






前言:
前文中,我们已经对比了 C 与 C++ 在函数及输入输出等层面的差异,其本质区别在于:C语言采用面向过程的编程范式,而C++则基于面向对象的设计理念。
在C++中,类 (Class) 作为面向对象编程的基础抽象单元,实例化 (Instantiation) 则是将抽象类转化为具体可操作对象的关键过程。
接下来将从概念定义、语法结构、核心特性及代码示例等维度,系统阐述这两个概念及其内在关联。

一、类的详解
面向对象编程(OOP)中的类是一种抽象数据类型,它作为对象的蓝图,定义了具有相同属性和行为的一组对象的共同特征。
通过类可以确定对象的基本结构和行为模式。
1.1 类的语法格式
定义一个类,就是告诉编译器这个自定义类型长什么样。
主要包含两部分:
①属性 (成员变量):描述它 “是什么” (例如:名字、年龄)。
②行为 (成员函数):描述它 “能做什么” (例如:说话、跑步)。
class 类名
{
// 成员函数
void DoSomething();
// 成员变量
int variable;
}; // <--- 注意:这里必须有一个分号!
代码示例:定义一个 Student(学生)类:
#include <iostream>
#include <string>
using namespace std;
class Student
{
// 成员函数(行为)
void SetInfo(string n, int a)
{
_name = n;
_age = a;
}
void Study()
{
cout << _name << " 正在学习,虽然他已经 " << _age << " 岁了。" << endl;
}
// 成员变量(属性)
string _name;
int _age;
};
温馨提示:
为了区分成员变量,⼀般习惯上成员变量会加⼀个特殊标识,如成员变量前⾯或者后⾯加_ 或者 m 开头,
注意C++中这个并不是强制的,只是⼀些惯例。
1.2 访问限定符
在 C++ 中,访问限定符是实现封装的关键工具,它们决定了类中的成员(变量和函数)在什么地方可以被访问,什么地方被禁止访问。
访问权限作⽤域从该访问限定符出现的位置开始直到下⼀个访问限定符出现时为⽌,如果后⾯没有访问限定符,作⽤域就到类结束为止。
1.2.1 public (公有)
权限:public修饰的成员在类外可以直接被访问,可以形象的理解为:家门口的告示牌,谁路过都能看。
用途:通常用于成员函数(接口),供外部调用。
代码示例:在学生类中通过使用public,此时类中的所有成员可以直接被访问
#include <iostream>
#include <string>
using namespace std;
class Student
{
public:
// 成员函数(行为)
void SetInfo(string n, int a)
{
_name = n;
_age = a;
}
void Study()
{
cout << _name << " 正在学习,虽然他已经 " << _age << " 岁了。" << endl;
}
// 成员变量(属性)
string _name;
int _age;
};
1.2.2 private (私有)
权限:private修饰的成员在类外不能直接被访问,可以形象的理解为:你的日记本,只有你自己(类内部)能看,连孩子(子类)都不能看。
用途:通常用于成员变量,防止外部随意修改数据(数据隐藏)。
