回任意一个。
注意: 对于 t 中重复字符,我们寻找的子字符串中该字符数量必须不少于 t 中该字符数量。
示例 1:
输入:s = “ADOBECODEBANC”, t = “ABC”
输出:“BANC”
解释:最短子字符串 “BANC” 包含了字符串 t 的所有字符 ‘A’、‘B’、‘C’
示例 2:
输入:s = “a”, t = “a”
输出:“a”
示例 3:
输入:s = “a”, t = “aa”
输出:“”
解释:t 中两个字符 ‘a’ 均应包含在 s 的子串中,因此没有符合条件的子字符串,返回空字符串。
提示:
1 <= s.length, t.length <= 105
s 和 t 由英文字母组成
来源:力扣(LeetCode)
链接:https://leetcode.cn/problems/M1oyTv
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
一开始我也是想的滑动窗口啊,很经典
但是我似乎没有办法协调好这两个指针
class Solution {
public:
string minWindow(string s, string t) {
int p1 = 0, p2 = 0;
int nz_count = 0;
unordered_map<int, int> t_map;
int ans_len = INT_MAX;
string ans;
for(char cha : t){
t_map[cha]++;
}
nz_count = t_map.size();
while(p2 < s.size()){
while(p1 <= p2 && p2 < s.size()){
if(t_map.find(s[p2]) != t_map.end()){
// 可能减到负数
t_map[s[p2]]--;
// 刚好减到 0 才判断
if(t_map[s[p2]] == 0){
nz_count--;
if(nz_count == 0){
if(p2 - p1 + 1 < ans_len){
ans_len = p2 - p1 + 1;
ans = s.substr(p1, ans_len);
}
break;
}
}
}
p2++;
}
bool flag = false;
while(p1 <= p2 && p2 < s.size()){
if(t_map.find(s[p1]) != t_map.end()){
if(flag == true) break;
// 可能从负数开始增加
t_map[s[p2]]++;
// 刚好增到 1 才判断
if(t_map[s[p2]] == 1){
flag = true;
}
}
p1++;
}
}
return ans;
}
};
再改了一下,我感觉是逻辑更清晰了,还是不对
class Solution {
public:
string minWindow(string s, string t) {
int p1 = 0, p2 = 0;
int nz_count = 0;
unordered_map<int, int> t_map;
bool first_char_matched = false;
int ans_len = INT_MAX;
string ans;
for (char cha : t) {
t_map[cha]++;
}
nz_count = t_map.size();
while (p1 <= p2 && p2 < s.size()) {
while (p1 <= p2 && p2 < s.size()) {
if (t_map.find(s[p2]) != t_map.end()) {
// 可能减到负数
t_map[s[p2]]--;
// 把 p1 移动到第一个匹配的字符上
if (!first_char_matched) {
first_char_matched = true;
p1 = p2;
}
// 刚好减到 0 才判断
if (t_map[s[p2]] == 0) {
nz_count--;
if (nz_count == 0) {
if (p2 - p1 + 1 < ans_len) {
ans_len = p2 - p1 + 1;
