




 本文探讨了针对InceptionV1的网络优化方法,包括避免早期特征压缩、增加卷积块激活、使用小卷积核分解大卷积核以及辅助分类器的正则化作用。通过这些优化,可以提升网络性能而不显著增加计算量。此外,介绍了高效降低特征图尺寸的策略,以及InceptionV2和InceptionV3的演变过程。
本文探讨了针对InceptionV1的网络优化方法,包括避免早期特征压缩、增加卷积块激活、使用小卷积核分解大卷积核以及辅助分类器的正则化作用。通过这些优化,可以提升网络性能而不显著增加计算量。此外,介绍了高效降低特征图尺寸的策略,以及InceptionV2和InceptionV3的演变过程。
文章目录
1 摘要
1.1 本文要解决的问题(优化InceptionV1)
Here we will describe a few design principles based on large-scale experimentation with various architectural choices with convolutional networks
提出了一些被证明有用的、用于扩展网络结构的一般性准则和优化方法,并优化InceptionV1
2 一般性准则和优化方法
2.1 避免在网络初期就将特征极度压缩,会导致丢失非常多的信息
One should avoid bottlenecks with extreme compression. In general the representation size should gently decrease from the inputs to the outputs before reaching the final representation used for the task at hand.
2.2 增加每个卷积块的激活(不太理解)
Higher dimensional representations are easier to process locally within a network. Increasing the activations per tile in a convolutional network allows for more disentangled features. The resulting networks will train faster.
2.3 3x3之前用1x1降维信息并不会有太多损失,但能加快训练
Spatial aggregation can be done over lower dimensional embeddings without much or any loss in representational power.
Given that these signals should be easily compressible, the dimension reduction even promotes faster learning.