代码示例:在学生类中,对成员函数使用public,对成员变量使用private
#include <iostream>
#include <string>
using namespace std;
class Student
{
public:
// 成员函数(行为)
void SetInfo(string n, int a)
{
_name = n;
_age = a;
}
void Study()
{
cout << _name << " 正在学习,虽然他已经 " << _age << " 岁了。" << endl;
}
private:
// 成员变量(属性)
string _name;
int _age;
};
温馨提示:
① 在该段代码中public修饰的范围:从public到private之间的代码段。
② 在该段代码中通过private修饰后的成员变量不可在类的外部被访问
1.2.3 protected (保护)
权限:protected修饰的成员在类外不能直接被访问,但允许子类(派生类)进行使用,可以形象的理解为:家里的传家宝,只有自己和孩子(子类)能用,外人不行。
用途:当你希望数据对外界保密,但允许子类继承和使用时。
温馨提示:在我们初学时姑且可以认为protected和private是⼀样的,在以后学习了继承章节才能体现出他们的区别。
1.2.4 默认情况
在C++编程中,当我们声明类成员(包括数据成员和成员函数)时,如果没有显式指定访问限定符(public、protected或private),编译器会自动为其分配默认的访问权限。
1. 对于类(class)定义:
权限:默认访问权限是private
内容:这意味着在类体中,所有未明确指定访问权限的成员都将被视为私有成员
代码示例:
class MyClass
{
int x; // 默认为private
void func(); // 默认为private
};
2.对于结构体(struct)定义:
权限:默认访问权限是public
内容:这意味着在结构体中,所有未明确指定访问权限的成员都将被视为公有成员
代码示例:
struct MyStruct
{
int x; // 默认为public
void func(); // 默认为public
};
温馨提示:
在 C++ 中,
class和struct几乎是一样的,唯一的区别就在于默认的访问权限不同。
1.3 类域
在 C++ 中,类域 (Class Scope) 指的是类定义的大括号 { } 包围起来的区域。
形象理解:
你可以把类域想象成一个“专属领地”或“围墙”, 在围墙里面定义的东西(变量、函数、类型),只属于这个类。
出了这个围墙,别人就不知道它们是谁了,除非你明确指出“我要找某某家里的某某”。
这很好的解决了命名冲突的问题,比如,Human 类里可以有一个 run() 函数,Car 类里也可以有一个 run() 函数,它们互不干扰,因为它们属于不同的“领地”。
1.3.1 为什么需要类域
在 C 语言中,如果两个库都定义了一个叫 Print 的函数,编译器就会报错(重定义),但在 C++ 中,类定义了一个新的作用域。
代码示例:Person域里的Print 和 Printer域里的Print
class Person
{
void Print()
{
cout << "Hello world" << endl;
}
};
class Printer
{
void Print()
{
cout << "Hello world" << endl;
}
};
1.3.2 访问类域