ans = s.substr(p1, ans_len);
}
p2++;
break;
}
}
}
p2++;
}
t_map[s[p1]]++;
if (t_map[s[p1]] == 1) nz_count++;
p1++;
while (p1 <= p2 && p2 < s.size()) {
if (t_map.find(s[p1]) == t_map.end()) {
p1++;
}
else {
break;
}
}
}
return ans;
}
};
思考了一下我的思路……感觉确实不太对
A D O B E C O D E B A N C
p1 p2
A D O B E C O D E B A N C
p1 p2
A D O B E C O D E B A N C
p1 p2
A D O B E C O D E B A N C
p1 p2
A D O B E C O D E B A N C
p1 p2
A D O B E C O D E B A N C
p1 p2
A D O B E C O D E B A N C
p1 p2
主要还是用两个 while 来控制两边确实会比较难
看了题解之后才发现别人的思路确实清晰,我的思路都是乱的
class Solution {
public:
// ori 记录 t 中每一个字符出现的次数
// cnt 记录滑动窗口中与 t 中字符相同的字符出现的次数
unordered_map <char, int> ori, cnt;
bool check() {
for (const auto &p: ori) {
if (cnt[p.first] < p.second) {
return false;
}
}
return true;
}
string minWindow(string s, string t) {
for (const auto &c: t) {
++ori[c];
}
int l = 0, r = -1;
int len = INT_MAX, ansL = -1, ansR = -1;
// r 每走一步,l 就紧跟着尝试收缩
// 对 size_t 转为 int,可以防止 r 作为 int 被转为 size_t
while (r < int(s.size())) {
if (ori.find(s[++r]) != ori.end()) {
++cnt[s[r]];
}
// 在滑动窗口满足条件的情况下,收缩滑动窗口
while (check() && l <= r) {
if (r - l + 1 < len) {
len = r - l + 1;
ansL = l;
}
// 收缩的时候更新哈希表
if (ori.find(s[l]) != ori.end()) {
--cnt[s[l]];
}
++l;
}
}
return ansL == -1 ? string() : s.substr(ansL, len);
}
};
类似的也可以写成
class Solution {
public:
unordered_map<int, int> t_map;
bool check() {
for (const auto &p: t_map) {
if (p.second > 0) {
return false;
}
}
return true;
}
string minWindow(string s, string t) {
for (const auto &c: t) {
++t_map[c];
}
int l = 0, r = -1;
int len = INT_MAX, ansL = -1;
// r 每走一步,l 就紧跟着尝试收缩
// 对 size_t 转为 int,可以防止 r 作为 int 被转为 size_t
while (r < int(s.size())) {
if (t_map.find(s[++r]) != t_map.end()) {
--t_map[s[r]];
}
// 在滑动窗口满足条件的情况下,收缩滑动窗口
while (check() && l <= r) {
if (r - l + 1 < len) {
len = r - l + 1;
ansL = l; // 记录最小长度时的 l