2.4 平衡网络的深度和宽度(修改filter的参数,每层filter的数量,网络的结构等),可以在不增加计算量的情况下,加强网络性能
Balance the width and depth of the network. Optimal performance of the network can be reached by balancing the number of filters per stage and the depth of the network. Increasing both the width and the depth of the network can contribute to higher quality networks. However, the optimal improvement for a constant amount of computation can be reached if both are increased in parallel. The computational budget should therefore be distributed in a balanced way between the depth and width of the network.
3 优化方法一:用小的卷积核去分解大的卷积核 (Factorizing Convolutions with Large Filter Size)
2个3x3的卷积核感受野与1个5x5卷积核感受野相同,计算量减少,不详细说。
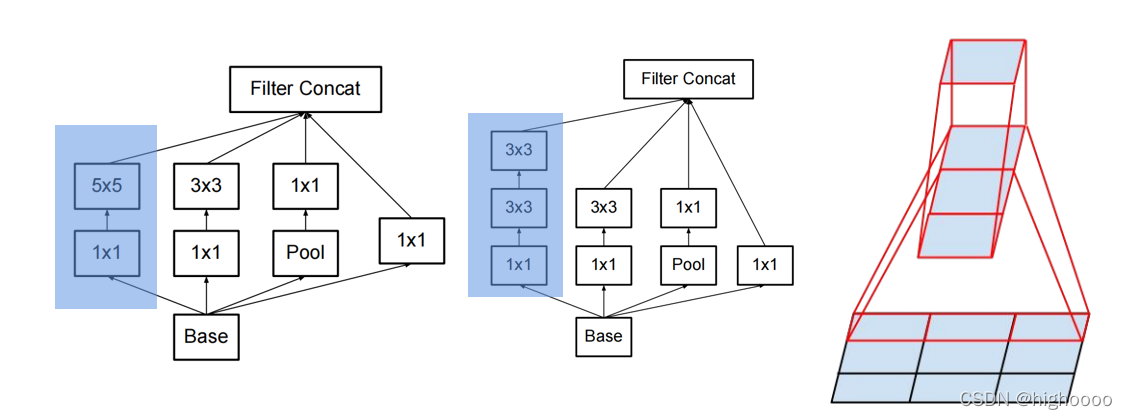
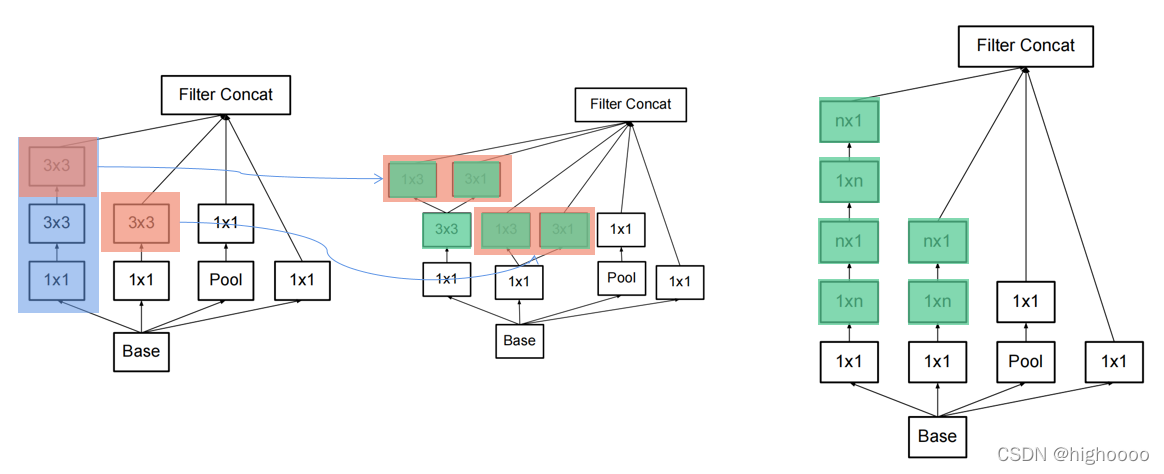
1x3+3x1又可以分解3x3 (非对称分解卷积)
4 优化方法二:辅助分类器(Utility of Auxiliary Classifiers)
Instead, we argue that the auxiliary classifiers act as regularizer.
作为一个正则化工具(只是猜想),因为辅助分类器在网络浅层几乎没作用,只在深层有效。
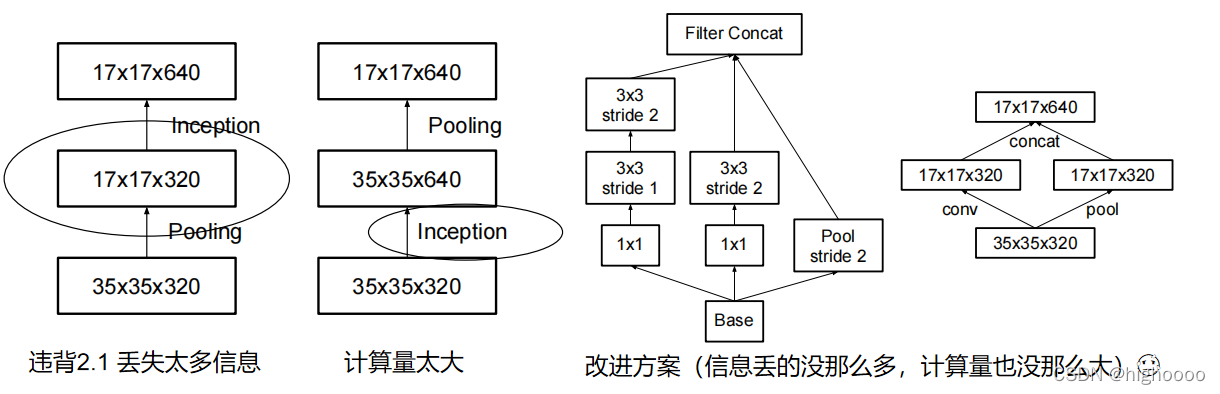
5 优化方法三:高效下降特征图尺寸(Efficient Grid Size Reduction)
提到了传统都是先卷积再池化
6 InceptionV2
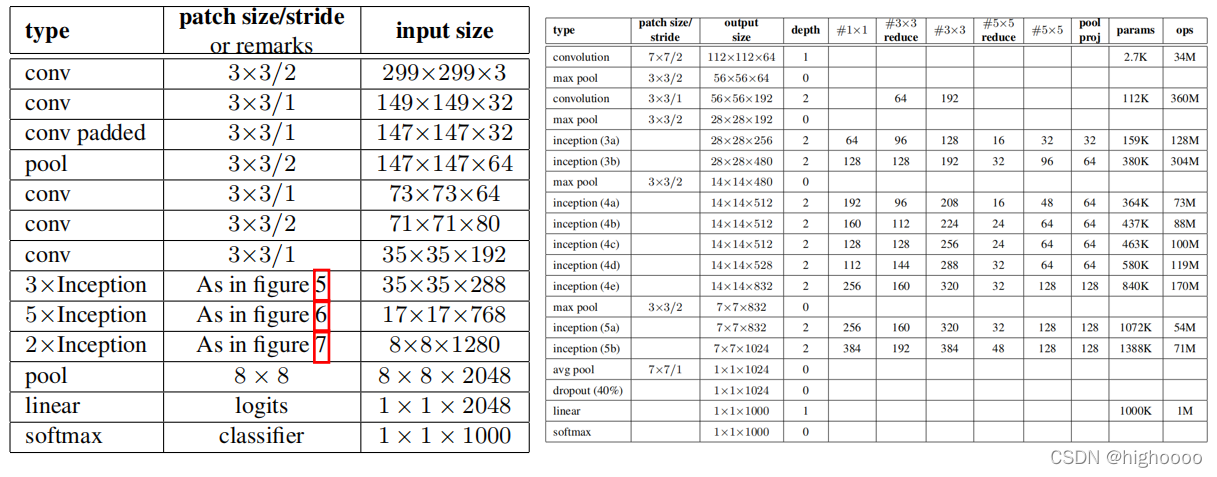
7 InceptionV3
InceptionV2加上RMSprop优化、LSR 与 BN-auxilary, 形成了Inception-v3

















 805
805

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