当我们需要在类外面访问类里面的成员时,就需要用到作用域限定符:“ :: ”。
它的含义是:“属于”,例如 Person::Print 读作:“Person 类里的 Print”。
应用场景一:声明与定义分离
在实际开发中,我们通常在类里面只写声明(告诉编译器有什么),而把具体的实现(代码逻辑)写在类外面,这时就必须使用到作用域限定符:“ :: ”。
代码示例:通过在Person类内声明Eat函数,在类域外定义函数
#include <iostream>
using namespace std;
class Person
{
public:
//在类域内只声明
void Eat();
};
// 在类域外定义(实现)
// 必须加 Person::,否则编译器以为这是个普通的全局函数
void Person::Eat()
{
cout << "正在吃饭..." << endl;
}
如果忘记写
Person::会怎样?
编译器会认为你定义了一个叫
Eat的全局函数,而不是Person类的成员函数,那么你就无法访问Person类里的私有成员变量。
应用场景二:类型也是类域的一部分
类域不仅包含变量和函数,还包含类型定义(如 enum, typedef, 嵌套类)。
代码示例:在Screen类,对内置类型int重定义
class Screen
{
public:
// 定义了一个类型 pos,它只在 Screen 类域内有效
typedef int pos;
pos cursor; // 类内直接用,没问题
};
int main()
{
pos x; // 错误!外面不认识 pos 是什么
// 正确:必须告诉编译器,我要用 Screen 里的 pos 类型
Screen::pos myCursor = 10;
return 0;
}
应用场景三:类域内的名称遮蔽
当函数的局部变量(通常是参数)和成员变量同名时,局部变量优先,这会导致成员变量被“遮蔽”了。
代码示例:当参数变量名与成员变量名相同时,可以通过使用 类名:: 成员变量 来进行区分
class Box
{
public:
// 参数也叫 width
void setWidth(int width)
{
Box::width = width;
}
private:
int width; // 成员变量
};
二、实例化详解
在 C++ 中,类 (Class) 和 实例化 (Instantiation) 是面向对象编程(OOP)的核心概念。
其中类是对象进⾏⼀种抽象描述,是⼀个模型⼀样的东西,限定了类有哪些成员变量,这些成员变量只是声明,没有分配空间,⽤类实例化出对象时,才会分配空间。
为了直观地理解,我们可以使用一个经典的比喻:“图纸”与“房子”。
①类 (Class):就像是建筑图纸,它规定了房子有几扇窗、什么颜色、怎么开门,但图纸本身不能住人,也不占用土地空间。
②实例化 (Instantiation):就是根据图纸盖房子的过程,盖出来的房子叫做对象 (Object),房子是实实在在存在的,占用土地(内存)空间。
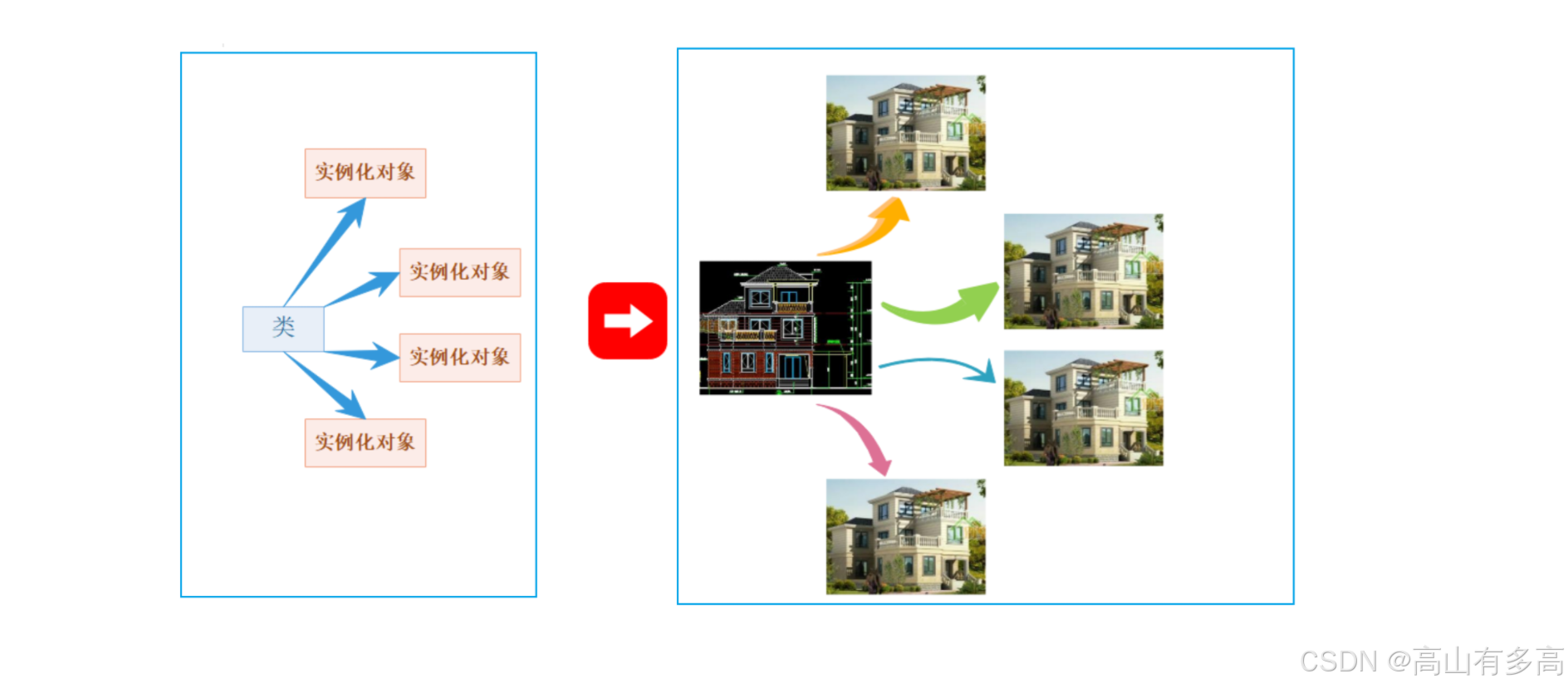
2.1 实例化对象
实例化对象的过程就是根据图纸盖房子的过程,盖出来的房子叫做对象 (Object),房子是实实在在存在的,占用土地(内存)空间。
在内存上的栈区进行实例化 (静态分配),这是最常用的方式,系统会自动管理内存,出了作用域(比如函数结束),对象自动销毁。
-
语法:
类名 对象名; -
访问成员:使用点操作符
.