}
// 收缩的时候更新哈希表
if (t_map.find(s[l]) != t_map.end()) {
++t_map[s[l]];
}
++l;
}
}
return len == INT_MAX ? string() : s.substr(ansL, len);
}
};
写的太痛苦了……主要还是我写题习惯的问题把
上来就用两个 while 控制 l 和 r 主要因为我想到快排也是这么控制的,但是我没有预估到我的能力是这样的……
其实这样
while 在 r 不越界的情况下
r 每走一步,l 就紧跟着尝试收缩
while 在滑动窗口满足条件的情况下
收缩滑动窗口,取最小长度,记录最小长度时的边界
收缩的时候更新哈希表
这种方法就很好……就是,明显很清晰
而且在更新哈希表的时候,滑动窗口可能变成不满足条件了的,就终止 while 了,这就是,嗯,如果按照这个思路写,就会自然而然地想出来的
或者这只是我的马后炮……
剑指 Offer II 018. 有效的回文
class Solution {
private:
bool isSameChar(const char a, const char b) {
if (isalpha(a) && isalpha(b)) {
if ((tolower(a) - 'a') == (tolower(b) - 'a')) return true;
}
else if (isdigit(a) && isdigit(b)) {
if ((a - '0') == (b - '0')) return true;
}
return false;
}
public:
bool isPalindrome(string s) {
string s_only_alpha_and_digit;
for (char& cha : s) {
if (isalpha(cha) || isdigit(cha)) {
s_only_alpha_and_digit.append(1, cha);
}
}
int len = s_only_alpha_and_digit.size();
for (int i = 0; i < len / 2; ++i) {
if (!isSameChar(s_only_alpha_and_digit[i], s_only_alpha_and_digit[len - i - 1])) return false;
}
return true;
}
};
剑指 Offer II 019. 最多删除一个字符得到回文
class Solution {
public:
bool validPalindrome(string s) {
int len = s.size();
int p1 = 0, p2 = len - 1;
while(p1 < p2 && s[p1] == s[p2]){
p1++;
p2--;
}
// 如果不用删除就能得到回文
if(p1 >= p2) return true;
int p3 = p1, p4 = p2;
// 尝试删除右边
p4 = p2 - 1;
while(p3 < p4 && s[p3] == s[p4]){
p3++;
p4--;
}
if(p3 >= p4) return true;
// 尝试删除左边
p3 = p1 + 1;
p4 = p2;
while(p3 < p4 && s[p3] == s[p4]){
p3++;
p4--;
}
if(p3 >= p4) return true;
return false;
}
};
剑指 Offer II 020. 回文子字符串的个数
class Solution {
private:
string str;
bool isSymmetric(int l, int r){
while(l < r && str[l] == str[r]){
l++;
r--;
}
if(l >= r) return true;
else return false;
}
public:
int countSubstrings(string s) {
str = s;
int ans = 0;
for(int i = 0; i < s.size(); ++i){
