




 本文详细阐述了一种仅需self-attention和线性层构成的Encoder-Decoder模型,对比了其与Seq2Seq和RNN的区别。重点介绍了多头注意力机制、QKV操作、位置编码和正则化的应用,以及Transformer如何优化语言模型并减少RNN的记忆限制。
本文详细阐述了一种仅需self-attention和线性层构成的Encoder-Decoder模型,对比了其与Seq2Seq和RNN的区别。重点介绍了多头注意力机制、QKV操作、位置编码和正则化的应用,以及Transformer如何优化语言模型并减少RNN的记忆限制。
文章目录
1 摘要
1.1 核心
提出一个仅需要self attention + linear组合成encoder+decoder的模型架构
2 模型架构
2.1 概览
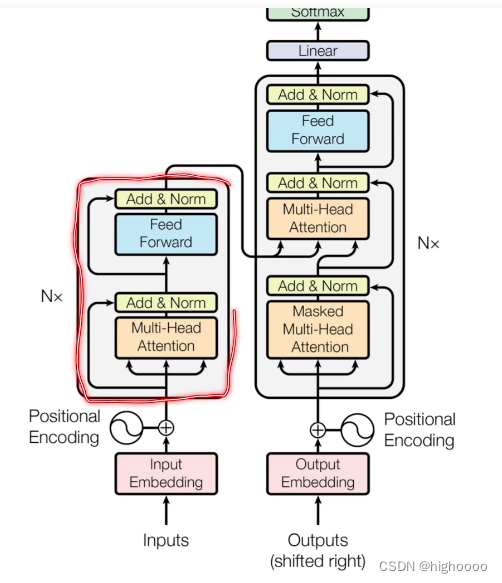
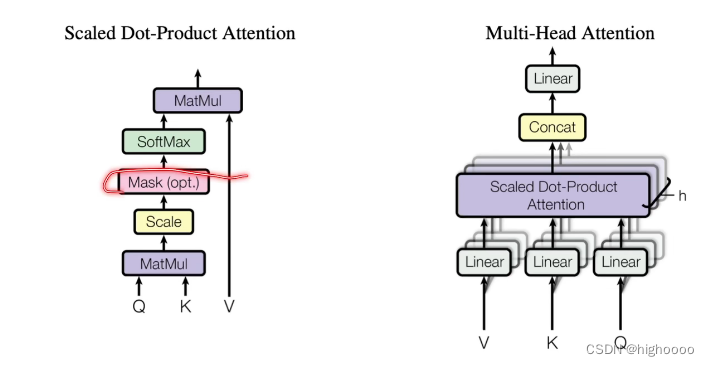
2.2 理解encoder-decoder架构
2.2.1 对比seq2seq,RNN
Self Attention
- 输入token转为特征输入
- shape [n(序列长度), D(特征维度)] 输入
- 进入attention模块
- 输出 shape [n(序列长度), D1(特征维度)] 此时每个D1被N个D做了基于attention weight的加权求和
- 进入MLP
- 输出 shape [n(序列长度), D2(输出维度)] 此时每个D2被D2和MLP weight矩阵相乘
- 每个D2转换为输出token
RNN
- 34步去除,并将每次MLP的输入修改为前一个Kt-1组合Kt输入
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1367
1367

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