代码示例:声明Date 日期类,并实例化出对象d1
class Date
{
public:
void Init(int year, int month, int day)
{
_year = year;
_month = month;
_day = day;
}
void Print()
{
cout << _year << "/" << _month << "/" << _day << endl;
}
private:
// 这⾥只是声明,没有开空间
//为了区别形参,在成员变量前加特殊标示,如 _
int _year;
int _month;
int _day;
};
void test01()
{
//实例化出对象 d1
Date d1;
//通过.进行访问类中的函数
d1.Init(2025, 12, 21);
d1.Print();
}
2.2 对象的⼤⼩
计算一个类实例化出的对象的大小( 即 sizeof(对象)),是 C++ 面试和底层编程中非常经典的问题。
很多初学者会直觉地认为:对象大小 = 所有成员变量大小之和。
2.2.1 原则 1:只算“普通成员变量”
算进去的:
①非静态成员变量:属于每个对象独自拥有的数据(如:int age,char c 等)。
②虚函数指针:如果类中有虚函数(涉及到多态),对象内部会隐藏一个指针,通常占 4 字节(32位系统)或 8 字节(64位系统)。
不算进去的:
①成员函数:函数代码存放在公共代码区,不占对象空间。
②静态成员变量:存放在全局/静态数据区,属于类共有,不属于某个对象。
③类型定义 (typedef, enum 等):只是定义,不占内存。
温馨提示:
实例化的对象中只存储非静态的成员变量,而不进行存储成员函数,因为成员函数存储在公共代码区。
为什么要这样设计?(空间效率)
想象一下,你是一个老师,班里有 50 个学生(50 个对象)。
成员变量(私有数据):每个学生都有自己的“作业本”,张三写张三的,李四写李四的,每个人的内容不一样,必须人手一本。
成员函数(行为逻辑):这是“教科书”,书本里的知识点和公式(代码逻辑)对所有人都是一样的。
如果对象里包含函数代码: 就像要求每个学生必须把整本教科书的内容抄写到自己的作业本上,如果有 50 个学生,教科书的内容就被复制了 50 份,这极其浪费纸张。
现在的设计: 教科书只有一本(放在讲台上,即公共代码区),所有学生共用这一本书,但每个人在作业本(对象内存)上写自己的答案。
2.2.2 原则 2:内存对齐 (重点)
在计算类大小前,首先得了解规则:
1. 类的第⼀个成员对⻬到和类中成员变量起始位置偏移量为0的地址处(第一个成员对齐到偏移量为0的位置)
2. 其他成员变量要对⻬到某个数字(对⻬数)的整数倍的地址处。
对⻬数 = 编译器默认的⼀个对⻬数 与 该成员变量⼤⼩的较⼩值。
- VS 中默认的值为 8
- Linux中 gcc 没有默认对⻬数,对⻬数就是成员⾃⾝的⼤⼩
3. 类的总⼤⼩为最⼤对⻬数(类中每个成员变量都有⼀个对⻬数,所有对⻬数中最⼤的)的整数倍。
4. 如果嵌套了类的情况,嵌套的类成员对⻬到⾃⼰的成员中最⼤对⻬数的整数倍处,类的整体⼤⼩就是所有最⼤对⻬数(含嵌套类成员的对⻬数)的整数倍。
温馨提示:
对于一个类而言,访问权限 public / private 不影响内存大小和对齐规则,成员依然按照声明顺序排列 。
实战演练一:普通类
class MyClass
{
private:
char a; // 1 字节
public:
int c; //int:4 字节 vs默认对齐数:8字节 对齐数:4字节
//MyClass类的最大对齐数:4
};
int main()
{
MyClass c;
cout<<sizeof(c)<<endl;
}
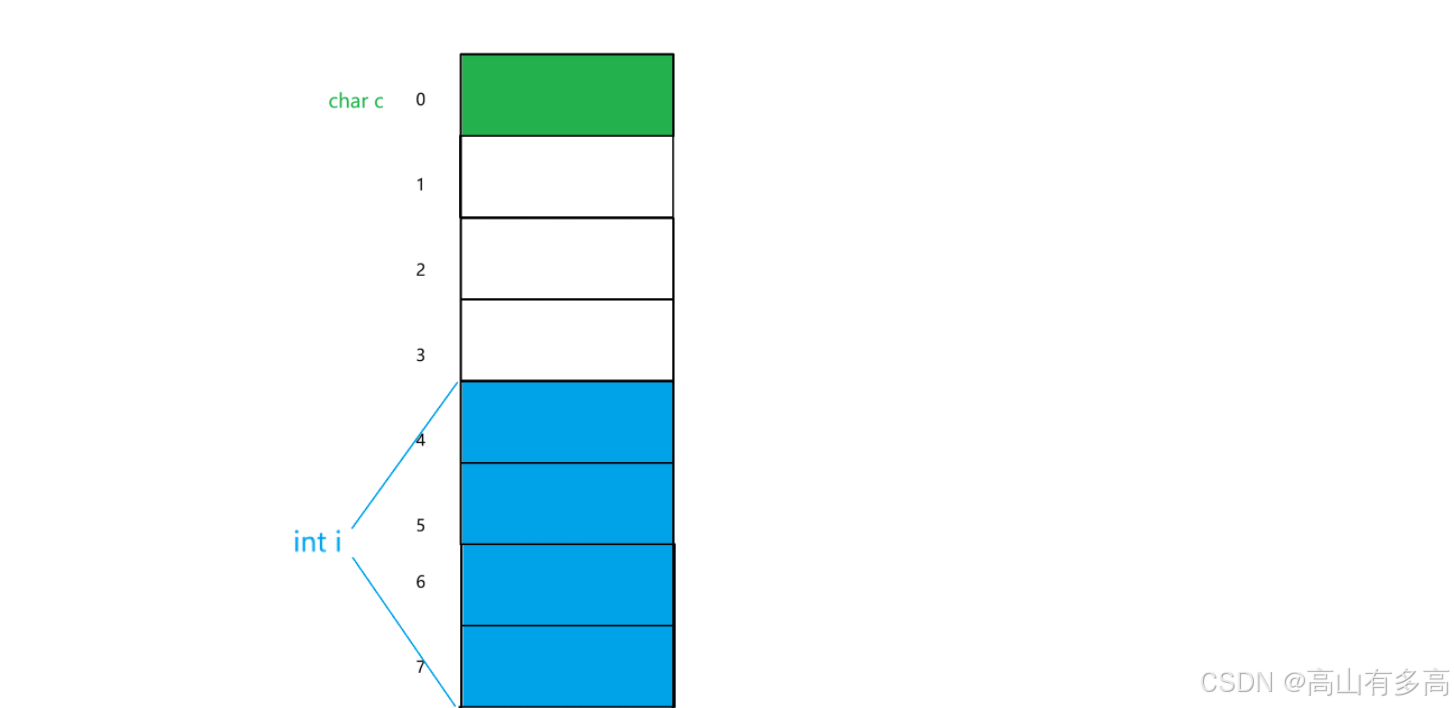
① char a; 为类中的第一个成员,需要对齐到偏移量为0的位置
② int i; int:4 字节 vs默认对齐数:8字节 对齐数:4字节
③类的最大对齐数:4
如上图所示,该类的内存大小为8个字节,满足最大对齐数的整数倍。
实战演练二:类中嵌套类
// 发动机类 (Engine)
class Engine
{
char type; // 1 字节
int power; // 4 字节
// Engine 自身大小:1 + (3填充) + 4 = 8 字节
// Engine 的最大对齐数:4 (因为 int)
};
// 汽车类 (Car)
class Car
{
char color; // 1 字节
Engine eng; //Engine对象的对齐数为:4 vs默认对齐数为:8 对齐数为:4字节
char brand; //char: 1 字节 vs默认对齐数为:8 对齐数:1
//car类的最大对齐数为:4
};
int main()
{
Car c;
cout<<sizeof(c)<<endl;
}
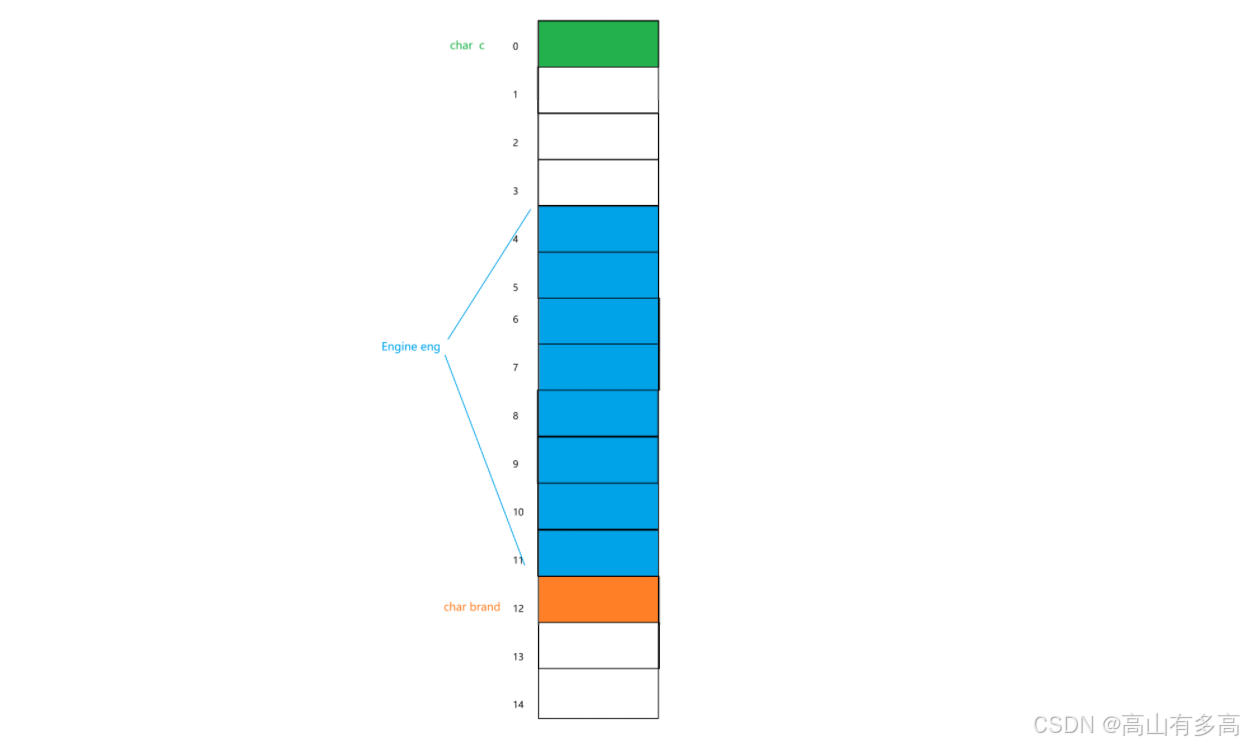
①char color; 为类中的第一个成员,需要对齐到偏移量为0的位置
②Engine eng; Engine最大成员:4字节 vs默认对齐数:8字节 对齐数:4字节 (占用8字节)