for(int j = i; j < s.size(); ++j){
if(isSymmetric(i, j)) ans++;
}
}
return ans;
}
};
中心拓展
计算有多少个回文子串的最朴素方法就是枚举出所有的回文子串,而枚举出所有的回文子串又有两种思路,分别是:
枚举出所有的子串,然后再判断这些子串是否是回文;
枚举每一个可能的回文中心,然后用两个指针分别向左右两边拓展,当两个指针指向的元素相同的时候就拓展,否则停止拓展。
我一开始写的中心拓展
class Solution {
public:
int countSubstrings(string s) {
int l = 0, r = 0;
int ans = 0;
for(int i = 0; i < s.size(); ++i){
l = r = i;
ans++;
if(l - 1 >= 0 && r + 1 < s.size() && s[l - 1] == s[r + 1]){
l--;
r++;
ans++;
}
}
return ans;
}
};
但是这个方法会少判定一些回文串
a a a
a
a
a
a a
a a
a a a
其中
a a
a a
的回文串没有判断到
这些回文串的特点是,中心在 i + 0.5 的位置
一开始我还在想,这些回文串应该归类到哪个整数的位置上……我这样的想法就复杂了
所以就是扫两遍就行了,第一遍是以整数序号为中心,第二遍是以半整数序号为中心
class Solution {
public:
int countSubstrings(string s) {
int l = 0, r = 0;
int ans = 0;
for(int i = 0; i < s.size(); ++i){
l = r = i;
while(l >= 0 && r < s.size() && s[l] == s[r]){
l--;
r++;
ans++;
}
}
for(int i = 0; i < s.size() - 1; ++i){
l = i;
r = i + 1;
while(l >= 0 && r < s.size() && s[l] == s[r]){
l--;
r++;
ans++;
}
}
return ans;
}
};
线性规划
假设 dp[i][j] 表示 s 的序号 i 到 j 为回文串
那么更新思路就是加一些字符上去
两边各加一个
dp[i-1][j+1] = dp[i][j] && (s[i] == s[j])
第一时间只能想到这样更新了,那其实,经历过中心拓展的坑,这里也有类似的非整数坐标中心的坑
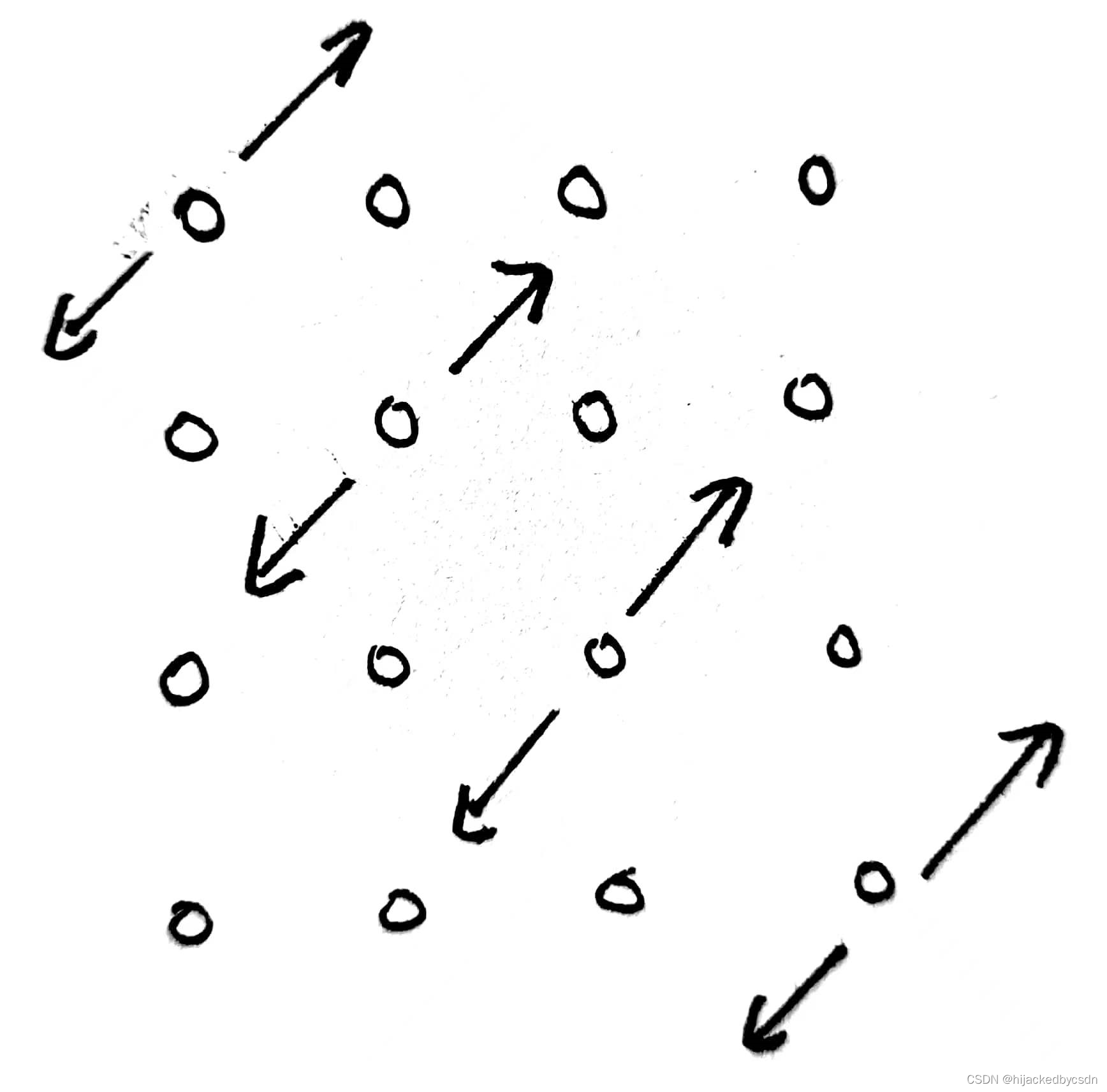
所以其实 dp 的更新与中心拓展的坑的解决方法都是一样的
第 7 天 链表
剑指 Offer II 021. 删除链表的倒数第 n 个结点
很常见的双指针,一开始的时候一个指针先动,另一个指针不动,等到先动的指针移动了 n 步之后,两个指针再同步移动,很经典
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* removeNthFromEnd(ListNode* head, int n) {
ListNode* p1 = head, *p2 = head, *prev = head;
// 找到要删除的节点 p1
for(int i = 0; i < n; ++i){
if(p2 != nullptr) p2 = p2->next;
}
while(p2 != nullptr){
prev = p1;
p1 = p1->next;
p2 = p2->next;
}
// 删除 p1
// 如果要删除的节点是头节点
if(p1 == head){
prev = p1->next;
p1->next = nullptr;
//free(p1);
return prev;
}
// 如果要删除的节点是尾结点或中间节点
prev->next = p1->next;
//free(p1);
return head;
}
};
剑指 Offer II 022. 链表中环的入口节点
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
ListNode *detectCycle(ListNode *head) {
ListNode *p1 = head, *p2 = head;
if(head == nullptr) return nullptr;
for(int i = 0; i < 2; ++i){
if(p2->next == nullptr) return nullptr;
else p2 = p2->next;
}
while(p1 != p2){
if(p2->next == nullptr || p2->next->next == nullptr) return nullptr;
p1 = p1->next;
p2 = p2->next->next;
}
return p1;
}
};
经典快慢指针
但是我都不知道为什么我会在这里错
输入:
[-21,10,17,8,4,26,5,35,33,-7,-16,27,-12,6,29,-12,5,9,20,14,14,2,13,-24,21,23,-21,5]
24
输出:
tail connects to node index 26
预期结果:
tail connects to node index 24
感觉应该是哪里写错了
重写了一遍,结果发现是,快慢指针相遇的地方,不一定是环连接的地方
比如有的情况下,快慢指针相遇的地方确实是环连接的地方,比如我上面那个例子
class Solution {
public:
ListNode* detectCycle(ListNode* head) {
ListNode* p1 = head, * p2 = head;
if (head == nullptr) return nullptr;
do {
if (p2->next == nullptr || p2->next->next == nullptr) return nullptr;
p1 = p1->next;
p2 = p2->next->next;
} while (p1 != p2);
return p1;
}
};
但是有的情况下,快慢指针相遇的地方的上一位才是环连接的地方,所以还要记录上一个位置
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
ListNode* detectCycle(ListNode* head) {
ListNode* p1 = head, * p2 = head, * prev = head;
if (head == nullptr) return nullptr;
do {
if (p2->next == nullptr || p2->next->next == nullptr) return nullptr;
prev = p1;
p1 = p1->next;
p2 = p2->next->next;
} while (p1 != p2);
return prev;
}
};
例如
环从尾部连接到序号 1
n0 n1 n2
p1p2
n0 n1 n2
p1 p2
n0 n1 n2
p1p2
还有的情况下快慢指针相遇的地方在环连接的地方之后两个 next
例如
环从尾部连接到序号 1
n0 n1 n2 n3
p1p2
n0 n1 n2 n3
p1 p2
n0 n1 n2 n3
p2 p1
n0 n1 n2 n3
p1p2
这就给我整蒙了
之后看题解才知道这里还有一个数学关系

首先其实要知道的是,在环中,假设以入环点为序号 0,某个指针现在的序号为 i,环的长度为 len,那么如果你在环中某一个走了 n 步,你接下来的序号为 (n + i) % len
虽然这是很简单的事,但是这就意味着,如果你走的步数之中包含环长,那么从结果上来看,有没有这个环长是无所谓的
他这个意思就是,双指针停止之后,初始化指向头节点的新指针与 slow 指针同步走,slow 指针走 c + (n - 1)(b + c) 步,新指针走 a 步,这两个是一样的
又因为在环中的指针走整数倍的圈数不影响它的位置,所以新指针走 a 步走到了入环点,而 slow 指针走的 c + (n - 1)(b + c) 步,原来在 b 步的位置,现在其实就是 b + c + (n - 1)(b + c) = n(b + c),%(b + c) 得 0,也就是 slow 指针也走到了入环点