③char brand : char:1字节 vs默认对齐数:8字节 对齐数:1字节
④Car类的最大对齐数:4
如上图所示,Car类目前的内存大小为13个字节,不满足最大对齐数的整数倍,需要填充到整数倍,故而Car类的内存大小为16字节。
实战演练三:类型定义(如:typedef 、enum、class声明 )
1. typedef / using (类型别名)
情况A:起个别名不需要占用内存
class Person
{
// 只是起个名字,编译器记在小本本上:"Age 就是 int"
typedef int Age;
using ID = long;
};
情况B:定义了变量需要占用内存
class Person
{
// 只是起个名字,编译器记在小本本上:"Age 就是 int"
typedef int Age;
using ID = long;
// 真正的变量,这才是要占内存的
Age myAge; // 等同于 int myAge; (占 4 字节)
ID myID; // 等同于 long myID; (占 4/8 字节)
};
2.enum (枚举定义)
情况A:声明枚举变量不占用内存
class TrafficLight
{
// 这只是告诉编译器:Color 这种类型只有 3 种可能的值
// 这是一个规则定义,不是数据
enum Color
{
RED = 0,
YELLOW = 1,
GREEN = 2
};
// 没有定义 Color 类型的变量!
};
情况B:声明了枚举类型并进行定义变量,需要占用内存
class TrafficLight
{
// 1. 定义类型 (不占内存)
enum Color { RED, YELLOW, GREEN };
// 2. 定义变量 (占内存!)
Color currentLight;
};
3. 嵌套类
情况A:定义了新类型不占用内存
class Outer
{
public:
//只是定义了一种新类型叫 Inner,就像定义 enum 或 typedef 一样
//不占用内存
class Inner
{
int y; // 4 字节
int z; // 4 字节
};
};
情况B:定义了变量需要占用内存
class Outer
{
public:
//只是定义了一种新类型叫 Inner,就像定义 enum 或 typedef 一样
//不占用内存
class Inner
{
int y; // 4 字节
int z; // 4 字节
};
// 定义变量 (占内存!)