这个时候新指针和 slow 指针相遇,可以作为 while 停止条件
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
ListNode* detectCycle(ListNode* head) {
ListNode* slow = head, * fast = head;
if (head == nullptr) return nullptr;
do {
if (fast->next == nullptr || fast->next->next == nullptr) return nullptr;
slow = slow->next;
fast = fast->next->next;
} while (slow != fast);
// reuse fast pointer
fast = head;
while(fast != slow){
slow = slow->next;
fast = fast->next;
}
return slow;
}
};
还有哈希表的做法,一遍遍历,发现在哈希表中出现过的节点,说明这个节点就是入环点,不过还要占 n 的空间
剑指 Offer II 023. 两个链表的第一个重合节点
经典双指针取间隔
一开始两个指针同步走,然后先达到终点的那个指针停下,然后给一个 tmp 赋为落后的那个指针的链表的头节点
落后的指针与 tmp 再同步走,直到落后的指针达到终点,赋落后的那个指针为 tmp,先达到终点的指针赋为其链表的头节点
这样的得到效果是,双指针距离各自的链表的尾部的距离是相同的
然后这个时候双指针再同步走,如果能相遇的话必定相遇
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
ListNode *getIntersectionNode(ListNode *headA, ListNode *headB) {
if(headA == nullptr || headB == nullptr) return nullptr;
ListNode* pA = headA, *pB = headB, *tmp;
while(pA != nullptr && pB != nullptr){
pA = pA->next;
pB = pB->next;
}
if(pA == nullptr){
tmp = headB;
while(pB != nullptr){
tmp = tmp->next;
pB = pB->next;
}
pA = headA;
pB = tmp;
}
else if(pB == nullptr){
tmp = headA;
while(pA != nullptr){
tmp = tmp->next;
pA = pA->next;
}
pB = headB;
pA = tmp;
}
while(pA != pB){
pA = pA->next;
pB = pB->next;
}
return pA;
}
};
这个题也可以用哈希表,先遍历一遍 A,然后再遍历一遍 B,遍历 B 的时候如果发现哈希表中已有节点,说明这个节点是相交的节点
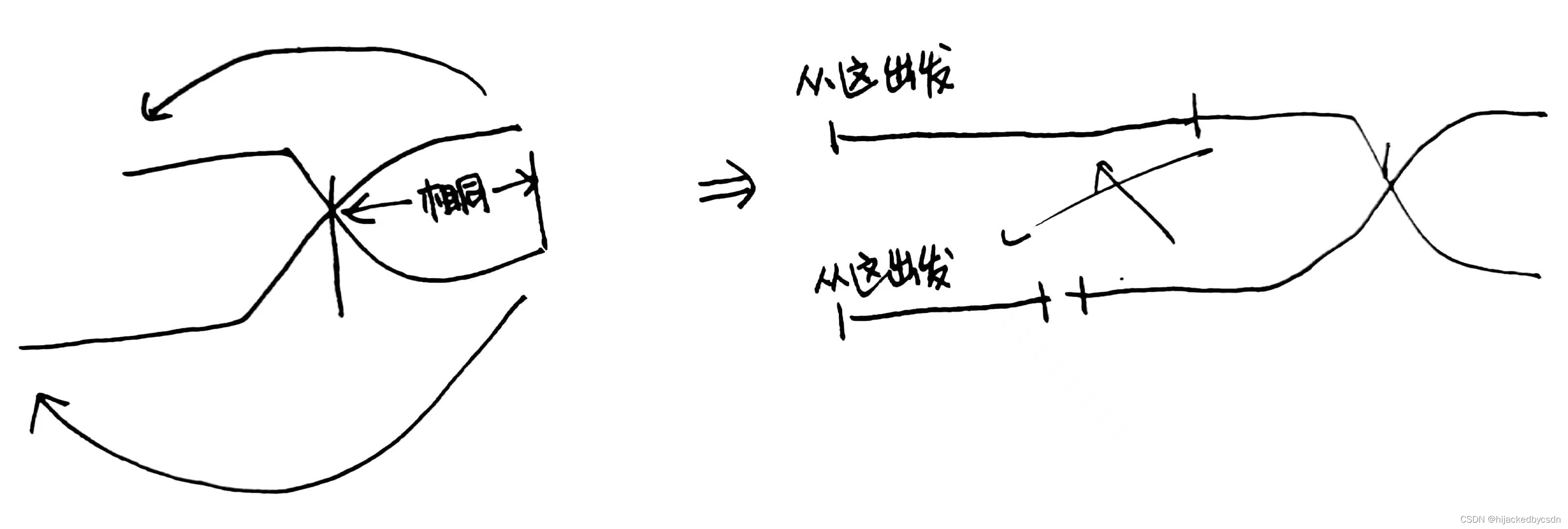
还有一种对齐的思路是,把 A 的尾结点与 B 的头节点连接,B 的尾结点与 A 的头节点连接

得到的结果就是两个指针走过的路变相地对齐了,因为相交点之后的那一段是相同的
剑指 Offer II 024. 反转链表
还是比较简单的
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* reverseList(ListNode* head) {
ListNode* curr = head, *prev = nullptr;
if(head == nullptr) return nullptr;
ListNode* tmp_next = curr->next;
while(tmp_next != nullptr){
curr->next = prev;
prev = curr;
curr = tmp_next;
tmp_next = curr->next;
}
curr->next = prev;
return curr;
}
};
剑指 Offer II 025. 链表中的两数相加
如果不修改原链表,就用栈来做
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* addTwoNumbers(ListNode* l1, ListNode* l2) {
stack<int> stk1, stk2, stk3;
ListNode* p = nullptr, *head = nullptr;
p = l1;
while(p != nullptr){
stk1.push(p->val);
p = p->next;
}
p = l2;
while(p != nullptr){
stk2.push(p->val);
p = p->next;
}
int sum = 0, res = 0;
while(!stk1.empty() && !stk2.empty()){
sum = stk1.top() + stk2.top() + res;
if(sum >= 10){
res = 1;
sum = sum % 10;
}
else{
res = 0;
}
stk1.pop();
stk2.pop();
stk3.push(sum);
}
while(!stk1.empty()){
sum = stk1.top() + res;
if(sum >= 10){
res = 1;
sum = sum % 10;
}
else{
res = 0;
}
stk1.pop();
stk3.push(sum);
}
while(!stk2.empty()){
sum = stk2.top() + res;
if(sum >= 10){
res = 1;
sum = sum % 10;
}
else{
res = 0;
}
stk2.pop();
stk3.push(sum);
}
if(res != 0) stk3.push(res);
p = nullptr;
while(!stk3.empty()){
ListNode* node = new ListNode(stk3.top());
stk3.pop();
if(head == nullptr){
head = node;
}
else{
p->next = node;
}
p = node;
}
return head;
}
};
剑指 Offer II 026. 重排链表
中等
给定一个单链表 L 的头节点 head ,单链表 L 表示为:
L0 → L1 → … → Ln-1 → Ln
请将其重新排列后变为:
L0 → Ln → L1 → Ln-1 → L2 → Ln-2 → …
不能只是单纯的改变节点内部的值,而是需要实际的进行节点交换。
注意最后要把结尾的环断开
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
void reorderList(ListNode* head) {
if (head == nullptr) return;
stack<ListNode*> nodes;
ListNode* p = head, * tmp = nullptr;
while (p != nullptr) {
nodes.push(p);
p = p->next;
}
p = head;
int len = nodes.size();
for (int i = len / 2; i > 0; i--) {
tmp = nodes.top();
nodes.pop();
tmp->next = p->next;
p->next = tmp;
p = tmp->next;
}
// 断开结尾的环
if (len > 1) {
if (len % 2 == 0)
tmp->next = nullptr;
else
p->next = nullptr;
}
}
};

















 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