Inner in;
};
实战演练四:包含静态变量和成员函数
// 情况2:包含静态成员和函数
class WithStatic
{
char c; // 1
int i; // 4
static int s; // 不算!
void func() {} // 不算!
// 结果依然是 8
};
温馨提示:静态变量和成员函数均不占用内存,因为静态变量存储在静态区,成员函数存储在公共代码段
① char a; 为类中的第一个成员,需要对齐到偏移量为0的位置
② int i; int:4 字节 vs默认对齐数:8字节 对齐数:4字节
③类的最大对齐数:4
如上图所示,该类的内存大小为8个字节,满足最大对齐数的整数倍。
2.2.3 原则 3:空类(特殊)
空类的大小是 1,这是类和结构体的一个显著区别点(在 C 语言中空结构体大小可能是 0,但在 C++ 中空类必须占位)。
class Empty
{
};
int main()
{
sizeof(Empty) == 1
}
原因:为了保证每个实例化的对象在内存中都有独一无二的地址。
2.2.4 总结
| 内存区域 | 存放内容 | 归属权 | 这里的算进 sizeof(对象) 吗? |
| 栈/堆 | 非静态成员变量 (int a, char b) | 归属于对象 (每个对象各有一份) | 算!只有这些才是本体 |
| 静态/全局区 | 静态成员变量 (static int count) | 归属于类 (所有对象共享一份) | 不算! |
| 代码区 | 成员函数 (void fun()) | 归属于类 (所有对象共用一份代码) | 不算! |
三、this指针
3.1 什么是this指针
this 指针本质是一个对象指针,作为 C++ 类机制中连接“对象”与“成员函数”的隐形桥梁。
this指针的本质是: 类名 * const this
3.2 this指针的引入
代码示例:声明了一个学生类
class Student
{
public:
int age;
void SetAge(int a)
{
age = a; // 这里的 age 实际上是 this->age
}
};
int main()
{
Student s1;
s1.SetAge(18); // 调用
Student s2;
s2.SetAge(20); // 调用
}
我们之前已经非常清楚地认识到:“成员函数存在公共代码区,不占对象内存”。
那么成员函数是如何区分是对象s1调用,还是对象s2调用的呢?
答案就是:靠
this指针偷偷传纸条。
编译器处理后的代码(实际发生的):编译器做了一场“手术”,把对象地址作为参数传了进去。
class Student
{
public:
int age;
// 1. 函数定义变了:多了一个名为 this 的指针参数
//函数相当于变成了void SetAge(Student *const this,int a)
void SetAge(int a)
{
age = a; // 这里的 age 实际上是 this->age
}
};
// 2. 调用方式变了:把 s1 的地址 (&s1) 传进去
int main()
{
Student s1;
s1.SetAge(18); //相当于调用了s1.SetAge(&s1, 18);
Student s2;
s2.SetAge(&s2, 20); //相当于调用了s2.SetAge(&s2, 20);
}
结论: this 指针保存的就是当前调用该函数的对象的地址。
①当你调用 s1.SetAge(18),this 就指向 s1。
②当你调用 s2.SetAge(20),this 就指向 s2。
3.3 this 指针的特性
①只能在成员函数内部使用:全局函数、静态成员函数(static)里没有 this 指针。
②指针被 const修饰:this 的类型是 类名* const,这意味着你不能修改 this 指针本身的指向(不能写 this = nullptr; 或 this = &otherObj;),但你可以修改 this 指向的对象的内容。
③this指针的声明周期:它作为函数的参数(形参),在函数调用时创建,函数结束时销毁,它不占用对象的存储空间(通常通过寄存器 ecx 传递)。
3.4 this指针的使用
场景一:解决命名冲突
当函数的形参和成员变量同名时,形参会遮挡成员变量。
class Student
{
public:
void SetAge(int age)
{
this->age = age; // 把形参 age 赋给当前对象的成员 age
}
private:
int age;
};
场景二:链式调用
如果你想让代码写成 obj.func1().func2().func3() 这种“流水线”风格,函数需要返回对象本身。
class Calculator
{
public:
Calculator() { sum = 0; }
// 返回引用,意味着返回对象本体,而不是拷贝
Calculator& add(int n)
{
sum += n;
return *this; // 返回当前对象的引用
}
private:
int sum;
};
int main()
{
Calculator calc;
// 链式调用:先加1,结果(对象本身)再加2,再加3
calc.add(1).add(2).add(3);
}
3.5 一个经典的“坑”:空指针调用
class A
{
public:
void Print()
{
cout << "Hello" << endl;
}
void PrintAge()
{
cout << age << endl;
}
private:
int age;
};
int main()
{
A* p = nullptr; // p 是空指针
p->Print(); // 第一行:会不会崩?
p->PrintAge(); // 第二行:会不会崩?
}
详情解析:
①p->Print():不会崩!
编译器将其转化为 Print(p)。
虽然传进去的 this 指针是 nullptr,但 Print 函数内部并没有解引用 this(没有访问任何成员变量),它只是打印一个字符串。所以能正常运行。
②p->PrintAge():会崩!
编译器转化为 PrintAge(p)。
函数内部试图访问 age,这等价于 this->age。
因为 this 是 nullptr,访问 nullptr->age 会导致段错误
为了让你彻底理解“为什么”,我们需要拆解成三个层面来讲:
1. 物理层面:代码复用 (为了省内存)
我们在之前的对话中提到过:成员函数不占对象内存,它存在公共代码区。
这意味着,无论你实例化了 100 个对象还是 1000 个对象,
既然代码只有一份,它的内存地址就是固定的(假设地址是
0x400800)。当你调用
p->Print()时,CPU 实际上是执行了一条指令:call 0x400800(跳转到该函数地址去执行)。
问题来了: 既然大家都跳转到同一个地方去执行代码,函数怎么知道现在是处理 A 对象的数据,还是 B 对象的数据呢?
解决方案: 必须把对象的地址当成参数带过去!这就是
Print(p)的由来。p就是那个必须要带过去的“上下文”。
2. 历史层面:C++ 的前身是 C (翻译机制)
C++ 最早的编译器叫 Cfront,它的工作原理不是直接把 C++ 变成机器码,而是先把 C++ 翻译成 C 语言,然后再用 C 编译器编译。
了解这段历史,你就能瞬间明白这种转换逻辑:
class A
{
public:
int x;
void func(int num)
{
x = num;
}
};
int main()
{
A a;
a.func(10);
}
编译器“脑补”出的 C 语言代码
为了在 C 语言里实现面向对象,编译器做了两件事:
-
把
class里的函数拆出来,改成全局函数(改个名字,防止重名)。 -
给函数加一个参数
A* const this。
// 1. 结构体只包含数据
struct A
{
int x;
};
// 2. 成员函数变成了全局函数,多了一个 this 指针参数
// _ZN1A4funcEi 是编译器修饰后的名字
void _ZN1A4funcEi(struct A* const this, int num)
{
this->x = num; // 通过指针操作数据
}
int main()
{
struct A a;
// 3. 调用时,自动把 &a 传进去
_ZN1A4funcEi(&a, 10);
}
3. 为什么 nullptr 调用不崩?(核心逻辑)
当我们写:
A* p = nullptr;
p->Print();
编译器将其转化为:
// 假设 Print 函数实际上叫 A_Print
A_Print(p);
此时发生了什么?
①传参:把 p 的值(也就是 0 或 NULL)作为第一个参数传给函数,这一步是合法的,传个 0 进去怎么了?不会崩。
②跳转:CPU 跳转到 A_Print 函数的代码地址开始执行,这一步也是合法的,代码就在那,跑过去就行。
③函数内部执行:
如果函数里写的是 cout << "Hello":它不需要读取寄存器里的那个 0,直接打印字符串,程序正常运行。
如果函数里写的是 cout << this->age:CPU 尝试去读取 0 地址偏移量的内存(比如 0x0000 + 4),访问 0 地址是非法的 -> 操作系统拦截 -> 崩溃 。
相信看了上述解释,你也能够征服面试官!
既然看到这里了,不妨关注+点赞+收藏,感谢大家,若有问题请指正。



















 5081
5081

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









